
Cơ bản về fastai (P2) - DataBlock API
Bài đăng này đã không được cập nhật trong 3 năm
TIếp nối bài viết lần trước về các tính năng mì ăn liền của fastai, trong bài viết hôm nay, mình sẽ giới thiệu cho các bạn về để xử lý dữ liệu và hệ thống callback của fastai. Let's get started.
DataBlock API
Thư viện fastai được thiết kế theo kiểu phân tầng. Ở trên cùng là tầng applications cho phép chúng ta train mô hình chỉ với vài dòng code như đã thấy ở bài viết trước.
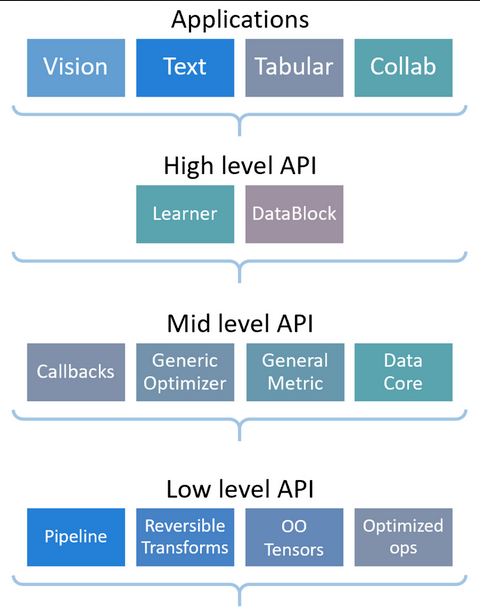
Ví dụ để tạo DataLoaders cho bài toán phân loại ảnh, ta có thể dùng đoạn code sau:
path = untar_data(URLs.MNIST)
dls = ImageDataLoaders.from_folder(path=path, train='training', valid='testing')
Các phương thức có sẵn trong fastai như from_folder sẽ khá là tiện nếu data của chúng ta được tổ chức theo chuẩn như kiểu bộ MNIST. Nhưng trên thực tế thì data có muôn hình vạn trạng, không có theo format cụ thể nào cả. Vì thế, fastai cung cấp cho ta một API khá linh hoạt để load data gọi là DataBlock API.
Thử inspect source code của ImageDataLoaders.from_folder?? trên jupyter ta sẽ thấy đoạn code sau:
ImageDataLoaders.from_folder(
path,
train='train',
valid='valid',
valid_pct=None,
seed=None,
vocab=None,
item_tfms=None,
batch_tfms=None,
*,
bs: 'int' = 64,
val_bs: 'int' = None,
shuffle: 'bool' = True,
device=None,
)
Source:
@classmethod
@delegates(DataLoaders.from_dblock)
def from_folder(cls, path, train='train', valid='valid', valid_pct=None, seed=None, vocab=None, item_tfms=None,
batch_tfms=None, **kwargs):
"Create from imagenet style dataset in `path` with `train` and `valid` subfolders (or provide `valid_pct`)"
splitter = GrandparentSplitter(train_name=train, valid_name=valid) if valid_pct is None else RandomSplitter(valid_pct, seed=seed)
get_items = get_image_files if valid_pct else partial(get_image_files, folders=[train, valid])
dblock = DataBlock(blocks=(ImageBlock, CategoryBlock(vocab=vocab)),
get_items=get_items,
splitter=splitter,
get_y=parent_label,
item_tfms=item_tfms,
batch_tfms=batch_tfms)
return cls.from_dblock(dblock, path, path=path, **kwargs)
Trong phương thức from_folder, một object gọi là DataBlock được khởi tạo. Các bạn có thể nghĩ 1 DataBlock là một list các chỉ dẫn để khởi tạo DataLoaders:
- Định dạng data là gì? (ảnh, audio, text, tabular data, ...)
- Làm thế nào để tạo 1 list các phần tử trong dataset? (ví dụ từ đường dẫn của bộ MNIST, là sao để tạo 1 list tất cả đường dẫn tới ảnh trong dataset.
- Label từng phần tử trong list như thế nào?
- Transform các phần tử trong dataset như thế nào?
- Tạo tập validation như thế nào?
