
DB-GPT: Ứng dụng LLM trong việc phân tích, truy vấn dữ liệu
I. Giới thiệu
Với sự phát triển nhanh chóng của trí tuệ nhân tạo trong những năm trở lại đây, các mô hình ngôn ngữ lớn (LLM) đang giải quyết nhiều bài toán đa dạng trong nhiều lĩnh vực:
- Trả lời câu hỏi tự nhiên và hỗ trợ khách hàng: LLM có thể xử lý các câu hỏi từ khách hàng, tự động cung cấp câu trả lời hoặc hướng dẫn người dùng qua chatbot, giúp tối ưu hoá trải nghiệm khách hàng.
- Hỗ trợ sáng tạo nội dung: Từ viết bài blog đến kịch bản quảng cáo, LLM giúp tạo ra nội dung sáng tạo dựa trên những yêu cầu cụ thể, tiết kiệm thời gian và công sức.
- Dịch thuật và ngôn ngữ học: LLM giúp dịch các ngôn ngữ và cung cấp văn bản đã dịch với độ chính xác cao, hỗ trợ giao tiếp đa ngôn ngữ hiệu quả.
- Giáo dục và đào tạo: LLM hỗ trợ trong việc tạo ra các chương trình học tự động, trả lời câu hỏi của học sinh, và cung cấp các bài tập được cá nhân hoá, giúp nâng cao trải nghiệm học tập.
Với khả năng hiểu ngữ cảnh một cách sâu sắc, các mô hình ngôn ngữ lớn (LLM) đã giúp đơn giản hóa nhiều bài toán tưởng chừng phức tạp. Tuy nhiên, một hướng phát triển đầy tiềm năng và đang thu hút nhiều sự chú ý là ứng dụng LLM trong phân tích dữ liệu từ nhiều định dạng khác nhau như PDF, Excel, và thậm chí cả cơ sở dữ liệu phức tạp. Khả năng này mở ra triển vọng mới cho việc xử lý và trích xuất thông tin từ khối lượng lớn dữ liệu phi cấu trúc, hứa hẹn sẽ trở thành một xu hướng đột phá trong thời gian tới.
II. DB-GPT
1. DB-GPT là gì?
DB-GPT là một framework mã nguồn mở dành cho phát triển ứng dụng dữ liệu AI với ngôn ngữ AWEL (Agentic Workflow Expression Language) và các tác tử (agents). Mục tiêu của DB-GPT là xây dựng nền tảng hạ tầng cho các mô hình ngôn ngữ lớn, tập trung vào các tính năng kỹ thuật tiên tiến như quản lý đa mô hình (SMMF), tối ưu hóa Text2SQL, sử dụng framework RAG (Retrieval-Augmented Generation) và quản lý quy trình tác tử (AWEL). Nhờ những công nghệ này, DB-GPT giúp đơn giản hóa việc tạo ứng dụng mô hình ngôn ngữ lớn kết hợp dữ liệu, mang đến sự thuận tiện và hiệu quả cao hơn trong các bài toán xử lý dữ liệu.
Chức năng cốt lõi của DB-GPT:
- RAG (Retrieval Augmented Generation): Giúp xây dựng ứng dụng kiến thức với khả năng truy xuất thông tin, là tính năng thực tiễn và cần thiết nhất hiện nay.
- GBI (Generative Business Intelligence): Cung cấp nền tảng trí tuệ dữ liệu, hỗ trợ phân tích báo cáo và đưa ra thông tin chi tiết cho doanh nghiệp.
- Fine-tuning Framework: Cung cấp khung tinh chỉnh mô hình cho các lĩnh vực chuyên biệt, với độ chính xác đạt 82.5% trên bộ dữ liệu Spider.
- Multi-Agents Framework: Hoạt động dựa trên dữ liệu, cho phép các tác tử tự phát triển và thực hiện quyết định liên tục.
- Data Factory: Tập trung vào làm sạch và xử lý dữ liệu đáng tin cậy, đảm bảo dữ liệu chất lượng cho các ứng dụng.
- Data Sources: Hỗ trợ tích hợp nhiều nguồn dữ liệu khác nhau, kết nối liền mạch với các tính năng chính của DB-GPT.
