[DeepLearning from scratch] Xử lý, xây dựng deep learning model với tập dữ liệu.
Bài đăng này đã không được cập nhật trong 8 năm
Đây là một bài mẫu phổ biến trên thế giới, nó quen thuộc với những người mới bắt đầu học hoặc nghiên cứu về Machine Learning, Deep Learning.
Trọng tâm bài viết bao gồm các mục sau:
- Phân tích dữ liệu và hiển thị dữ liệu.
- Phân lớp sử dụng neural network với tensorflow.
Phân tích và hiển thị dữ liệu
Phân tích tập dữ liệu (dataset)
Chúng ta sẽ sử dụng một bộ dữ liệu phổ biến được soạn bởi Đại học Wisconsin vào năm 1992. Nhiều bài báo đã được công bố về phân loại trên tập dữ liệu này bằng các kỹ thuật như SVM, logistic regression và mạng nơron. Mỗi hàng dữ liệu chứa một bản tóm tắt các ô trong một mẫu. Các chỉ số tóm tắt là: trung bình (mean), độ lệch chuẩn (standard deviation) và "tệ nhất" (worst). Ba chỉ số tóm tắt được cung cấp cho từng tính năng sau (ngoại trừ chẩn đoán):
- diagnosis: chẩn đoán (M = ác tính, B = lành tính) - biến mục tiêu của chúng ta
- radius: bán kính (trung bình khoảng cách từ trung tâm đến điểm trên chu vi)
- texture: kết cấu (độ lệch chuẩn của các giá trị thang độ xám)
- perimeter: chu vi
- area: diện tích
- smoothness: độ mịn (biến thiên cục bộ trong độ dài bán kính)
- compactness: phân bố (chu vi ^ 2 / diện tích - 1.0)
- concavity: độ lõm (mức độ nghiêm trọng của các phần lõm của đường bao)
- concave points: điểm lõm (số phần lõm của đường bao)
- symmetry: tính đối xứng
- fractal dimension: kích thước fractal
Tập dữ liệu này gồm 569 mẫu, mỗi mẫu bao gồm 32 thuộc tính. Khi mở tập dữ liệu lên, ta thấy rằng:
- Cột
IDkhông thể được dùng vào phân loại được. - Diagnosis là class label => target của classify
- Cột
Unnamed: 32chứaNaNvì vậy ta không cần chúng.
Các bước thực hiện:
import numpy as np
import pandas as pd
import seaborn as sns # data visualization library
import matplotlib.pyplot as plt
import time
data = pd.read_csv('data.csv')
# y includes our labels and x includes our features
y = data.diagnosis # M or B
list = ['Unnamed: 32','id','diagnosis']
x = data.drop(list,axis = 1 )
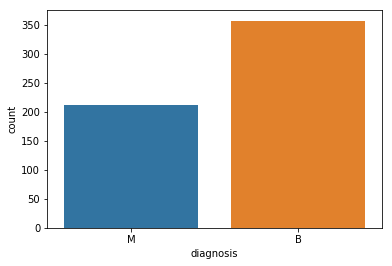
Như vậy ta đã xử lý xong phần phân tích dữ liệu mẫu, để có cái nhìn tổng quát về tỉ lệ label, ta sẽ biểu diễn chúng bằng chart
ax = sns.countplot(y,label="Count") # M = 212, B = 357
B, M = y.value_counts()
Hiển thị hóa dữ liệu.
Tại sao cần phải hiển thị hóa dữ liệu?
Dựa vào cách bộ não con người xử lý dữ liệu, sử dụng biểu đồ hoặc đồ thị để miêu tả lượng lớn dữ liệu phức tạp sẽ dễ dàng hơn nhiều so với các bản báo cáo hoặc bảng tính. Hiển thị hóa dữ liệu là một cách nhanh chóng, dễ dàng truyền tải các khái niệm (concept) mà không vướng vào bất kì rào cản nào đối với người khác, hơn nữa, bạn còn có thể thử nghiệm với các tình huống khác nhau chỉ bằng một vài điều chỉnh nhỏ.
