"Cào" dữ liệu doanh nghiệp với Beautiful Soup một cách cực kỳ đơn giản
Bài đăng này đã không được cập nhật trong 6 năm
Cuối năm rảnh rỗi, đang ngồi lướt facebook thì thấy bà chị nhắn tin nhờ kiếm ít dữ liệu doanh nghiệp để spam sale  cũng đang rảnh nên thôi thì cũng giúp đỡ tý, lâu rồi không code cũng ngứa nghề
cũng đang rảnh nên thôi thì cũng giúp đỡ tý, lâu rồi không code cũng ngứa nghề 
Đầu tiên giới thiệu qua trang https://vinabiz.org/ là một trang cho phép chúng ta xem thông tin của các doanh nghiệp ở VN theo tỉnh, thành phố, nghành nghề,... tất nhiên thông tin cơ bản thôi nhưng qua đủ để các sale đi spam 
Để "cào" dữ liệu từ một trang web trươc hết phải xác định những thông tin sau:
- Cấu trúc dữ liệu cần lấy (các trường dữ liệu, kiểu dữ liệu)
- Các trang web load data về browser, thường thì trang web sẽ gọi API hoặc render trực tiếp vào trang HTML
- Dùng công nghệ gì để "cào"

- Code, code và code
Ngoài ra trong quá trình thực hiện sẽ vướng phải những vấn đề khác (vd. các trick để trang web chống lại các cào-er, ...) mình sẽ nói rõ ở phần sau. Chúng ta bắt đầu theo các bước từ trên xuống dưới Bài này mình sẽ dùng Python để code, còn tại sao lại là Python thì xin trả lời là nó nhanh, dễ code, dễ chạy, dùng text editor cũng code được mà không cần vác IDE ra (ở đây mình dùng Visual Studio Code của MS)
B1: Xác định cấu trúc dữ liệu cần lấy Thông tin của một doanh nghiệp trên https://vinabiz.org/ sẽ có dạng như sau:
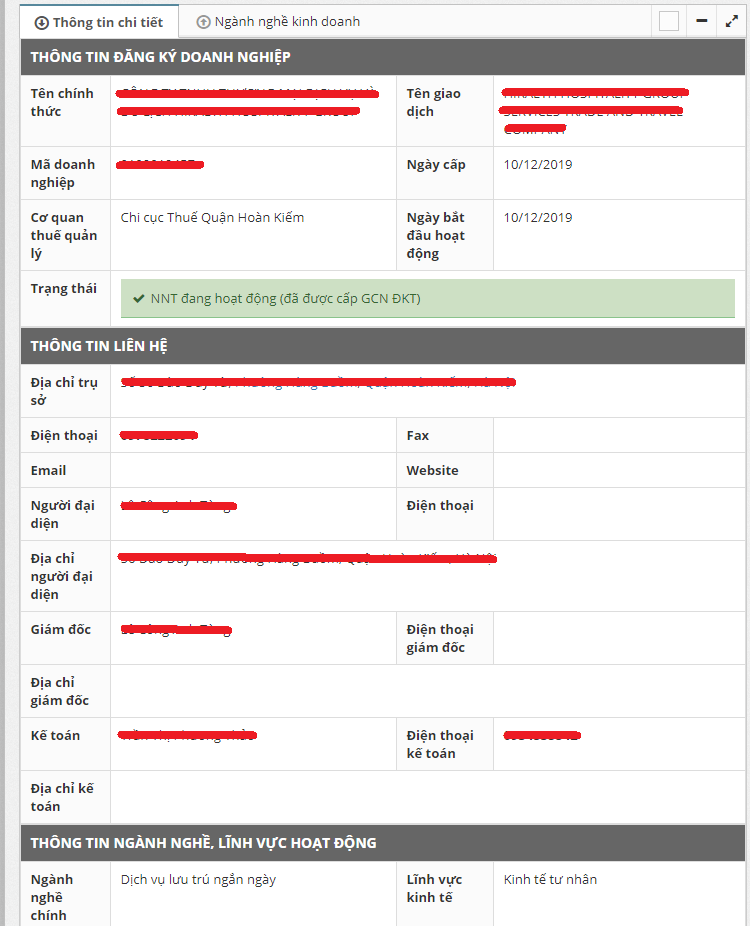
Tạo một Class với các attributes là các trường mình quan tâm
class Company:
official_name = ''
trading_name = ''
bussiness_code = ''
date_of_license = ''
start_working_date = ''
status = ''
address = ''
phone = ''
email = ''
director = ''
director_phone = ''
accountant = ''
accountant_phone = ''
business_lines = ''
def __repr__(self):
return str(self.__dict__)
Okay chúng ta đã xong bước đầu tiên, đơn giản nhỉ 
B2: Xác định cách trang web load data về
Cách đơn giản nhất và mình cũng mong muốn nhất là trang web load data về bằng cách gọi API. Bắt đầu mở Dev tool lên và check phần Network. Và thật là đ*o còn gì đen hơn, trang này có gọi API thật, nhưng mà lại là API Ads  Xác định phát này lại ngồi bóc HTML sml rồi!!!!
