Cassandra - Data Mode
Bài đăng này đã không được cập nhật trong 5 năm
Giới thiệu
Apache Cassandra lưu dữ liệu ở trong các bảng, mỗi bản bao gồm nhiều rows và columns. CQL (Cassandra Query Language) được sử dụng để query dữ liệu trong các bảng. Cassandra không hỗ trợ mô hình dữ liệu quan hệ dành cho relational databases.
Data Modeling
Data modeling là quá trình xác định các thực thể (entities) và mối quan hệ của chúng. Trong cơ sở dữ liệu quan hệ, dữ liệu được đặt trong các bảng chuẩn hóa với các khóa ngoại được sử dụng để tham chiếu dữ liệu liên quan trong các bảng khác. Những câu truy vấn mà ứng dụng sử dụng sẽ tập tụng vào cấu trúc của các tables và mối quan hệ giữa dữ liệu, thường được liên kết lại với nhau bằng việc joins các tables. Trong Cassandra, data modeling sẽ tập trung vào câu query. Các patterns để truy cập dữ liệu và các câu query trong ứng dụng sẽ là cơ sở để xây dựng cấu trúc và tổ chức dữ liệu rồi sau đó được sử dụng để thiết kế các bảng cơ sở dữ liệu. Dữ liệu được mô hình hóa xung quanh một (hoặc một tập) câu query cụ thế, tất các thực thể tham gia vào một truy vấn tốt nhất nên ở cùng một bảng để làm cho việc truy cập dữ liệu rất nhanh. Một table có thể có một hoặc nhiều thực thể, hay một thực thể cũng có thể ở trong nhiều tables.
Query-drive modeling
Không giống như model cơ sở dữ liệu quan hệ, các câu query sử dụng join để lấy dữ liệu từ nhiều bảng, join không được hỗ trợ trong Cassandra vì vậy tất các các trường trong câu query phải được nhóm lại với nhau trong một table. Bởi vì mỗi câu query được hỗ trở bởi một table, nên dữ liệu sẽ được sao chép trên nhiều bảng (bất chuẩn hóa - denormalization). Việc nhân bảng dữ liệu và mootjthoong lượng ghi cao được sử dụng để đạt được hiệu suất đọc cao.
Mục đích
Việc lựa chọn primary key và partition key rất quan trong để phân phối dữ liệu đồng đều trên toàn bộ cluster. Giữ số lượng phân vùng được đọc cho một truy vấn ở mức tối thiểu cũng rất quan trong vì các phân vùng khác nhau có thể nằm trên các node khác nhau và việc điểu phối để đọc sẽ cần gửi yêu cầu đến mỗi node làm tăng chi phí và độ trễ. Thậm chí nếu các phân vùng khác nhau trong một query ở trên cùng một node, ít phân vùng được đọc cũng tạo nên một câu query hiệu quả hơn.
Các phân vùng
Cassandra là một cơ sở dữ liệu phân tán, một partition key được sử dụng để phân vùng dữ liệu trong các node. Cassandra sử dụng một biến thể của consistent hashing để phân phối dữ liệu. Hashing là một kỹ thuật được sử dụng để ánh xạ dữ liệu với một khóa, một hàm băm tạo ra một giá trị băm được lưu trữ trong một bảng băm. Primary key được tạo từ trường đầu tiên của khóa chính (primary key). Dữ liệu được phân vùng thành các bảng băm bằng cách sử dụng các khóa phân vùng giúp tra cứu nhanh chóng.
Ví dụ trong table t có id là trường duy nhất trong khóa chính.
CREATE TABLE t (
id int,
k int,
v text,
PRIMARY KEY (id)
);
Partition key được tạo ra từ khóa chính id để phân tán dữ liệu ra các node ở trong một cluster.
Xem xét một biến thể khác của bảng t, có 2 trường ở trong khóa chính.
CREATE TABLE t (
id int,
c text,
k int,
v text,
PRIMARY KEY (id,c)
);
Trong bảng này, trường đầu tiên id sẽ được dùng để tạo ra partition key và trường thứ 2 c là clustering key được sử dụng để sắp xếp dữ liệu trong một partition. Sử dụng clustering key để sắp xếp dự liệu giúp việc truy xuất dữ liệu liền kề nhau hiệu quả hơn.
