Cách thiết kế cơ sở dữ liệu chat trong mongoDB
Bài đăng này đã không được cập nhật trong 6 năm
Bản thân mình khi viết bài này là đang đi tìm kiếm một giải pháp cho bài toán IoT của mình . Đó là hệ thống có sẽ nhiều người dùng , mỗi người dùng có rất nhiều sensor ,hơn nữa dữ liệu tracking là dạng time-series như thế nó sẽ đòi hỏi một khả năng ghi và đọc tuyệt vời mới có thể đáp ứng được bài toán . Mình đã từng nghĩ rằng nếu đã phức tạp như thế vậy hãy thử việc với mỗi người dùng sẽ tạo một Schema riêng về tracking và sensor đi như thế sẽ có vẻ tốt hơn là lưu tất vào một Schema tracking chung và truy vấn dựa vào ID của User . Và mình nhận ra bài toán này khá tương đồng với việc thiết kế cơ sở dữ liệu chat . Hãy cùng tìm hiểu xem nó có gì mới mẻ nào .

Các ứng dụng cần kiểu thiết kế này
Thiết kế Schema là một phần vô cùng quan trọng của bất kỳ ứng dụng nào. Giống như hầu hết các cơ sở dữ liệu, sẽ có nhiều cách để mô hình hóa dữ liệu trong MongoDB và điều quan trọng là làm sao để vận dụng, xác định thiết kế tốt nhất để tăng hiệu suất cho ứng dụng của mình . Trong bài này, mình sẽ giới thiệu về ba cách tiếp cận để sử dụng MongoDB khi tạo một database về chat hay các vấn yêu cầu tương tự .
Đầu tiên phải xác định các yêu cầu cho những bài toán như này :
- Ứng dụng kiểu này cần phải có khả năng xử lý một khối lượng đọc và ghi lớn .
- Việc đọc và ghi không giống nhau giữa các người dùng.
- Ứng dụng phải cung cấp trải nghiệm người dùng realtime.
- Ứng dụng sẽ ít hoặc hầu như ko xóa các dữ liệu.
Bởi vì chúng ta đang thiết kế một ứng dụng cần hỗ trợ một khối lượng lớn việc đọc và ghi, chúng tôi sẽ sử dụng sharded collection cho các tin nhắn ( mình sẽ giải thích khái niệm này trong một bài khác ). Tất cả ba thiết kế sẽ xoay quanh khái niệm fan out, có nghĩa là phân phối công việc trên các mảnh song song :
- Fan out on Read
- Fan out on Write
- Fan out on Write with Buckets
Mỗi cách tiếp cận đều có sự đánh đổi vậy nên hãy sử dụng thiết kế phù hợp nhất với các yêu cầu ứng dụng của bạn nhé .
Fan out on Read
Ý tưởng sẽ là : Khi người dùng gửi message, nó sẽ chỉ đơn giản là lưu vào inbox collection. Khi bất kỳ người dùng nào xem inbox riêng của họ ứng dụng sẽ queries tất cả các messages. Các tin nhắn được trả lại theo thứ tự thời gian để người dùng có thể xem các tin nhắn gần đây nhất.
//Shard dựa vào "from"
db.shardCollection( "mongodb.inbox", {from: 1})
//Thêm index khép (nhiều hơn 1 chỉ mục)
db.inbox.ensureIndex({to: 1, sent: 1})
msg = {
from: "Joe"
to: ["Bob", "Jane"],
sent: new Date(),
message: "Hi!",
}
//Send a message
db.inbox.save (msg)
//Read Bob's inbox
db.inbox.find ({ to: "Bob"}).sort({sent:-1})
Để áp dụng thiết kế kiểu này hãy tạo một collection tên là inbox , chỉ định trường from là shard key, đại diện cho địa chỉ gửi message. Sau đó, bạn có thể thêm index khép trên trường to và trường sent. Khi mà document được lưu vào inbox, message sẽ được gửi một cách hiệu quả đến tất cả người nhận. Với phương pháp này, việc gửi message rất hiệu quả.
