Cách Facebook xây dựng hệ thống Memcache lớn nhất thế giới
Bài đăng này đã không được cập nhật trong 2 năm
Mỗi giây, Facebook nhận được hàng tỷ truy vấn và lưu trữ hàng nghìn tỷ mục trong cơ sở dữ liệu của họ. Theo nhóm của họ, "kiến trúc web truyền thống" không thể đáp ứng nhu cầu của mạng xã hội này. Facebook đã sử dụng một kho lưu trữ key-value đơn giản có tên là Memcached và mở rộng quy mô để xử lý hiệu quả hàng tỷ truy vấn mỗi giây cho hàng nghìn tỷ mục. Họ từng đề cập vào năm 2013 rằng hệ thống của họ là "hệ thống Memcached lớn nhất thế giới".
Quy tắc mở rộng của Facebook
-
Tập trung vào người dùng: Bất kỳ thay đổi nào cũng chỉ được thực hiện khi phục vụ người dùng tốt hơn hoặc giải quyết vấn đề vận hành.
-
Đừng theo đuổi sự hoàn hảo: Facebook chấp nhận việc một số người dùng có thể nhận dữ liệu cũ hơn nếu điều đó giúp họ mở rộng quy mô nhanh hơn.
Phân tích Quy tắc:
1. Hướng người dùng: Facebook ưu tiên trải nghiệm người dùng và giải quyết các vấn đề trực tiếp ảnh hưởng đến họ. Điều này đảm bảo rằng việc mở rộng quy mô không đi kèm với trải nghiệm tồi tệ hoặc sự cố vận hành nghiêm trọng.
2. Thực tế và linh hoạt: Facebook hiểu rằng hoàn hảo là khó đạt được, đặc biệt là khi mở rộng quy mô nhanh chóng. Họ chấp nhận một số thiếu sót nhỏ nếu không ảnh hưởng đáng kể đến người dùng để có thể phát triển nhanh hơn.
3. Cân bằng rủi ro và lợi ích: Quy tắc này nhấn mạnh việc đánh đổi giữa mở rộng quy mô và trải nghiệm người dùng. Việc chấp nhận một số rủi ro có thể mang lại lợi ích lớn hơn trong tầm nhìn tổng thể.
Cách Facebook Mở Rộng Quy Mô
Requirements
Ngay từ đầu, Facebook đã giả định rằng:
- Người dùng đọc nhiều hơn viết.
- Có nhiều nguồn dữ liệu khác nhau để đọc.
- Quá trình đọc, viết và giao tiếp phải diễn ra gần như tức thời.
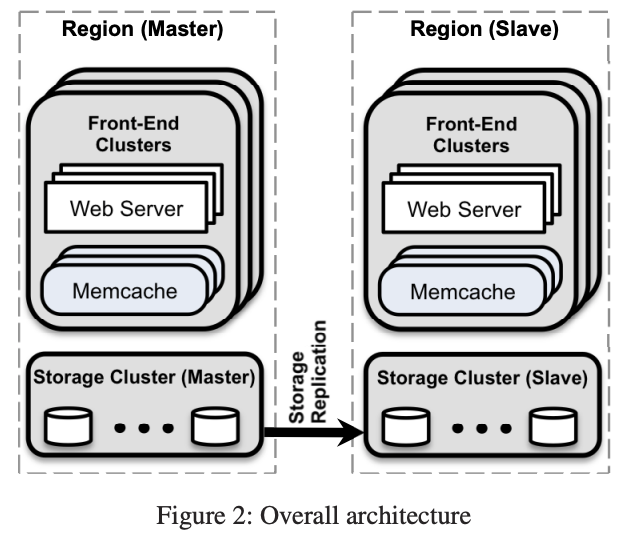
Để đáp ứng những yêu cầu này, Facebook đã áp dụng 3 tầng mở rộng: cluster, region, and worldwide.
Giới thiệu về Memcached
Memcached là một hệ thống lưu trữ key-value (khóa-giá trị) đơn giản, được triển khai sử dụng bảng băm (hash table) và lưu trữ dữ liệu trong bộ nhớ RAM.
Việc đọc cơ sở dữ liệu chậm hơn nhiều so với việc đọc trong bộ nhớ. Cơ sở dữ liệu của Facebook lưu trữ hàng nghìn tỷ items
Ví dụ: trong một ứng dụng tôi đã phát triển, phản hồi JSON 1,2 MB mất ~ 1100 mili giây để trả về. Sau khi tôi cài đặt Memcached, nó chỉ mất 200ms khi được lưu vào bộ nhớ đệm.
