Cách thức hoạt động của các hệ thống stream processing(P1)
Bài đăng này đã không được cập nhật trong 7 năm
Ở bài viết trước, chúng ta đã hiểu sơ lược về Stream Processing là gì . Trong bài này chúng ta hãy xem các thức hoạt động của nó cũng như làm thế nào Stream Processing lại có thể khiến cho các hệ thống lưu trữ và xử lý dữ liêu của bạn trở nên linh hoạt hơn, bớt phức tạp hơn, đáng tin cậy, dễ dàng mở rộng, dễ dàng bảo trì.
1. Xử lý dữ liệu trong một ứng dụng lớn khó như nào ?
Giả sử chúng ta có một ứng dụng web, trường hợp đơn giản nhất là kiến trúc ba tầng như sau: Ứng dụng này phục vụ cho một số đối tượng người dùng, có thể là web, cũng có thể dùng mobile. Ứng dụng cho phép người dùng lưu trữ và truy xuất dữ liệu trong database.
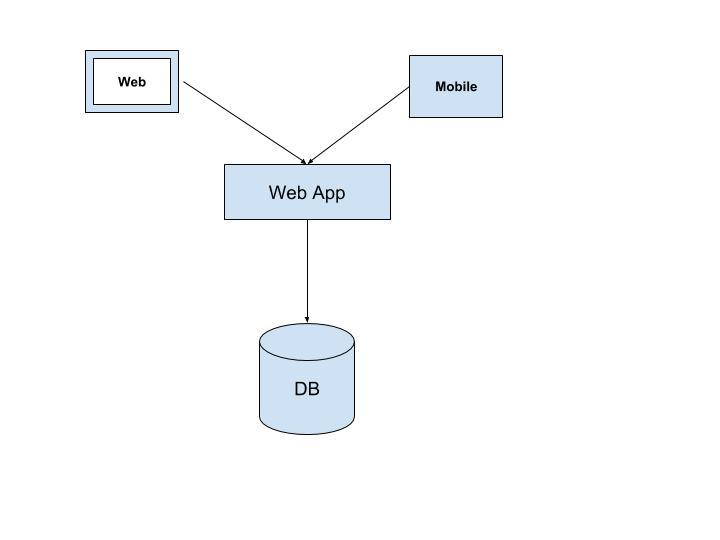
Vào một ngày kia, bạn nhận ra rằng mình có nhiều người dùng hơn, thực hiện nhiều yêu cầu hơn, database của bạn trở nên ì ạch, bạn cần thêm bộ nhớ đệm để tăng tốc cho nó (memcaches hoặc Redis chẳng hạn). Bạn cũng lại cần tích hợp thêm full-text search, khi mà cách tìm kiếm cơ bản được tích hợp trong cơ sở dữ liệu của bạn không đủ tốt, và rồi bạn quyết định sử dụng Elasticsearch, hay bạn cần move một số xử lý chạy background job, gửi mail
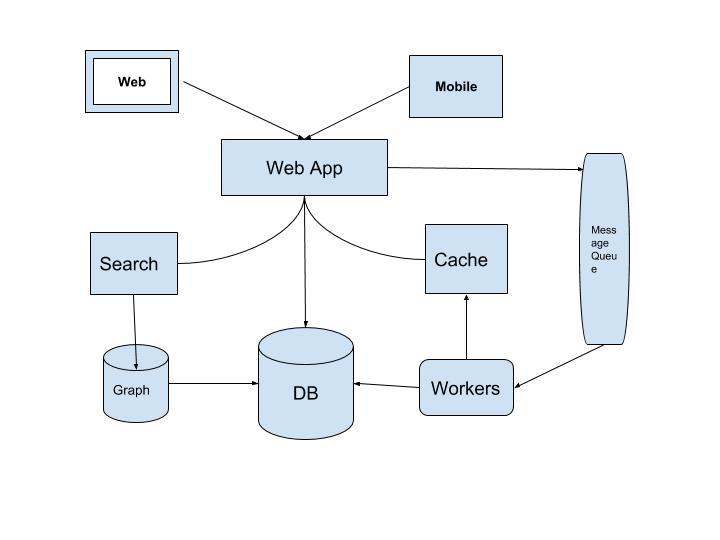
Ngày qua ngày các phần khác của hệ thống cũng trở nên chậm, bạn lại thêm cache, về lý thuyết thêm cache có thể khiến hệ thống chạy nhanh hơn. Lúc này đây, chúng ta có rất nhiều services đang chạy, cần phải quản lý chúng để xem các services này có hoạt động thực sự tốt hay không. Tiếp theo bạn lại muốn gửi thông báo cho người dùng, push notification khi có bất kỳ thay đổi hay thông tin mới, và thế là bạn lại cần thêm 1 hệ thống thông báo ngay cạnh hàng đợi workers và có thể sẽ cần 1 DB riêng để tracking .Càng ngày chúng ta càng thấy hệ thống càng trở nên rắc rối, gặp nhiều bất cập trong việc thêm tính năng cũng như giải quyết bài toán scalable.