Mặt khác, việc xem inbox sẽ kém hiệu quả hơn. Khi người dùng xem inbox của họ, ứng dụng sẽ dùng lệnh find dựa trên trường to, được sắp xếp theo sent. Bởi vì inbox collection sử dụng from là shard key vì thế các message được nhóm lại theo người gửi . Trong các truy vấn, MongoDB không dựa trên shard key mà sẽ route đến tất cả các shard. Do đó, mỗi khi read sẽ phải route đến tất cả shards trong hệ thống. Khi hệ thống scale và có nhiều người dùng xem inbox của họ, tất cả các truy vấn sẽ được route đến tất cả các shards. Thiết kế này không scale tốt lắm vì nó ko query đến thằng shards mà lại query hết .
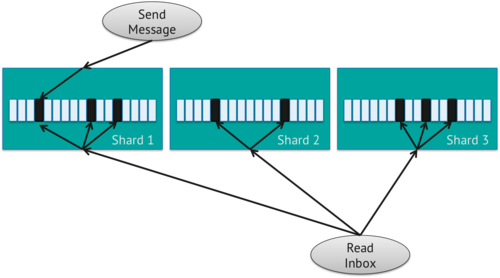
Với kiểu Fan Out on Read này việc ghi vào sẽ rất hiệu quả nhưng việc đọc sẽ kém hiệu quả hơn .
Fan out on Write
Lần này, thay vì shard key là from chúng ta sẽ dùng recipient (người nhận) và sent . Theo cách này, khi chúng ta đi xem inbox, các truy vấn có thể được chuyển đến một shard duy nhất như thế sẽ tốt hơn. message document của chúng ta sẽ vẫn giống như trên, nhưng bây giờ lưu một bản sao của tin nhắn cho mọi recipient.
//Shard on "recipient" and "sent"
db.shardCollection("mongodbdays.inbox", {"recipient": 1, "sent":1})
msg = {
from: "Joe",
to: ["Bob", "Jane"]
sent: new Date()
message: "Hi!",
}
//Send a message
for (recipient in msg.to){
msg.recipient = msg.to[recipient]
db.inbox.insert(msg);
}
//Read Bob's inbox
db.inbox.find ({recipient: "Bob"}).sort({ sent:-1})
Cách này có vẻ hữu ích cho việc đọc đấy nhưng khoan đã nếu ghi ko tốt thì đọc nhanh kiểu gì nhỉ . Đúng như ví dụ trên về việc chat nhóm gồm bản thân mình ,Bob và Jane và độ 5 người nữa việc hiển thị sẽ như thế nào nhỉ .Có một chiến lược là dựa vào last read. Đơn giản là những người last read gần đây nhất sẽ được update trước còn những người ít đọc sẽ đc update sau .
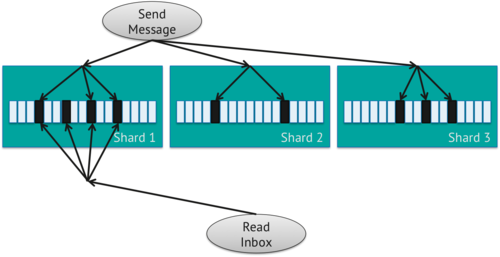
Với kiểu Fan Out on Write này việc đọc sẽ rất hiệu quả nhưng việc ghi sẽ kém hiệu quả hơn .
Nhưng việc ghi như thế này sẽ chẳng mấy chốc mà full ổ đĩa. May mắn là chúng ta có thể tận dụng document data model nâng cao để tối ưu cho thiết kế này . Đó là phương pháp tiếp theo
Fan out on Write with Buckets
Fan out trên Write with Buckets sẽ nâng cấp thiết kế Fan Out on Write bằng cách nhóm các message với nhau khoảng 50 message được sắp xếp theo thời gian. Khi người dùng xem inbox của họ, yêu cầu có thể được thực hiện bằng cách chỉ đọc gồm 50 tin nhắn thay vì thực hiện nhiều lần đọc. Bởi vì thời gian đọc bị chi phối bởi thời gian tìm kiếm, việc giảm số lượng tìm kiếm có thể cung cấp một cải tiến với hiệu suất tốt hơn cho ứng dụng. Một lợi thế khác của phương pháp này là có ít index hơn.
