Cách thức hoạt động của các hệ thống stream processing(P2)
Bài đăng này đã không được cập nhật trong 7 năm
Trong phần trước, chúng ta đã làm quen với cách tiếp cận lưu log thay cho việc cập nhật cơ sở dữ liệu theo cách truyền thống cũng như lợi ích của nó mang lại như: tăng performance, độ tin cậy cao, dễ dàng mở rộng ... Tuy vậy, việc thay đổi cách thức lưu trữ và xử lý dữ liệu rõ ràng không hề đơn giản bởi lẽ các hệ thống này vẫn đang chạy, cho nên đập đi làm lại không phải là giải pháp tối ưu.
1. Change data capture (CDC)
Dữ liêu được lưu trong DB, nhưng đôi khi chúng cũng được copy sang những nơi khác như full-text index, cache, data wirehouse nhằm tăng tốc độ đọc hoặc giảm tải cho database.
Log vẫn là giải pháp hữu hiệu thực hiện công việc này, chúng ta hoàn toàn có thể trích xuất dữ liệu từ database hiện có và lưu vào log
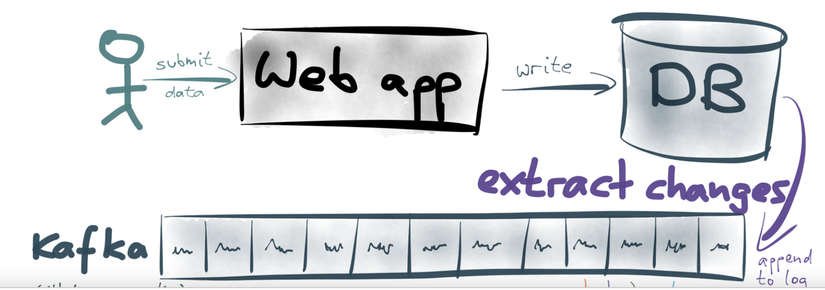
Câu hỏi đặt ra là : Làm thế nào để đưa dữ liệu từ DB vào log mà không làm thay đổi hiện trạng sẵn có của hệ thống đó ?
Nếu bạn cần copy cơ sở dữ liêu vô search serrver bạn chỉ việc tạo snapshot của DB hiện có và import vào search server, hầu hết các cơ sở dữ liệu đều hỗ trợ việc tạo snapshot như mysqldump, pg_dump. Tuy vậy dữ liệu trong DB luôn biến động, snapshot bạn tạo bị outdated trươc khi quá trình copy data kết thúc. Vấn đề là chỉ có một phần nhỏ DB bị thay đổi nhưng bạn vẫn phải tạo snapshot cho toàn bộ DB. Bạn có thể tăng tần suất tạo snapshot lên 1 lần 1 ngày, 1 lần 1 giờ hoặc hơn nữa, nhưng cũng không thể đáp ứng được khi dữ liệu thay đổi trong 1s, 1/100s.
Nếu ta coi việc DB update cũng giống như stream of events, tức là hễ có ai đó cập nhật cơ sở dữ liệu thì được coi như event trong stream, nêu thứ tự apply được đảm bảo giống DB gốc, chúng ta đã có một bản sao chính xác của DB
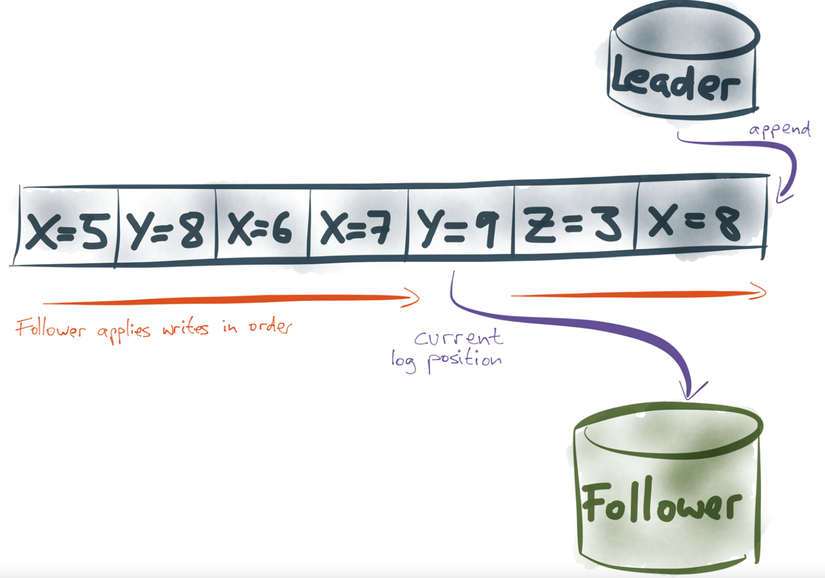
Ta có thể thấy DB Leader tạo ra 1bản sao log, bản chất là một chuối các sự kiện nối tiếp nhau tương ứng với nhưng thay đổi của DB leader. Để đảm bảo dữ liệu phía follower luôn cập nhật với Leader, follower chỉ việc apply tuần tự theo chuỗi các sự kiện này.