Các đặc điểm chính của DB-GPT:
- Private Domain Q&A & Data Processing: Hỗ trợ xây dựng cơ sở kiến thức, lưu trữ và truy xuất dữ liệu có cấu trúc và phi cấu trúc; hỗ trợ đa dạng định dạng file và plugin tùy chỉnh.
- Multi-Data Source & GBI (Generative Business Intelligence): Cung cấp khả năng tương tác bằng ngôn ngữ tự nhiên với các nguồn dữ liệu như Excel, cơ sở dữ liệu, kho dữ liệu; hỗ trợ tạo báo cáo và tổng hợp thông tin.
- Multi-Agents & Plugins: Tích hợp mô hình Auto-GPT và plugin tùy chỉnh cho nhiều nhiệm vụ, tăng cường khả năng tương tác đa tác vụ.
- Automated Fine-tuning Text2SQL: Hỗ trợ tinh chỉnh tự động chuyển đổi văn bản thành truy vấn SQL, giúp đơn giản hóa quá trình tinh chỉnh.
- SMMF (Service-oriented Multi-model Management Framework): Cung cấp hỗ trợ cho nhiều mô hình ngôn ngữ lớn như LLaMA, ChatGLM, và nhiều mô hình nguồn mở khác.
2. AWEL
AWEL (Agentic Workflow Expression Language) là một ngôn ngữ mô tả quy trình dành riêng cho các tác tử thông minh, được phát triển đặc biệt để hỗ trợ ứng dụng mô hình ngôn ngữ lớn (LLM). Với tính năng đa dạng và linh hoạt, AWEL cho phép nhà phát triển tập trung vào logic nghiệp vụ của các ứng dụng LLM mà không cần lo lắng về các chi tiết phức tạp của mô hình hay môi trường làm việc. AWEL sử dụng kiến trúc API phân tầng, tạo ra một cách tiếp cận dễ dàng và trực quan hơn cho các nhà phát triển khi làm việc với các ứng dụng AI.
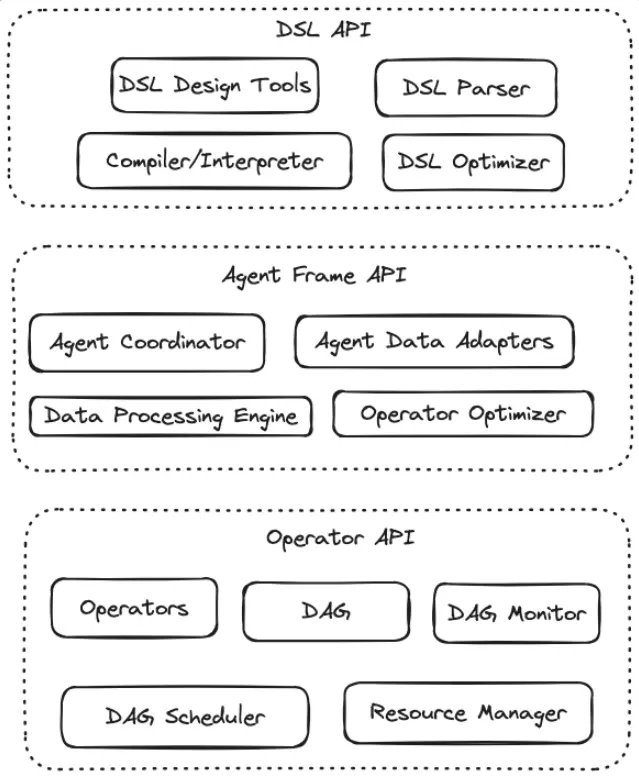
AWEL được chia thành ba cấp độ trong thiết kế, bao gồm lớp vận hành (Operator layer), lớp tác tử (AgentFream layer) và lớp DSL (DSL layer):
- Operator layer: Đây là tầng cơ bản nhất trong quá trình phát triển ứng dụng LLM, bao gồm các tác vụ nhỏ như truy xuất, vector hóa, tương tác với mô hình, và xử lý prompt trong phát triển ứng dụng RAG. Trong các bản phát triển tiếp theo, framework sẽ chuẩn hóa và mở rộng thiết kế của các vận hành này, giúp triển khai nhanh chóng qua các API chuẩn.
