Dagster Cơ Bản: Build Một Data Pipeline Đơn Giản Với Dagster
Bài đăng này đã không được cập nhật trong 2 năm
Lời mở đầu
Trong bài trước mình đã giới thiệu với mọi người về Dagster, nó là gì, dùng để làm gì. Trong bài này mình sẽ hướng dẫn các bạn làm một project cơ bản với Dagster, cụ thể là build một data pipeline đơn giản. Ai quên thì kệ 🤪!

I. Cài đặt thư viện và các thứ cần thiết
Để cài Dagster, bạn cần phải cài đặt Python bản 3.8 trở lên, sau đó có thể cài Dagster rất dễ dàng thông qua pip. Mở termianl và chạy câu lệnh sau:
pip install dagster dagster-webserver dagit
Vậy là bạn đã có thể cài Dagster với chỉ thao tác đơn giản. Bạn cũng có thể cài Dagster thông qua source của nó, cơ mà cái nào đơn giản thì làm  )
)
II. Định nghĩa các asset
Trong bài trước, chúng ta đã tìm hiểu asset là gì, tuy nhiên với một cách khá là lý thuyết. Hôm nay mình sẽ cho các bạn thấy asset thực sự là gì, cách implement nó trong code và trực quan của nó trông ra sao.
Như đã nói ở bài trước, chúng ta sẽ tạo một project cơ bản để build một data pipeline với các giai đoạn:
- Downloads top 10 stories từ HackerNews
- Tiến hành lọc và chọn ra các field cần thiết
- Ghi kết quả thu được vào Pandas Dataframe rồi cuối cùng lưu xuống file .csv
Mình đang sử dụng Ubuntu. Tạo một folder tên gì cũng được ) ở đây mình đặt tên là hello-dagster, di chuyển vào folder và tạo một file Python, ở đây mình đặt là hello-dagster.py.
mkdir hello-dagster
cd hello-dagster
touch hello-dagster.py
Code trong file hello-dagster.py:
import json
import requests
import pandas as pd
from dagster import AssetExecutionContext, MetadataValue, asset
@asset
def hackernews_top_story_ids():
"""
Get top 10 stories from the HackerNews top stories endpoint.
API Docs: https://github.com/HackerNews/API#new-top-and-best-stories.
"""
top_story_ids = requests.get("https://hacker-news.firebaseio.com/v0/topstories.json").json()
with open("hackernews_top_story_ids.json", "w") as f:
json.dump(top_story_ids[:10], f)
# asset dependencies can be inferred from parameter names
@asset(deps=[hackernews_top_story_ids])
def hackernews_top_stories(context: AssetExecutionContext):
"""Get items based on story ids from the HackerNews items endpoint."""
with open("hackernews_top_story_ids.json", "r") as f:
hackernews_top_story_ids = json.load(f)
results = []
for item_id in hackernews_top_story_ids:
item = requests.get(f"https://hacker-news.firebaseio.com/v0/item/{item_id}.json").json()
results.append(item)
df = pd.DataFrame(results)
df.to_csv("hackernews_top_stories.csv")
# recorded metadata can be customized
metadata = {
"num_records": len(df),
"preview": MetadataValue.md(df[["title", "by", "url"]].to_markdown()),
}
context.add_output_metadata(metadata=metadata)
Ở đoạn code trên, chúng ta define 2 function, function đầu tiên là hackernews_top_story_ids có nhiệm vụ fetch data (ID của các story) từ API của Hacker News, sau đó lưu vào file dưới dạng JSON, sau đó function thứ 2 là hackernews_top_stories sẽ đọc dữ liệu từ file JSON vừa lưu, sau đó tiếp tục collect data (dựa trên iD vừa thu được) và lưu vào một Pandas Dataframe. Đoạn code chức năng trong 2 hàm cũng dễ hiểu nên k cần giải thích gì nhỉ ))
Và bước quan trọng tiếp theo là thêm decorator @asset cho mỗi function. Và từ đó chúng ta đã có 2 assets lần lượt là hackernews_top_story_ids và hackernews_top_stoies. Ở decorator của function hackernews_top_stories có tham số deps, có nghĩa là asset hackernews_top_stoies phụ thuộc vào asset hackernews_top_story_ids (phải có ID của story mới lấy được story và các thông tin khác). Ô cê cũng dễ nhỉ 😁
III. Chạy UI cho trực quan thôi ~~
Từ từ, hãy đảm bảo bạn đã install cả Pandas nữa ))
pip install pandas
Ô cê rồi, di chuyển đển thư mục chứa hello-dagster.py và chạy lệnh sau:
dagster dev -f hello-dagster.py
Lệnh này sẽ khởi động web server đến host Dagster's UI. Vậy là chúng ta đã thành công khởi động Dagster UI. Mặc định sẽ chạy ở cổng 3000 (có thể đổi cổng bằng option -p khi chạy command). Truy cập vào http://localhost:3000/ và web server sẽ hiển thị.

Và các bạn đã có thể thấy được UI của Dagster với 2 asset được hiển thị. Mũi tên từ hackernews_top_story_ids đến hackernews_top_stoies Bấm vào nút Materialize All là các bạn có thể chạy thành công pipeline rồi. Data sẽ được collect về và lưu vào file JSON.
Nhưng vẫn còn một thứ khá hay ho, đó là Metadata. Thông tin của asset sẽ được lưu trong metadata. Ở trong hàm hackernews_top_stories ta đã định nghĩa metadata và lưu các thông tin cơ bản của asset trong đó. Ở webserver, ta có thể truy cập và xem thông tin metadata bằng cách click vào asset, sau đó click vào [Show Markdown] ở phần Materialization in Last Run
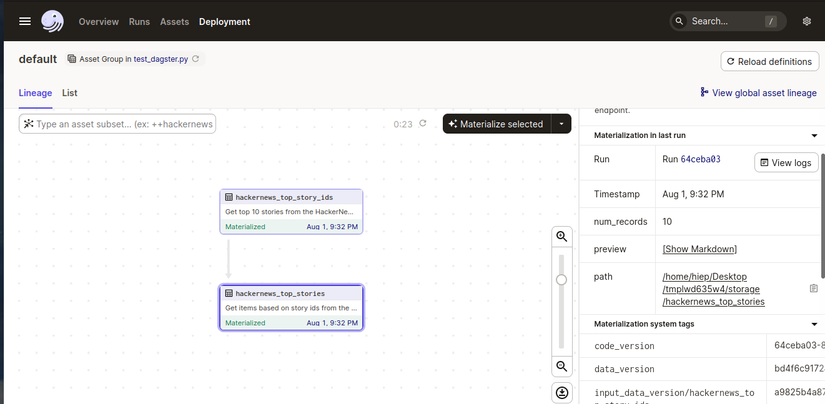
Và kết quả sẽ hiển thị như sau:

Lời kết
Ô cê vậy là mình đã hướng dẫn các bạn build và chạy một cái pipeline đơn giản đầu tiên với Dagster. Những bài sau tiếp tục là kiến thức với Dagster nhé. Cảm ơn mọi người đã đọc!
Reference
All rights reserved