Tóm lại việc hiển thị hóa dữ liệu sẽ giúp tôi như thế nào...?
1. Nhận ra các vùng, miền bạn cần phải chú ý hoặc cần được cải thiện.
2. Lọc ra các yếu tố ảnh hưởng đến dữ liệu bạn cần.
3. Giúp bạn hiểu vị trí cần đặt của dữ liệu.
4. Dự đoán dữ liệu tiếp theo.

Lời khuyên: bạn nên luôn luôn hiển thị hóa dữ liệu của bạn để đưa ra nhận xét và giải pháp tốt nhất cho tập dữ liệu của bạn.
Nhóm các feature để quan sát dữ liệu tốt nhất
Quay trở lại với dữ liệu của chúng ta. Bởi vì sự khác nhau giữa các giá trị của thuộc tính rất lớn để quan sát trên đồ thị, ta sẽ nhóm các đặc trưng (feature) vào 3 nhóm, mỗi nhóm bao gồm 10 đặc trưng để quan sát tốt hơn.
# first ten features
data_dia = y
data = x
data_n_2 = (data - data.mean()) / (data.std()) # standardization
data = pd.concat([y,data_n_2.iloc[:,0:10]],axis=1)
data = pd.melt(data,id_vars="diagnosis",
var_name="features",
value_name='value')
plt.figure(figsize=(10,10))
sns.violinplot(x="features", y="value", hue="diagnosis", data=data,split=True, inner="quart")
plt.xticks(rotation=90)
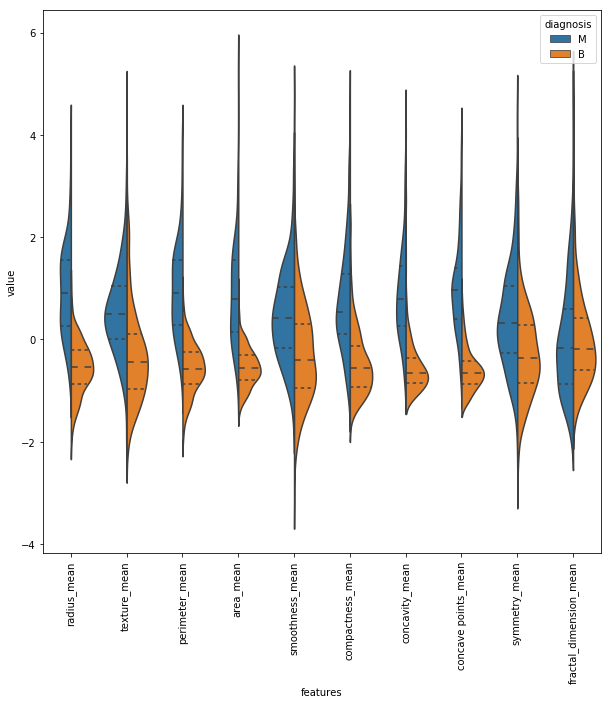
Nhìn vào biểu đồ ta thấy, trong feature texture_mean, đường trung bình của M và B đối xứng với nhau vì vậy feature này được sử dụng tốt cho việc phân loại. Tuy nhiên, với feature fractal_dimension_mean, đường trung bình giữa M và B không đối xứng, vì vậy nó sẽ không cho ta thông tin tốt để phân loại.