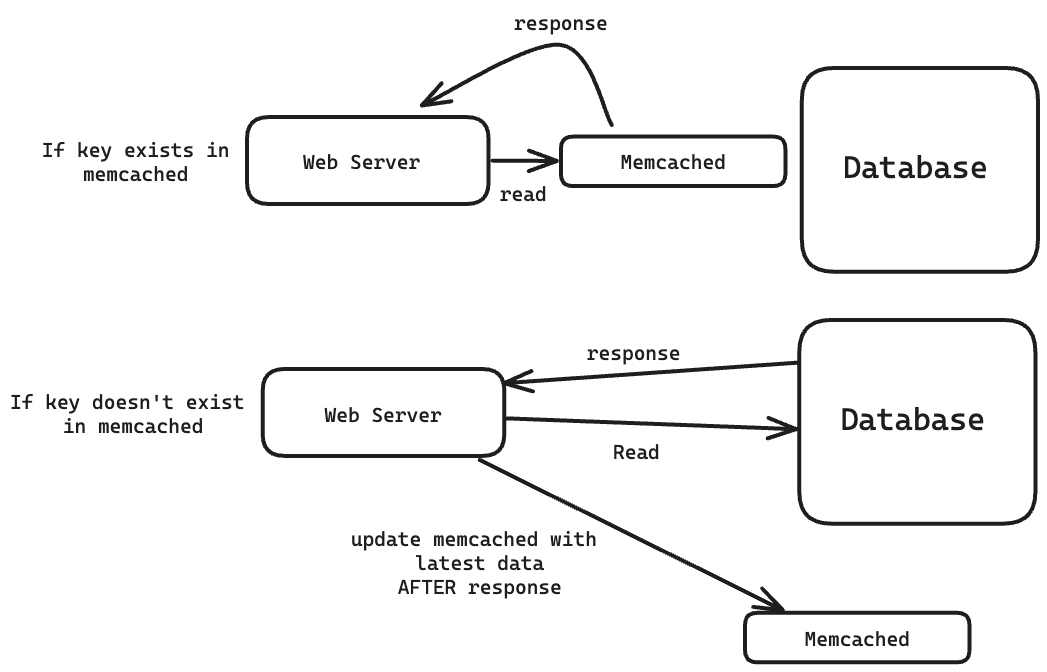
Facebook lưu trữ gì ở trong Memcached?
Memcached lưu trữ phản hồi cho các yêu cầu khác nhau.
Nếu người dùng yêu cầu thông tin hồ sơ của họ và thông tin đó không thay đổi kể từ yêu cầu cuối cùng của họ thì phản hồi của yêu cầu đó đã được lưu trữ trong Memcached.
Nó cũng lưu trữ các thành phần trung gian phổ biến, chẳng hạn như kết quả được tính toán trước từ thuật toán học máy của Facebook.
Vì sao lại là Memcached?
“Memcached provides a simple set of operations (set, get, and delete) that makes it attractive as an elemental component in a large-scale distributed system.” (Section 2, Overview)
Trong bài báo của Facebook, họ sử dụng Memcached làm kho lưu trữ khóa-giá trị cơ bản và Memcache làm phiên bản hệ thống phân tán của Memcached mà họ đang chạy.
Tôi thấy cách đặt tên của họ khó hiểu, vì vậy tôi sẽ đề cập đến phiên bản hệ thống phân tán của họ, memcache, trong phần còn lại của bài đăng này.
Cluster Scaling
Mục tiêu:
- Giảm độ trễ của việc đọc dữ liệu
- Giảm tải cho cơ sở dữ liệu
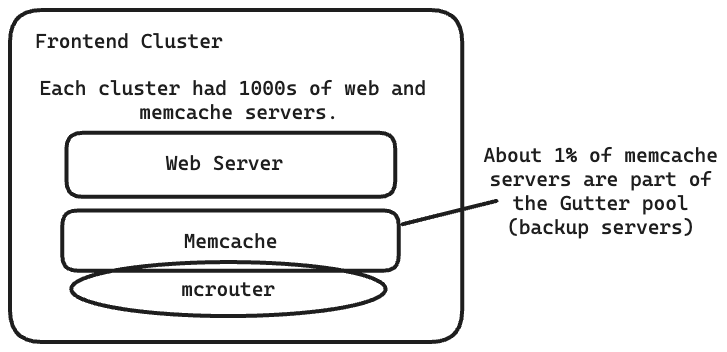
Trong một cụm, Facebook có hàng nghìn máy chủ.
Mỗi máy chủ đều có một memcache client, phục vụ một loạt các chức năng (nén, tuần tự hóa, giải nén, v.v.). Tất cả các clients đều có một bản đồ của tất cả các máy chủ có sẵn.
Việc tải một trang Facebook phổ biến trung bình cần đến 521 lượt đọc từ memcache. Một máy chủ web thường sẽ phải liên lạc với nhiều máy chủ memcache cho 1 request.
Giảm độ trễ
Các yêu cầu phải được hoàn thành và gửi lại theo thời gian thực.