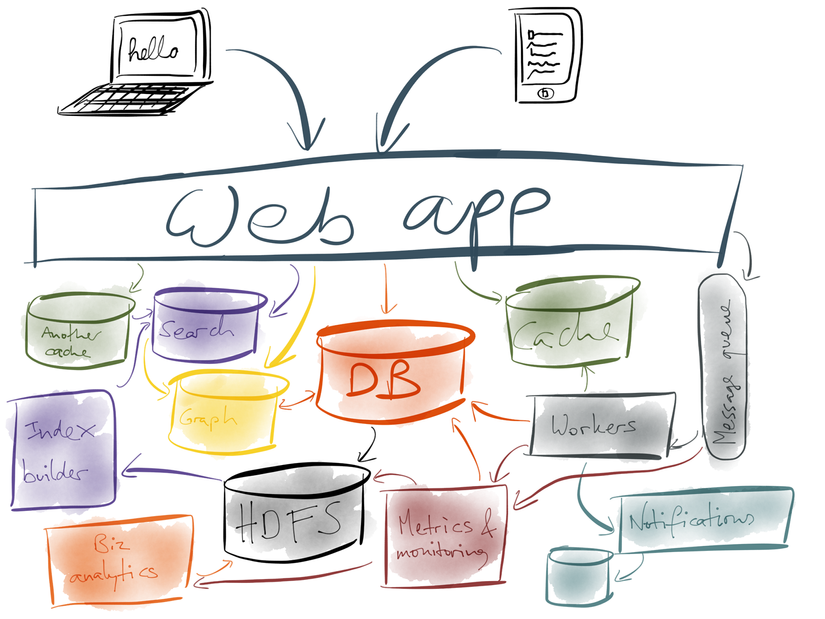
2. Hướng giải quyết
Mặc dù chúng ta sử dụng những công cụ tốt nhất, phù hợp nhất cho ứng dụng của mình. Việc có quá nhiều hệ thống lưu trữ dữ liệu sẽ chẳng phải là vấn đề gì to tát nêú như các hệ thống này lưu các dữ liệu độc lập. Vấn đề ở đây là rất nhiều trong số chúng lại chứa cùng một dữ liệu hoặc dữ liệu liên quan nhưng tồn tại ở các dạng khác nhau (same data in difference form). Caching, indexing, redundant data thường rất cần thiết để tối ưu truy vấn nhưng với một điều kiện đó là làm sao để đồng bộ hoá được các dữ liệu và thể hiện này nhằm đảm bảo nếu có dữ liệu thay đổi ở một nơi thì cần thay đổi tương ứng cho các nơi còn lại.