Xác định phát này lại ngồi bóc HTML sml rồi!!!!
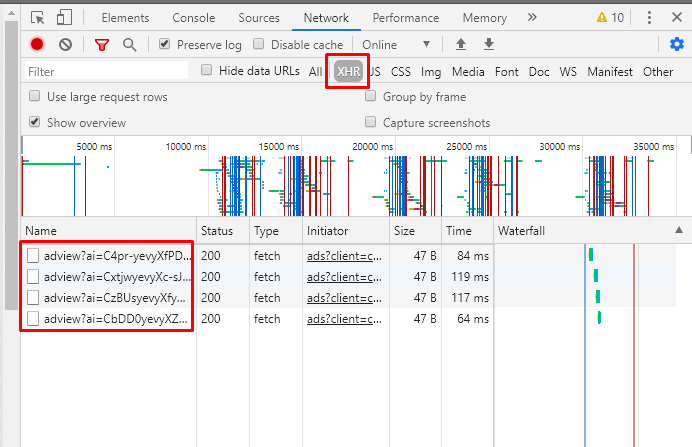
Tiếp tục dùng Network để tìm những request trả về data, và may mắn là chỉ cần Get request tới url của công ty là chúng ta đã có đầy đủ dữ liệu 
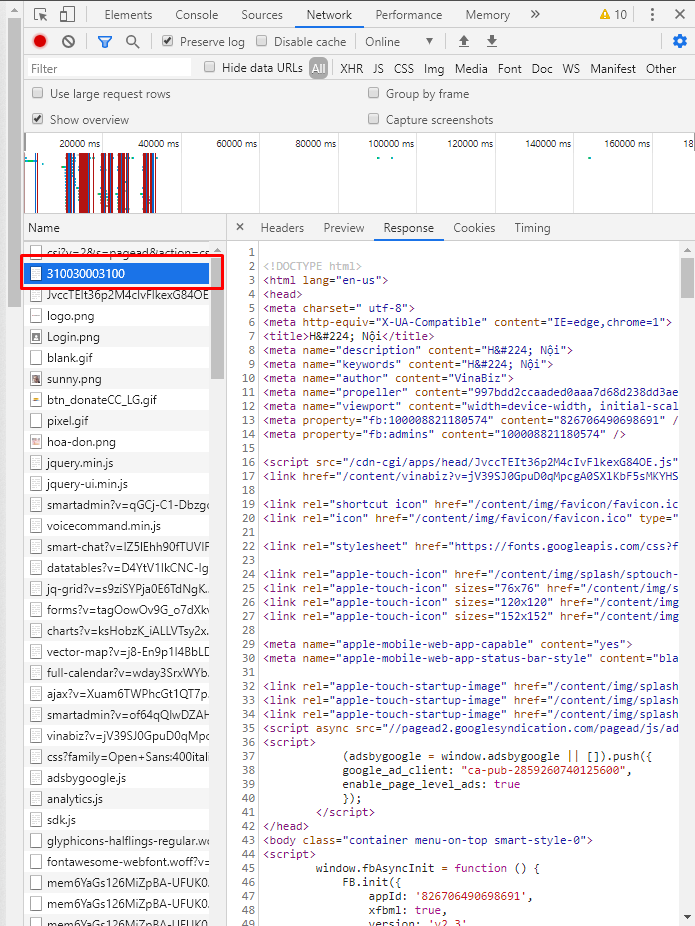
Thế là lại xong bước 2, có vẻ dễ hơn ăn cháo 
B3: xác định công nghệ để "cào"
Ngôn ngữ thì mình đã nói trước là sử dụng Python, còn để bóc tách HMTL thì có một thư viện đã quá nổi tiếng và quen thuộc rồi đó là Beautiful Soup. Thư viện này hỗ trợ rất nhiều ngôn ngữ khác nhau và tất nhiên là có cho Python, mình sẽ không nói về cách setup nữa, các bạn có thể xem thêm tại đây
B4: Đầy đủ thông tin rồi bắt tay vào cào thôi
Cấu hình Logging để có thể sử dụng tính năng log có sẵn của Python, rất tiện cho việc debug (thật ra dùng print() cũng được mà mình thích màu mè  )
)
import logging
log_format = '[%(levelname)s] - %(message)s'
logging.basicConfig(level='INFO', format=log_format)
Nhìn vào cách paging ta có thể thấy trang web này paging bằng path ở cuối url, số trang tương ứng luôn với path đó. Vì vậy ta cần xác định page bắt đầu và page kết thúc muốn lấy dữ liệu.
