Database Replication: Đừng Để Database Của Bạn Là "Single Point of Failure"
chào anh em nha. đến hẹn lại lên !!!

lét gét sờ ta tịt
Trong các hệ thống nhỏ, một Database duy nhất là đủ. Nhưng khi hệ thống lớn dần (như lúc anh em mình Scale-up cho Hasaki chẳng hạn), việc chỉ có một DB duy nhất sẽ dẫn đến hai thảm họa: Bottleneck (nghẽn cổ chai) và SPOF (Single Point of Failure).
Giải pháp? Database Replication. Hôm nay chúng ta sẽ cùng mổ xẻ các mô hình Master-Slave và Master-Master - những "kiến trúc thượng tầng" mà mọi Backend Engineer đều phải nằm lòng.
1. Mô hình Master-Slave (Leader-Follower)
Đây là mô hình "quốc dân". Ý tưởng rất đơn giản: Chia để trị.
- Master (Leader): Chuyên trách việc Write (INSERT, UPDATE, DELETE). Mọi thay đổi dữ liệu đều phải đi qua đây.
- Slave (Follower/Replica): Chuyên trách việc Read (SELECT). Slave sẽ đồng bộ dữ liệu từ Master về.
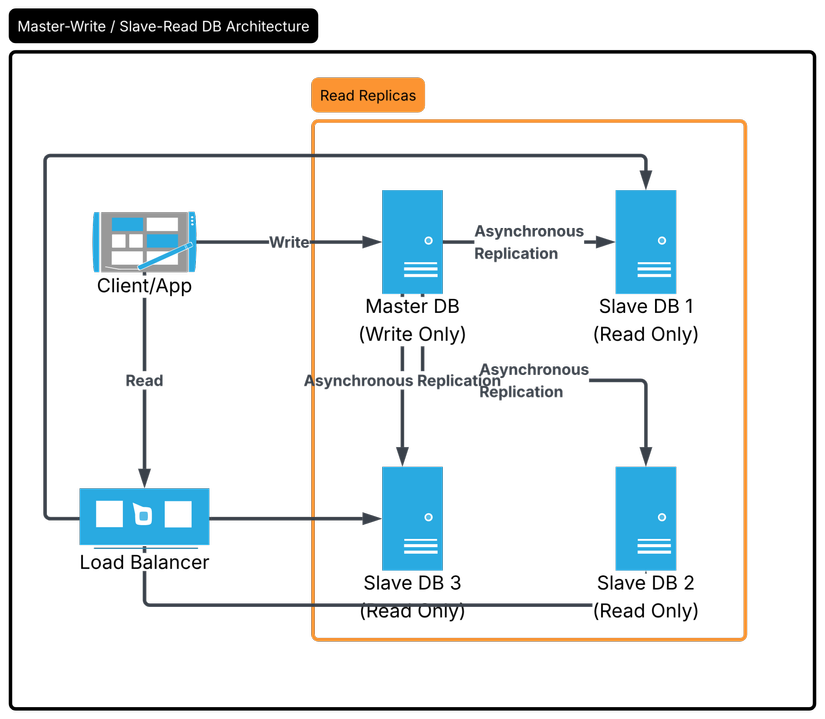
Tại sao lại dùng mô hình này?
- Tăng hiệu năng (Performance): Tách biệt luồng Đọc/Ghi. Anh em có thể thoải mái Scale số lượng Slave để phục vụ hàng triệu query SELECT mà không làm chậm việc Ghi.
- Dự phòng (Redundancy): Nếu một Slave "ngỏm", hệ thống vẫn sống. Nếu Master "ngỏm", chúng ta có thể promote một Slave lên làm Master mới.
