Chặng 1.3: Pandas, Chinh phục Thử thách trên Datacamp
Chào anh em,
Tiếp tục hành trình thuộc series bài chinh phục python, data & automation, trong "Chặng 1.2: Python, Vượt thử thách Hackerank" tôi đã demo cho anh em thấy, các nền tảng mở như Hackerank, bao gồm Viblo rất tuyệt vời để chúng ta ôn luyện võ công, hẹn ngày tỷ thí ở lầu Ngưng Bích. Tôi rất thích các bài test dạng challenge, thử thách tổng hợp cô đọng, có thể giúp ta kiểm tra nhanh chóng năng lực, cũng như tự định vị được mình đang ở đâu, có chỗ nào hổng cần đầu tư thêm thời gian hay không.
- Ở chặng 1.2: chúng ta đã hoàn thành 6/10 mục tiêu liên quan tới: python cơ bản: syntax, OOP, exception handling, numpy. Đặc biệt các bài test liên quan tới Python Functions (lamda, map, filter) là rất hay ho, các bài về Regex cũng powerful, mạnh mẽ không kém.
- Trong chặng 1.3 này: tôi sẽ đi tiếp hành trình của mình với 4/10 mục tiêu còn lại, xoay quanh: Pandas, đọc/ghi: CSV, Excel, JSON, và các bộ tools liên quan bao gồm: jupyter, matplotlib, seaborn.
Điểm may mắn là tôi đã có dịp "lướt qua" mí bạn như pandas, jupyter rồi, nên những bước đầu tiên trong hành trình, đặc biệt chặng 1.x này có lẽ là tương đối thoải mái. Thôi thì mưa tới đâu, cứ mát mặt tới đấy anh em nhỉ? Điểm qua các mục tiêu cần đạt trong chặng này:
| No. | Từ khóa | Liên kết bài kiểm tra | Độ khó | Độ phổ biến | Ghi chú |
|---|---|---|---|---|---|
| 3 | Pandas CSV/Excel | Pandas Exercises , 101 Pandas Exercises for Data Analysis | Trung bình | 75% | Các bài tập này giúp bạn làm quen với việc đọc/ghi và xử lý dữ liệu bằng Pandas. |
| 4 | Jupyter Notebook | Trung bình | 70% | Hướng dẫn sử dụng Jupyter Notebook cho phân tích dữ liệu, giúp bạn làm việc với dữ liệu một cách trực quan. | |
| 6 | Data Cleaning | Trung bình | 65% | Thực hành làm sạch dữ liệu, một kỹ năng quan trọng trong phân tích dữ liệu. | |
| 8 | Data Visualization | Trung bình | 70% | Học cách vẽ biểu đồ cơ bản với Matplotlib và Seaborn để trực quan hóa dữ liệu. |
.
Xét tổng quan thì các mục tiêu 3, 4, 6, 8 nêu trên khá OK. Anh em cứ theo topic, từ khóa mà tìm kiếm tư liệu để update, trau đồi kĩ năng nhé. Còn đi vào chi tiết thì như chặng 1.2 đã nêu, trợ lý AI của tôi lại tự biên tự diễn một số link 4, 6, 8 nêu trên (không tồn tại). Các link còn lại thì tôi không ưng lắm, tôi vẫn thích các bài test kiểu challenge, thử thách tổng hợp để đánh giá và review nhanh kĩ năng hơn. Vì vậy tôi sẽ bỏ qua các links được gợi ý bởi trợ lý AI nhà tôi, mà thay vào đó bằng các link/thử thách phù hợp. Anh em xem bên dưới nhé.
1.3.1 Thử thách "Dự đoán Sự cố Máy công nghiệp" trên Datacamp
Tôi cố tìm các nền tảng cung cấp các bài test/challenge thử thách tổng hợp liên quan tới pandas, và jupiter để vừa học vừa review lại kĩ năng thì có 2 bạn đập vào mắt tôi đó là: kaggle.com và datacamp.com. Trong links giới thiệu của trợ lý AI nhà tôi có 2 bạn này, nhưng vì trợ lý AI gặp hạn chế trong việc truy cập dữ liệu nhà 2 bạn ấy, nên đưa link test không chính xác, chứ 2 bạn này thì rất OK để luyện skills data anh em nhé.
Giới thiệu sơ lược:
- Kaggle: được biết đến là một nền tảng dành cho các nhà khoa học dữ liệu và kỹ sư học máy, nổi bật với cộng đồng đông đảo và hàng loạt cuộc thi phân tích dữ liệu với giải thưởng hấp dẫn. Kaggle cung cấp kho dữ liệu mở khổng lồ, môi trường lập trình trực tuyến (Kaggle Notebooks), và các bộ công cụ hỗ trợ học tập, thử nghiệm thuật toán ngay trên nền tảng. Điểm vượt trội của Kaggle là khả năng kết nối cộng đồng mạnh mẽ, nơi mọi người chia sẻ mã nguồn, giải pháp, và kiến thức. Đây cũng là nơi lý tưởng để rèn luyện kỹ năng thực chiến và xây dựng hồ sơ dữ liệu uy tín.
- Kaggle được Google mua lại và sát nhập đâu đó khoảng năm 2017, và trở thành một phần của hệ sinh thái Google bên cạnh Google BigQuery hay TensorFlow. Bạn TensorFlow thì tôi có đọc lướt đâu đó trong bài giới thiệu của Huyền Chíp cách đây hơn 5 năm, chưa có dịp vọc thử. Hi vọng cuối thử thách này sẽ có dịp "rờ tới", hehe.
- DataCamp: tập trung vào việc cung cấp các khóa học trực tuyến về khoa học dữ liệu, phân tích, và lập trình bằng các ngôn ngữ như Python, R, SQL. Ưu điểm của DataCamp là các bài học tương tác, hướng dẫn chi tiết và nền tảng thân thiện cho người mới bắt đầu. Hệ sinh thái của DataCamp tập trung vào việc đào tạo kỹ năng, cung cấp lộ trình học tập cụ thể và chứng chỉ cho người học. Không giống Kaggle, DataCamp nhấn mạnh vào việc học tập có cấu trúc thay vì các dự án thực tế hay cộng đồng cạnh tranh.
.
Tôi may mắn được tiếp cận Kaggle trong một khóa học python ngắn hạn 3 tháng, trên Kaggle thấy có rất nhiều cuộc thi lớn, nhiều thử thách thực tế "real problems" rất thú vị, và nhiều Team mạnh, có cả VinBigData thì phải. Datacamp thì tôi chưa có dịp đụng tới, nhưng lướt thấy giao diện và thiết kế khá giống Kaggle, cũng rất hay ho nên chọn để làm bài test, hoàn thành chặng 1.3.x này cho biết xem có khác nhiều so với Kaggle hay không.
- Tôi sẽ tạm bỏ qua các mục Courses, Practice (câu hỏi dạng Q&A), Assessments, và Tutorials. Anh em nếu cần củng cố kiến thức nền, và kĩ năng có tính hệ thống thì cố gắng cày cuốc các hạng mục này nhé.
- Mục tiêu trong chặng này là các bài test/thử thách phức hợp, nên tôi có để ý tới: Competitions, Code Alongs, và Real World Projects.