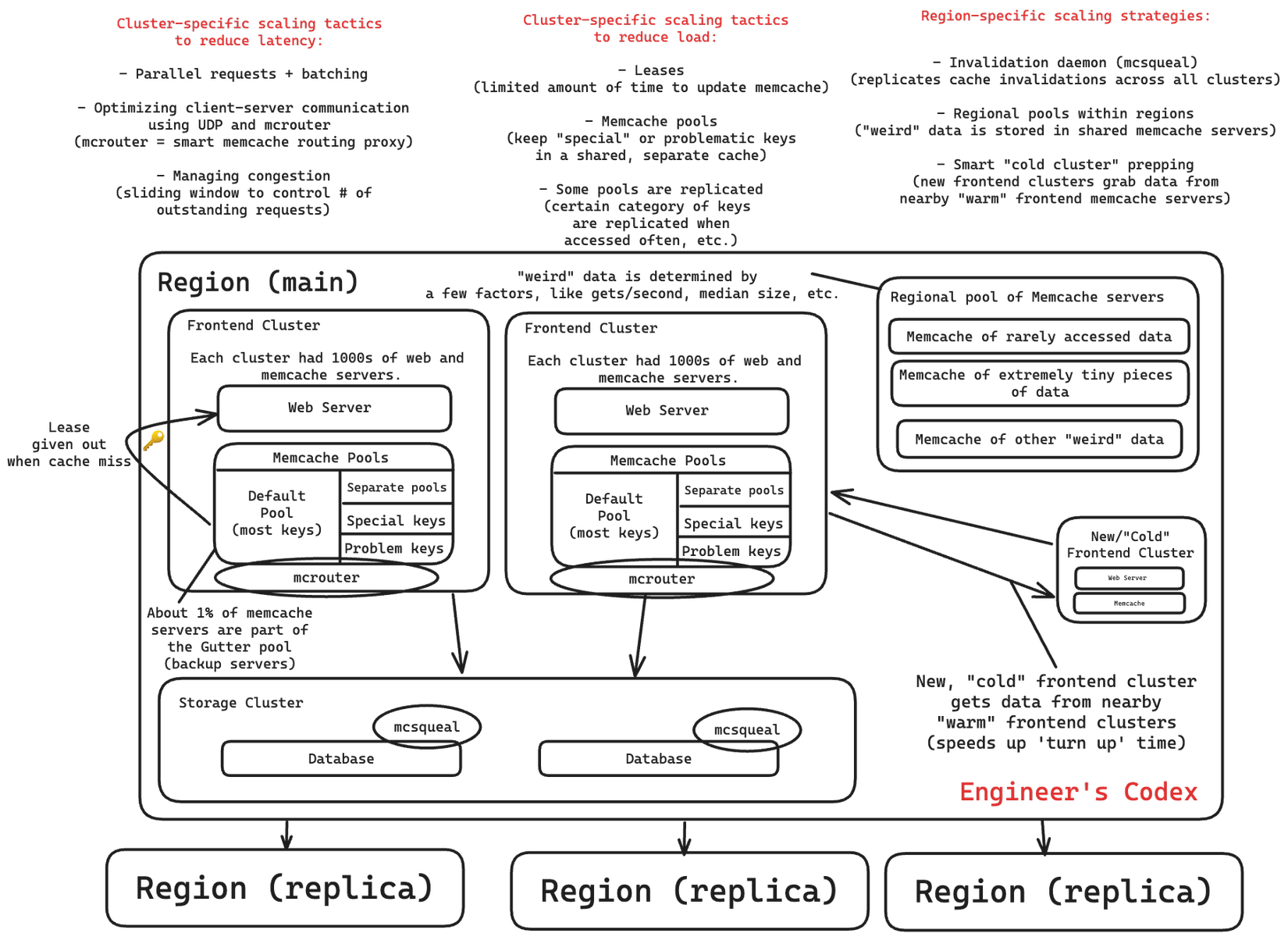
Facebook có ba chiến lược: parallel requests + batching, faster client-server communication và controlling request congestion.
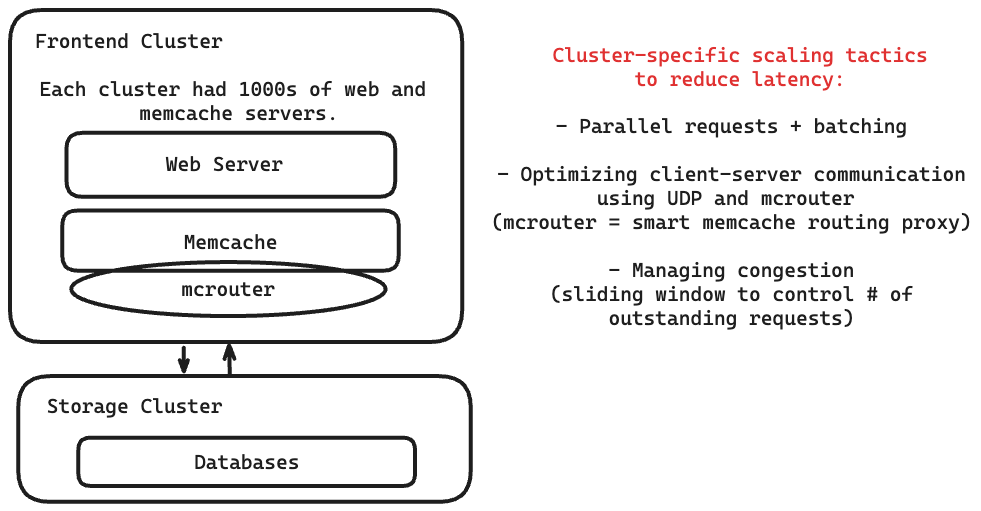
Parallel requests and batching
Mục tiêu của việc sử dụng các yêu cầu song song và phân nhóm là để giảm số lượng các chuyến đi khứ hồi mạng (network round trips).