# Second ten features
data = pd.concat([y,data_n_2.iloc[:,10:20]],axis=1)
data = pd.melt(data,id_vars="diagnosis",
var_name="features",
value_name='value')
plt.figure(figsize=(10,10))
sns.violinplot(x="features", y="value", hue="diagnosis", data=data,split=True, inner="quart")
plt.xticks(rotation=90)
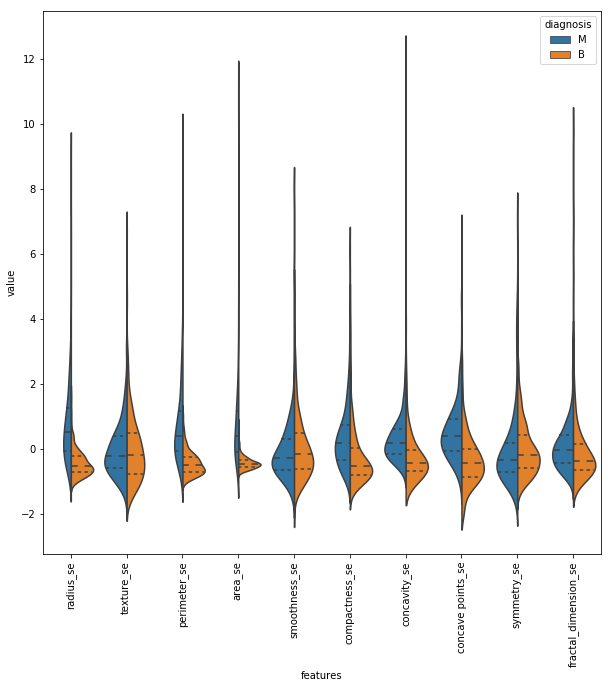
# last ten features
data = pd.concat([y,data_n_2.iloc[:,20:31]],axis=1)
data = pd.melt(data,id_vars="diagnosis",
var_name="features",
value_name='value')
plt.figure(figsize=(10,10))
sns.violinplot(x="features", y="value", hue="diagnosis", data=data,split=True, inner="quart")
plt.xticks(rotation=90)
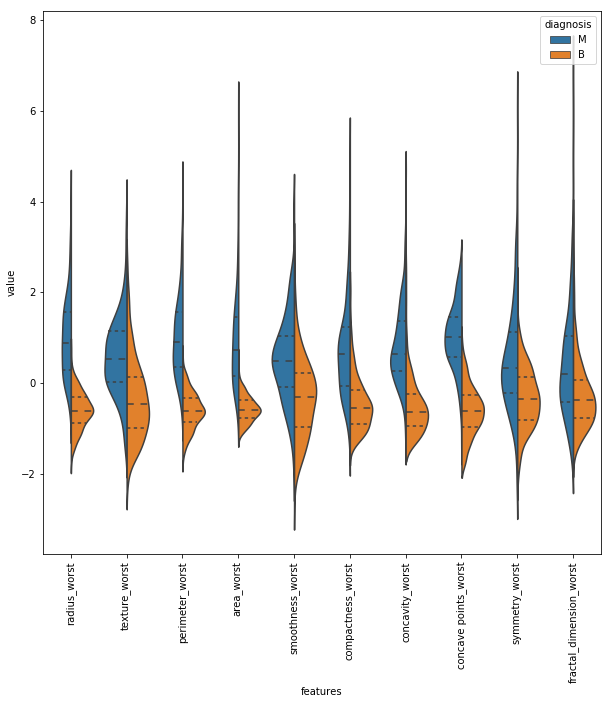
So sánh giữa 2 feature
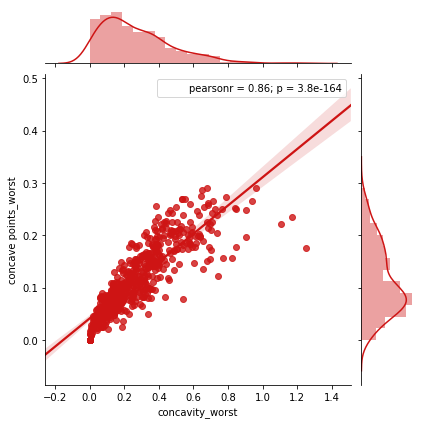
Ta thấy giá trị của concavity_worst và độ lõm của point_worst có vẻ tương đồng với nhau nhưng làm sao chúng ta có thể quyết định liệu chúng có ràng buộc nhau hay không. Thông thường khi feature ràng buộc với nhau, ta có thể loại bỏ 1 trong số chúng.