Sau một hồi tọc vọc thì tôi phát hiện ra:
- Để vào được các dự án thực tế Real World Projects thì anh em phải có tài khoản Premium, sơ sơ 7$/tháng (50% off). Nhưng tôi chưa kiếm được xu nào trong mục tiêu đi săn 10$ remote job cả, nên tôi tạm lướt qua bạn ấy anh em nhé. Khi nào giàu, cafe thoải mái không phải suy nghĩ, tôi sẽ quay lại. =))
- Trong mục Competitions, thì tôi thấy có khá nhiều bài test, thử thách phức hợp đáp ứng tiêu chí của tôi. Tài khoản Free cũng được vọc sơ sơ 3 bài, trước mắt như vậy cũng tạm ổn, có gì xài nấy đã anh em nhé. kaka.
Tiêu chí chọn bài test/thử thách
- Bài test phức hợp, review và học được nhiều skills, kĩ năng
- Bài test điểm qua được các topic, từ khóa đã nêu bao gồm: Pandas, đọc/ghi: CSV, Excel, JSON, và các bộ tools liên quan bao gồm: jupyter, matplotlib, seaborn.
Theo tiêu chí này thì hầu hết các bài competitions đều rất OK để anh em thử sức nhé.
Tôi chọn lụi lấy một bài gần đây, ưu tiên các bài không bị áp lực thời gian: "Predicting industrial machine downtime 🔧 Level 1", tạm dịch là thử thách: "Dự đoán Sự cố Máy công nghiệp". Anh em sẽ được cung cấp một bộ data dưới dạng file .csv, data gồm các chỉ số đo lường trên máy công nghiệp (nhiệt độ, tốc độ xoắn, thủy lực, và thời gian chết máy) được ghi nhận cho 3 dây chuyền khác nhau trong khoảng 1 năm. Thử thách này yêu cầu anh em làm báo cáo đánh giá xoay quanh câu chuyện khi nào thì "máy chết", tại sao, để có kế hoạch vận hành và bảo dưỡng phù hợp, và một vài yêu cầu kĩ thuật nhỏ có tính dẫn dắt kiểu bài tập như tính trung bình momen xoắn để xác định mức độ ảnh hưởng, vân vân mây mây, rất chi là hay ho.

Các kĩ năng và kinh nghiệm sẽ học được?
Sau khi truy cập vào thử thách, anh em sẽ được đưa tới một trang WorkBook online:
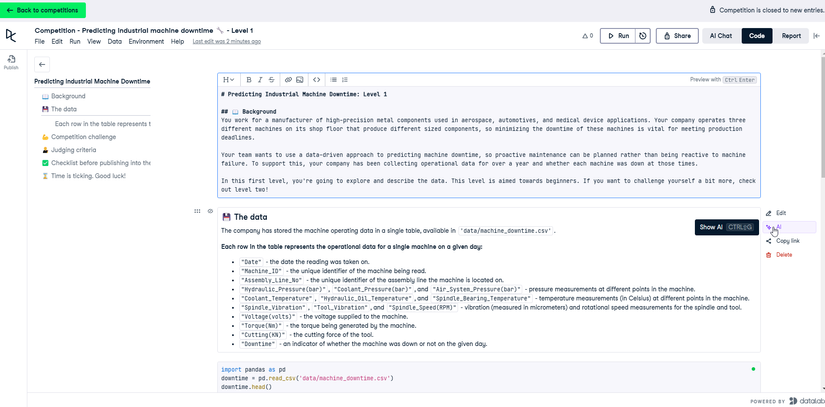
Má ơi, siêu xịn, code mà đẹp quá chừng. Tôi code java back-end lâu quá, riết thành ra tôi quen với sự rối rắm và sự phức tạp, lớp chồng lớp, của mấy chục ngàn dòng code, chứ chưa quen lắm với cái sự sang-xin-mịn của python WorkBook. 😃
Note nhẹ để anh em nắm workbook này có gì nhé?
- #1. Jupyter: Nếu anh em đã từng làm việc với jupyter thì sẽ nhận ra workbook này y chang, workbook này là một IDE online, cho phép anh em code, run, và report trực tiếp trên nền tảng luôn. Rất OK để prototype nhanh, phác thảo ý tưởng, share kinh nghiệm hay làm báo cáo anh em nhé. Anh em chưa biết jupyter hay python workbook là gì thì sau khi vượt qua thử thách này cũng sẽ bỏ túi được 1 Tool ngon lành rồi hen.
- Side bar bên trái là outline như các file words, pdf
- Trung tâm là mix giữa interpret python code và text (markdown) == vừa chạy code, vừa diễn giải. Anh em làm java lâu năm, nếu không update thêm python, jupyter thì sẽ dễ bị lạc hậu lắm thay.
- Góc trên bên phải là Buttons: để anh em RUN all, Report view, share.
- Datacamp có tích hợp cả AI ngay trong từng code-block luôn. Quá xịn sò.
Mấy anh em mới vào nghề, xài workbook online như này thì đỡ tốn công setup trên máy local, đỡ đau đầu lỗi thư viện, python version conflict, vân vân mây mây. Còn anh em làm lâu năm rồi thì down về xài trên local nếu không thích online hén.
- #2. Pandas: Lội xuống một tí thì anh em sẽ thấy pandas là bắt buộc để anh em vượt qua thử thách này nhé.
- Việc đọc ghi CSV bao gồm cả Excel, Json, XML kết-hợp-pandas cũng rất đơn giản. Chỉ cần đúng một dòng là anh em đã có thể đọc ghi mấy file như data/machine_downtime.csv mấy chục, mấy trăm nghìn records và đưa vào xử lý nhanh gọn lẹ luôn hén. Việc này đối với java lại hơi rườm rà, và phức tạp. 😭
import pandas as pd
downtime = pd.read_csv('data/machine_downtime.csv')
downtime.head()
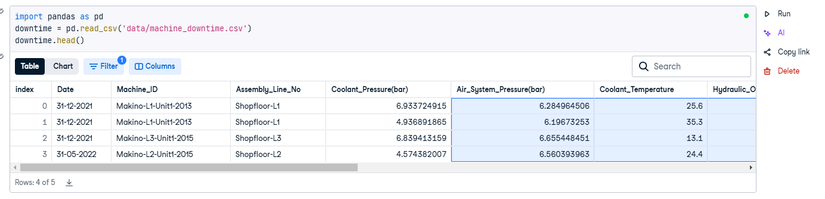
- #3. Visualizations, Storytelling: Theo yêu cầu của thử thách, anh em cũng sẽ phải làm báo cáo cùng với kĩ năng vẽ biểu đồ (xử dụng matplotlib, seaborn) và thể hiện khả năng kể chuyện của mình, kết nối data với kết luận một cách logic và có sức nặng.

Anh em sẽ phải thích ứng theo tiêu chí đánh giá, Judging criteria, khá khoai như hình, và hoàn thành toàn bộ checklist. Nên về mặt tổng quan, thử thách này khá đạt 99% mục tiêu của chặng 1.3 mà trợ lý AI của tôi đã vẽ ra anh em ạh. Việc còn lại là tôi và anh em chỉ cần hoàn thành thử thách theo các tiêu chí đã đề ra mà thôi. Sau khi hoàn thành xong thử thách này chúng ta sẽ:
- 🚩Biết rõ hơn về pandas.