Họ đã tạo ra một DAG gồm các phần phụ thuộc dữ liệu được sử dụng để tối đa hóa số lượng mục có thể được tìm nạp cùng một lúc, tức là 24 khóa mỗi lần (trung bình).
Optimizing client-server communication
Sử dụng các máy khách không trạng thái (stateless clients) để các máy chủ memcache có thể được giữ đơn giản.
Giao thức UDP được sử dụng để nhận yêu cầu tới memcache vì mọi sự cố đều được hiển thị dưới dạng lỗi phía máy khách. (vì vậy người dùng chỉ cần thử lại)
Giao thức TCP được sử dụng cho các hoạt động thiết lập/xóa bằng cách sử dụng mcrouter.
Mcrouter là một proxy của máy chủ memcache được dùng để định tuyến các request/response đến/từ các máy chủ khác.
Managing congestion
Khi có quá nhiều yêu cầu cùng một lúc, máy khách memcache sẽ sử dụng cơ chế cửa sổ trượt (sliding window mechanism) để kiểm soát số lượng yêu cầu chưa xử lý.
Kích thước cửa sổ họ sử dụng đã được tìm ra bằng một số phân tích dữ liệu, trong đó họ tìm thấy sự cân bằng giữa độ trễ của người dùng quá cao hoặc quá nhiều yêu cầu đến cùng một lúc
Giảm tải cho cơ sở dữ liệu
Facebook đã giảm tải cho cơ sở dữ liệu bằng ba chiến lược: leases, memcache pools, và replication within pools.
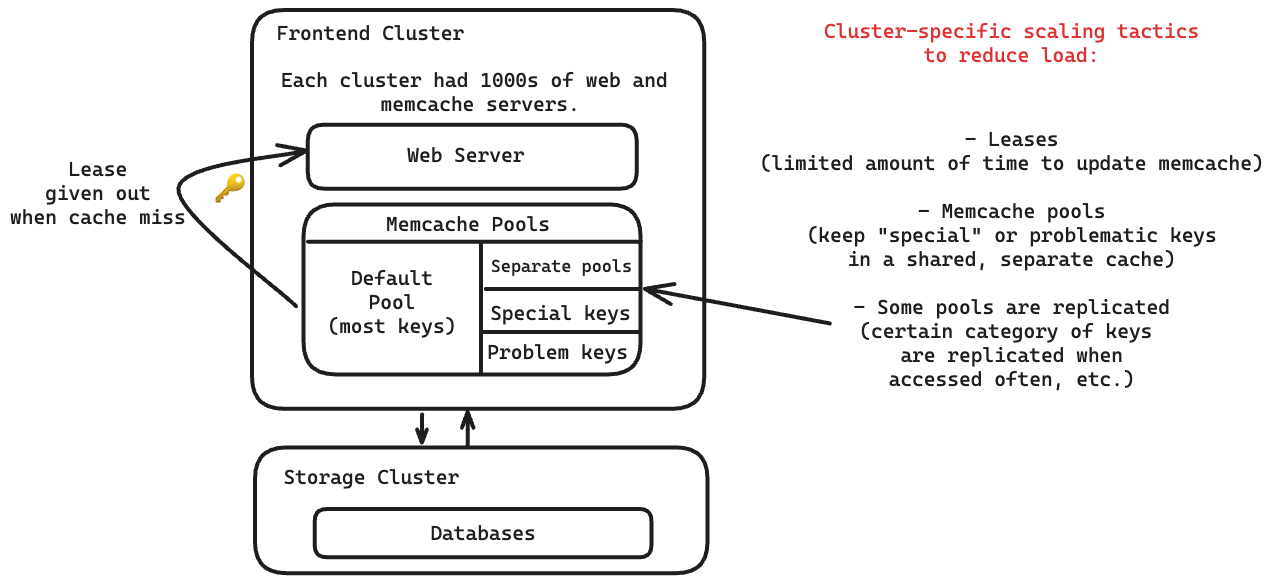
Leases (Hợp đồng thuê)
Khi máy khách gặp lỗi cache miss, một instance memcache sẽ cấp một hợp đồng thuê tạm thời. Đôi khi, khi máy chủ ghi dữ liệu trở lại cache, hợp đồng thuê đã hết hạn, nghĩa là dữ liệu đó đã quá cũ tại thời điểm đó và đã được thay thế bằng dữ liệu mới hơn.
Hợp đồng thuê đã giải quyết được hai vấn đề:
- Stale sets (tập dữ liệu cũ): Máy chủ web đặt giá trị không chính xác trong memcached phân tán.
- Thundering herds (hiệu ứng bầy đàn ồn ào): Một khóa có hoạt động đọc và ghi dữ liệu rất cao cùng một lúc.