Để so sánh sâu hơn về 2 feature, ta thực hiện gộp đồ thị. Ta thấy đồ thị ở trên có sự tương đồng lớn với nhau. Giá trị Pearsonr là giá trị tương quan và 1 là giá trị lớn nhất. Vì vậy 0.86 dường như đủ để khẳng định sự tương quan này. Tuy vậy bạn cũng đừng ngộ nhận rằng chúng ta đang chọn ra các feature, chúng ta mới chỉ quan sát đồ thị và nhận xét về chúng.
sns.jointplot(x.loc[:,'concavity_worst'], x.loc[:,'concave points_worst'], kind="regg", color="#ce1414")
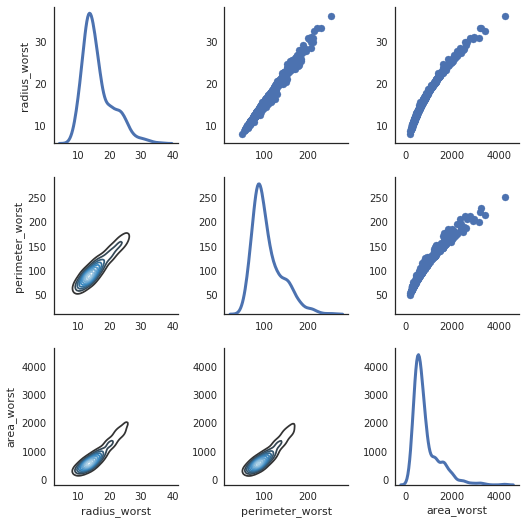
So sánh 3 hoặc nhiều hơn 3 feature
1. Sử dụng PairGrid
Với việc so sánh 3 hoặc nhiều hơn 3 feature, chúng ta có thể sử dụng PairGrid. Dễ thấy rằng radius_worst, perimeter_worst và area_worst có các giá trị tương quan. Chúng ta sẽ sử dụng khám phá này cho việc chọn các feature.
sns.set(style="white")
df = x.loc[:,['radius_worst','perimeter_worst','area_worst']]
g = sns.PairGrid(df, diag_sharey=False)
g.map_lower(sns.kdeplot, cmap="Blues_d")
g.map_upper(plt.scatter)
g.map_diag(sns.kdeplot, lw=3)
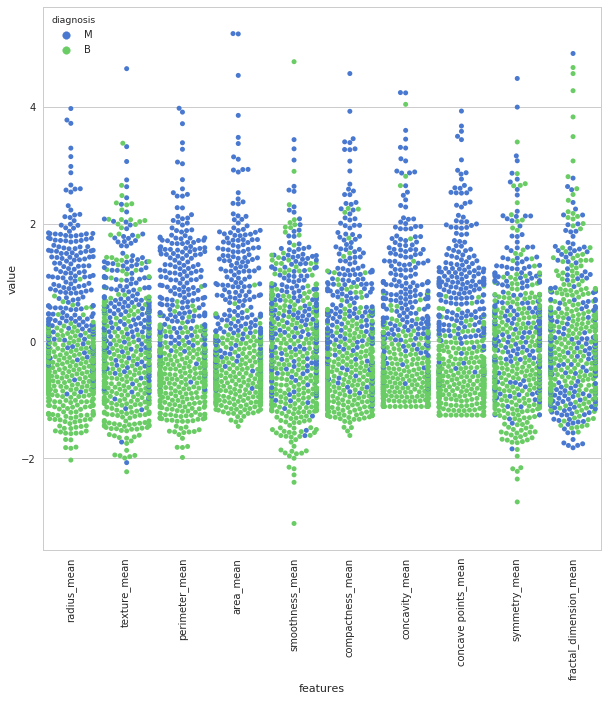
2. Sử dụng SwarmPlot
Hiển thị số lượng M và B theo từng feature, biểu đồ swarm giúp bạn dễ quan sát label.