- 🚩Đọc/ghi: CSV, Excel, JSON kết hợp pandas ngon lành
- 🚩Biết thêm về: jupyter, matplotlib, seaborn.
- 🚩Biết được bố cục một bài data-analysis chuẩn chỉnh, code nhưng đẹp mắt là như nào.
Let's go!!
Ây, khoan! Trông cũng hào hứng thật đấy 💪, nhưng tôi tự dưng cảm giác mình như amateur, tôi chưa biết phải làm gì để "bắt đầu" với thử thách này anh em ạh! Thôi thì tôi sẽ xử dụng chiến lược "đứng trên vai khổng lồ" => tôi sẽ đi học lỏm 3 bài sumbit vote cao nhất đã publish trên nền tảng, xem người ta tiếp cận và giải quyết bài toán này như nào nhé. Rồi tôi sẽ tự bơi cho các bài khác sau, kaka.
1.3.2 Khảo sát: 3 bài có votes cao nhất
Vì thử thách này đã hoàn thành, không còn bị áp lực thời gian như một cuộc thi, nên việc chọn khảo sát các đáp án sẵn có để học hỏi là một chiến lược phù hợp anh em nhé. Anh em bấm vào mục ENTRIES:

Để khảo sát 3 bài này, chúng ta bám theo yêu cầu và tiêu chí của competitions nhé, đóng vai là ban giám khảo hoặc chỉ đơn giản là một người xem, người học có khiếu tò mò, xem có thu lượm được điều gì không nhé?
💪 YÊU CẦU: Tạo một báo cáo đáp ứng 3 điều kiện (kỹ thuật) sau:
- Xác định ngày khởi đầu, và ngày kết thúc của báo cáo?
- Tính trung bình momen xoắn của máy công nghiệp (Torque)?
- Xác định dây chuyền bị lỗi "chết máy" cao nhất trong 3 dây chuyền?
🧑⚖️ Tiêu chí:
- Đề xuất (Recommendations): 35%: báo cáo có đề xuất hành động rõ ràng, chất lượng, và có nhiều insights.
- Mạch lạc (Storytelling): 35%: báo cáo vừa xúc tích lại đào sâu, vừa kết hợp mạch lạch giữa đề xuất và các điểm dữ liệu quan trọng.
- Biểu đồ (Visualizations): 20%: xử dụng biểu đồ phù hợp, hiệu quả
- Phần còn lại là vote: 10%; chúng ta tạm bỏ qua.
.
Ngoài ra, trong phần checklist, thử thách yêu cầu các bài workbook phải đưa phần Tổng kết (executive summary) lên trên đầu, và lược bỏ đi các phần không quan trọng. Và sau đây là outline, mục lục của 3 bài được up votes cao nhất, anh em thử tài "soi" xem có gì thú vị không nhé? Các bài xếp theo thứ tự 1, 2, 3 từ trái sang phải theo thứ tự votes:
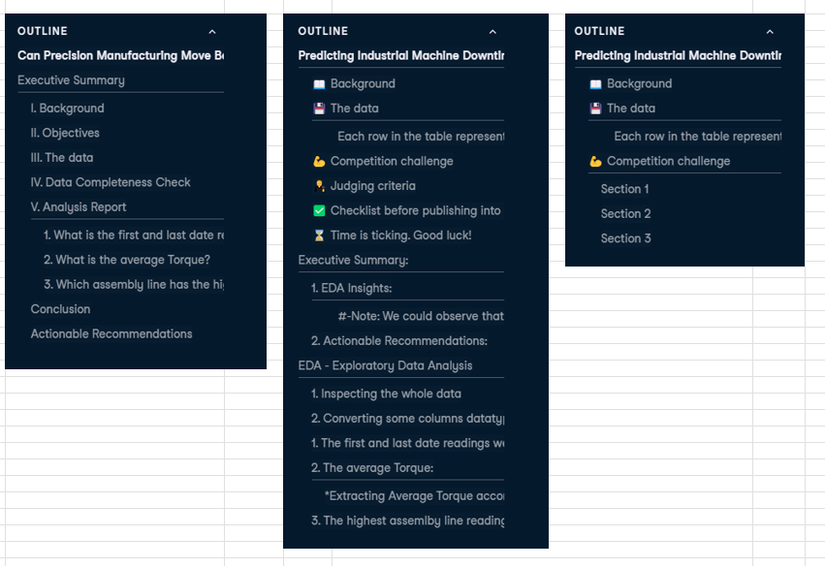
Nhìn lướt qua thì:
- Bài số 3: đúng nghĩa chỉ tập trung hoàn thành yêu cầu, với 3 sessions, không quan tâm tới tiêu chí đánh giá hay bố cục trình bày. =)) Bạn nào thích nhanh gọn lẹ thì nhảy vào bài này nhé, học được các kĩ thuật pandas, và matplotlib cơ bản.
- Bài số 2: thì ngược lại, phong cách hơi rườm rà, chú trọng bố cục theo tiêu chí hơn, và có vẻ đưa ra được một số quan sát + đề xuất thay vì chỉ đạt mục tiêu theo "yêu cầu" như bài 1. Bài 2 như kiểu dân chuyên Văn, còn bài 1 như kiểu dân chuyên Toán vậy anh em nhé. =))
- Bài số 1: trông có vẻ chuyên nghiệp và hàn lâm, bố cục cũng tương đối rõ ràng, và có votes cao nhất hiện tại = 47. Bài này có các kĩ thuật plot biểu đồ khá bá đạo, anh em ngâm cứu xem học hỏi được gì không nhé?
Học được gì từ bài số 3?
Updated: 24/01/2025.
Khảo sát, bài số 3 của bạn Daniel:
Predicting Industrial Machine Downtime: Level 1
Đặc điểm nổi bật của bài này là: bố cục tinh gọn, đi thẳng vào yêu cầu. Những anh em tay ngang mới bơi qua python, pandas hay bị vướng cái pattern chưa biết phải làm gì để "bắt đầu" thì cứ làm như bài này là OK nhé == hoàn thành các YÊU CẦU đúng kĩ thuật trước, rồi ta sẽ bàn về tầm nhìn, sứ mệnh, chém gió theo các TIÊU CHÍ sau.
- Anh em có thể chọn "Make a copy" và đứng trên vai người khổng lồ.
Trường hợp anh em không thích bị người khác "copy" thì chọn chế độ private == tự vọc tự chơi một mình. Tuy nhiên, khuyến nghị anh em, khi mình "chưa là gì" thì không có gì để mất cả, cứ chơi tới bến mới mau leo RANK được nha. - Sau khi tạo 1 bản sao thì anh em có thể tự RUN và tự vọc thêm các đoạn code như trong bài để kiểm tra học hỏi các kĩ thuật của bạn Daniel. Nếu không thì anh em đọc lướt để khảo sát như tôi cũng được.
.
💪 Nhắc lại YÊU CẦU:
- Xác định ngày khởi đầu, và ngày kết thúc của báo cáo?
- Tính trung bình momen xoắn của máy công nghiệp (Torque)?
