Crawl dữ liệu trên trang chuyencuadev.com
Bài đăng này đã không được cập nhật trong 4 năm
Crawl dữ liệu trên trang chuyencuadev
Vô tình đọc được bài viết trên viblo nên biết được trang này. Mình liền nảy sinh ý định xấu xa, lấy toàn bộ dữ liệu mang về nhà cất.
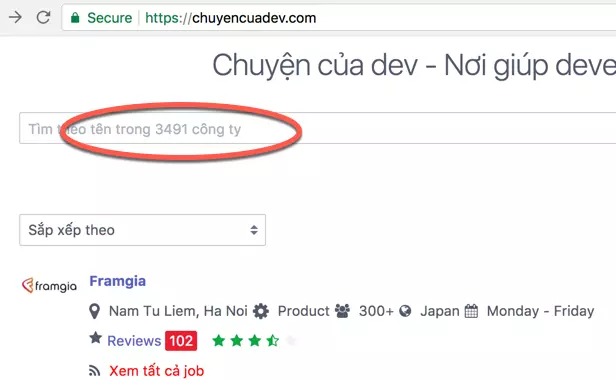
Dữ liệu thì cũng không có gì ngoài danh sách các công ty IT ở VN (Khoảng ~ 3400). 
Mình cũng chẳng biết lấy về làm gì nữa. Chắc là để build một cái tương tự. =))
Chuẩn bị
Để lấy được thì cũng phải chuẩn bị một vài cái trước khi lấy chứ nhỉ.
1. Yêu cầu
Yêu cầu thì đơn giản rồi. Lấy danh sách 3491 công ty từ trang chuyencuadev
2. Kiểm tra hàng họ
Check một hồi chả biết là họ đang dùng cái quỉ gì để làm được cái web này nữa. =))
Cơ mà thấy một nút Xem thêm to bự chảng gần cuối trang. Mừng thấy mẹ. Nhấn thử xem nó có cái gì.
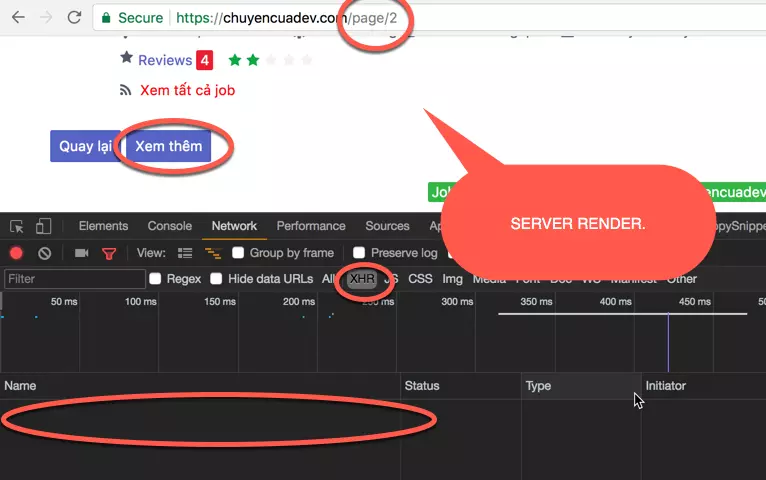
Buồn thối ruột vì họ dùng server render, không phải XHR request. Vậy là không vui rồi. Vì lúc này mình chẳng chôm chỉa được dữ liệu có cấu trúc dạng JSON hoặc XML gì đó.
Lúc này mình phải nghĩ đến việc parse html rồi. Nhìn quanh quẩn thì thấy trên domain có cái /page/2.
Ồ. Có thể dùng được rồi. Bắt tay vào làm thôi.
3. Lựa chọn công cụ, ngôn ngữ.
python hoặc nodejs
Mình khoái nodejs hơn nên quyết định chọn nodejs cho game này.
