Cache stampede - Câu chuyện đàn thỏ
Bài đăng này đã không được cập nhật trong 3 năm
Ngày nay, với sự thành công của facebook. Từ người già tới trẻ nhỏ, hầu như ai cũng dùng facebook. Sự phát triển mạnh mẽ như vậy nhờ có đội ngũ engineer hùng hậu phía sau. Trong lịch sử của facebook, không từng ít lần trang web này xảy ra nhiều vấn đề nghiêm trọng, một trong số đó là sự kiện website bị sập bốn tiếng vào tháng 9 năm 2010(Link). Lí do cho việc facebook bị sập bốn tiếng là do thay đổ cấu hình, dẫn tới xảy ra tình trạng cache stampede, hay còn gọi là thundering herds.
Vậy cache stampede là gì? Làm sao để giải quyết nó? Các bạn hãy cùng mình tìm hiểu nhé.
Lời đầu tiên
Đầu tiên, mình là Ryan Cao, là một developer chân chính đang trên đường chém gió. Để ủng hộ mình các bạn có thể upvote bài viết này, follow Github Caophuc799 và đón đọc các bài viết trên Ryan Cao blog chính thức của mình để mình có thêm động lực chia sẽ những bài viết hay, ý nghĩa khác nhé
1. Cache stampede là gì?
Trước khi tìm hiểu về cache stampede thì mình sẽ cùng nhìn lại mô hình một backend gọi đọc dữ liệu từ cache và database nhé. Backend sẽ xử lí các yêu cầu từ người dùng, đọc dữ liệu từ database và trả thông tin cho người dùng.
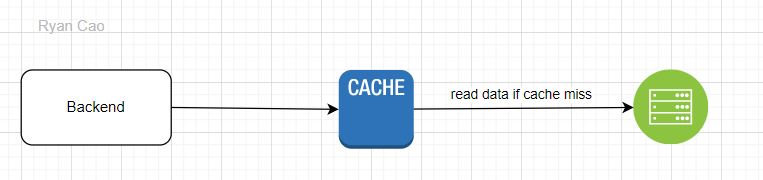
Để giảm tải cho database, chúng ta sẽ có thêm cache. Nếu xảy ra cache miss thì sẽ trực tiếp gọi vào database để lấy dữ liệu. Mình đã có bài viết chia sẽ về cache là gì, tại sao lại dùng nó, các bạn có thể đọc qua nếu chưa biết nhéChiến lược caching (Caching strategies). Tuy nhiên, khi mới khởi chạy hoặc khi dữ liệu bị hết hạn, cache thường sẽ rỗng dẫn tới liên tục xảy ra cache miss. Ví dụ như giờ cao điểm, có hàng trăm nghìn request từ backend tới cache, cache miss xảy ra dẫn tới backend tạo hàng trăng nghìn query vào database để lấy dữ liệu.
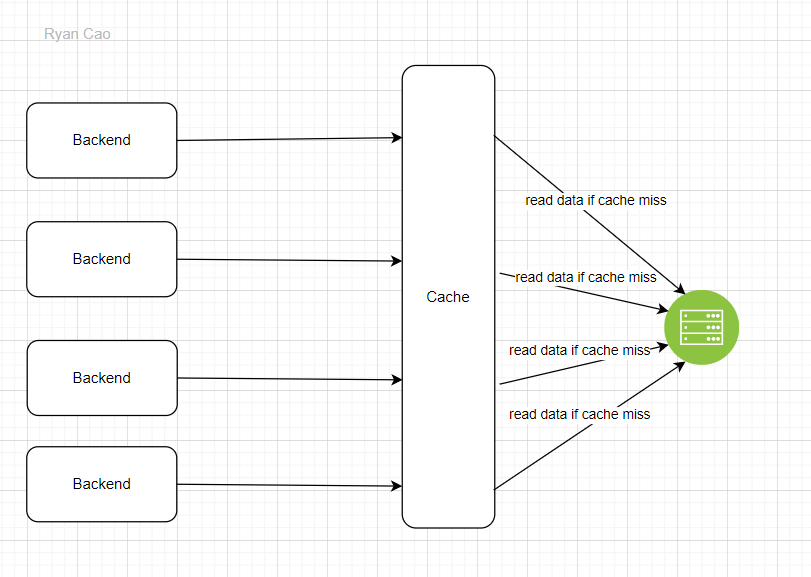
Lúc đó, database phải handle hàng trăm nghìn query. Một số trường hợp xấu có thể xảy ra:
- vì có hàng trăm nghìn câu query tới database dẫn tới database có thể bị chết, hoặc time out query
- Khi xảy ra tình trạng timeout thì chúng ta thường sẽ retry, khi retry thì lượng query tới database sẽ ngày càng nhiều hơn, dẫn tới database càng căng thẳng, rối loạn lo âu.