* Dual writes
Viết code để cập nhật dữ liệu ở tất cả các bên liên quan: Người dùng cập nhật dữ liệu trên ứng dụng web, trước tiên sẽ lưu và DB sau đó update cache, đánh lại index
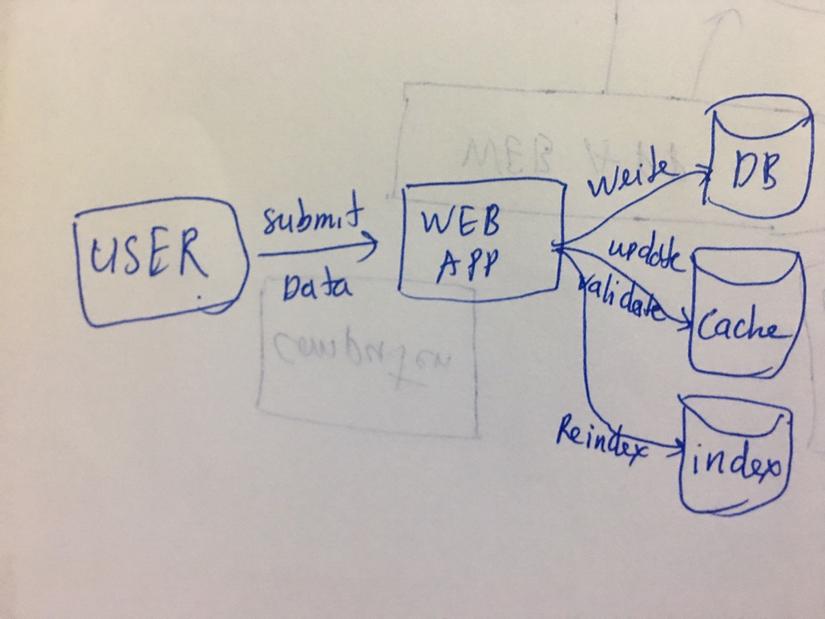
Cách này tưởng chừng như đơn giản và dễ làm nhưng chúng ta sẽ chẳng thể phát hiện ra việc cơ sở dữ liệu và chỉ mục tìm kiếm trở nên không nhất quán
* Lưu trữ các bản ghi theo một thứ tự nhất định
Nếu chúng ta thực hiện công việc một cách tuần tự, sẽ không có các events nào diễn ra đồng thời, sẽ không có sự bất đồng bộ nào xảy ra. Thêm nữa, khi mọi thứ được thực hiện tuần tự, thì việc rollback lại phần failures cũng trở nên dễ dàng hơn.
Cụ thể là bất kể khi nào write data, chúng ta sẽ ghi nối nội dung đó vào chuỗi data săn có (sequence of records ). Không thay đổi trình tự order, chỉ append-only (không sửa đổi các bản ghi hiện có, chỉ thêm các bản ghi mới vào cuối), và dữ liệu này được lưu trữ lâu dài trên ổ cứng (nghe hao hao giống blockchain  )
)

* Logs
Log có một sức mạnh đáng kinh ngạc, nó chính là một dạng data structures được sắp xếp tuần tự, chỉ được append-only. Logs tồn tại ở bất kỳ đâu, có thể là DB storage engine, DB replication, distributed consensus hay Kafka.
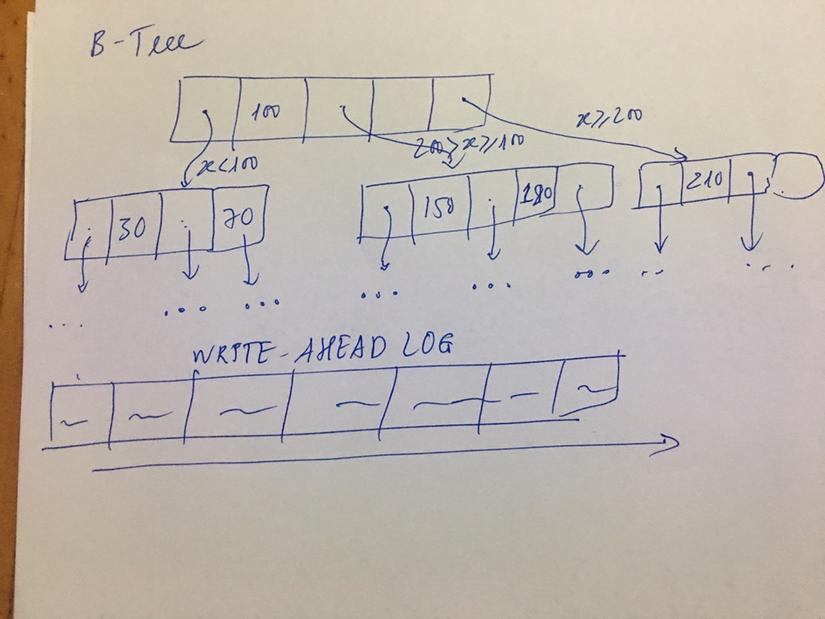 Hình vẽ trên, Write ahead log (WAL) đóng vai trò gì trong cấu trúc B-tree?