- Xác định dây chuyền bị lỗi "chết máy" cao nhất trong 3 dây chuyền?
.
#3.1 Để tìm ngày bắt đầu và kết thúc của báo cáo, bạn Daniel tiếp cận đúng style "kỹ thuật" mới vào nghề. Nếu tôi không đi vọc 3 bài votes cao nhất, mở mang được tầm nhìn, thì chắc tôi cũng làm giống bạn Daniel thôi anh em ạh. kaka
downtime_sorted = downtime.sort_values("Date", ascending=True)
downtime_sorted.reset_index(drop=True, inplace=True)
First_downtime_date = downtime_sorted.loc[0]["Date"]
Last_downtime_date = downtime_sorted.loc[2499]["Date"]
- Ở đây kĩ thuật bạn dùng là sort_values(), reset_index() by date, sau đó lấy giá trị đầu và cuối.
- Kĩ thuật trên khá OK, nếu anh em chưa quen làm việc với index trong pandas, +1 điểm.
- Tuy nhiên lấy ngày cuối cùng trên báo cáo dùng .loc[2499] là -1 điểm nhé. Vì 2499 thì sẽ bị phụ thuộc vào data.
- Thời gian lấy mẫu dữ liệu đâu đó khoảng: 2021-11-24 đến 2022-07-03: gần 9 tháng.
Để tìm ngày đầu và cuối của báo cáo, còn có nhiều cách tiếp cận khác hay ho hơn, kiểu "non-code", anh em xem thêm các bài sau hen.
.
#3.2 Để tính trung bình momen xoắn, bạn Daniel sử dụng pandas .mean():
Average_Torque= downtime["Torque(Nm)"].mean()
- Này thì quá rõ rồi, không có gì để bàn. Rất chi là "on target", "đúng", "trúng", không giải thích gì thêm. =))
- Trung bình momen xoắn bạn tính được là: ["Torque(Nm)"].mean() = 25.23: chưa rõ có gì khác bọt hay không?
- Điểm trừ là bạn để format number quá dài dòng: "25.234915129567682", ngày cũng vậy, theo bài thì Time không cần thiết nên thay vì "2022-07-03 00:00:00" bạn chỉ cần dùng "2022-07-03" => -2 điểm.
.
#3.3 Để xác định dây chuyền nào bị lỗi "chết máy" cao nhất trong 3 dây chuyền, bạn Daniel tiếp tục với các thao tác pandas cơ bản:
Machine_downtime = downtime[downtime["Downtime"] == "Machine_Failure"].groupby("Assembly_Line_No").size()
Machine_downtime_sorted = Machine_downtime.sort_values()
Machine_downtime_sorted.plot(kind="barh", title="Machine Downtime by Assembly Line")
- Ở đây kỹ thuật filter by "Machine_Failure" và groupby("Assembly_Line_No") được sử dụng
- Biểu đồ cơ bản: .plot(kind="barh", title="Machine Downtime by Assembly Line") cũng được xài, và rất phong cách Daniel "on target". Nhìn vào biểu đồ thì cũng dễ dàng thấy rằng "Dây chuyền số 1" (Assembly Line 1) bị lỗi chết may cao nhất, với hơn 400 lần chết máy.
.
Như vậy bài của bạn Daniel cơ bản đánh trúng, đi thẳng tới yêu cầu. Ở góc độ thuần "kỹ thuật", tay ngang mới vào nghề là rất OK. Nhưng để đáp ứng thêm khoản bố cục cho tới các tiêu chí như một data-analysis thực thụ thì anh em ngâm cứu thêm 2 bài còn lại nhé.
Phần mình ưng nhất trong bài của bạn Daniel lại nằm ngoài 3 yêu cầu trên, đó là phần mở đầu session 1.
downtime.isna().sum().sort_values().plot(kind="barh")
downtime["Torque(Nm)"].fillna(downtime.groupby(["Machine_ID","Assembly_Line_No"])["Torque(Nm)"].transform("mean"))
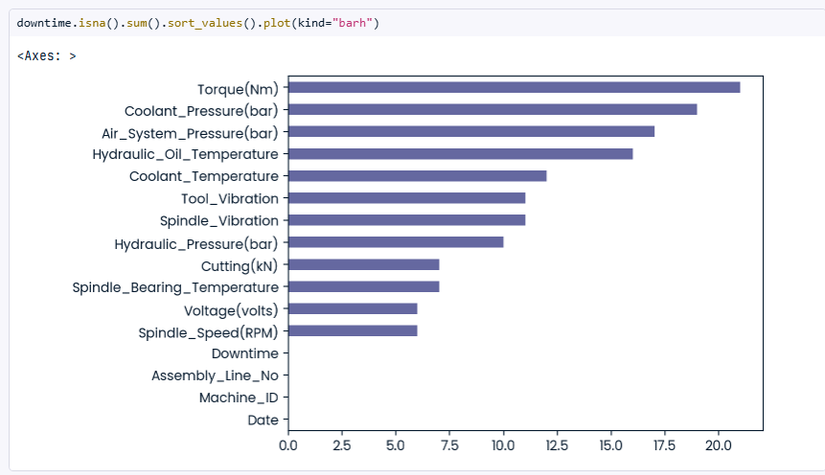
- Chỉ với 2 dòng code thôi, cũng đã tóm tắt được thế nào là "Làm sạch dữ liệu" (Data Cleaning) anh em nhé.
- Dữ liệu "không sạch" thường bao gồm: không có giá trị NaN (NULL trong Java), hoặc dữ liệu bất thường (outlier).
- Kỹ thuật: .isna(), .plot(kind="barh"): chỉ với 1 dòng code đơn giản + nhìn vào biểu đồ, anh em sẽ thấy có khoảng 20 records không có momen xoắn "Torque(Nm)", các columns khác cũng bị miss vài, 10-15 recods.
- Kỹ thuật: .fillna() giúp anh em "bổ sung" các records bị thiếu bằng một giá trị "hợp lý", trong trường hợp này là .groupby(["Machine_ID"])["Torque(Nm)"].transform("mean")) == thay bằng giá trị trung bình của một "Machine_ID" cùng loại.
- Ở góc độ Data Cleaning là rất OK, rất đúng qui trình anh em hen. Còn ở góc độ bài toán và thực tế, thì ta còn cần phải cân nhắc thêm, tỷ trọng NaN, missing values là bao nhiêu(?) có đáng kể không (?), có cần phải Cleaning thật không (?), vân vân mây mây.
- +1 điểm cho khoản biểu đồ .plot(kind="barh"): trong trường hợp này biểu đồ rất trực quan, giúp tớ thấy rõ có bao nhiêu NaN. Nếu thêm khoản tỷ trọng (%) vào nữa là OK con dê luôn ạh.
.
Tạm biệt bạn Daniel.
Anh em lót dép hóng 2 bài tiếp theo hen.
Học được gì từ bài số 2?
Updated: 24/01/2025.