- Khi database bị căng thẳng thì sẽ càng xử lí chậm, mà xử lí chậm thì có thể sẽ timeout. Khi timeout thì lại retry, khi retry thì lại làm database càng căng thẳng, xì chét.
Vâng, với bất kì trường hợp xấu nào trong các trường hợp trên đều làm cho database bị xì chét, trầm cảm hay thậm chí là đột tử. Việc cache miss dẫn tới có hàng trăm nghìn request tới database chính là biểu hiện của cache stampede
Cache stampede hay còn gọi là thundering herds là thuật ngữ dùng để chỉ vấn đề khi một vài/nhiều threads truy cập vào cache song song cùng lúc nhưng xảy ra cache miss, lúc đó các threads đó sẽ lấy dữ liệu từ source chính như third-party, database... làm ảnh hưởng nghiêm trọng tới source chính.
Cache stampede thường xảy ra khi:
- mới khởi tạo, restart cache
- khi truy cập loại dữ liệu mới
Khi nào chúng ta cần quan tâm tới cache stampede? Thật ra, cache stampede xảy ra rất nhiều ở hầu hết các hệ thống. Hầu hết mọi người chưa quan tâm, chưa cần giải quyết nó vì lượng request chưa đủ nhiều cho trường hợp cache miss ở cùng một thời điểm, lúc đó database vẫn handle được lượng query.
2. Các cách giải quyết:
Để giải quyết cache stampede a.k.a thundering herds, chúng ta phải làm sao? Để giải quyết được nó, chúng ta cần giải quyết root cause là cache miss quá nhiều. Để giải quyết cache miss, chúng ta sẽ có hai hướng
- Giảm thiểu trường hợp cache miss ít nhất có thể. Để giảm thiểu được nó, chúng ta phải đảm bảo dữ liệu trong cache luôn tồn tại - tránh trường hợp cache bị rỗng. Tại sao cache bị rỗng? Cache rỗng khi mới khởi tạo, restart cache hoặc dữ liệu trong cache bị hết hạn. Chúng ta có thể dùng Exeternal computation hoặc Probalilistic early expiration để giải quyết.
- Với trường hợp không thể tránh khỏi cache miss, chúng ta tìm cách handle nó tốt hơn, một trong số đó là dùng lock hoặc promise. => Cái này là cái hay ho, là cái mình tâm đắt nhất trong bài này.
2.1 External Computation - early recomputation
Giải pháp này rất đơn giản, chúng ta sẽ khởi tạo giá trị ban đầu trong cache khi mới start cache. Sau đó, chúng ta sẽ tạo một worker để kiểm tra dữ liệu nào sắp hết hạn, nếu sắp hết hạn, worker sẽ vào database lấy dữ liệu lưu vào cache và extends thêm ttl cho dữ liệu trong cache. Chúng ta có thể cho worker chạy định kì(schedule, cron job...) hoặc trigger theo event expired từ cache.
Tuy nhiên, cách này có điểm bất lợi là trong cache sẽ chứa nhiều dữ liệu dư thừa, dẫn tới tốn resource của cache. Ví dụ như thông tin cấu hình của một tài khoản thường chỉ dùng một lần khi mở app, khi nó được đưa vào cache, worker sẽ giữ mãi dữ liệu này trong cache không chịu buôn mặc dù chúng ta không còn dùng tới nó nữa.
2.2 Probabilistic early expiration
Cách này được dựa theo một giải thuật của bài báo Optimal Probabilistic Cache Stampede Prevention. Công thức:
currentTime - ( timeToCompute * beta * log(rand()) ) > expiry
- currentTime là thời gian hiện tại
- timeToCompute là thời gian để tính toán lại dữ liệu
- beta là một giá trị cấu hình luôn lớn hơn hoặc bằng 0. Mặc định là 1.
- rand() là hàm trả giá trị ngẫu nhiên trong khoảng từ 0 tới 1
- expiry là thời gian tương lai nếu set expired.