- AgentFream layer: Lớp này bao bọc các vận hành và có thể thực hiện các tính toán theo chuỗi dựa trên các vận hành đó. AgentFream hỗ trợ tính toán phân phối với các thao tác chuỗi như lọc, ghép, ánh xạ, và giảm. Các logic tính toán phức tạp hơn cũng sẽ được hỗ trợ trong tương lai.
- DSL layer (Domain-Specific Language Layer): Lớp DSL cung cấp ngôn ngữ cấu trúc chuẩn, giúp hoàn thành các thao tác của AgentFream và vận hành thông qua các câu lệnh DSL. Điều này giúp lập trình xung quanh dữ liệu và mô hình lớn trở nên rõ ràng hơn, giảm sự mơ hồ của ngôn ngữ tự nhiên và giúp việc lập trình ứng dụng dữ liệu trở thành một quy trình nhất quán và đáng tin cậy.
III. Cài đặt DB-GPT
1. Cài đặt bằng docker
Đầu tiên, chúng ta cần pull docker image từ image repository (Eosphoros AI Docker Hub):
docker pull eosphorosai/dbgpt:latest
Việc tải docker image có thể sẽ mất khá nhiều thời gian do dung lượng của nó khá lớn. Sau khi tải xong, chúng ta có thể check xem image đã được pull thành công hay chưa bằng lệnh sau:
# command
docker images | grep "eosphorosai/dbgpt"
Nếu kết quả hiển thị như bên dưới thì bạn đã pull về thành công.
# result
--------------------------------------------------------------------------------------
eosphorosai/dbgpt-allinone latest 349d49726588 27 seconds ago 15.1GB
eosphorosai/dbgpt latest eb3cdc5b4ead About a minute ago 14.5GB
Trong đó, eosphorosai/dbgpt là image cơ bản, chứa các phụ thuộc dự án và cơ sở dữ liệu SQLite. Image eosphorosai/dbgpt-allinone được xây dựng dựa trên eosphorosai/dbgpt và bao gồm thêm cơ sở dữ liệu MySQL.
Chúng ta có thể chạy DB-GPT với nhiều loại model và database khác nhau. Nếu bạn muốn chạy với local LLM, bạn có thể tham khảo tải các mô hình dưới đây (nếu muốn chạy với proxy LLM, bạn có thể bỏ qua bước này)
cd DB-GPT
mkdir models and cd models
# embedding model
git clone https://huggingface.co/GanymedeNil/text2vec-large-chinese
# also you can use m3e-large model, you can choose one of them according to your needs
# git clone https://huggingface.co/moka-ai/m3e-large
# LLM model, if you use openai or Azure or tongyi llm api service, you don't need to download llm model
git clone https://huggingface.co/THUDM/glm-4-9b-chat
Dưới đây là cách chạy DB-GPT với một số loại model và DB phổ biến. Nếu bạn muốn chạy với model và DB khác, có thể tham khảo github DB-GPT tại đây
a. Chạy với Sqlite DB
Để chạy DB-GPT với sqlite DB, chúng ta sử dụng image eosphorosai/dbgpt với command sau:
docker run --ipc host --gpus all -d \
-p 5670:5670 \
-e LOCAL_DB_TYPE=sqlite \
-e LOCAL_DB_PATH=data/default_sqlite.db \
-e LLM_MODEL=glm-4-9b-chat \
-e LANGUAGE=zh \
-v /data/models:/app/models \
--name dbgpt \
eosphorosai/dbgpt
b. Chạy với MySQL DB
Để chạy DB-GPT với MySQL, chúng ta sử dụng image eosphorosai/dbgpt-allinone với command sau:
docker run --ipc host --gpus all -d -p 3306:3306 \
-p 5670:5670 \
-e LOCAL_DB_HOST=127.0.0.1 \
-e LOCAL_DB_PASSWORD=aa123456 \
-e MYSQL_ROOT_PASSWORD=aa123456 \
-e LLM_MODEL=glm-4-9b-chat \
-e LANGUAGE=zh \
-v /data/models:/app/models \
--name db-gpt-allinone \
db-gpt-allinone
c. Chạy với model khác
Ở 2 ví dụ trên, DB-GPT đều chạy với mô hình glm-4-9b-chat. Nếu muốn chạy với mô hình khác như Open AI Proxy, bạn chỉ cần thay đổi các biến môi trường sao cho phù hợp với mô hình đó.