TIếp theo hãy thử tạo tự tạo DataBlock nhé. Đầu tiên ta bắt đầu với 1 DataBlock trống
dblock = DataBlock()
Khi đứng 1 mình thì DataBlock chỉ là 1 list các chỉ dẫn cách để tập hợp data. Muốn truy cập vào data của DataBlock thì trước hết phát chỉ cho nó biết lấy data từ đâu. Ở dưới ta dùng hàm get_image_files trong fastai để lấy tất cả đường dẫn file ảnh trong path.
path = untar_data(URLs.MNIST)
fnames = get_image_files(path)
Ta có thể dùng DataBlock để convert source thành 2 object Datasets và DataLoaders bằng 2 phương thức DataBlock.datasets hoặc DataBlock.dataloaders. DataLoaders thì các bạn đã thấy ở phần trước rồi, còn Datasets cũng tương tự, chỉ là wrapper của training Dataset và validation Dataset. Do source của chúng ta là một list các đường dẫn không đóng thành batch được, gọi .dataloaders ở đây sẽ bị lỗi nên ở đây mình sẽ convert về Datasets:
dsets = dblock.datasets(source=fnames)
print(dsets.train[0])
Output:
(Path('/home/root/.fastai/data/mnist_png/training/7/59513.png'), Path('/home/root/.fastai/data/mnist_png/training/7/59513.png'))
Mặc định, DataBlock sẽ cho rằng data của chúng ta có 2 thứ: input cho mô hình và label nên đường dẫn bị lặp lại 2 lần ở đây. Một cách làm khác là ta có thể set tham số get_items của DataBlock bằng hàm get_image_files:
dblock = DataBlock(get_items=get_image_files)
dsets = dblock.datasets(source=path)
print(dsets.train[0])
Bây giờ thì thay vì để source là list các đường dẫn, ta chỉ cần truyền vào thư mục gốc và DataBlock sẽ tự gọi get_image_files để lấy list các đường dẫn.
Tiếp theo, ta cần cho DataBlock biết cách để trích xuất label của ảnh từ đường dẫn của nó. Bộ dữ liệu MNIST được format như sau

Trong mỗi thư mục từ 0-9 là các ảnh tương ứng với class đó. Vì vậy, ta cần viết 1 function để convert từ đường dẫn Path('/home/root/.fastai/data/mnist_png/training/7/59513.png') thành 7:
def parent_label(fname: Path):
return Path(fname).parent.name
Tiếp theo ta truyển hàm label vào DataBlock để lấy label từ đường dẫn:
dblock = DataBlock(
get_items=get_image_files,
get_y=parent_label
)
dsets = dblock.datasets(path)
print(dsets.train[0])
Output:
(Path('/home/root/.fastai/data/mnist_png/training/5/50497.png'), '5')
Okay. Giờ ta đã có input và target. Việc tiếp theo cần làm là chỉ cho DataBlock cách xử lý chúng như thế nào. Với input thì là dạng ảnh còn target thì là dạng category. Các dạng dữ liệu khác nhau được biểu diễn bằng các block trong DataBlock, ở đây ta sẽ dùng ImageBlock và CategoryBlock
dblock = DataBlock(
blocks=(ImageBlock(cls=PILImageBW), CategoryBlock),
get_items=get_image_files,
get_y=parent_label
)
dsets = dblock.datasets(path)
print(dsets.train[0])
Output:
(PILImageBW mode=L size=28x28, TensorCategory(5))
Ta có thể thấy DataBlock đã tự thêm các transform cần thiết để đọc ảnh (trong fastai họ dùng thư viện pillow) và convert label từ string sang tensor. Các bạn có thể truy cập vào mapping giữa các category và index tương ứng qua dsets.vocab:
['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
Tiếp theo ta cần chỉ cho DataBlock cách chia training và validation set. Với bộ MNIST ta có thể dùng GrandparentSplitter hoặc nếu bạn thích chia ngẫu nhiên thì có thể dùng RandomSplitter:
dblock = DataBlock(
blocks=(ImageBlock(cls=PILImageBW), CategoryBlock),
get_items=get_image_files,
get_y=parent_label,
splitter=GrandparentSplitter(train_name='training', valid_name='testing')
#splitter=RandomSplitter()
)
Thường thì khi train mô hình, ta thường train theo từng mini-batch, tức là input đầu vào phải cùng kích thước với nhau. Nên khi viết Dataset bằng Pytorch ta thường có thêm bước resize ảnh về cùng một kích thước hoặc thêm data augmentation cho ảnh. Trong DataBlock thì ta có thể thực hiện bước này thông qua item_tfms (MNIST thì cùng kích thước sẵn rồi nên resize ở đây để demo là chính