Hợp đồng thuê chỉ có thể được cấp một lần sau mỗi 10 giây cho mỗi khóa. Việc sử dụng hợp đồng thuê đã cho phép giảm tỷ lệ truy vấn cơ sở dữ liệu cao điểm từ 17K/s xuống còn 1.3K/s.
Memcache pools (Các nhóm Memcache)
Các máy chủ memcache trong một cụm được phân chia thành các nhóm riêng biệt.
Có một nhóm mặc định cho hầu hết các khóa. Các nhóm còn lại chứa các khóa "có vấn đề" hoặc "đặc biệt" không nằm trong nhóm mặc định, chẳng hạn như các khóa được truy cập thường xuyên nhưng việc cache miss không ảnh hưởng đáng kể đến tải hoặc độ trễ.
Replication within pools (Sao chép dữ liệu trong các nhóm)
Chúng tôi lựa chọn sao chép một nhóm khóa trong một pool khi:
- Ứng dụng thường xuyên truy xuất nhiều khóa cùng lúc.
- Toàn bộ tập dữ liệu có thể nằm gọn trong một hoặc hai máy chủ memcache.
- Tỷ lệ yêu cầu cao hơn nhiều so với khả năng xử lý của một máy chủ đơn lẻ.
Region Scaling
Bạn không thể mở rộng cụm vô hạn.
Nhiều cụm (mặt trước) tạo thành một vùng. Chúng sẽ có nhiều máy chủ web và memcache, cùng với một cụm lưu trữ.
Họ có ba chiến lược để mở rộng Memcache trong một vùng: một daemon vô hiệu hóa, một nhóm vùng và một cơ chế "khởi động nguội" để nhanh chóng xoay chuyển các cụm mới.
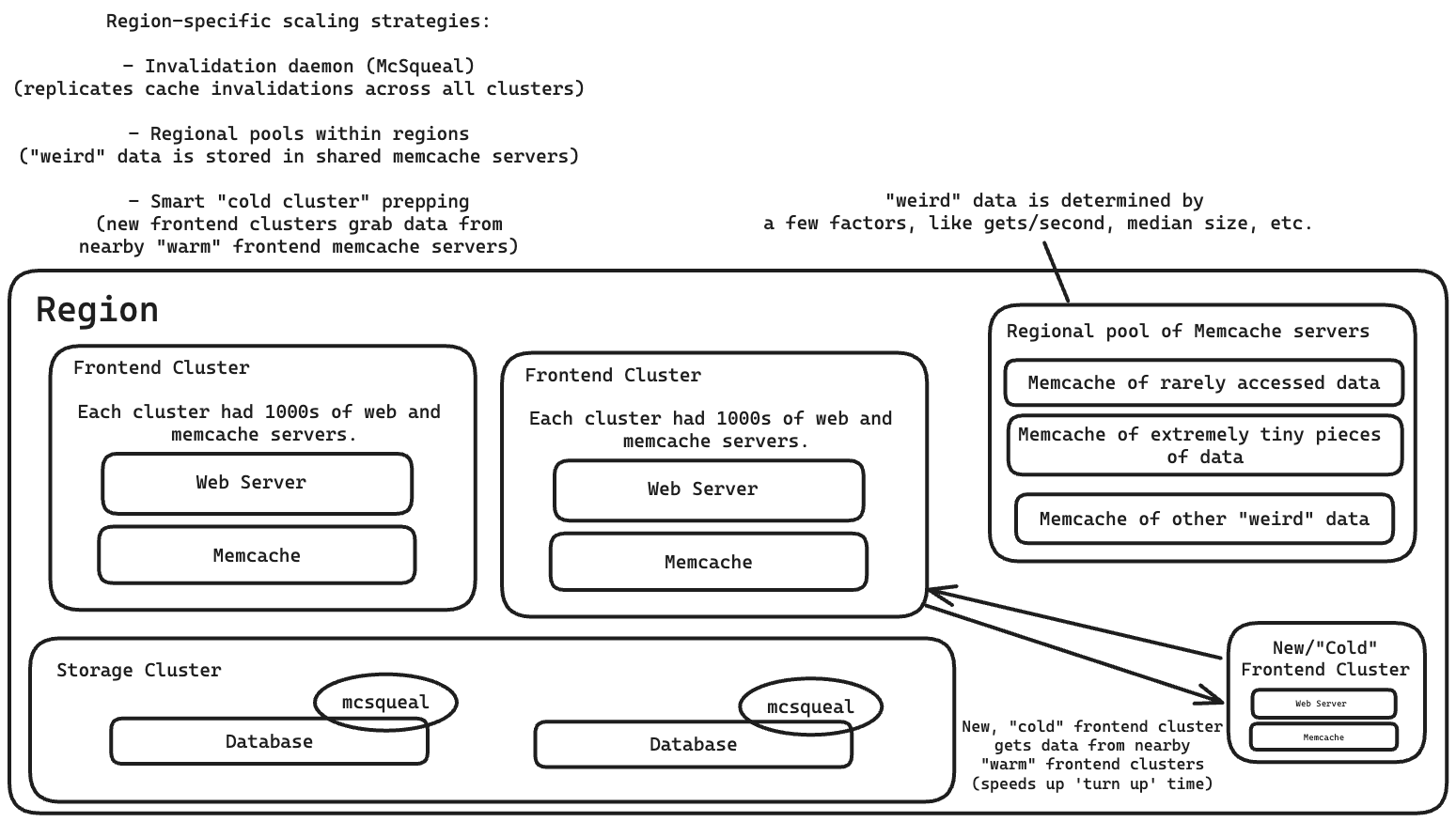
Daemon vô hiệu hóa (Invalidation Daemon)
Một daemon vô hiệu hóa, được gọi là mcsqueal, có nhiệm vụ nhân bản các hành động vô hiệu hóa cache trên tất cả các cache trong một vùng.