Chẳng hạn khi chạy với Open AI:
docker run --gpus all -d -p 3306:3306 \
-p 5670:5670 \
-e LOCAL_DB_HOST=127.0.0.1 \
-e LOCAL_DB_PASSWORD=aa123456 \
-e MYSQL_ROOT_PASSWORD=aa123456 \
-e LLM_MODEL=proxyllm \
-e PROXY_API_KEY="Your api key" \
-e PROXY_SERVER_URL="https://api.openai.com/v1/chat/completions" \
-e LANGUAGE=zh \
-v /data/models/text2vec-large-chinese:/app/models/text2vec-large-chinese \
--name db-gpt-allinone \
db-gpt-allinone
Chúng ta có thể truy cập vào DB-GPT thông qua đường dẫn: http://localhost:5670
2. Cài đặt bằng source code
Chúng tôi khuyên bạn nên cài đặt bằng docker vì nó sẽ giảm thiểu tỉ lệ sinh ra bug. Tuy nhiên, nếu bạn muốn can thiệp sâu hơn, bạn có thể sử dụng source code để cài đặt.
Đầu tiên, chúng ta clone code từ github:
git clone https://github.com/eosphoros-ai/DB-GPT.git
Tiếp theo, chúng ta cần install các dependencies và dowload embedding model:
pip install -e ".[openai]"
cd DB-GPT
mkdir models and cd models
git clone https://huggingface.co/GanymedeNil/text2vec-large-chinese
Sau đó, ta config các tham số của Open AI proxy model:
# .env
LLM_MODEL=chatgpt_proxyllm
PROXY_API_KEY={your-openai-sk}
PROXY_SERVER_URL=https://api.openai.com/v1/chat/completions
# If you use gpt-4
# PROXYLLM_BACKEND=gpt-4
Cuối cùng, ta chạy DB-GPT thông qua lệnh sau:
python dbgpt/app/dbgpt_server.py
Như vậy, DB-GPT đã được triển khai trên đường dẫn: http://localhost:5670.
IV. Sơ lược về DB-GPT Application.
Ngôn ngữ của DB-GPT Application được để mặc định là tiếng Trung, vì vậy bạn nên chuyển lại về tiếng Anh để dễ dàng sử dụng.
1. Các kịch bản chat
DB-GPT hỗ trợ 6 kịch bản chat khác nhau với từng loại dữ liệu:
- Chat Normal: Đây là chức năng chat cơ bản, giống như việc bạn giao tiếp với ChatGPT thông thường.
- Chat Data: Tạo các cuộc hội thoại với dữ liệu thông qua ngôn ngữ tự nhiên (dữ liệu cần có cấu trúc hoặc bán cấu trúc).
- Chat Excel: Diễn giải và phân tích dữ liệu Excel thông qua hội thoại ngôn ngữ tự nhiên.
- Chat DB: Phân tích hiệu suất cơ sở dữ liệu, tối ưu hóa và thực hiện các tác vụ khác bằng cách giao tiếp trực tiếp với cơ sở dữ liệu.
- Chat Knowledge Base: Chat knowledge Basecung cấp khả năng đặt câu hỏi và trả lời câu hỏi dựa trên kiến thức chuyên ngành riêng, và có thể xây dựng các hệ thống hỏi đáp thông minh, trợ lý đọc và các sản phẩm khác dựa trên công nghệ này knowledge base
- Chat Dashboard: Phân tích và tạo báo cáo thông minh theo ngữ cảnh qua ngôn ngữ tự nhiên, phục vụ các tình huống BI tạo sinh (GBI) trong DB-GPT.
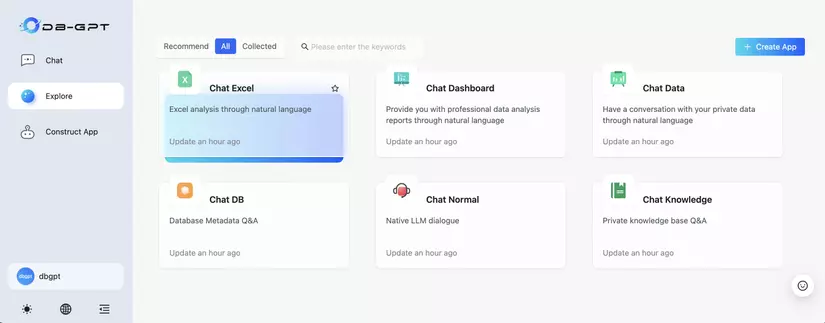
2. Chat App
Giao diện chat của DB-GPT cung cấp các tính năng chính cho hội thoại, hiển thị lịch sử trò chuyện và ứng dụng đang được sử dụng trong cuộc hội thoại. Đồng thời, hộp thoại cũng cung cấp nhiều lựa chọn tham số khác nhau, chẳng hạn như lựa chọn mô hình, điều chỉnh tham số nhiệt độ, tải tệp lên, v.v.