Phân tích
Cấu trúc
Chẳng biết cấu trúc của cái nồi này ra sao, nên phải mò một lúc. Mình thấy họ phân trang, mỗi trang có n công ty. Mà cụ thể là:
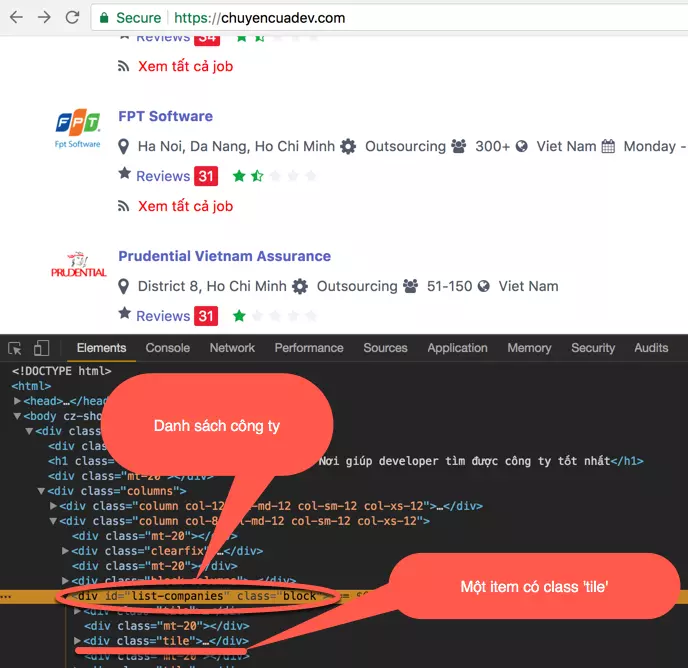
À, có cái list-companies và trong đó có nhiều items tile. Hehe Bao nhiêu item đây.
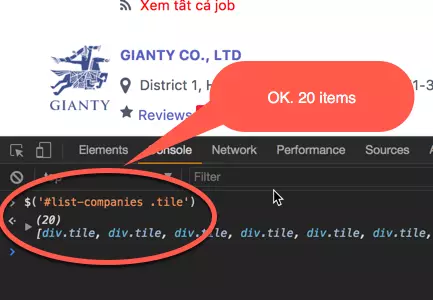
-> Có 3491 / 20 ~ 175 pages
Chốt hạ có 175 pages cần khai thác.
Tức là mình sẽ có một vòng for chạy từ 0 đến 174 và parse dữ liệu.
Tạm dừng ở đây đã.
Phân tích sâu hơn.
Mình có 175 lần lặp, mỗi lần sẽ parse data để lấy dữ liệu. Vậy thì hàm parse đó sẽ làm gì?
- Get
htmltừhttps://chuyencuadev.com/page/${i} - Dùng DOM Parser hoặc cái gì đó giống jQuery để có thể động đến các thẻ
htmlmột cách nhanh nhất. Để đó, search sau. - Xác định đối tượng
list-companies
#list-companies
.tile
.tile-icon img src (logo link)
.tile-content
.tile-title [0] => Company Name & Review Link
a href (review link)
text (company name)
.tile-title [1] => Info (Location, type, size, country, working time)
icon
text (Info - Repeat 5 times)
.tile-title [2] => Reviews (count, star)
a>span text => count
>span
i*5 (i | i.none)
- Define Company Object (Sau khi đã xác định được các thành phần của một đối tượng)
{
id: ObjectId,
name: String,
reviewLink: String,
logo: String,
location: String,
type: String,
country: String,
workingTime: String,
reviewCount: Number,
star: Number,
}
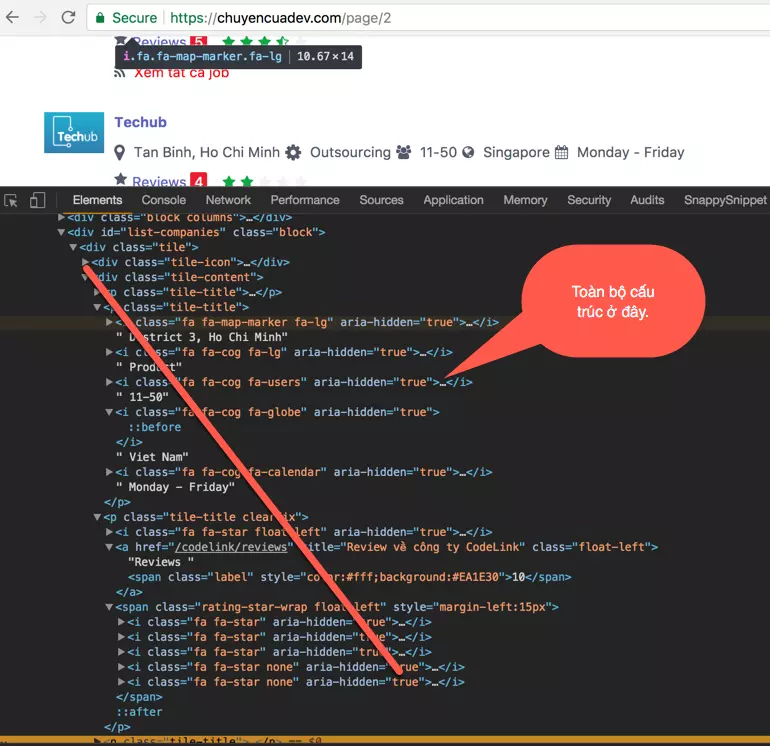
Chết cha. Toàn bộ chỉ có thế. Code thôi.