Khảo sát, bài số 2 của bạn Abdulaziz:
Predicting Industrial Machine Downtime: Level 1
Bài của bạn Abdulaziz thì có vẻ giống một data-analysis rồi, mặc dù các kết luận và quan sát (obvervation) của bạn còn chưa được chặt chẽ cho lắm. Bạn đáp ứng đủ các YÊU CẦU 💪 1, 2, 3 như Bài số 1 ở trên, nên ở đây ta tạm bỏ qua việc "soi" các yêu cầu mà bạn đã hoàn thành hen. Bài này ta sẽ "soi: các 🧑⚖️ Tiêu chí: Đề xuất (Recommendations), Mạch lạc (Storytelling), Biểu đồ (Visualizations), cũng như kiểm tra các ✅ Checklist xem có gì thú vị không hen?
Checklist mà bạn đã làm rất tốt là:
- ✅ Đưa phần "executive summary" một Tóm tắt ngắn kết quả nghiên cứu (data-analysis) lên trên đầu, +1 điểm. Nói là ngắn thế thôi, chứ tóm tắt của bạn vẫn còn khá dài dòng, bạn chỉ nên liệt kê 1,2,3 kết quả và ra Recommendation luôn, -1 điểm.
- 🧑⚖️Đề xuất (Recommendations): Dựa trên kết quả tóm tắt thì bạn có đề xuất một chiến lược "Proactive-Maintenance", vận hành chủ động. Mặc dù kế hoạch vận hành chủ động này vẫn chưa ra một ACTION cụ thể nào, nhưng các quan sát (observation) của bạn có vẻ thú vị:
- Bài của bạn có sử dụng 1 kỹ thuật là: "distribution of Machine-Failure cases with days". Kỹ thuật này mình đánh giá là rất hay ho, giúp nhìn nhanh tổng thể, và thấy được liên kết giữa thời gian "Date" và sự kiện "Chết máy" (Machine-Failure). Anh em lội xuống dưới bài chi tiết của bạn sẽ thấy hén. Dựa trên phân phối, distribution, bạn đưa ra 2 quan sát:
- "Machine-Failure happens multiple times within same day"
- "Machine-Failure conditions over days has accumulated behavior"
Quan sát này mình đánh giá là "có giá trị", vì nếu-đúng-như-vậy, khi máy chết thì nó chết luôn (accumulated) ở nhiều ngày tiếp theo, thì dữ liệu này cho thấy đội ngũ vận hành phản ứng "khá chậm", và tốn nhiều thời gian để đưa máy vận hành trở lại bình thường, + 10 điểm.
- Bài của bạn có sử dụng 1 kỹ thuật là: "distribution of Machine-Failure cases with days". Kỹ thuật này mình đánh giá là rất hay ho, giúp nhìn nhanh tổng thể, và thấy được liên kết giữa thời gian "Date" và sự kiện "Chết máy" (Machine-Failure). Anh em lội xuống dưới bài chi tiết của bạn sẽ thấy hén. Dựa trên phân phối, distribution, bạn đưa ra 2 quan sát:
.
Một điểm trong Checklist bạn làm chưa tốt là:
- Remove "redundant cells" like the judging criteria, so the workbook is focused on your story.
Có lẽ bạn quên, nên không bỏ bớt các phần thuộc đề bài, competitions, nên nhìn bố cục bài vẫn còn rối rắm.
.
Distribution of Machine-Failure cases by days"
Như mình đã nêu, phần này của bạn Abdulaziz là mình rất ưng.
downtime[downtime['Downtime'] == "Machine_Failure"]['Date'].value_counts()
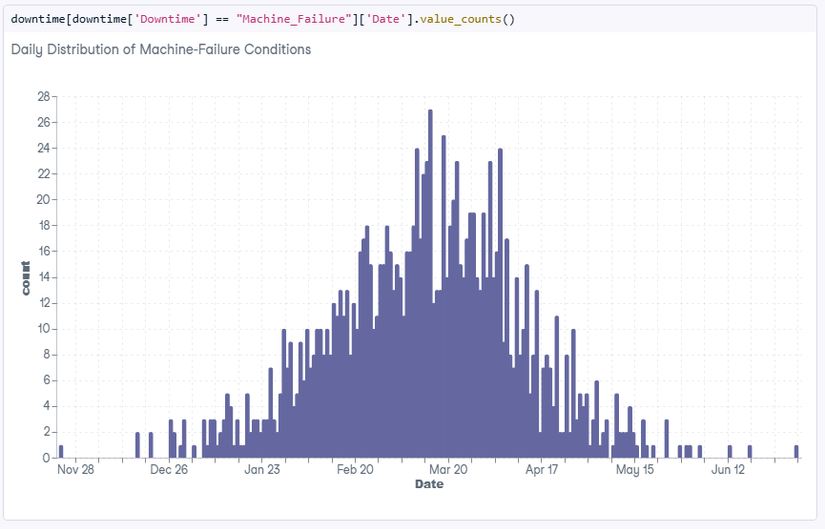
- Nhiều khi anh em học vẽ biểu đồ, học toán phân bố xác suất các kiểu, nhưng toàn xài/vẽ lung tung.
- Biểu đồ này đơn giản nhưng "xài được", rất OK. Cột ngang là ngày, "Date", cột dọc là sự kiện == "Machine_Failure", máy chết. Nhìn vào thì không chỉ:
- Biết được tổng thể ngày bắt đầu, và ngày kết thúc theo yêu cầu, đề bài.
- Mà còn nhanh chóng "thấy được" mối liên hệ giữa thời gian "Date" và sự kiện "máy chết", +3 điểm. Nếu anh em để ở dạng bảng, table + values, thì sẽ "không thấy được". Thì cái "thấy được" vs "không thấy được" sẽ cho anh em biết giá trị của biểu đồ. Nếu vẽ biểu đồ lên mà cũng như không vẽ biểu đồ => nghĩa là chỗ đó anh em bỏ luôn cái biểu đồ giùm tôi nhé.
- 🧑⚖️Theo tiêu chí Visualizations: khoản này rất OK.
.
Thì nhìn vào biểu đồ sẽ nhận ra được vài điểm thú vị:
- Sự kiện "máy chết", Machine_Failure, xảy ra khá nghiêm trọng và khoảng tháng 3 (Mar), sau đó giảm dần và gần như không đáng kể từ tháng 5 (May) cho tới tháng 7, là thời điểm kết thúc báo cáo.
- Có một sự tích lũy "accumulated" đáng kễ lỗi chết máy bắt đầu từ tháng 1 (Jan), tăng dần tới tháng 2, rồi tháng 3. Bạn Abdulaziz phát hiện rất tốt khoản "accumulated" này. Tôi đánh giá nó là điểm "mấu chốt" có giá trị rất lớn trong bài này, + 10 điểm. Bởi nếu phân tích kĩ khoản lỗi chết máy tích lũy này có thể giải quyết được 90% bài toán, thay đổi toàn bộ cuộc chơi.
- Nếu biểu đồ mà tháng nào cũng có lỗi, và lỗi tương đối đều nhau, thì lại là một câu chuyện khác!! Anh em hiểu ý tôi chứ?
.