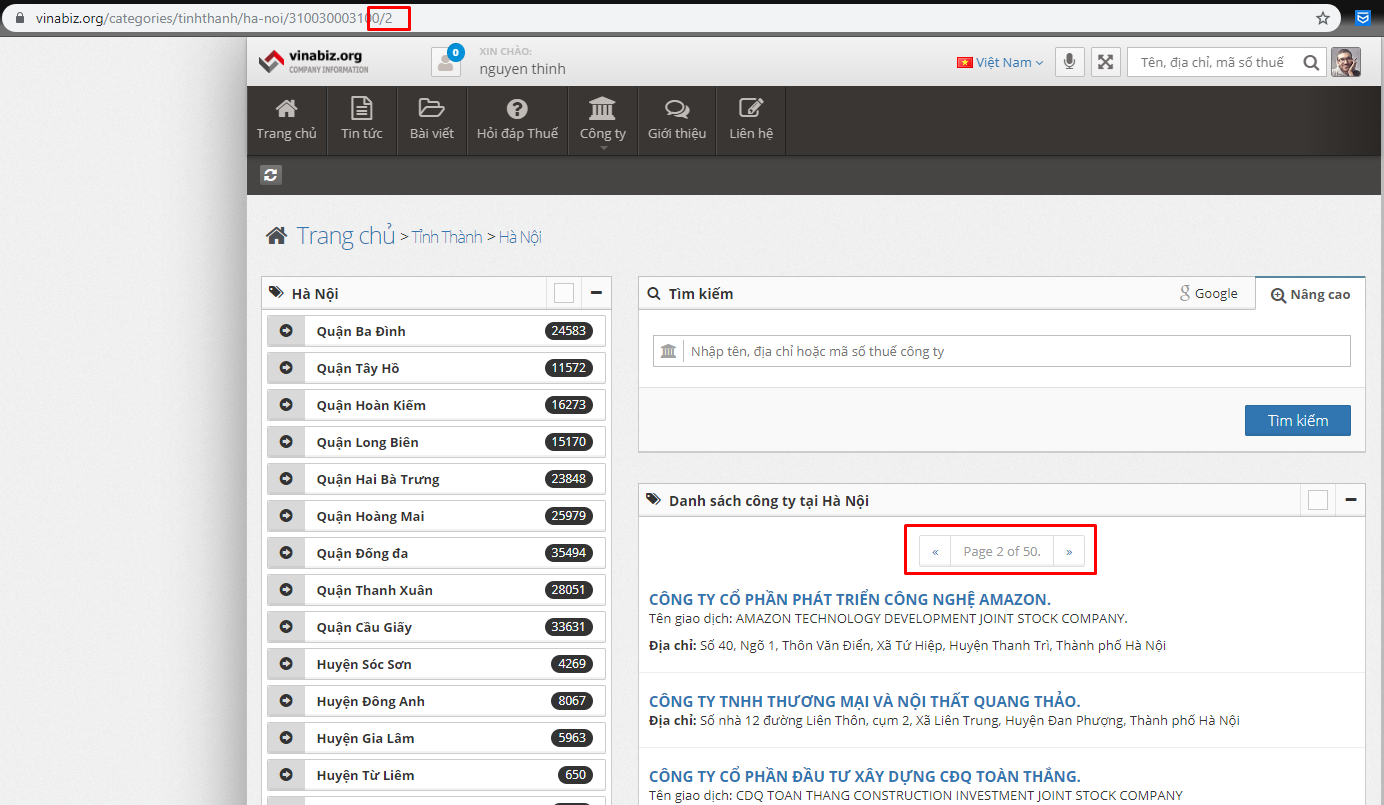
Bắt đầu khai báo các arguments cần thiết:
- url: link chứa danh sách các doanh nghiệp, có thể lấy theo tỉnh, thành, quận, huyện bla bla bla bla
- start: trang bắt đầu lấy
- end: trang cuối cùng cần lấy
- out: file lưu dữ liệu cào được
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--url", "-u", help="base url")
parser.add_argument("--start", "-s", help="start page")
parser.add_argument("--end", "-e", help="end page")
parser.add_argument("--out", "-o", help="output file")
args = parser.parse_args()
Nếu muốn màu mè có thể thêm phần validate cho các urguments  phần này phụ nên mình if else cho lẹ
phần này phụ nên mình if else cho lẹ 
def check_input():
if args.url is None:
logging.error('Please enter base url');
sys.exit(0)
if args.start is None:
logging.error('Please enter start page');
if int(args.start) <= 0:
logging.error('Please enter start page > 0');
sys.exit(0)
if args.end is None:
logging.error('Please enter end page');
sys.exit(0)
if int(args.start) > int(args.end):
logging.error('Please enter start page < end page');
sys.exit(0)
if args.out is None:
logging.error('Please enter output file');
sys.exit(0)
Luồng crawl chính sẽ tiền hành như sau:
- Request lên url chứa danh sách doanh nghiệp -> lấy được danh sách link chứa thông tin chi tiết của từng doanh nghiệp
- Request tiếp tơi link chứa thông tin doanh nghiệp đã lấy được ở bước trên -> bóc tách HTML trả về để lấy các thông tin cần thiết
- Sau khi lấy hết các thông tin các doanh nghiệp page này thì tiếp tục request tới page tiếp theo và lặp lại các bước bóc tách.