Ngoài ra, partition key cũng có thể được tạo từ nhiều trường nếu chúng được nhóm vào trong thành phần đầu tiên của khóa chính. Ví dụ bảng t sau, có thành phần đầu tiên của khóa chính được tạo từ 2 trường id1 và id2:
CREATE TABLE t (
id1 int,
id2 int,
c1 text,
c2 text
k int,
v text,
PRIMARY KEY ((id1,id2),c1,c2)
);
Thành phần đầu tiền của khóa chính ( id1, id2) được sử dụng để tạo partition key và các trường còn lại (c1, c2) là các clustering key được sử dụng để sắp xếp trong một phân vùng.
Nói chung, trường hoặc thành phần đầu tiên trong khóa được sẽ được hash để tạo ra partition key và phần còn lại là custering key được sử dụng để sắp xếp dữ liệu trong một phân vùng. Những trường khác không ở trong khóa chí cũng có thể sử dụng idex để tăng hiệu năng của câu query.
Ví dụ về Data Modeling
Giả sử, có một data set magazine bao gồm dữ liệu cho các tạp chí với các thuộc tính như id, tên tạp chí, tần suất xuất bản, ngày xuất bản và nhà xuất bản. Một câu query cơ bản (Q1) là liệt kê tất các các tên tạp chí bao gồm tần suất xuất bản. Vì không phải tất các các thuộc tính dữ liệu đều cần thiết cho Q1 nên mô hình dữ liệu sẽ chỉ bao gồm id, tên tạp chí và tần suất xuất bản như sau:
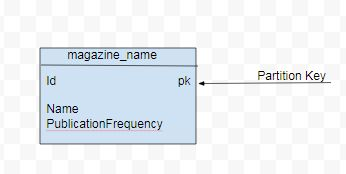
Query:
CREATE TABLE magazine_name (id int PRIMARY KEY, name text, publicationFrequency text)
Một câu query khác (Q2) để liệt kê toàn bộ tên tạp chí theo nhà xuất bản. Trong trường hợp này, data model sẽ bổ sung thêm thuộc tính pulisher làm partition key, thuộc tính id sẽ trở thành clustering key để sắp xếp dữ liệu trong một phân vùng:
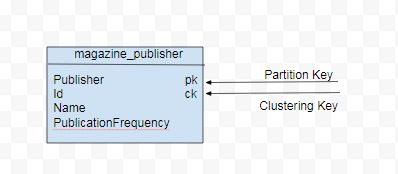
Query:
CREATE TABLE magazine_publisher (publisher text,id int,name text, publicationFrequency text,
PRIMARY KEY (publisher, id)) WITH CLUSTERING ORDER BY (id DESC)
Phân tích data model
Data model phải được phân tích và tối ưu hóa dựa trên dung lượng, khả năng lưu trữ, dự phòng và tính nhất quán. Một data model có thể cần phải chỉnh sửa sau khi thực hiện các phân tích. Những điểm cần cân nhắc khong quá trình phân tích data model bao gồm:
- Kích thước phân vùng
- Dữ liệu dự phòng
- Dung lượng ổ đĩa
- Lightweight Transactions (LWT)
Hai thông số để đo kích thước phân vùng là số lượng giá trị trong một phân vùng và kích thước của phân vùng trên đĩa. Đối với 2 thông số này có thể thay đổi tùy theo ứng dụng, nhưng nguyên tắc chúng là giữ số lượng giá trị trên mỗi phân vùng dưới 100.000 và dung lương đĩa trên mỗi phân vùng dưới 100MB. Dữ liệu dự phòng cũng như việc nhân bản dữ liệu trong bảng và nhiều phân vùng được kỳ vọng trong thiết kế mô hình dữ liệu, tuy nhiên nên được xem xét như một tham số để giữ ở mức tối thiểu. Các LWT (compare-and-set, cập nhật có điều kiện) có thể ảnh hưởng để hiệu suất và của truy vấn sử dụng LWT nên được giữ ở mức tốt thiểu.
All rights reserved