Một cái distribution, cũng biểu đồ trong bài của bạn Abdulaziz mà tôi không ưng là cái này:
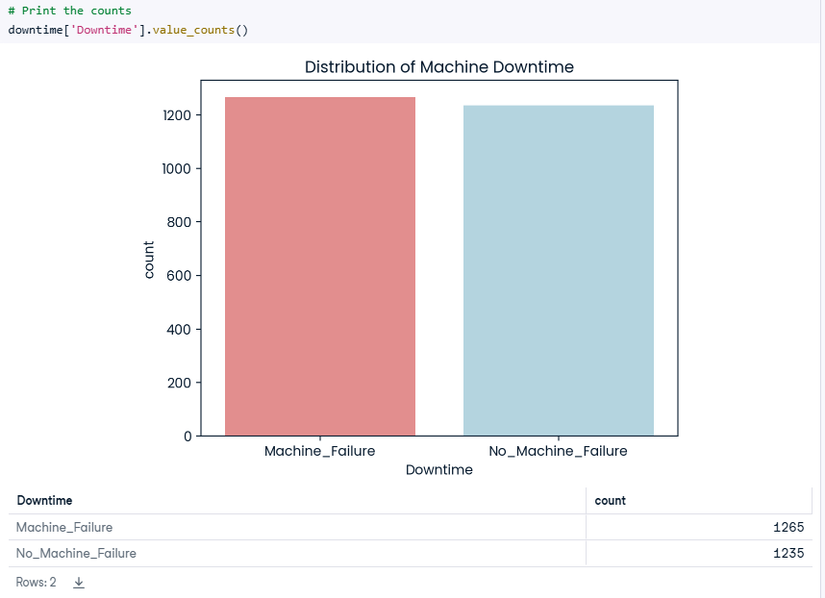
- Này nhìn bảng: 1265 vs 1235 là được rồi.
- Vẽ biểu đồ lên nhìn "cũng hay", nhưng không có mấy giá trị anh em nhé => BỎ!
.
Average Torque per Assembly-Line
Khoản này của bạn Abdulaziz tôi cũng rất ưng, rất đáng học hỏi anh em ạh. Nếu anh em chỉ dừng lại tính trung bình/trung vị momen xoắn "Torque(Nm)" theo yêu cầu của đề bài thì không mấy có giá trị nhé, +0.5 điểm thôi.
downtime.groupby('Assembly_Line_No')[['Torque(Nm)']].mean().round(2)}")
The average Torque for each Assembly Line:
Torque(Nm)
Assembly_Line_No
Shopfloor-L1 24.95
Shopfloor-L2 25.21
Shopfloor-L3 25.56
The total average Torque for all Assembly Line as once:
Torque(Nm) 25.23
- Trung vị: Torque(Nm) 25.23: OK
- Rồi có ý nghĩa gì? Có đáng kể gì? Đa phần lính mới thì sẽ dừng lại theo yêu cầu đề bài.
- Nhưng nếu tự định vị mình là một data-analysist thì mình phải "thấy" được ý nghĩa của các con số, anh em nhé.
.
Hãy xem cách bạn Abdulaziz "cố để thấy" ý nghĩa của con số Torque(Nm) 25.23, một nỗ lực rất đáng học hỏi.
# Create a boxplot to visualize the distribution of 'Torque(Nm)' according to 'Downtime' cases
sns.set(style="whitegrid")
plt.figure(figsize=(12, 6))
sns.boxplot(x='Downtime', y='Torque(Nm)', data=downtime, palette='coolwarm')
plt.title("Distribution of Torque(Nm) According to Downtime Cases")
plt.xlabel("Downtime")
plt.ylabel("Torque(Nm)")
plt.show()
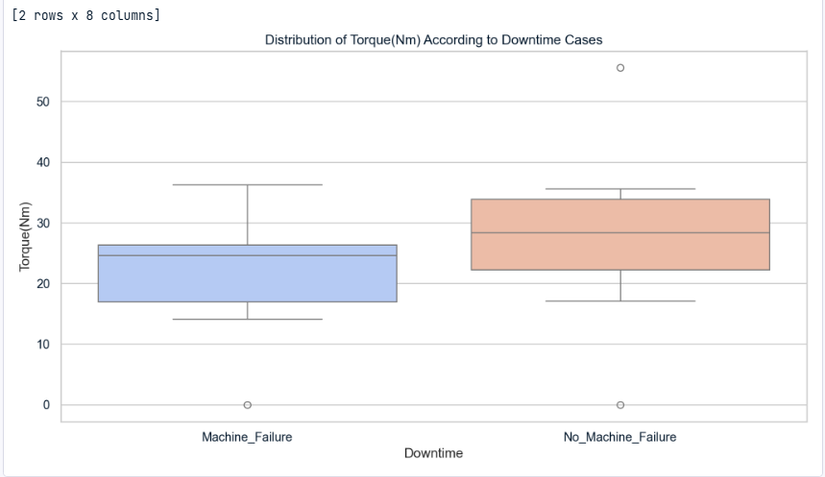
- Bạn dùng kỹ thuật: .boxplot() để thể hiện mối liên hệ giữa sự kiện Downtime, và tốc độ momen xoắn Torque(Nm). Kỹ thuật vẽ với plt. và seaborn sns. rất đáng để học hỏi anh em nhé. Trên datacamp.com/datalab cũng có sẵn AI rồi, anh em bảo AI vẽ cho tôi boxplot() nói đúng từ khóa là nó vẽ cho anh em trong phút mốt hen.
- "Nhìn" vào biểu đồ, thì có thể "thấy" con số trung vị Torque(Nm) 25.23 "có vẻ" liên quan tới sự kiện máy chết Machine_Failure. Anh em để ý một đường ngang ô màu xanh. Có thể ước tính sơ bộ, nếu máy đang quay, đang vận hành nhưng momen xoắn giảm xuống (máy yếu) dưới Torque(Nm) 25.23 thì khả năng máy sắp có sự cố.
- Các máy vận hành ổn định No_Machine_Failure, theo biểu đồ, thường có momen xoắn cao Torque(Nm) > 25.23.
- Ngoài ra không thấy được gì thêm! Cái này quan trọng nhé, anh em đừng "cố vẽ" ra làm gì. =))
Như vậy, với nỗ lực "cố để thấy" ý nghĩa con số Torque(Nm) 25.23 này của bạn Abdulaziz, bạn ấy xứng đáng được +3 điểm.
- Và bỏ túi hạng mục 🧑⚖️ Visualizations: anh em nhé.
.
Anh em có thấy bài của bạn Abdulaziz có khác nhiều so với bài của bạn Daniel hem? Rất hay ho đúng không nào. Đặc biệt khoản 🧑⚖️ Visualizations khá ấn tượng, tôi học được rất nhiều, mặc dù chỉ ngồi "soi" và chém gió anh em ạh. =))
Học được gì từ bài số 1?
Updated: 26/01/2025.
Chủ Nhật, 27 tháng Chạp, những ngày cuối năm Giáp Thìn, chào đón xuân Ất Tỵ. Tôi khởi động chuỗi bài này đúng vào dịp cuối năm, những ngày này được nghỉ nhiều mới có chút thảnh thơi, ngâm cứu, chém gió anh em ạh, chứ vào ngày thường thì sẽ bị tư bản dí đít cho sấp mặt. Ăn được một đồng của tư bản nó chua lét. =))
Khảo sát, bài số 1 của bạn John:
Can Precision Manufacturing Move Beyond Reactive Maintenance?