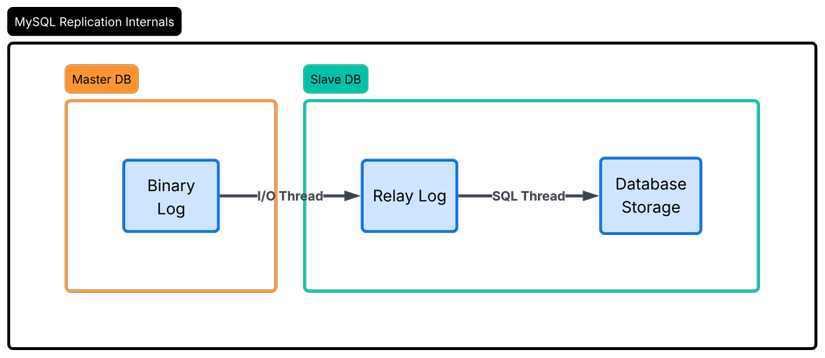
2. Dưới nắp ca-pô: Quá trình Replication diễn ra thế nào?
Làm sao Slave biết Master vừa có dữ liệu mới? Nó không dùng "tâm linh" đâu, nó dùng Log.
- Binary Log (Binlog): Khi Master ghi dữ liệu, nó lưu vào một file log.
- I/O Thread: Slave sẽ kết nối tới Master và đọc file Binlog này về, lưu vào Relay Log cục bộ.
- SQL Thread: Slave đọc Relay Log và "thực thi lại" (replay) các câu lệnh đó trên database của chính nó.
3. Master-Master (Multi-Master) - Cấp độ "Hardcore"
Nếu Master-Slave chỉ giải quyết được bài toán Read-heavy, thì Master-Master sinh ra để giải quyết bài toán Write-heavy và High Availability tuyệt đối.
Trong mô hình này, cả hai (hoặc nhiều) Node đều có quyền Read và Write. Dữ liệu ghi vào Node A sẽ được đồng bộ sang Node B và ngược lại.
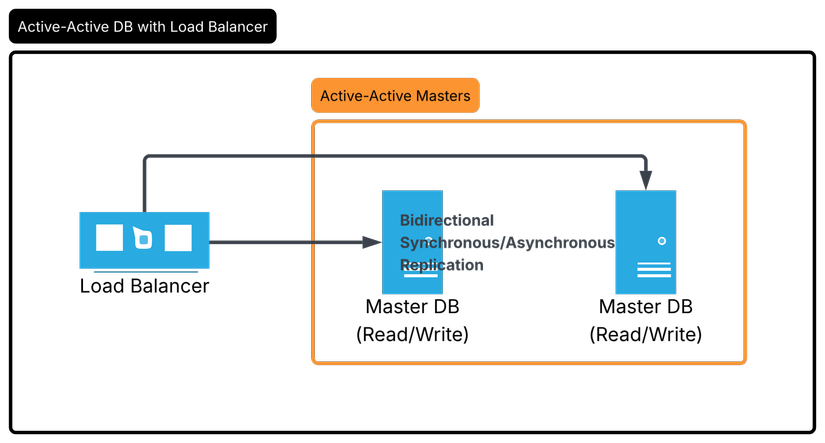
Cẩn thận với "Conflict"! Đây là phần "khoai" nhất. Nếu hai User cùng sửa một bản ghi ở hai Master khác nhau cùng lúc, hệ thống sẽ phải đối mặt với Conflict Resolution. Đây là lý do Master-Master phức tạp hơn Master-Slave rất nhiều lần.
4. Khi nào nên dùng cái nào?
| Đặc điểm | Master-Slave | Master-Master |
|---|---|---|
| Độ phức tạp | Thấp | Cao |
| Khả năng Scale Write | Không (Chỉ có 1 Master) | Có (Nhiều Master) |
| Tính sẵn sàng (HA) | Tốt (Cần Failover manual/auto) | Tuyệt vời (Active-Active) |
| Conflict dữ liệu | Không bao giờ | Rất dễ xảy ra |
Kết luận
Việc nắm vững Master-Slave hay Master-Master không chỉ giúp anh em vượt qua các buổi phỏng vấn "căng não" mà còn là chìa khóa để xây dựng các hệ thống Scalable và Resilient.
Lời khuyên cho anh em: Hãy bắt đầu với Master-Slave + Caching (Redis) trước khi nghĩ đến Master-Master để tránh "over-engineering".
Anh em đã từng gặp case "Slave lag" kinh điển chưa? Cùng thảo luận dưới phần comment nhé!
All rights reserved
