Khái niệm về Stream Processing
Bài đăng này đã không được cập nhật trong 7 năm
1. Nguồn gốc của big data
Vào giữa những năm 1990, Internet thực sự đã có tác động mạnh mẽ đến cuộc sống hàng ngày. Kể từ đó, Web đã cho chúng ta quyền truy cập, tìm kiếm thông tin tuyệt vời cùng với khả năng giao tiếp ngay lập tức với bất kỳ ai, ở bất cứ nơi nào trên thế giới. Một sản phẩm phụ bất ngờ được tạo ra từ tất cả kết nối này đó chính là lượng data khổng lồ.
Kỷ nguyên của big data thực sự bắt đầu đó là khi Sergey Brin và Larry Page thành lập Google. Hai người đã phát triển cách xếp hạng trang web cho việc tìm kiếm sử dụng thuật toán PageRank. Ở mức highlevel, PageRank đánh giá một trang web bằng cách đếm số lượng và chất lượng của các liên kết trỏ đến nó. Một trang web càng quan trọng thì càng có nhiều website đề cập đến nó.
2. Vì sao chúng ta cần stream processing
Bối cảnh lập trình hiện nay bùng nổ với big data và các công nghệ đính kèm nó. Cùng với đó là sự gia tăng mạnh mẽ về thị trường thiết bị di động cũng như sự phát triển nhanh chóng của các ứng dụng di động. Tuy nhiên dù thị trường thiết bị di động lớn đến đâu, ứng dụng di động có biến động ra sao thì có một thứ bất biến đó là mỗi ngày chúng ta phải xử lý ngày càng nhiều dữ liệu. Dữ liệu tăng lên thì nhu cầu phân tích tận dụng dữ liệu đó cũng tăng lên tương ứng . Việc xử lý lượng lớn dữ liệu thường được thực hiện bằng Batch Processing (dữ liệu chứa hàng triệu bản ghi mỗi ngày được lưu trữ dưới dạng các tệp tin hoặc bản ghi. Các tệp tin này sẽ trải qua quá trình xử lý vào cuối ngày để phân tích theo cách khác nhau mà công ty muốn thực hiện.)
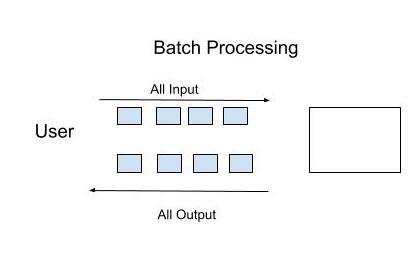 Càng ngày các tổ chức càng thấy rằng họ cần xử lý dữ liệu ngay khi có sẵn (stream processing), có nghĩa là bạn phải xử lý từng bản ghi ngay khi nó có sẵn.
Ví dụ:
Có bao nhiêu đăng nhập không hợp lệ trong vòng 10 phút qua ?
Có bao nhiêu tính năng được phát hành gần đây được người dùng sử dụng ?
Xu hướng hiện tại đang là gì ?
Rõ ràng cần phải có giải pháp khác thay thế cho việc sử dụng batch như hiện tại, và đó chính là stream processing
Càng ngày các tổ chức càng thấy rằng họ cần xử lý dữ liệu ngay khi có sẵn (stream processing), có nghĩa là bạn phải xử lý từng bản ghi ngay khi nó có sẵn.
Ví dụ:
Có bao nhiêu đăng nhập không hợp lệ trong vòng 10 phút qua ?
Có bao nhiêu tính năng được phát hành gần đây được người dùng sử dụng ?
Xu hướng hiện tại đang là gì ?
Rõ ràng cần phải có giải pháp khác thay thế cho việc sử dụng batch như hiện tại, và đó chính là stream processing
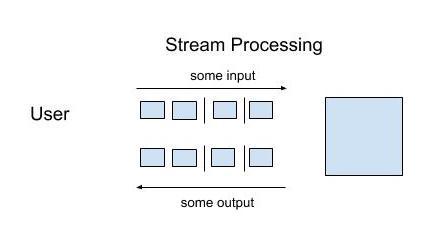
3. Định nghĩa stream processing
Có rất nhiều cách định nghĩa khác nhau về stream processing thế nhưng như chúng ta phân tích bên trên, có thể hiểu đơn giản stream processing là xử lý dữ liệu ngay khi nó xuất hiện trong hệ thống, mở rộng hơn nữa thì stream processing có khả năng làm việc với luồng dữ liệu vô hạn, quá trình tính toán xảy ra liên tục.

- Như hình vẽ bên trên: Mỗi vòng tròn đại diện cho thông tin hoặc event xảy ra trong một thời điểm, số lượng event là không giới hạn và di chuyển liên tục từ trái qua phải. Vậy những ai cần sử dụng Stream Processing? Câu trả lời là bất cứ ai, bất cứ hệ thống nào cần sự phản hồi nhanh từ một event gửi đến.
4. Khi nào cần sử dụng Stream processing, khi nào không nên sử dụng ?
Cũng giống như bất kỳ giải pháp kỹ thuật nào, stream processing cũng có những giới hạn riêng, không thể sử dụng được cho mọi trường hợp. Nếu yêu cầu nhanh chóng phản hồi hoặc report khi có dữ liệu đến thì nên dùng stream processing.
- Gian lận thẻ tín dụng: Chủ thẻ có thể không nhận biết được thẻ của mình bị đánh cắp nhưng bằng cách xem xét các giao dịch trong các thời điểm, địa điểm, thói quen tiêu dùng thì hệ thống có thể phát hiện ra thẻ tín dùng bị đánh cắp và cảnh báo cho chủ sở hữu.
- Gian lận trong thể thao: Có thể gắn các con chíp vào giày chạy, khi vận động viên vượt qua các cảm biến đặt dọc đường, chúng ta có thể sử dụng thông tin đó để theo dõi vị trí người chạy từ đó phát hiện ra gian lận hay sự cố người đó gặp phải.
- Ngành tài chính: Theo dõi số liệu về giá cả và định hướng thị trường theo thời gian thực là điều cần thiết để các nhà môi giới và nhà đầu tư đưa ra quyết định chính xác về thời điểm mua bán. Trái lại, những trường hợp cần thực hiện dự báo trong tương lai cần sử dụng một lượng lớn dữ liệu theo thời gian để loại bỏ sự bất thường cũng như xác định xu hướng & mô hình, ở đây ta cần tập trung phân tích dữ liệu theo thời gian hơn là dữ liệu mới nhất.
5. Kết luận
Stream processing ra đời giúp chúng ta giải quyết được bài toán khó khăn trong việc xử lý data. Bạn sẽ cần đến nó khi
- Cần một phương pháp để gửi data đến bộ lưu trữ trung tâm một cách nhanh chóng
- Bởi vì máy móc thường xuyên gặp lỗi nên cần có cách thức sao chép dữ liệu nhằm giúp cho khi xảy ra sự cố, không bị downtime hoặc mất data.
- Cần có tiềm năng mở rộng quy mô đáp ứng bất kỳ lượng người dùng mà không cần phải theo dõi các ứng dụng khác nhau. Hoặc cần cung cấp dữ liệu cho bất kỳ ai trong một tổ chức mà không cần theo dõi xem ai đã và chưa được xem dữ liệu. Khi nhắc đến stream processing, chúng ta không thể không nhắc đến các open source như Apache Spark, Apache Storm, Apache Flink và Apache Kafka
All rights reserved