sns.set(style="whitegrid", palette="muted")
data_dia = y
data = x
data_n_2 = (data - data.mean()) / (data.std()) # standardization
data = pd.concat([y,data_n_2.iloc[:,0:10]],axis=1)
data = pd.melt(data,id_vars="diagnosis",
var_name="features",
value_name='value')
plt.figure(figsize=(10,10))
tic = time.time()
sns.swarmplot(x="features", y="value", hue="diagnosis", data=data)
plt.xticks(rotation=90)
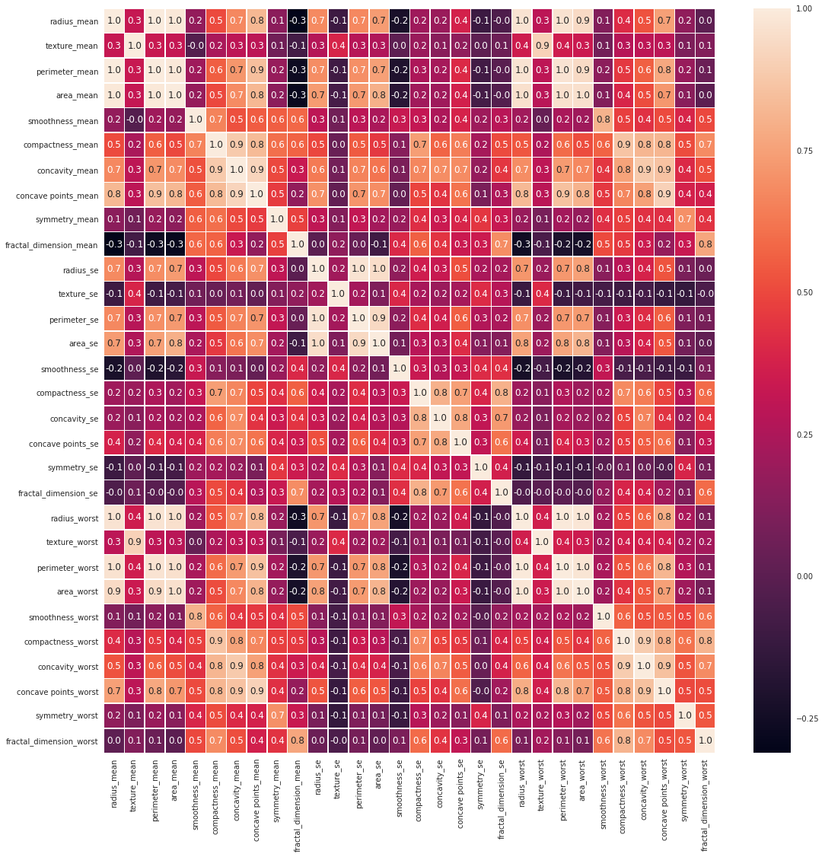
3. Sử dụng heat map Heat map giúp chúng ta có thể quan sát hết được các tương quan giữa các feature.
#correlation map
f,ax = plt.subplots(figsize=(18, 18))
sns.heatmap(x.corr(), annot=True, linewidths=.5, fmt= '.1f',ax=ax)
Trên đây là các cách cơ bản giúp chúng ta quan sát dữ liệu, giúp ích cho việc phân tích và xử lý cũng như việc chọn thuật toán thích hợp cho từng vùng dữ liệu. Trong phần tiếp theo, chúng ta sẽ tiếp tục sử dụng deep learning, xây dựng mạng nơ ron nhằm đánh giá cũng như dự đoán label.
All rights reserved