Lướt profile bạn này người Philipines, kinh nghiệm từ tháng 6/2023 chỉ mới có 2 năm thôi, nhưng profile có vẻ khá mạnh vì đã làm Leader cho một data-team nhỏ nhỏ rồi. Bạn treo một cái slogan cũng rất kêu trên profile:
- Believer, Doer, Achiever 💪
Anh em ạh, ngày nay thinker đông như quân nguyên, chỉ ngồi "think" thôi, và chém gió như tôi đang làm, mà 3 tháng, 6 tháng, 1 năm rồi vẫn không có kết quả gì mới mẻ và cụ thể. Nên anh em mà muốn "bứt phá" thì năm Ất Tỵ 2025 treo cái "Doer" làm khẩu hiệu HÀNH ĐỘNG của mình nhé. Tổng thống D. Trump cũng là một Doer idol điển hình, Trump mà "nghĩ" tới việc gì thấy hay ho => là Trump LÀM NÓ NGAY, sai thì sửa, không nói nhiều, làm ngay hôm nay, làm ngay những ngày đầu tiên nhậm chức tổng thống. Một tư duy rất quyết đoán và mạnh mẽ, khuyến nghị anh em nên học theo nhé!
.

Bố cục🧑⚖️ và yêu cầu 💪 của competition thì bạn John làm khỏi chê:
- 3 yêu cầu V. 1, 2, 3, được triển khai trong phần: "V. Analysis Report" rất chi là "gõ gàng"💪: OK
- Checklist ✅: Executive Summary: đưa lên đầu: OK
Note nhẹ: là có hơi đưa lên đầu quá, mình nghĩ là chỉ nên đưa lên sau phần Background và Data, khi người xem đã hiểu sơ sơ bài toán này nói gì thì mới summary nhẹ nhẹ được. Một số kết luận mà bạn John có được:- "Critical period: March 2022 showed highest failure concentration": OK
- "Torque transitions through 25.23 Nm represent critical failure points": OK. Như vậy: 2 "key insights" trong bài của bạn John khá giống bài của bạn Abdulaziz, chỉ khác là bạn John có phần kết luận, summary tốt hơn, mặc dù nhiều chi tiết khác vẫn còn hơi thừa.
.
Bây giờ chúng ta hãy xem bài bạn John có những điểm thú vị nào khác, cần học tập nhé.
.
Data Completeness Check
Trong data-analysis, việc làm sạch data là rất quan trọng, một trong những từ khóa chặng 1.3.x này là "Data Cleaning" đúng không nào? Anh em đã thấy ở Bài số 3 của bạn Daniel, chúng ta có thể làm sạch dữ liệu bằng 2 kỹ thuật cơ bản là: .isna() phát hiện NaN missing values, sau đó .fillna() điền vào chỗ trống các missing values với giá trị phù hợp.
Bạn John, "nâng tầm" khoản Data Cleaning này lên một level đúng chuẩn "industry" anh em nhé. Bạn ra hẳn luôn 1 cái REPORT bao gồm số lượng + tỷ trọng missing values:
=== MISSING DATA ANALYSIS REPORT ===
OVERALL STATISTICS
--------------------------------------------------
Total Number of Data Points: 40,000
Total Missing Values: 143
Overall Missing Percentage: 0.36%
VARIABLE-LEVEL ANALYSIS
--------------------------------------------------
Missing Count Missing %
Torque(Nm) 21 0.84
Coolant_Pressure(bar) 19 0.76
Air_System_Pressure(bar) 17 0.68
Hydraulic_Oil_Temperature 16 0.64
Coolant_Temperature 12 0.48
Spindle_Vibration 11 0.44
Tool_Vibration 11 0.44
Hydraulic_Pressure(bar) 10 0.40
Spindle_Bearing_Temperature 7 0.28
Cutting(kN) 7 0.28
Spindle_Speed(RPM) 6 0.24
Voltage(volts) 6 0.24
- Total Missing Values: 143:
Như đã nói ở Bài 1, con số này không mấy ý nghĩa nếu không đi cùng với tỷ trọng. - Overall Missing Percentage: 0.36% /40K records
- Torque(Nm): 21 0.84
Zay, cái này mới quan trọng nè!! Nhìn vào tỷ trọng missing values anh em sẽ thấy:- data cung cấp "data/machine_downtime.csv" có chất lượng quá tốt!! Hoặc là phần sensors tại nhà máy hoặc động quá ổn định, hoặc data đã được "làm sạch" trước đó.
- Với tỷ trọng missing values 0.36% thì tôi nghĩ anh em hoàn toàn có thể bỏ qua bước "data cleaning" nhé, nếu các phép toán liên quan tới số học + mix với NaN không bị lỗi. Còn nếu trong quá trình tính toán bị lỗi do NaN thì anh em cứ làm .isna() + fillna() vào là xong.
- Nếu tỷ trọng missing value quá cao, ví dụ 30%, 40% trên columnX: thì khuyến nghị anh em nên bỏ qua column X, vì dự đoán trên một trường data có quá nhiều lỗi là không đáng tin cậy.
.
Riêng với phần report và tỷ trọng 0.36% này, bạn John xứng đáng bỏ túi +3 điểm. Ngoài ra, phần biểu đồ của bạn John cũng có nhiều điểm hay ho.
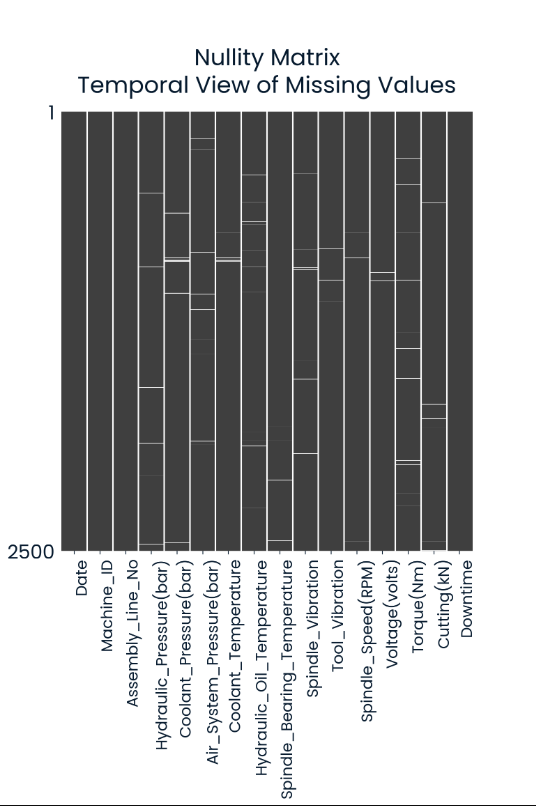
- Nulity Matrix: Biểu đồ này giúp anh em 'nhìn rõ" phân bố của các missing values, +1 điểm. Theo biểu đồ, thì các NaN, giá trị bị thiếu là các vạch màu trắng nhé anh em.
- Vì phân bố các missing values khá đồng đều, nên data có thể xem là tin cậy, tự tin không có gì cần phải kiểm tra thêm, + 1 điểm.
.