Để thực hiện các HTTP request ở đây mình sử dụng thư viện Requests của Python. Sau khi cài đặt để sử dụng chỉ cần import vào file code là được.
import requests
Hàm lấy ra danh sách url chứa thông tin chi tiết doanh nghiệp theo page. Danh sách doanh nghiệp được lưu bởi một danh sách các </div> có classs "row margin-right-15 margin-left-10". Sau khi request lên và nhận được HTML mình sử dụng Beautiful Soup để lọc ra tất cả các div đó và lấy giá trị của thuộc tính href của thẻ <a> nằm trong đó, chính là link chứa thông tin chi tiết của doanh nghiệp.
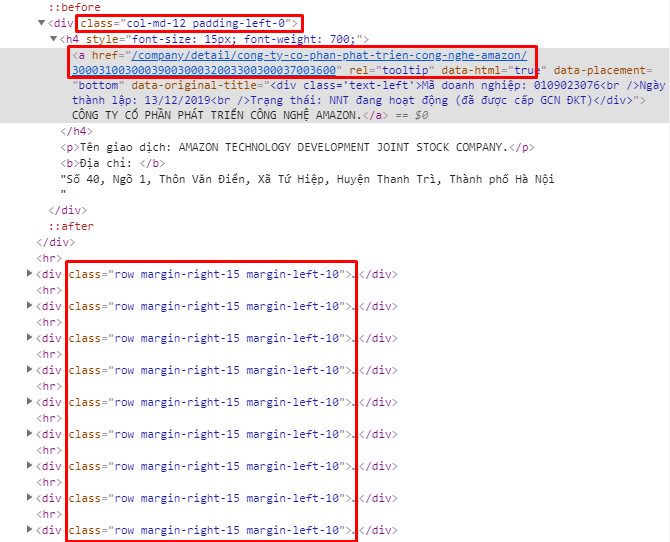
def request_list_company(page):
company_url_list = []
logging.info("getting list of company in page " + str(page))
url = args.url
if int(page) > 1 : url = url + str(page)
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
list_of_company_div = soup.find_all("div", class_= "row margin-right-15 margin-left-10")
for company_div in list_of_company_div:
if company_div.find('a')['href'] : company_url_list.append(company_div.find('a')['href'])
logging.info('Get total ' + str(len(company_url_list)) + ' company url')
return company_url_list
Khi đã có danh sách url chi tiết của các doanh nghiệp thì mình sử dụng một vòng lặp đơn giản và viết 1 hàm để lấy ra thông tin chi tiết của mỗi doanh nghiệp. Khi làm đến đây mình phát hiện ra một điều khá thú vị, nếu không login thì khi truy cập vào trang chi tiết một số thông tin như email, số điện thoại giám đốc, bla bla sẽ không hiển thị. Đây là một trick khá vui của trang web, và mình đi tìm cách bypass nó.
Trong request gửi lên mình phát hiện ra server sẽ check loggin session của user thông qua cookies được đính kèm.