Khi dữ liệu trong cụm lưu trữ (cơ sở dữ liệu) thay đổi, mcsqueal sẽ gửi thông báo vô hiệu hóa đến các cụm của nó. Điều này đảm bảo rằng dữ liệu trong các cache luôn được cập nhật và đồng bộ với dữ liệu trong cơ sở dữ liệu.
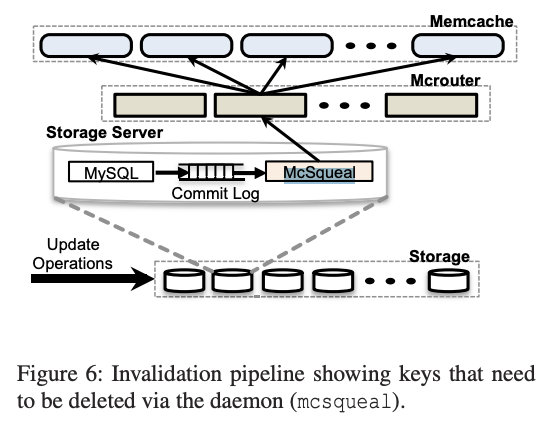
Mỗi cơ sở dữ liệu đều có mcsqueal.
- Mcsqueal: Gom các lệnh xóa thành các gói tin nhỏ hơn, sau đó gửi chúng đến các máy chủ mcrouter trong mỗi cụm frontend.
- Mcrouter: Định tuyến các lệnh vô hiệu hóa đến các máy chủ Memcache phù hợp.
Quy trình hoạt động:
- Khi dữ liệu trong cơ sở dữ liệu thay đổi, mcsqueal sẽ tạo ra các lệnh xóa tương ứng.
- Mcsqueal gom nhóm các lệnh xóa này lại để giảm số lượng gói tin cần gửi đi.
- Mcsqueal gửi các gói tin chứa lệnh xóa đến các máy chủ mcrouter trong các cụm frontend.
- Mcrouter nhận các gói tin và xác định các máy chủ Memcache chứa dữ liệu cần vô hiệu hóa.
- Mcrouter gửi các lệnh xóa đến các máy chủ Memcache tương ứng để đảm bảo dữ liệu cache được cập nhật.
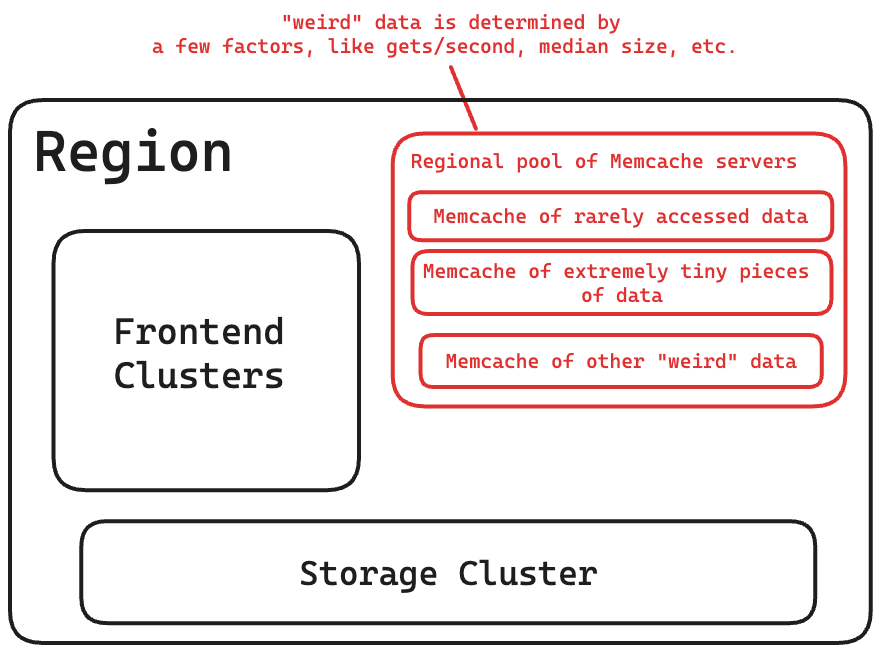
Nhóm vùng (Regional pools)
Nhóm vùng Memcache: Một nhóm máy chủ Memcache được chia sẻ bởi tất cả các cụm trong một vùng để lưu trữ một số loại dữ liệu nhất định.