Biểu đồ này cũng rất hay:
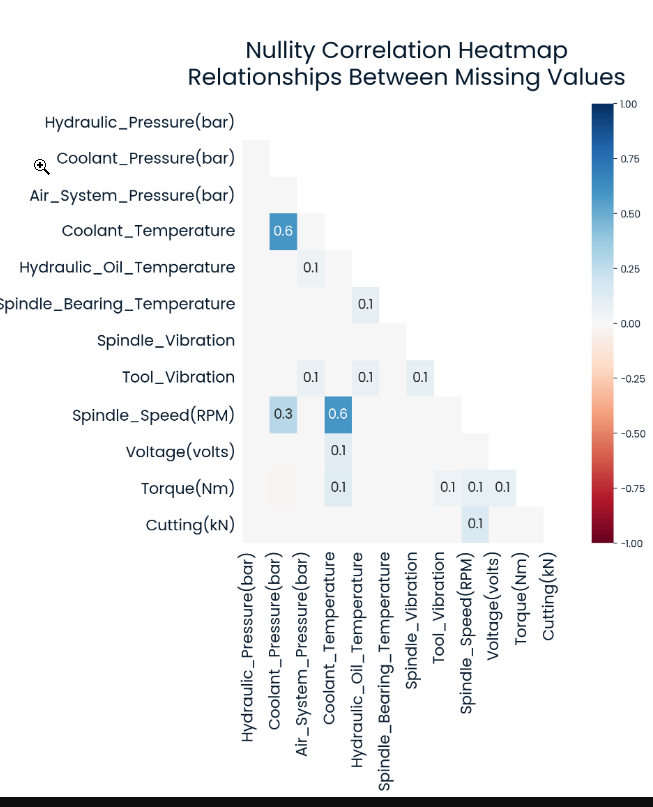
- Mặc dù mục tiêu của đề bài, không nói gì nhiều tới mối liên hệ của các trường dữ liệu, cơ bản Correlation check là không cần thiết.
- Tuy nhiên: nếu anh em chưa biết về Correlation: thì nên xem cho biết nhé.
- Nullity Correlation: cho biết mỗi liên hệ giữa các trường dữ liệu khi bị miss.
- Ví dụ trong hình: correlation = 0.6: mỗi khi Coolant_Temperature bị thiếu, thì Coolant_Pressure, Spindle_Speed bị thiếu, bị miss, không có giá trị theo luôn. Mặc dù không có gì nhiều để khai thác mối "liên hệ" (correlation) này trong bài, nhưng là một phương pháp rất hay để bỏ túi anh em nhé, +1 điểm.
.
Machine Failures Daily Heatmap
Để tìm ra ngày đầu, và cuối của báo cáo:
- Bạn Daniel dùng "code" sắp xếp theo "Date" rồi lấy ngày đầu và cuối => phong cách thuần "kỹ thuật".
- Bạn Abdulaiza dùng Daily Distribution, biểu đồ phân bố "Machine_Failure" theo "Date".
- Còn bạn John, trong bài bày thì dùng Daily Heatmap anh em nhé.
Anh em xem thử "Daily Heatmap" thì có vượt trội hơn so với "Daily Distribution" không hen?
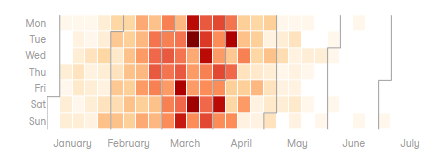
- Daily Heatmap: thì anh em sẽ thấy được phân bố "Machine_Failure" theo từng ngày trong tuần từ Thứ 2-Chủ Nhật luôn. Mặc dù dựa vào kết quả thì không thấy sự khác biệt lắm giữa ngày trong tuần T2-T6 vs T7+CN. Có lẽ 3 dây chuyền sản xuất được chạy xuyên suốt 24/7 cũng nên, chạy dữ quá nên "máy chết" cũng hợp lý anh em nhỉ? Máy cũng cần phải nghỉ đúng không nào?
- Điểm chung của Daily Heatmap và Daily Distribution là anh em sẽ thấy điểm nóng nhất tập trung vào khoảng tháng 3, Mar. Tuy nhiên biểu đồ Daily Distribution thì anh em sẽ thấy điều này "rõ hơn", và cũng thấy được khoản tích lũy "accumulated" như bạn Abdulaiza mô tả, còn Daily Heatmap thì không thấy được. Bạn John mất điểm, +0 khoản "accumulated" nhé.
.
What is the average Torque?
Mean Torque: 25.23
Median Torque: 24.65
Number of values between mean and median: 130
Percentage of total values: 5.20%
Như anh em đã biết, trung vị momen xoắn Torque: 25.23. Tuy nhiên vấn đề là con số Torque: 25.23 có ý nghĩa gì? Bạn John đã "quan tâm" tới việc đó ngay từ câu hỏi "what is .." bạn cũng đem Mean vs Median ra soi, và phát hiện ra trong khoảng Mean - Median chỉ có khoảng 5.20% real values. Điều này rất thú vị, nó có nghĩa là giá trị thực của Torque không tập trung ở Mean hay Median, mà phân bố ở 2 cực anh em nhé.
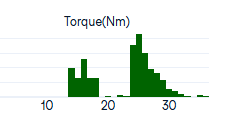
- Hơi "lạ" là tốc độ momen xoắn Torque lại phân bố thành 2 cực, nhờ phát hiện này => bạn John xứng đáng +2 điểm.
- Câu hỏi: có phải các máy chạy với Torque band thấp 13-19Nm là các máy có nguy cơ "chết máy" còn các máy chạy với Torque band cao 23-30 là các máy bình thường không? Không thấy bạn John giải mã khoản này, -1 điểm.
- Thông thường, nếu muốn đi sâu hơn, chúng ta có thể cố gắng gán nhãn, label cho 2 nhóm Torque này anh em nhé. Ví dụ gắn nhãn là Machine_Failure cho nhóm low-band, và nhãn No_Machine_Failure cho nhóm high-band tùy theo kết quả phân nhóm. Kĩ thuật gắn nhãn này được gọi là Clustering.
.
Như vậy sau bài của 3 bạn, chúng ta có thể quan sát rằng: hiện tượng "chết máy" xảy ra nghiêm trọng, và cao điểm vào tháng 3, có sự tích lũy, accumulated lỗi "chết máy" trong khoảng tháng 1 tới tháng 3 và vẫn chưa tìm ra được yếu tố nào liên quan. Trung vị momen xoắn Torque(Nm) 25.23, nhưng giá trị phân bố ở 2 cực, cũng chưa có phân tích cụ thể 2 cực này đại diện cho điều gì. Dây chuyền bị lỗi nhiều nhất là dây chuyền số 1: Shopfloor-L1: với 450 lỗi/1 năm (chiếm 51.95%), tỷ lệ 51.95% này khá "kì", vì lỗi "chết máy" thì thường chỉ lâu lâu mới bị, khoảng 10-20% này tới 51.95%, nên cũng cần làm rõ thêm. Như vậy còn rất nhiều "đất diễn" để anh em khai thác thêm nhé.
1.3.3 Vượt thử thách: làm bài
Tôi sẽ update kết quả, tóm tắt bài làm của tôi ở đây: khai thác các điểm còn lại chưa được khai thác bởi 3 bài top votes. To be continue... anh em lót dép hóng thêm nhé (First Update: 23/01/2025).
All rights reserved
