Crawl hết ảnh trên instagram của một user với Python requests.
Bài đăng này đã không được cập nhật trong 5 năm
Giới thiệu
Bài viết hướng dẫn các bạn mới học cú pháp python có thể sử dụng thư viện requests của python để download ảnh của một tài khoản Instagram một cách đơn giản .
Chuẩn bị
cài đặt thư viện requests : pip install requests
Phân tích
Đầu tiên, chúng ta truy cập vào page của user cần crawl ảnh
F12 -> network , dễ dàng tìm được api để lấy ảnh của instagram
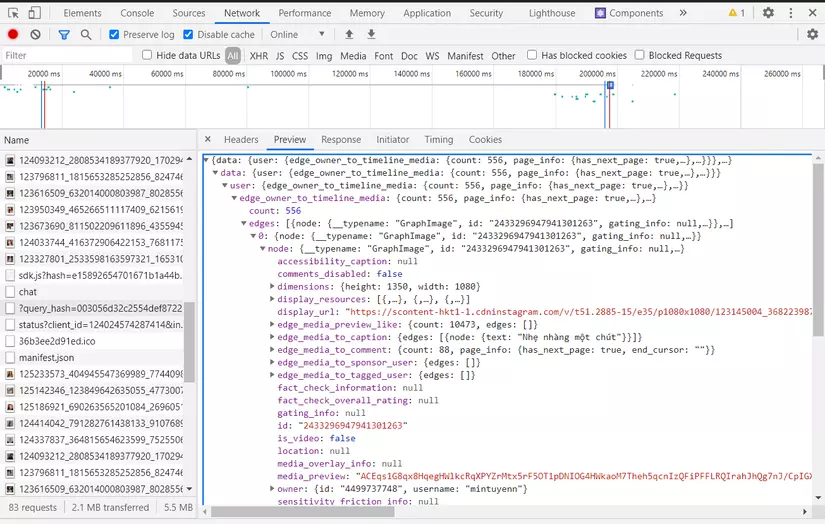
https://www.instagram.com/graphql/query/?query_hash=003056d32c2554def87228bc3fd9668a&variables=%7B%22id%22%3A%224499737748%22%2C%22first%22%3A12%2C%22after%22%3A%22QVFEU0wtaE15VUNGLUd5dXNKR0FHbWx2UmlKS0ZlcDZBVXpFNkdTeXhycFN4SHVhVWJwZzNsTld0cU1xS1RLa1huT2w0X0dnS0tLWnVfUVlsNU5JOTJKRw%3D%3D%22%7D
api có dạng:
https://www.instagram.com/graphql/query/?query_hash=003056d32c2554def87228bc3fd9668a&variables={"id":"4499737748","first":12,"after":"QVFEX0l4TElsblNiSklTSDJaXzZsLUE3ajlvTE44UktYR2lPNm1SOWtRWmR2d21VZWJNUEJKdHVXU3hIOGNDS2FKQWNhdVBaZk5wZGpmMGRkTG1rZTV6Tg=="}
first: số ảnh sẽ lấy bắt đầu từ after.
Với after = "" chúng ta có được 12 ảnh đầu tiên (after = end_cursor của requests trước nó)
 Vậy quá trình crawl của chúng ta sẽ là
request api đầu tiên -> Crawl ảnh, end_cursor, kiểm tra còn trang phía sau không? -> lại gửi api với end_cursor ở lần gọi api trước nếu còn.
Vậy quá trình crawl của chúng ta sẽ là
request api đầu tiên -> Crawl ảnh, end_cursor, kiểm tra còn trang phía sau không? -> lại gửi api với end_cursor ở lần gọi api trước nếu còn.
quá trình Crawl ảnh : Sử dụng kết quả từ requests api -> chuyển sang json -> check xem bài viết là ảnh hay video->Check xem có gồm các ảnh khác không -> lấy các url ảnh
nextLink = 'https://www.instagram.com/graphql/query/?query_hash=003056d32c2554def87228bc3fd9668a&variables={"id":"'+id+'","first":12,"after":"'+end+'"}'
res = r.get(nextLink).json()
edges = res['data']['user']['edge_owner_to_timeline_media']['edges']
for e in edges:
is_video = e['node']['is_video']
if(is_video is False):
link.append(e['node']['display_url'])
if "edge_sidecar_to_children" in e['node']:
ne = e['node']['edge_sidecar_to_children']['edges']
for nee in ne:
is_video = nee['node']['is_video']
if(is_video is False):
link.append(nee['node']['display_url'])
Kiểm tra có trang tiếp theo hay không và lấy end_cursor:
end = res['data']['user']['edge_owner_to_timeline_media']['page_info']['end_cursor']
check = res['data']['user']['edge_owner_to_timeline_media']['page_info']['has_next_page']
Cuối cùng, tạo thư mục mới và tải ảnh:
current_path = os.getcwd()
try: os.mkdir(current_path + "\\"+id+"\\")
except:pass
for l in link:
file_name = str(l).split('/')[-1].split('?')[0]
with open(id+'/'+ file_name, "wb") as file:
response = r.get(l)
file.write(response.content)
file.close()
Full Code :
Bạn có thể tải source code về, thay id bằng id tìm được trong api để bắt đầu tải ảnh.
import requests as r
import os
id = '3762891297'
current_path = os.getcwd()
try: os.mkdir(current_path + "\\"+id+"\\")
except:pass
linkStart = 'https://www.instagram.com/graphql/query/?query_hash=003056d32c2554def87228bc3fd9668a&variables={"id":"'+id+'","first":12,"after":""}'
print(linkStart)
nextLink= ''
firstres = r.get(linkStart).json()
check = firstres['data']['user']['edge_owner_to_timeline_media']['page_info']['has_next_page']
end = firstres['data']['user']['edge_owner_to_timeline_media']['page_info']['end_cursor']
# while(check != False):
link = []
while(check != False):
nextLink = 'https://www.instagram.com/graphql/query/?query_hash=003056d32c2554def87228bc3fd9668a&variables={"id":"'+id+'","first":12,"after":"'+end+'"}'
res = r.get(nextLink).json()
edges = res['data']['user']['edge_owner_to_timeline_media']['edges']
for e in edges:
is_video = e['node']['is_video']
if(is_video is False):
link.append(e['node']['display_url'])
if "edge_sidecar_to_children" in e['node']:
ne = e['node']['edge_sidecar_to_children']['edges']
for nee in ne:
is_video = nee['node']['is_video']
if(is_video is False):
link.append(nee['node']['display_url'])
end = res['data']['user']['edge_owner_to_timeline_media']['page_info']['end_cursor']
check = res['data']['user']['edge_owner_to_timeline_media']['page_info']['has_next_page']
print(len(link))
for l in link:
file_name = str(l).split('/')[-1].split('?')[0]
with open(id+'/'+ file_name, "wb") as file:
response = r.get(l)
file.write(response.content)
file.close()
link = []
if(check == False): break
p/s: code được viết một cách thô sơ nhất, khuyến khích sửa lại để clean hơn.
All rights reserved