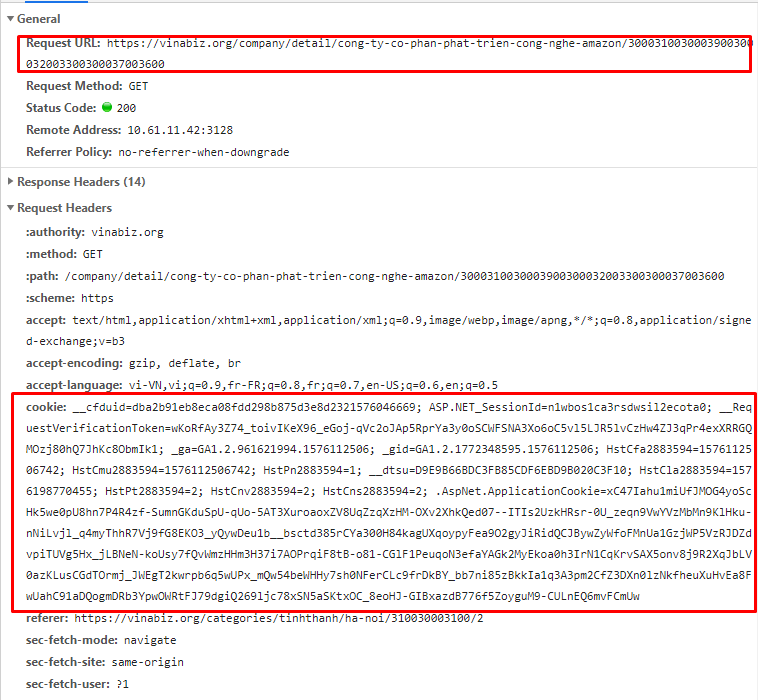
Để bypass đơn giản mình đăng nhập vào trang web sau đó khai báo một cái cookies ứng với session đang đăng nhập và gửi kèm theo request
cookie = '__cfduid=dba2b91eb8eca08fdd298...'
def get_company_details(url):
url = 'https://vinabiz.org/' + url
logging.info('Get company details in ' + url)
response = requests.get(url, headers={'Cookie': cookie})
Phần response chính là phần html trả về chứa thông tin, tiếp theo ra viết hàm để bóc tách thông tin từ đống html này. Data được đặt trong một table với class "table table-bordered", các thông tin ứng với từng hàng và cột trong table đó.
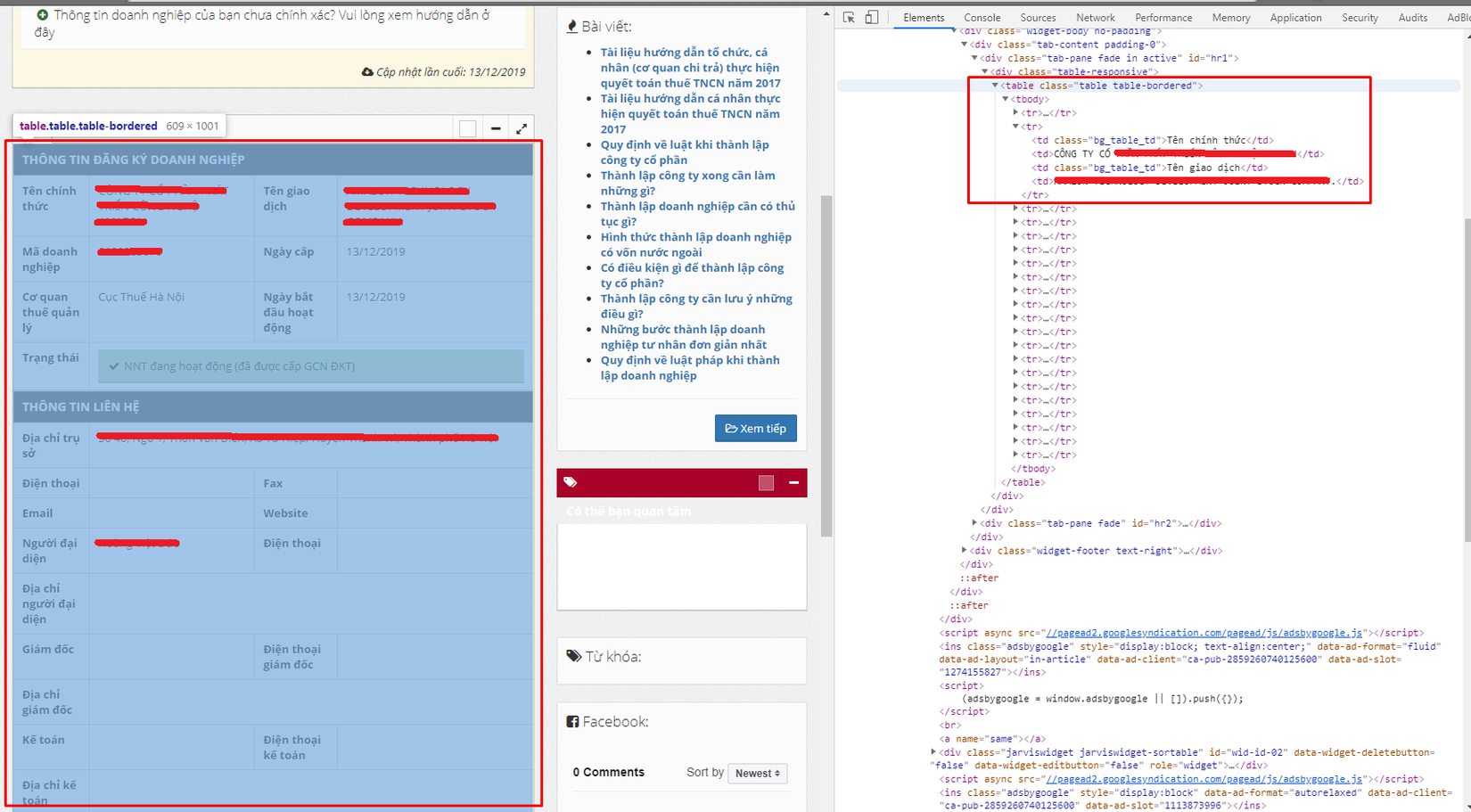
Viết một hàm để bóc tách dữ liệu của table này với input là response trả về từ hàm get_company_detail(url) và return một object Company như đã khai báo ở đầu bài.
def parse_company_detail(rows):
emailCode = None
company = Company()
company.official_name = rows[1].find_all('td')[1].get_text().strip()
company.trading_name = rows[1].find_all('td')[3].get_text().strip()
company.bussiness_code = rows[2].find_all('td')[1].get_text().strip()
company.date_of_license = rows[2].find_all('td')[3].get_text().strip()
company.start_working_date = rows[3].find_all('td')[3].get_text().strip()
company.status = rows[4].find_all('td')[1].find_all('div', class_='alert alert-success fade in')[0].get_text().strip()
company.address = rows[7].find_all('td')[1].get_text().strip()
company.phone = rows[8].find_all('td')[1].get_text().strip()
company.phone = rows[9].find_all('td')[1].get_text().strip()
company.director = rows[12].find_all('td')[1].get_text().strip()
company.director_phone = rows[12].find_all('td')[1].get_text().strip()
company.accountant = rows[14].find_all('td')[1].get_text().strip()
company.accountant_phone = rows[14].find_all('td')[3].get_text().strip()
return company
Sau khi làm phần này thì mình cứ nghĩ vậy là xong, nhưng đ*o Khi log phần data bóc được ra thì thấy email bị mã hóa thành [email protected]. Nhìn lại vào thẻ chứa thông tin email thì thấy email được mã hóa ở dạng sau
<a href="/cdn-cgi/l/email-protection#2e4d4140495a574a435e004d4100425a4a6e49434f4742004d4143">