Trường hợp chúng ta cần insert new key, value vào B-tree, chúng ta cần insert vào page mà có phạm vi chứa key cần chèn, trường hợp page đó. Nếu page đó không đủ không gian trống nó sẽ được chia thành 2 page con, lúc này trong ổ cứng lưu trữ 3 pages: 2 page được separate, 1 page parent. Trường hợp gặp lỗi trong quá trình indexing khiến cho chỉ có một hoặc một vài page được update, còn lại thì không.
WAL ra đời khiến cho B-tree trở nên đáng tin cậy hơn bởi lẽ bất kể khi nào storage engin muốn thực hiện thay đổi trên B-tree, trước tiên nó phải ghi lại thay đổi đó trên WAL, sau khi dữ liệu được ghi lại trên WAL và ổ cứng success, thì mới được phép sửa đổi trên B-tree
Vậy để giải quyết vấn đề chúng ta cần phải
Hình vẽ trên, Write ahead log (WAL) đóng vai trò gì trong cấu trúc B-tree?
Trường hợp chúng ta cần insert new key, value vào B-tree, chúng ta cần insert vào page mà có phạm vi chứa key cần chèn, trường hợp page đó. Nếu page đó không đủ không gian trống nó sẽ được chia thành 2 page con, lúc này trong ổ cứng lưu trữ 3 pages: 2 page được separate, 1 page parent. Trường hợp gặp lỗi trong quá trình indexing khiến cho chỉ có một hoặc một vài page được update, còn lại thì không.
WAL ra đời khiến cho B-tree trở nên đáng tin cậy hơn bởi lẽ bất kể khi nào storage engin muốn thực hiện thay đổi trên B-tree, trước tiên nó phải ghi lại thay đổi đó trên WAL, sau khi dữ liệu được ghi lại trên WAL và ổ cứng success, thì mới được phép sửa đổi trên B-tree
Vậy để giải quyết vấn đề chúng ta cần phải
- Không sử dụng dual writes
- Thay vì lưu trực tiếp dữ liệu vào datastores, ứng dụng chỉ nên append data vào logs (Kafka chẳng hạn). Các xử lý liên quan đến DB, Indexing, Caching đều được đọc và lấy từ logs sequatially
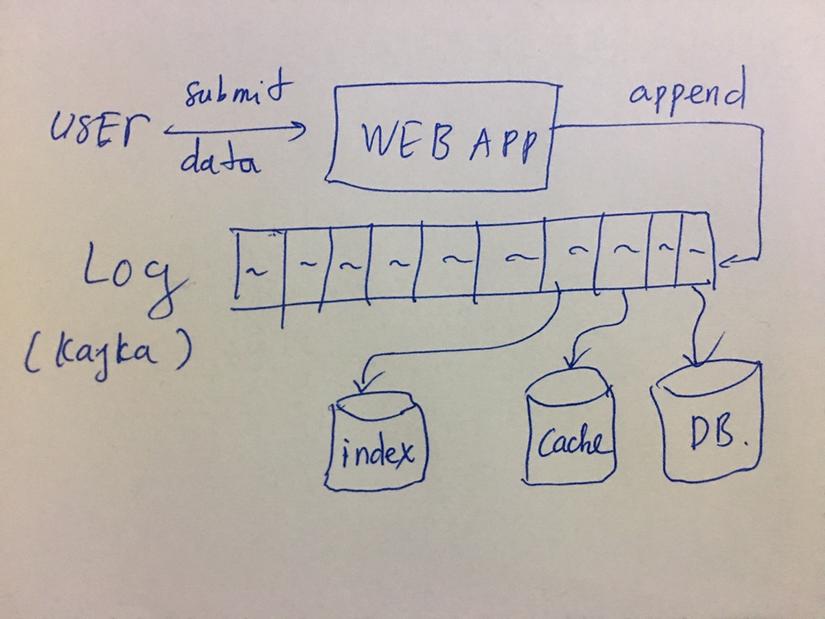
Phần này chúng ta đã thấy rằng logs là cách tốt nhất để giải quyết vấn đề tích hợp dữ liệu, đảm bảo tính nhất quán của dữ liệu dù được lưu ở các nơi khác nhau. Nếu việc cập nhật data giờ đây đơn giản chỉ là việc append event to log, thì hệ thống Restfull API (POST, PUT, DELETE, GET) giờ đây chỉ gói gọn trong GET khi mà toàn bộ việc write data đã được thực hiện trên log.
Tài liệu tham khảo: Martin Kleppmann - Making Sense of Stream Processing
All rights reserved