Code
Create Project
mkdir -p ~/Project/crawler/crawl-companies
Packages
yarn add mongoose connect-mongo moment lodash request request-promise cheerio
Một vài thư viện mà mình nghĩ là mình sẽ dùng. Cơ mà chắc chỉ dùng mongoose, connect-mongo, request-promise, cheerio thôi. Còn moment và lodash thì mình chưa biết sẽ làm gì với nó. Cơ mà trong đầu nghĩ là sẽ dùng. =))
cheerio => jQuery basic for nodejs.
index.js
Thử code cái đã. 
const mongoose = require('mongoose')
const request = require('request-promise')
const cheerio = require('cheerio')
const URL = 'https://chuyencuadev.com/'
const companyCount = 3491 // Cái này là mình thấy trên trang này nó ghi vậy. =))
const pageSize = 20 // Đã test. :)
const pageCount = parseInt(companyCount / pageSize)
/**
* Get content for each page
*
* @param {*} uri (Ex: ${URL}page/2)
*/
const getPageContent = (uri) => {
const options = {
uri,
headers: {
'User-Agent': 'Request-Promise'
},
transform: (body) => {
return cheerio.load(body)
}
}
return request(options)
}
getPageContent(`${URL}page/2`).then($ => {
console.log(`Tile > `, $('title').text())
})
Well done! Ta có output ưng ý.
console.log(`Tile > `, $('title').text())
hmmm... Cùng thử lấy ra list-companies như mình mô tả ở trên nào.
/**
* Parse html to companies
*
* @param {*} $
*/
const html2Companies = ($) => {
const companies = []
$('#list-companies .tile').each((_, c) => {
console.log($(c).html())
})
return companies
}
-> Tuyệt cú mèo. Mọi thứ đúng như những gì mình làm với jQuery trên client. Vậy thì cứ thế mà chiến tiếp thôi.
Mình sẽ tiến hành parse list of companies
/**
* Parse html to companies
*
* @param {*} $
*/
const html2Companies = ($) => {
const companies = []
$('#list-companies .tile').each((_, c) => {
companies.push(html2Company($(c)))
})
return companies
}
Còn đây là parse từng company Object
/**
* Parse html to company Object
*
* @param {*} $
*/
const html2Company = ($) => {
// logo
const logo = $.find('.tile-icon img').attr('data-original') // Lúc đầu mình tưởng là src, nhưng không, họ dùng data-original sau đó dùng jquery để chuyển sang src. Thôi thì cái nào cuũng được =))
const cName = $.find('.tile-content .tile-title:nth-child(1) a')
const name = cName.find('span').text()
const reviewLink = cName.attr('href')
$.find('.tile-content .tile-title:nth-child(2) i').replaceWith('|') // Hơi độc. Cấu trúc của họ là <i> text <i> text ... Mình phải replace thẻ `i` thành separator `|`
const details = $.find('.tile-content .tile-title:nth-child(2)')
.html().split('|').map(d => d.replace(/^\s+/, '')) // Sau đó split về mảng và replace first `\s` character
const reviews = $.find('.tile-content .tile-title:nth-child(3)')
const reviewCount = reviews.find('a>span').text() // reviewCount
const star = reviews.find('>span i:not(.none)').length // Những cái nào không `none` thì nó là số lượng star được voted.
return {
name,
reviewLink,
logo,
location: details[1],
type: details[2],
size: details[3],
country: details[4],
reviewCount,
star,
}
}
Và response theo ý muốn...
[ { name: 'CodeLink',
reviewLink: '/codelink/reviews',
logo: 'https://cdn.itviec.com/system/production/employers/logos/3074/codelink-logo-170-151.png?1476957849',
location: 'District 3, Ho Chi Minh',
type: 'Product',
size: '11-50',
country: 'Viet Nam',
reviewCount: '10',
star: 3 },
...