Chia sẻ giữa các cụm: Nhiều cụm frontend sử dụng chung một nhóm máy chủ Memcache này trong một vùng.
Lưu trữ dữ liệu không thường xuyên truy cập: Do việc sao chép dữ liệu tốn kém, nhóm vùng thường được sử dụng để lưu trữ các loại dữ liệu "đặc biệt", chẳng hạn như dữ liệu không được truy cập thường xuyên.
Tiêu chí lựa chọn dữ liệu: Việc lựa chọn dữ liệu nào sẽ được lưu trữ trong nhóm vùng được dựa trên một số yếu tố như số lượng người dùng trung bình, số lần truy cập mỗi giây và kích thước giá trị trung bình.
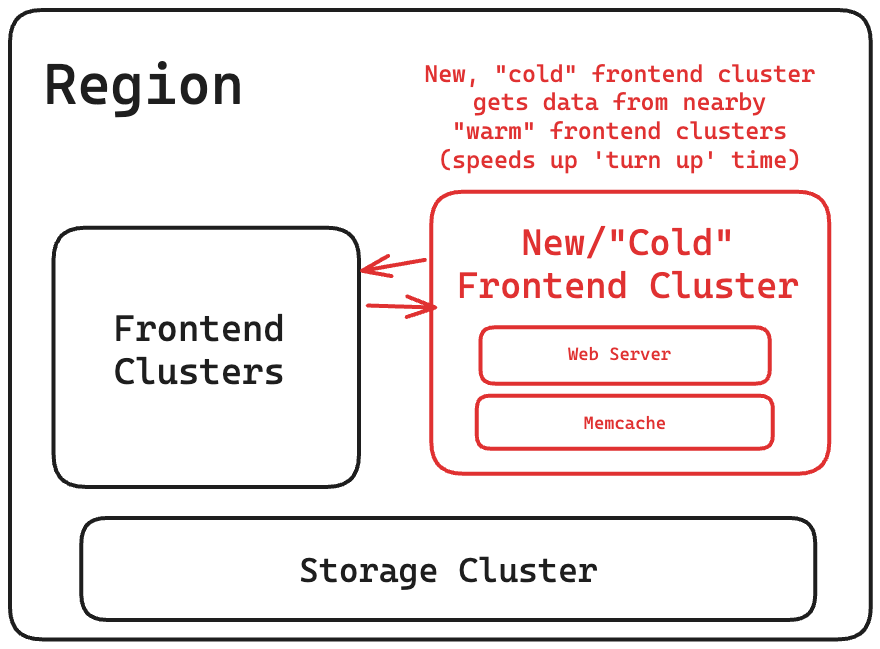
Chuẩn bị cụm nguội (Cold Cluster Prepping)
Một "cụm nguội", hay một cụm frontend có cache trống, sẽ truy xuất dữ liệu từ một "cụm ấm" hoặc một cụm có cache với tỷ lệ truy cập trúng thông thường. Điều này giúp giảm "thời gian khởi động" của một cụm mới từ vài ngày xuống chỉ còn vài giờ.
Lưu ý: Có thể xảy ra tình trạng tranh chấp (race condition) với tính nhất quán của cache. Vấn đề này được giải quyết bằng cách thêm thời gian chờ hai giây trước khi xóa dữ liệu trong cụm nguội. Thời gian chờ này sẽ được tắt sau khi tỷ lệ truy cập trúng cache của cụm nguội giảm xuống.
Worldwide Scaling
Các vùng được đặt trên khắp thế giới vì nhiều lý do:
- Gần người dùng hơn: Cải thiện tốc độ truy cập và trải nghiệm người dùng.
- Giảm thiểu tác động của thiên tai: Ngăn chặn gián đoạn dịch vụ do mất điện, bão lũ, v.v.
- Thúc đẩy kinh tế: Tận dụng chi phí điện rẻ hơn, ưu đãi thuế, v.v.
Cấu trúc vùng:
- Mỗi vùng bao gồm một cụm lưu trữ lưu trữ dữ liệu chính và một số cụm frontend xử lý các truy vấn của người dùng.
- Một vùng được chọn làm vùng chính chứa cơ sở dữ liệu chính (master), các vùng khác chứa bản sao chỉ đọc (read-only replica) được đồng bộ hóa thông qua cơ chế sao chép của MySQL.
