Cấu hình Startup, Readiness, Liveness Probe cho ứng dụng chạy trên Kubernetes
Mở đầu
Probes là các cấu hình được định nghĩa trong Deployment, StatefulSet,... dùng để kiểm tra trạng thái của pod nhằm mục đích đảm bảo pod vẫn đang hoạt động bình thường hay pod đã sẵn sàng nhận request từ client hay chưa. Việc không cấu hình hay cấu hình không phù hợp probe có thể gây ra downtime khi update ứng dụng, gây ra sự gián đoạn khi xử lý request từ người dùng hay gây ra timeout khi gửi request vào các pod chưa sẵn sàng...
Là một SRE (Server Reboot Engineer) để các điều trên xảy ra với service mình quản lý thực sự là một thảm họa và không thể chấp nhận được. Trước đây khi mới làm quen triển khai các dịch vụ trên Kubernetes mình đã trải qua việc cấu hình Probes và các logic cho API healthcheck không chuẩn, thành ra mỗi khi có các sự kiện như triển khai phiên bản mới, scaling, drain nodes,... là kiểu gì cũng sẽ có lỗi bắn ra ở đâu đó. Lỗi lúc đó không đủ lớn để bỏ effort ra tìm hiểu và sửa chữa tận gốc rễ, tuy nhiên các lỗi này xảy ra khá thường xuyên và vô tình trở thành 1 niềm đâu vô hình gây tốn kha khá effort để debug mỗi lần xảy ra lỗi. Vậy nên việc cấu hình đúng probes ngay từ đầu khi triển khai 1 service có thể khiến bạn nhàn hơn rất nhiều!
Trước hết
Bài viết này mình sẽ đi sâu về việc cấu hình các probe trong k8s sao cho hợp lý và logic của các API healthcheck cần thực hiện những gì chính vì vậy các bạn cần nắm được 1 số thông tin sau:
- Đã nắm rõ được cách thức cấu hình một service cơ bản trên môi trường K8s
- Hiểu được cơ bản vai trò các probe trong K8s. Nếu chưa biết về phần này bạn có thể đọc thêm ở bài viết này https://viblo.asia/p/kubernetes-best-practices-liveness-va-readiness-health-checks-4dbZN9R8KYM
Các loại probe trong Kubernetes
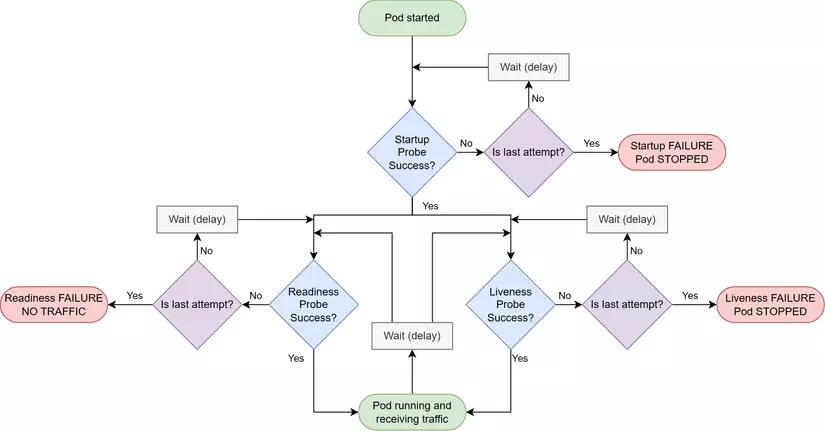
Hiện đến phiên bản 1.29 trong Kubernetes có 3 loại Probe là: Liveness, Readiness và Startup. Chúng ta sẽ cùng đi qua lần lượt từng loại Probe và cấu hình cho từng loại. Hình ảnh sau mô tả cách thức hoạt động của cả 3 probes trong Kubernetes, chi tiết từng probe hoạt động thế nào và cần lưu ý điều gì mình sẽ note ở từng probe.
Startup Probe
Đầu tiên là StartupProbe, đúng như cái tên của nó đây là loại sẽ chạy đầu tiên trong cả 3 probe khi pod vừa được khởi tạo. Chỉ khi startupProbe thành công thì Readiness và Liveness Probe mới có thể chạy.