Ý tưởng của phương pháp này là ngoài việc đọc dữ liệu trong cache và trả về cho backend, chúng ta sẽ chạy công thức trên, nếu kết quả là true thì chúng ta sẽ vào database lấy dữ liệu mới udpate vào cache + extends thời gian hết hạn. Nếu là false thì chúng ta không cần query dữ liệu trong database để update.
Cách này sẽ dựa theo xác xuất để biết dữ liệu nên hay không nên được update, từ đó tránh bị dư thừa như ở cách 2.1 External Computation - early recomputation mà còn đảm bảo hạn chế cache miss.
2.3 Lock
Để xử lí tốt hơn trường hợp cache miss, tránh tính trạng cache miss dẫn tới cache stampede chúng ta có thể dùng cách lock. Để hiểu đơn giản, khi một request tới backend, chúng ta sẽ vào cache để lấy dữ liệu dựa vào key. Khi có nhiều request cùng đọc vào một key đồng thời và đều gặp cache miss, lúc đó các request sẽ vào database query cùng một câu query => xảy ra cache stampede. Để hạn chế việc này, chúng ta có thể dùng lock để khóa lại key mà các request cần trong cache. Nếu gặp cache miss thì vào database query và update cache, update xong rồi release lock. Request tiếp theo mới được xử lí nếu cùng key lock.
Ví dụ: có 1000 request lấy thông tin sản phẩm có ID là Iphone14 tới đồng thời, vì tới đồng thời + gặp cache miss -> backend sẽ tạo 1000 câu query lấy thông tin sản phẩm có ID là Iphone14 trong database. Cách làm của lock: Xác định key được cache là Iphone14, ví dụ như chúng ta dùng redis để cache. Chúng ta sẽ dùng chức năng redlock của redis để lock key là Iphone14. Lúc đó chỉ có 1 request lấy thông tin Iphone14 được xử lí, các request lấy thông tin Iphone14 khác phải đợi. Request lấy thông tin Iphone14 sẽ lấy trong redis, phát hiện cache miss, sau đó sẽ query DB và update vào redis, release lock và trả kết quả. Tới request thứ 2 sẽ check trong redis, thấy có thông tin Iphone14, lúc đó request thứ 2 sẽ release lock và trả kết quả. Tương tự với request thứ 3, 4, 5... Như vậy, các request ban đầu kéo nhau một đàn vào database thì giờ sẽ qua cổng redlock, redlock sẽ bắt mọi request phải xếp hàng chờ tới lượt. Với việc áp dụng lock thì từ 1000 query vào database, giờ chúng ta chỉ còn 1 query vào database
Pseudo code:
class MyCache {
private lock = new Redlock();
private cache = new Redis();
async get<T>(key: string, fetchDataFromDatabase: () => Promise<T>, ttl: number): Promise<T> {
try {
let value = await cache.get(key);
if (value != null) {
return value;
}
lock.acquire();
value = await cache.get(key);
// Check value in cache before quering database
if (value != null) {
return value;
}
value = await fetchDataFromDatabase(key);
// Update cache
cache.set(key, value, ttl);
return value;
}
finally {
lock.release();
}
}
Cá nhân mình thấy cách này khá đơn giản, dể làm.