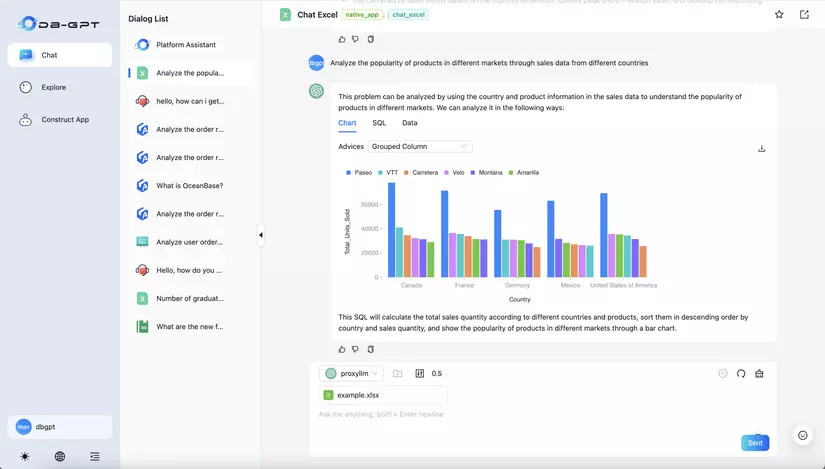
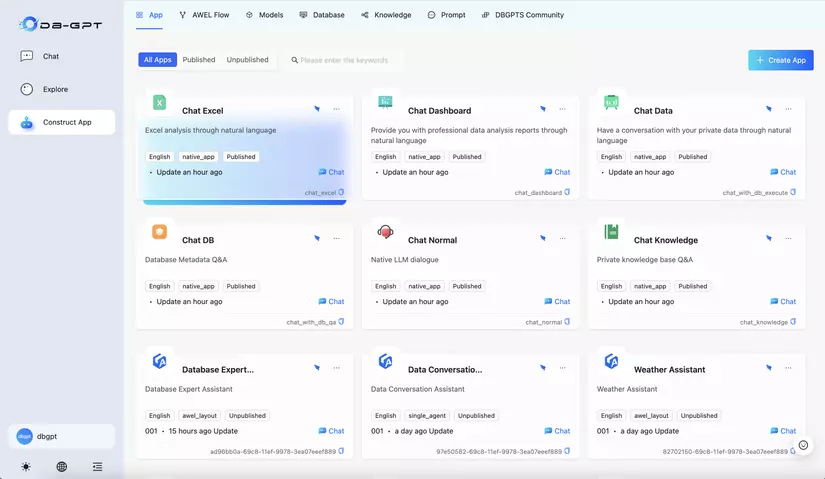
3. App Manage
Đây là nơi sẽ quản lý toàn bộ chat app, AWEL flow, models, database, knowledge, prompts. Bạn có thể dùng các chat app có sẵn trong DB-GPT hoặc có thể tạo ra chat app cho riêng mình với cấu hình mong muốn.
Ví dụ: khi bạn muốn sử dụng kịch bản chat DB, bạn cần tạo ra 1 database trong App Manager. Sau đó bạn có thể sử dụng nó trong chat app "Chat DB".
V. Thử nghiệm và đánh giá
Qua quá trình thử nghiệm, chúng tôi nhận thấy rằng DB-GPT có thể xử lý tốt ở một số dạng data, tuy nhiên phần còn lại vẫn còn gặp nhiều hạn chế. Cụ thể:
Chat DB:
- Mô tả: Giao tiếp với cơ sở dữ liệu và đưa ra các lệnh truy vấn SQL phù hợp.
- Hiệu quả:
- Hiểu được cấu trúc của cơ sở dữ liệu.
- Tạo ra các lệnh SQL khá chính xác để trả lời các câu hỏi.