Startup probe thường là không bắt buộc phải được định nghĩa, probe này thường được sử dụng để hoãn khoảng thời gian mà pod sẽ nhận traffic trong trường hợp ứng dụng cần một khoảng thời gian dài mới có thể sẵn sàng như một số ứng dụng Java,... Cách này cho phép thay thế cách sử dụng trường initialDelaySeconds trong readiness hay liveness để hoãn quá trình kiểm tra sự sẵn sàng của pod.
Cấu hình Startup Probe có dạng:
startupProbe:
httpGet:
path: /healthz
port: 5000
failureThreshold: 30
periodSeconds: 10
Cấu hình bên trên sẽ cho pod có khoảng thời gian tối đa failureThreshold * periodSeconds = 300 giây trước khi pod được đánh giá là không thể khởi động. Nếu sau 300s K8s không nhận được status code thành công từ path /healthz thì Pod sẽ bị kill. Trong khoảng thời gian tối đa 300 giây trên, ngay khi K8s nhận được phản hồi từ /healthz với status code thành công thì pod sẽ được chuyển sang giai đoạn tiếp theo để kiểm tra Readiness và Liveness.
Đối với API /healthz này logic phía sau đơn giản chỉ cần trả về 200 để phục vụ việc xác nhận ứng dụng đã chạy lên thành công, do sau khi pass probe này thì traffic người dùng vẫn chưa đẩy vào pod.
Readiness Probe
Readiness probe được dùng để xác định pod có sẵn sàng nhận traffic hay không? Nếu Kubernetes xác định pod đã sẵn sàng xử lý traffic, pod sẽ được thêm vào endpoint của service.
Nếu không có cấu hình Readiness, ngay khi container khởi động thành công và Pod được chuyển qua trạng thái Running, IP của pod sẽ được thêm vào trong Endpoint của service và traffic sẽ được gửi đến ngay pod đó. Trong trường hợp pod chưa sẵn sàng nhận traffic (do khởi động chậm, các bên thứ 3 chưa kết nối thành công, database sập,...) thì các request được gửi đến sẽ lỗi timeout, không được xử lý hoặc xử lý chậm. Chính vì vậy Readiness là probe mình cho rằng quan trọng nhất, luôn luôn phải có và cần phải xem xét thật kỹ càng để tinh chỉnh các thông số cho phù hợp với từng dịch vụ.
Cấu hình Readiness Probe sẽ có dạng
readinessProbe:
httpGet:
path: /readyz
port: 5000
initialDelaySeconds: 20
periodSeconds: 15
failureThreshold: 3
Là một Devops hay SR Engineer chúng ta đôi khi sẽ chỉ quan tâm đến những thông số cấu hình phía hệ thống mà không quan tâm đến logic code của các API healthcheck thực sự phải làm gì. Mình từng thấy rất nhiều trường hợp dev chỉ return 200 cho toàn bộ các API healthcheck, nếu như vậy thì việc các probes chạy sẽ không mang nhiều ý nghĩa. Như đã đề cập bên trên Readiness probe được dùng để xác định pod có sẵn sàng nhận traffic hay không, để sẵn sàng xử lý traffic thì pod cần có khả năng xử lý các chức năng một cách bình thường, hay nói cách khác, pod cần có thể kết nối đến các hệ thống liên quan và xử lý được các yêu cầu.
Ví dụ: Trong trường hợp Database bị chết, tuy nhiên app do return 200 nên vẫn trả thành công bình thường. Lúc đó K8s sẽ tin rằng ứng dụng vẫn đang hoạt động bình thường và gửi traffic vào đều đều, việc này là không hợp lý!
Vậy API sử dụng cho Readiness cần có logic gì? Theo mình API này cần có các logic sau:
- Kiểm tra kết nối đến database (Kết nối thành công, thực hiện 1 câu lệnh đơn giản)
- Kiểm tra kết nối đến các hệ thống bắt buộc bên thứ 3 (ví dụ service liên quan đến payment sử dụng API bên thứ 3 thì phải kiểm tra kết nối đến bên thứ 3 đó)
- Kiểm tra kết nối đến hệ thống cache
- Và rất nhiều nữa, tùy vào ứng dụng của bạn ...