Change Data Capture thực chất là sao chép dữ liệu từ storage này sang storage khác, để làm được điều này cần đảm bảo 2 điều kiện
- Consistent Snapshot của toàn bộ cơ sở dữ liệu tại thời điểm đó
- Realtime stream changes: cần có stream of events thay đổi tư thời điểm tạo snapshot đó trở đi Phương pháp này được áp dụng trong các cty lớn như: Databus của LinkedIn, Wormhole của Facebook. Kafka tích hợp api có tên Kafka connect- dùng kết nối với Kafka với hệ thống khác, bằng việc sử dụng CDC, nó sẽ đưa snapshot và stream of changes lên Kafka.
2. Triển khai Snapshot và change stream
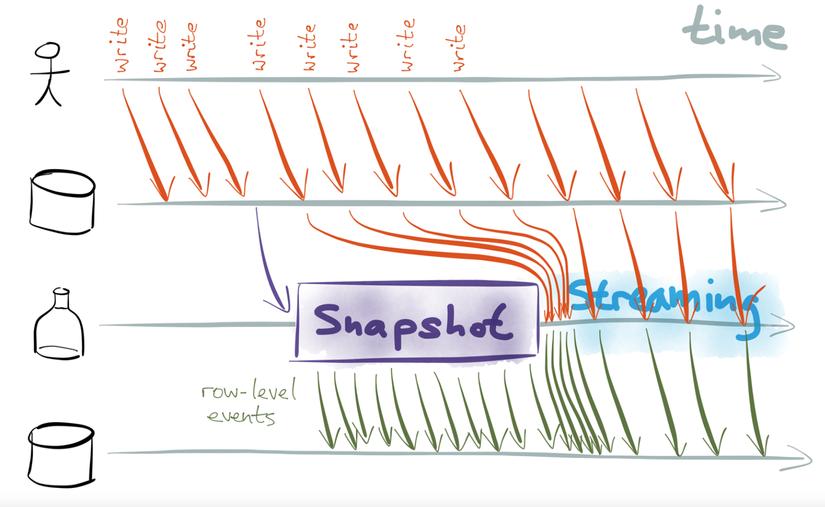 Như chúng ta thấy, User vẫn đang tiêp tục đọc và ghi dữ liệu. Hiện nay có nhiều cơ sở dữ liệu cho phép chúng ta tạo snapshot tại một thời điểm mà không cần locking DB.
Streaming change trong trường hợp này cần chứa chính xác những thay đổi dữ liệu xảy ra trong quá trình tạo snapshot (do trong thời gian snapshot được tạo, clients tiếp tục cập nhật, ghi thông tin vào DB, stream events cần move các sự thay đổi này vào queue và gửi đến log khi quá trình snapshot hoàn thành).
Như chúng ta thấy, User vẫn đang tiêp tục đọc và ghi dữ liệu. Hiện nay có nhiều cơ sở dữ liệu cho phép chúng ta tạo snapshot tại một thời điểm mà không cần locking DB.
Streaming change trong trường hợp này cần chứa chính xác những thay đổi dữ liệu xảy ra trong quá trình tạo snapshot (do trong thời gian snapshot được tạo, clients tiếp tục cập nhật, ghi thông tin vào DB, stream events cần move các sự thay đổi này vào queue và gửi đến log khi quá trình snapshot hoàn thành).
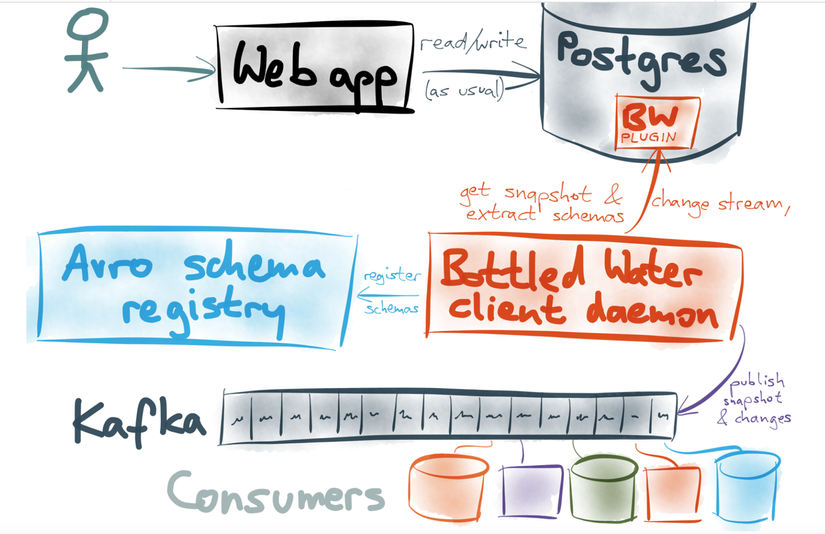
Một trong những giải pháp phải kể đến đó là Kafka + Posgres + Bottled Water
Tham khảo: http://nathanmarz.com/blog/how-to-beat-the-cap-theorem.html https://dzone.com/articles/making-sense-of-stream-processing
All rights reserved