- Không tự động thực thi SQL, chỉ đưa ra câu lệnh truy vấn.
- Hạn chế: Không hỗ trợ vẽ đồ thị.
- Đánh giá: Khả năng tạo lệnh SQL tốt, nhưng chưa có tính năng tự động chạy truy vấn để trả về kết quả.
Chat Data:
- Mô tả: Tương tự như Chat DB, nhưng có khả năng chạy lệnh SQL và trả về kết quả.
- Hiệu quả:
- Hiểu được cấu trúc cơ sở dữ liệu.
- Tạo lệnh SQL tự động và chạy truy vấn để trả về kết quả trực tiếp.
- Hạn chế: Không có tính năng vẽ đồ thị.
- Đánh giá: Tạo lệnh SQL không tốt bằng Chat DB, nhưng tự động thực thi truy vấn để trả về kết quả là lợi thế.
Chat Excel:
- Mô tả: Hỗ trợ người dùng truyền trực tiếp file Excel và thực hiện các truy vấn.
- Hiệu quả:
- Hiểu nội dung file Excel.
- Trả về cả lệnh SQL và kết quả truy vấn (nếu được yêu cầu).
- Hạn chế: Chưa hỗ trợ vẽ đồ thị thống kê, nhiều lỗi xuất hiện trong quá trình sử dụng.
- Đánh giá: Độ ổn định chưa cao, kết quả có thể bị lỗi.
Chat Knowledge:
- Mô tả: Yêu cầu người dùng tạo đối tượng Knowledge (chứa dữ liệu) để kết nối và thực hiện các câu hỏi trên dữ liệu đó.
- Hiệu quả:
- CSV: Hoạt động tương tự như Chat Excel nhưng kém hiệu quả.
- PDF và PowerPoint: Hiểu nội dung file, nhưng câu trả lời chưa sát nội dung.
- Raw Text và Word: Hiểu nội dung và trả lời khá tốt.
- Hạn chế:
- Chỉ xử lý được 5 mẫu dữ liệu từ mỗi file, bỏ sót các mẫu phía sau.
- Đôi khi trả lời không phù hợp với nội dung, hoặc cho rằng “không đủ dữ kiện” dù dữ liệu đầy đủ.
- Đánh giá: Hiệu quả không ổn định, cần cải thiện trong khả năng xử lý và hiểu dữ liệu đầy đủ.
Đánh giá trên chỉ mang tính chất tham khảo vì nó được đánh giá chủ quan dựa trên bộ data của chúng tôi.
VI. Tổng kết
DB-GPT mang đến một bộ công cụ mạnh mẽ cho phép người dùng khai thác dữ liệu từ nhiều nguồn khác nhau, thực hiện truy vấn, phân tích dữ liệu và cung cấp các câu trả lời dựa trên ngữ cảnh một cách trực quan. Với các tính năng đa dạng như Chat DB cho truy vấn cơ sở dữ liệu, Chat Excel để phân tích file, và Chat Knowledge để làm việc với các tài liệu như PDF hay PowerPoint, .... DB-GPT là một bước tiến trong việc ứng dụng các mô hình ngôn ngữ lớn vào quản lý và phân tích dữ liệu.
Bên cạnh DB-GPT, còn nhiều phương pháp khác giúp khai thác dữ liệu như các hệ thống phân tích truyền thống, các công cụ BI hoặc các framework AI khác. Tuy nhiên, DB-GPT đang thể hiện tiềm năng của các mô hình ngôn ngữ lớn (LLM) trong việc đơn giản hóa các quy trình phức tạp, giảm thiểu công sức và cung cấp kết quả nhanh chóng thông qua hội thoại tự nhiên.
Xu hướng hiện nay đang cho thấy LLM sẽ ngày càng được ứng dụng rộng rãi trong lĩnh vực phân tích dữ liệu. Với khả năng hiểu ngữ cảnh và diễn đạt tự nhiên, LLM giúp người dùng xử lý dữ liệu một cách thông minh và hiệu quả. Điều này cho phép các doanh nghiệp tận dụng tối đa dữ liệu sẵn có để đưa ra các quyết định sáng suốt, tối ưu hóa quy trình và nâng cao trải nghiệm người dùng.
VII. Tài liệu tham khảo
All rights reserved