]
Cũng gọi là chim ưng với kết quả này. Mình bắt tay làm tới. Quất thẳng 172 cái pages và lưu vào trong mongo-db
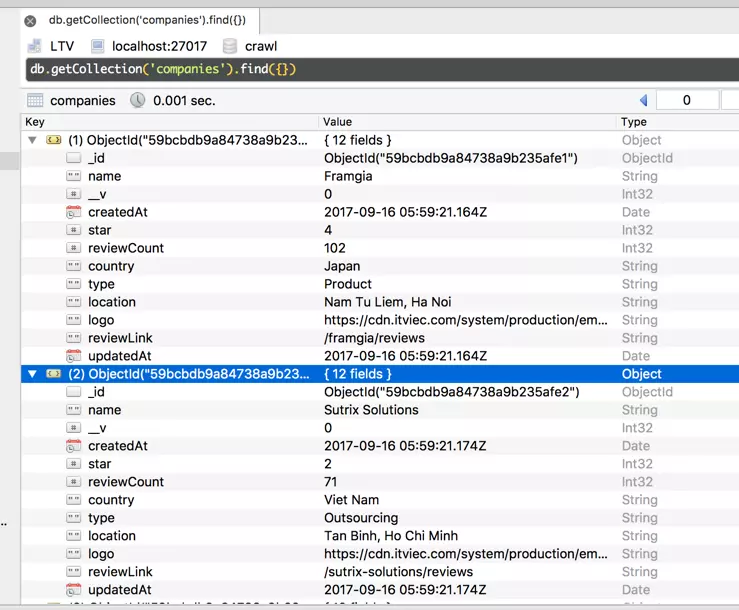
Define DB & Schema
Mình hơi màu mè tẹo. Tạo hẳn cái Schema cho nó vui. models/Company.js
const mongoose = require('mongoose')
const Schema = mongoose.Schema
const companySchema = new Schema({
name: String,
reviewLink: String,
logo: String,
location: String,
type: String,
country: String,
workingTime: String,
reviewCount: Number,
star: Number,
}, {
timestamps: true
})
const Company = mongoose.model('Company', companySchema)
module.exports = Company
Và đúng thủ tụ.
const crawl = async() => {
const companies = await getPageContent(`${URL}page/2`).then($ => html2Companies($))
return Company.create(companies)
}
mongoose.Promise = global.Promise
mongoose.connect(process.env.MONGODB_URI || 'mongodb://localhost:27017/crawl', {
useMongoClient: true
}, (error) => {
if (error) {
console.log('%s MongoDB connection error. Please make sure MongoDB is running.', chalk.red('✗'))
process.exit()
}
crawl().then((companies) => {
if (!companies)
return
console.log(`Created ${companies.length} companies`)
return
}).then(() => {
process.exit()
})
})
Kết quả có vẻ không đẹp cho lắm khi một số request bị timeout.  . Mỗi lần như vậy mình lại phải chạy lại từ đầu thì không ổn. Mình quyết định viết một recursive function. Hi vọng sẽ chạy những cái page nào bị timeout trước đó.
. Mỗi lần như vậy mình lại phải chạy lại từ đầu thì không ổn. Mình quyết định viết một recursive function. Hi vọng sẽ chạy những cái page nào bị timeout trước đó.
Cái hàm đó nhìn như thế này.
const crawl = async(pages, results) => {
const chunks = await Promise.all(pages.map(uri => crawlPage(uri)))
const availableChunks = _.filter(chunks, c => typeof c === 'object')
const remainPages = _.filter(chunks, c => typeof c === 'string')
if (availableChunks.length > 0) {
results = await Promise.all(availableChunks.map(companies => Company.create(companies)))
.then((data) => data.reduce((page1, page2) => page1.concat(page2)))
}
if (remainPages && remainPages.length > 0) {
console.log(`Remain ${remainPages.length}.`)
results = results.concat(await crawl(remainPages, results))
}
return results
}
Kết quả
Chả được cái tích sự gì khi mà server bên đó hơi cùi tí tẹo. Mới chạy có mấy chục cái request liên tục mà tải không nổi. Bị request timeout, nhảy vô web của họ thì thấy bị hi sinh luôn.
Kiến thức đã dùng
- nodejs ES6 (Node v8)
- async/await
- Promise
Source Code
git@github.com:lucduong/crawl-companies.git
https://github.com/lucduong/crawl-companies
Kết luận.
Thôi dẹp, lấy được đến đâu lấy. =)).
Đùa vậy thôi, mình có sửa lại chỗ này tí Company.create(companies) thành createCompanies(companies) và trong hàm createCompanies mình findOneAndUpdate để sau này stop, start lại nó ko update trùng.
Đúng ra còn nhiều cách tối ưu khác nữa nhưng mình xin phép nhường lại cho bạn đọc. Và hi vọng các bạn sẽ contribute thêm.
Có thể là mình sẽ đánh dấu lại những trang nào đã lấy dữ liệu rồi và loại trừ, lần sau chạy lại sẽ ko lấy nữa. Các bạn làm giúp mình với nhé.
All rights reserved