Lưu ý:
- Câu lệnh thực hiện trong DB nên có độ đơn giản, không tốn nhiều năng lực xử lý và câu lệnh này nên độc lập (không liên quan đến dữ liệu ứng dụng)
- Trong 1 số trường hợp hệ thống cache chết nhưng ứng dụng của bạn vẫn có thể serving data từ DB hoặc ngược lại thì không nên thêm logic kiểm tra kết nối đến hệ thống cache. Cấu hình kiểm tra cả 2 chả khác nào tự bắn vào chân mình. 😅
Liveness Probe
Liveness Probe phục vụ cho việc xác định pod sống hay chết từ đó đưa ra quyết định restart pod. Trong một số trường hợp pod bị treo hay rơi vào deadlock thì trạng thái pod vẫn ở Running nhưng không thể serving requests nữa. Liveness Probe lúc này sẽ được thực hiện nhằm mục đích restart container dựa theo Policy đã được định nghĩa ở restartPolicy trong Pod.
Đọc thêm về
restartPolicyở đây!
Cấu hình Liveness thì cũng tương tự các probe khác:
livenessProbe:
httpGet:
path: /healthz
port: 5000
initialDelaySeconds: 15
periodSeconds: 10
failureThreshold: 3
Logic cho API được sử dụng cho Liveness thì cũng chỉ cần return 200 là được, do mục đích của Liveness Probe là để kiểm tra tình trạng của container còn sống và còn phản hồi được yêu cầu hay không.
Common Practices
Như vậy chúng ta đã tìm hiểu về cả 3 Probe, mục đích và những lưu ý khi sử dụng các Probe này. Vậy quan trọng nhất, trong thực tế các probe này được sử dụng như thế nào?
Do Startup Probe là không bắt buộc và chỉ sử dụng trong trường hợp ứng dụng khởi động lâu nên mình sẽ không đề cập trong phần này.
1, Sử dụng 2 API khác nhau cho liveness và readiness
Tốt nhất thì mình thấy nên sử dụng 2 API khác nhau /readyz cho Readiness và /healthz cho Liveness để check, cấu hình sẽ có dạng:
livenessProbe:
httpGet:
path: /healthz
port: 5000
initialDelaySeconds: 15
periodSeconds: 10
failureThreshold: 3
readinessProbe:
httpGet:
path: /readyz
port: 5000
initialDelaySeconds: 30
periodSeconds: 15
failureThreshold: 3
Một vài lưu ý:
- Nếu không sử dụng StartupProbe, bạn nên cấu hình
initialDelaySecondstầm 30 giây để đảm bảo ứng dụng hoàn tất quá trình khởi động và tránh việc gửi traffic khi resource peak trong quá trình khởi động. periodSecondskhoảng thời gian interval check nên được lựa chọn hợp lý (10-15 giây) để không gây áp lực lên hạ tầng của dịch vụ.failureThresholdkhông nên để quá cao
2, Sử dụng chung 1 API cho liveness và readiness
Cấu hình khi sử dụng chung 1 API cho cả liveness và readiness sẽ có dạng như sau:
livenessProbe:
httpGet:
path: /healthcheck
port: 5000
periodSeconds: 10
failureThreshold: 5
readinessProbe:
httpGet:
path: /healthcheck
port: 5000
initialDelaySeconds: 30
periodSeconds: 10
failureThreshold: 3
Khi sử dụng chung 1 API, failureThreshold của liveness sẽ cao hơn so với readiness với mục đích trong trường hợp có sự cố xảy ra, trước hết readiness sẽ fail và K8s sẽ ngắt traffic của người dùng vào các pod đang gặp vấn đề. Nếu tình hình tệ hơn, dịch vụ không thể tự được khắc phục, liveness sẽ tiếp tục fail và K8s sẽ tiến hành restart container.
Kết
Trên là những gì mình đúc kết lại trong quá trình làm việc, chắc chắn không thể tránh những sai sót và chưa hợp lý. Nếu có sai sót hay muốn thảo luận gì thêm hãy comment ở phía dưới nhé. Hy vọng bài viết cung cấp cho bạn thêm ý tưởng trong quá trình làm việc. Chúc các bạn thành công! 
Nếu thấy bài viết hay và hữu ích, hãy Upvote và Follow mình để theo dõi thêm nhiều bài viết khác nhé. Thank all!
Chuyên mục quảng cáo
Nếu như bạn đang gặp khúc mắc trong vấn đề chuyên môn hay cần người hỗ trợ về mặt hệ thống, DevOps tools thì mình tự tin có thể hỗ trợ được bạn. Liên hệ với mình để trao đổi thêm nhé https://hoangviet.io.vn/
All rights reserved