<span class="__cf_email__" data-cfemail="c1a2aeafa6b5b8a5acb1efa2aeefadb5a581a6aca0a8adefa2aeac">[email protected]</span>
</a>;
Vì khi truy cập bằng browser thì email vẫn hiện ra bình thường -> suy nghĩ email này được decode bởi js phía client sau khi load trang. Tiếp tục lần mò mình phát hiện ra file email-decode.js Đây chính là cái chúng ta cần
Nhưng vấn đề là đây là code javascript, vậy lại cần một bước convert qua python code. Trong quá trình convert mình phát hiện ra một số hàm không liên quan tới việc decode mà chỉ là sửa các phần tử html sau khi decode. Sau khi convert email-decode.js qua Python ta sẽ được:
import urllib.parse
def r(e, t):
r = e[t:t+2]
return int(r, base=16)
def decode(n, c):
o = ''
a = r(n, c)
i = c + 2
xs = i
for x in range(i, len(n)):
if xs in range(i, len(n)):
l = r(n, xs) ^ a
o += chr(l)
xs = xs + 2
else:
break
try:
o = urllib.parse.unquote(urllib.parse.quote(o))
return o
except Exception as e:
logging.error(str(e))
Sau khi có hàm để decode email thì sửa lại set thông tin email của object Company như sau:
if rows[9].find_all('td')[1].find('span', class_='__cf_email__'): emailCode = rows[9].find_all('td')[1].find('span', class_='__cf_email__')['data-cfemail']
if emailCode is not None: company.email = decode(emailCode, 0)
else: company.email = ''
Hoàn thiện hàm get_company_detail(url)
def get_company_details(url):
url = 'https://vinabiz.org/' + url
logging.info('Get company details in ' + url)
response = requests.get(url, headers={'Cookie': cookie})
soup = BeautifulSoup(response.content, 'html.parser')
rows = soup.find_all("table", class_= "table table-bordered")[0].find_all('tr')
company = parse_company_detail(rows)
company_arr.append(company)
Luồng craw dữ liệu hoàn chỉnh, dữ liệu doanh nghiệp sẽ được lưu trong list của Company object với biến company_arr
def craw():
company_arr.clear()
for i in range(int(args.start), int(args.end) + 1):
company_url_list = request_list_company(i)
for company_url in company_url_list:
get_company_details(company_url)
logging.info('Get information of total ' + str(len(company_arr)) + ' companies')
Việc cuối cùng là ghi dữ liệu ra file excel  Để đọc/ghi excel mình hay sử dụng thư viện python xlwt các bạn có thể đọc cách cài đặt và sử dụng ở trang chủ.