2.4 Promise
Vâng, cuối cùng đã tới promise, cách mà mình thấy tâm đắc nhất. Để hiểu về cách này thì chúng ta có thể nhìn vào hình bên dưới:
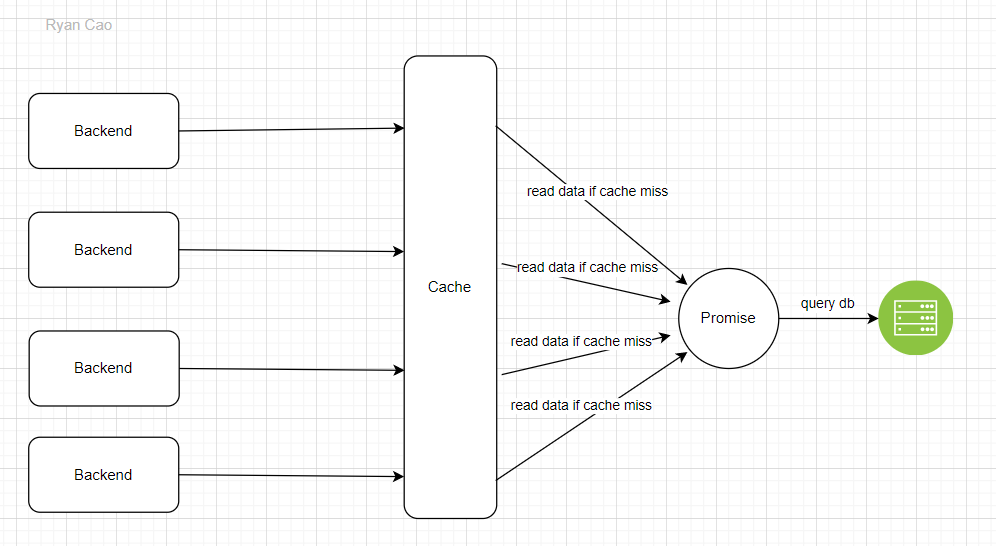
Ý tưởng của cách này nhìn thì có vẻ khá giống với lock. Nhưng thật ra hai cái khác nhau đấy bạn. Khác ở chỗ là thay vì chúng ta bắt các request phải xếp hàng chờ đợi, thì chúng ta sẽ gắn các request vào callback của promise. Khi một promise được chạy xong thì tất cả các request đều có kết quả, chứ không cần phải xếp hàng vào cache kiểm tra nữa. Nodejs bỗng dưng trở nên khít với giải pháp này một cách lạ thường. Nodejs được chạy với cơ chế single-threaded. Do đó việc tạo global variables để lưu trữ promise rất thuận tiện, không cần phải handle cho trường hợp nhiều thread cùng lúc.
Pseudo code:
const promiseCallingDBMaps: Map<string, Promise<unknown>> = new Map();
const get = async (key: string, fetchDataFromDatabase: () => Promise<T>, ttl: number): Promise<T> => {
let value = cache.get(key);
if (value != null) {
return value;
}
// Check if key is being processed in promiseCallingDBMaps
if (promiseCallingDBMaps.has(key)) {
return promiseCallingDBMaps.get(key) as Promise<T>;
}
try {
const promise = fetchDataFromDatabase(); // Mình Cố tình không dùng await
// store key + promise in promiseCallingDBMaps
promiseCallingDBMaps.set(key, promise);
value = await promise;
} finally {
// Remove key from promiseCallingDBMaps when done
promiseCallingDBMaps.delete(key);
}
await cache.set(key, value, ttl);
}
Ở dòng const promise = fetchDataFromDatabase(); mình cố tình không dùng await, bởi vì mình muốn lưu trữ promise đó vào trong promiseCallingDBMaps trước khi mình đợi promsie đó thực hiện xong. Với cách này, khi các request tới, việc đầu tiên mà chúng ta làm là check trong cache xem có giá trị không. Nếu không có giá trị, lúc đó chúng ta sẽ check trong promiseCallingDBMaps xem thử có promise nào đang gọi tới database với key đó không? Nếu có promise tới database thì chúng ta sẽ đợi kết quả của promise đó.
Nếu không có promise nào, lúc đó chúng ta mới tạo một promise gọi vào database và lưu promise đó vào promiseCallingDBMaps. Sau đó chúng ta sẽ dùng await để đợi promise đó thực hiện xong và lưu kết quả vào cache rồi trả về cho người dùng. Trong lúc đó, nếu có request khác tới có cùng key với request đầu, thì họ sẽ xách ghế ngời đợi cùng request đầu.
Với phương pháp này, chúng ta có thể giảm tối thiểu số lượng query vào database, lại tận dụng được ưu điểm single-thread của nodejs.
3. Tổng kết:
Trên đây là những kiến thức mình góp nhặt, tổng hợp được. Mong chúng hữu ích với các bạn.
Khoan, dừng lại khoản chừng là 2 giây. Vậy cache có liên quan gì tới câu chuyện đàn thỏ? Cache stampede là thundering herds. Thunder là sấm, sấm là thỏ(Thor trong MCU), herds là đàn => thundering herds là đàn thỏ. 🤣😂😂😂😂
Đừng quên upvote bài viết này, follow Github Caophuc799 và đón đọc các bài viết trên Ryan Cao blog chính thức của mình để mình có thêm động lực chia sẽ những bài viết hay, ý nghĩa khác nhé
All rights reserved