Để thực hiện thiết kế này, chúng ta sẽ tạo hai collection, inbox collection và user collection. inbox collection sẽ sử dụng hai trường cho shard key đó là owner và sequence, một cái chứa id của user và số thứ tự ( ví dụ: số thứ tự của một bucket gồm 50 message trong inbox của họ ). user collection đơn giản để theo dõi tổng số message trong hộp thư đến của họ. Vì có thể chúng tôi sẽ cần hiển thị tổng số tin nhắn cho người dùng ở trong app, đây là một nơi tốt để lưu trữ số lượng thay vì phải tính toán cho mỗi lần query.
//Shard on "owner/sequence"
db.shardCollection("mongodbdays.inbox",{owner: 1, sequence: 1})
db.shardCollection("mongodbdays.users", {user_name: 1})
msg={
from: "Joe",
to: ["Bob", "Jane"],
sent: new Date ()
message: "Hi!",
}
//Send a message
for(recipient in msg.to) {
count = db.users.findAndModify({
query: {user_name: msg.to[recipient]},
update:{"$inc":{"msg_count":1}},
upsert: true,
new: true}).msg_count;
sequence = Math.floor(count/50);
db.inbox.update({
owner: msg.to[recipient], sequence: sequence},
{$push:{"messages":msg}},
{upsert: true});
}
//Read Bob's inbox
db.inbox.find ({owner: "Bob"})
.sort({sequence:-1}).limit(2)
Để gửi tin nhắn, chúng ta sẽ lặp qua danh sách người nhận như chúng ta đã làm trong ví dụ về Fan out on Write, nhưng chúng ta cũng thực hiện một bước khác để tăng tổng số message trong inbox của người nhận, được duy trì trên user document. Một khi chúng ta biết được số lượng tin nhắn, chúng ta sẽ biết đc bucket nào chứa message mới nhất. Khi các message này đạt đến ngưỡng 50, sequence sẽ tăng dần và chúng ta bắt đầu thêm tin nhắn vào bucket tiếp theo. Các tin nhắn gần đây nhất sẽ luôn nằm trong bucket có số thứ tự cao nhất.
Thông thường, toàn inbox của người dùng sẽ tồn tại trên một shard duy nhất. Tuy nhiên, có thể một vài inbox đến của người dùng có thể được trải rộng trên hai shard. Bởi vì ứng dụng của chúng tôi có thể sẽ chuyển qua hộp thư đến của người dùng, nên có thể mọi truy vấn cho một vài người dùng này sẽ được chuyển đến một phân đoạn duy nhất.
Fan out on Write với Buckets nói chung là cách tiếp cận có khả năng mở rộng nhất trong ba thiết kế này cho các ứng dụng chat. Mỗi thiết kế trình bày sự đánh đổi khác nhau. Trong trường hợp này, việc xem inbox của người dùng rất hiệu quả, nhưng việc ghi lại có phần phức tạp hơn và tiêu tốn nhiều dung lượng đĩa hơn. Đối với nhiều ứng dụng, đây là sự đánh đổi đúng đắn.
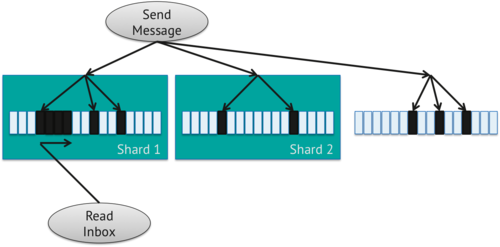
Tổng kết lại
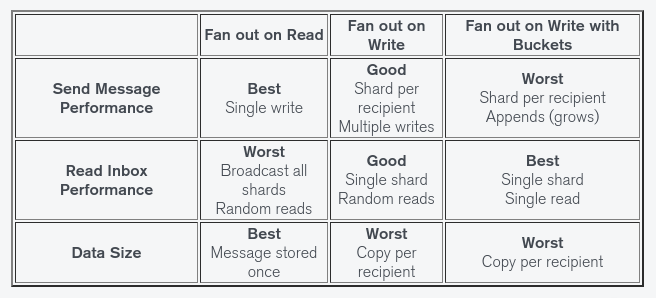
Thiết kế lược đồ là một trong những tối ưu hóa quan trọng nhất bạn có thể thực hiện cho ứng dụng của mình. Hãy cùng nhìn lại về các thiết kế trên .
All rights reserved