Đầu tiên cần một hàm để ghi header cho file
Để đọc/ghi excel mình hay sử dụng thư viện python xlwt các bạn có thể đọc cách cài đặt và sử dụng ở trang chủ.
Đầu tiên cần một hàm để ghi header cho file
def write_sheet_header(sheet):
sheet_header = ['Tên chính thức', 'Tên giao dịch', 'Mã doanh nghiệp', 'Ngày cấp', 'Ngày bắt đầu hoạt động',
'Trạng thái', 'Địa chỉ', 'Điện thoại', 'Email', 'Giám đốc', 'SĐT giám đốc',
'Kế toán', 'SĐT kế toán', 'Nghành nghề']
for header in sheet_header:
sheet.write(0, sheet_header.index(header), header)
Tiếp theo viết hàm ghi data vào file từ list company_arr
def write_sheet_data(sheet, data):
for company in data:
attributes_arr = list(company.__dict__.keys())
print(attributes_arr)
for att in attributes_arr:
sheet.write(data.index(company) + 1, attributes_arr.index(att), str(getattr(company, att)))
Hoàn chỉnh hàm ghi dữ liệu
def write_result(data):
file = args.out + '.xls'
logging.info('Save result to file')
wb = Workbook()
sheet = wb.add_sheet('Data')
write_sheet_header(sheet)
write_sheet_data(sheet, data)
wb.save(file)
logging.info('Saved to ' + file)
Mọi mọi việc đã xong 99%, mình viết thêm 1 hàm main chạy khi ta gọi file
def main():
check_input()
craw()
if __name__== "__main__":
main()
Và bây giờ, chạy thử và xem kết quả nhé
Mở terminal và gõ
![]()
Kết quả
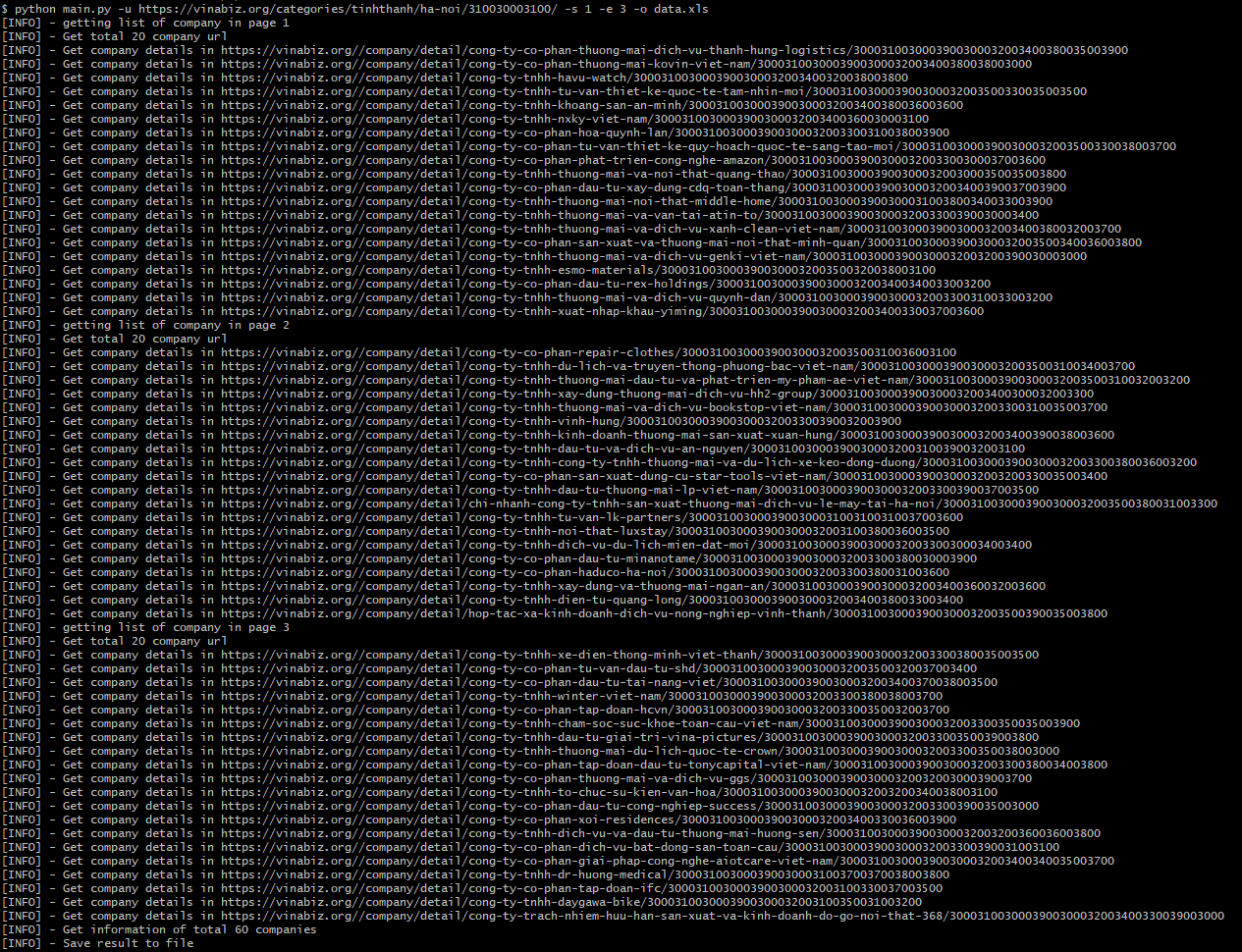
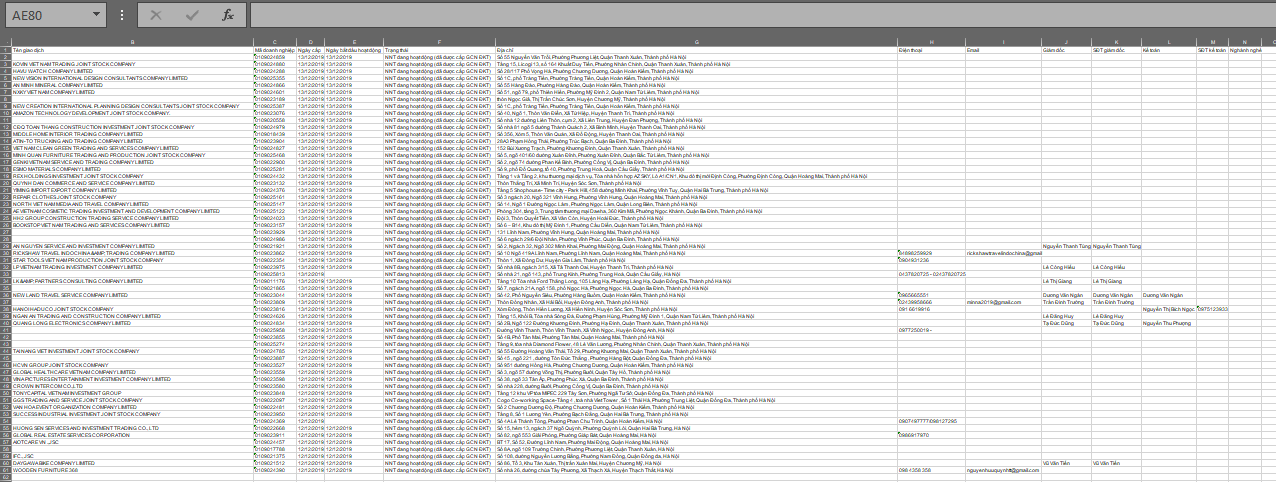
Vậy là xong =)) giờ các bạn có thể dùng thông tin đi làm gì thì làm
Full source tại đây, hy vọng các bạn sử dụng đừng spam quá nhiều
All rights reserved