dblock = DataBlock(
blocks=(ImageBlock(cls=PILImageBW), CategoryBlock),
get_items=get_image_files,
get_y=parent_label,
splitter=GrandparentSplitter(train_name='training', valid_name='testing'),
item_tfms=Resize(32)
)
Ngoài item transform thì fastai còn support batch transform khá là hữu ích cho việc normalize dữ liệu hay support các augmentation chạy trên GPU
dblock = DataBlock(
blocks=(ImageBlock(cls=PILImageBW), CategoryBlock),
get_items=get_image_files,
get_y=parent_label,
splitter=GrandparentSplitter(train_name='training', valid_name='testing'),
item_tfms=Resize(32),
batch_tfms=Normalize.from_stats(mean=[0.5], std=[0.5])
)
Done. Với DataBlock như trên thì ta đã có thể tạo DataLoaders như bài viết trước và đem đi train mô hình được rồi
dls = dblock.dataloaders(path, bs=64)
dls.show_batch()
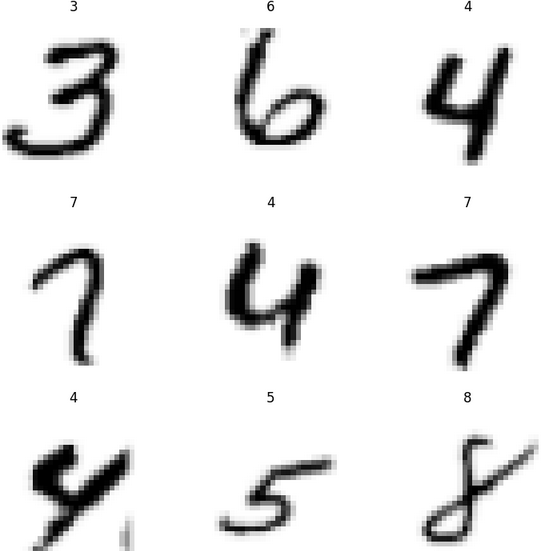
Lần này thì mình không dùng mô hình có sẵn nữa mà dùng 1 mạng CNN đơn giản:
model = nn.Sequential(
nn.Conv2d(1, 8, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(8),
nn.ReLU(),
nn.Conv2d(8, 16, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.Conv2d(16, 32, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.Conv2d(32, 16, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.Conv2d(16, 10, kernel_size=3, stride=2, padding=1),
Flatten()
)
Khởi tạo Learner
learner = Learner(dls, model, loss_func=nn.CrossEntropyLoss(), metrics=accuracy)
learner.summary()
Output:
Sequential (Input shape: 64 x 1 x 32 x 32)
============================================================================
Layer (type) Output Shape Param # Trainable
============================================================================
64 x 8 x 16 x 16
Conv2d 80 True
BatchNorm2d 16 True
ReLU
____________________________________________________________________________
64 x 16 x 8 x 8
Conv2d 1168 True
BatchNorm2d 32 True
ReLU
____________________________________________________________________________
64 x 32 x 4 x 4
Conv2d 4640 True
BatchNorm2d 64 True
ReLU
____________________________________________________________________________
64 x 16 x 2 x 2
Conv2d 4624 True
BatchNorm2d 32 True
ReLU
____________________________________________________________________________
64 x 10 x 1 x 1
Conv2d 1450 True
____________________________________________________________________________
64 x 10
Flatten
____________________________________________________________________________
Total params: 12,106
Total trainable params: 12,106
Total non-trainable params: 0
Optimizer used: <function Adam at 0x7f123a175ee0>
Loss function: FlattenedLoss of CrossEntropyLoss()
Callbacks:
- TrainEvalCallback
- CastToTensor
- Recorder
- ProgressCallback
Khi tạo Learner, chỉ có 2 tham số bắt buộc là dataloaders và mô hình. Khi truyền dataloaders vào thì không bắt buộc sử dụng DataLoaders được tạo từ DataBlock mà các bạn có thể tự viết Dataset pytorch và gọi Dataloader như bình thường sau đó bọc Dataloader train và validation như thế này: `DataLoaders(train_loader, val_loader).
Và công việc cuối cùng là train mô hình:
learner.fit(n_epoch=5, lr=1e-4)
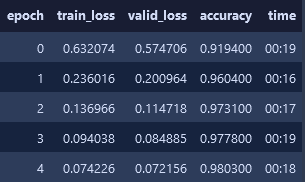
Kết luận
Ở trên mình đã hướng dẫn các bạn cách sử dụng DataBlock API của fastai. DataBlock API cung cấp cho người dùng 1 cách load data linh hoạt hơn so với các factory method có sẵn. Nếu sử dụng DataBlock vẫn chưa đủ linh hoạt cho nhu cầu của các bạn thì fastai còn cung cấp 1 tầng API thấp hơn gọi là mid-level API, nhưng cái này chắc sẽ để cho bài viết sau. Cám ơn mọi người đã đọc bài viết. Mong các bạn tiếp tục ủng hộ.
Reference
All rights reserved