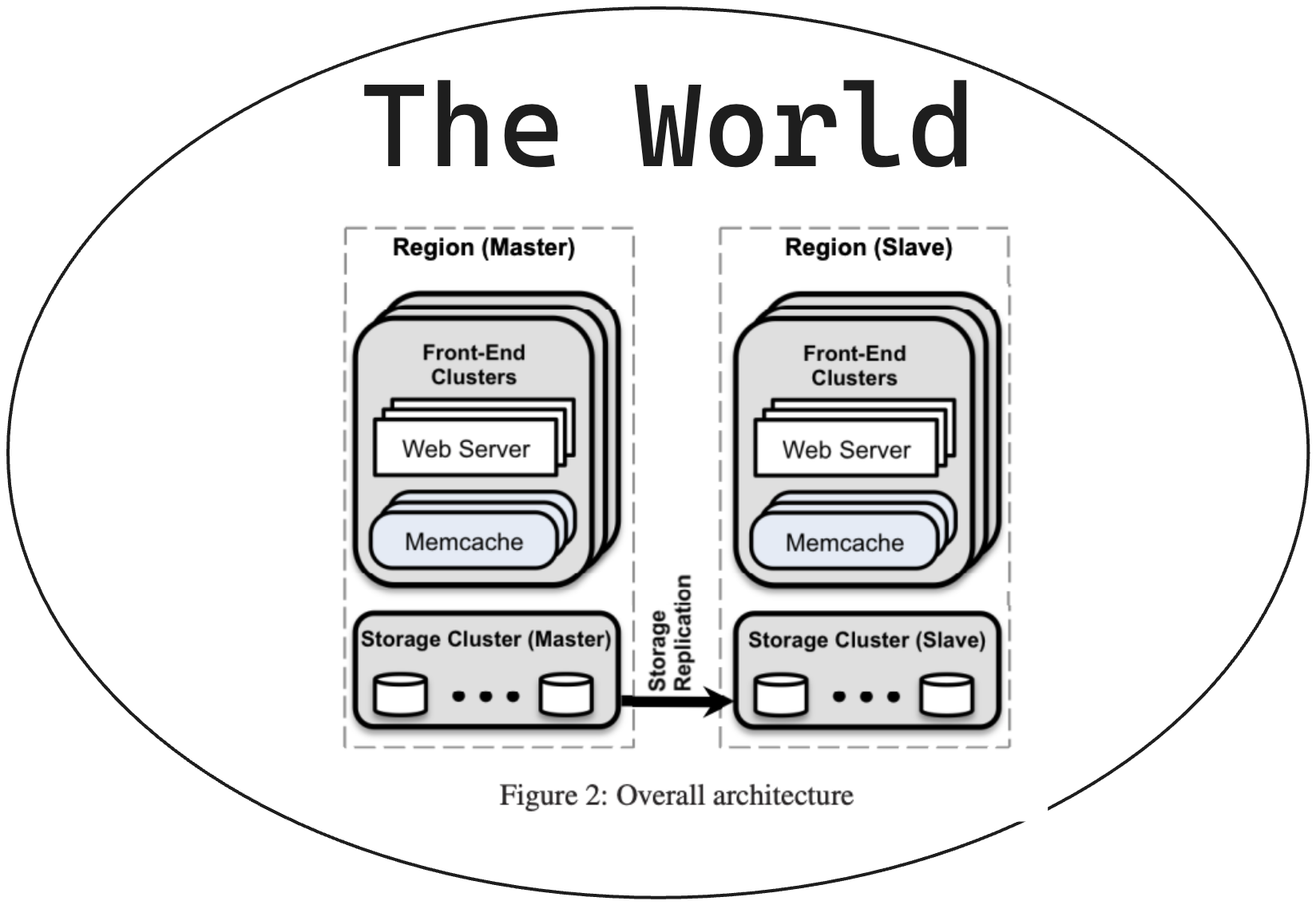
Lợi ích:
- Tăng khả năng chịu lỗi và tính sẵn sàng của dịch vụ.
- Cải thiện hiệu suất bằng cách phân tán tải dữ liệu trên nhiều vùng.
- Giảm phụ thuộc vào một trung tâm dữ liệu duy nhất.
Họ ưu tiên hiệu suất và thời gian hoạt động cao, nhưng vẫn đảm bảo tính nhất quán cuối cùng gần đúng.
Nhóm Facebook đã triển khai daemon vô hiệu hóa mcsqueal sau khi mở rộng sang nhiều vùng. Điều này cho phép họ viết mã để xử lý đúng các điều kiện đua trên toàn cầu ngay từ đầu.
Họ sử dụng cơ chế đánh dấu từ xa để giảm khả năng đọc dữ liệu cũ, cao hơn khi ghi xảy ra từ vùng không phải vùng chính. Bạn có thể đọc thêm về nó trong bài báo.
Các tối ưu hóa hiệu suất khác
Họ đã tối ưu hóa chính memcached:
- Cho phép tự động mở rộng bảng băm nội bộ.
- Biến máy chủ thành đa luồng sử dụng khóa toàn cục.
- Cung cấp cho mỗi luồng cổng UDP riêng.
- Hai tối ưu hóa đầu tiên đã được đóng góp cho cộng đồng mã nguồn mở.
- Họ cũng có nhiều tối ưu hóa khác mà chỉ sử dụng nội bộ trong Facebook.
Nâng cấp phần mềm cho một cụm máy chủ memcached có thể mất hơn 12 giờ.
- Họ đã sửa đổi memcached để lưu trữ các giá trị được lưu trong cache và các cấu trúc dữ liệu khác trong các vùng bộ nhớ chia sẻ, nhằm giảm thiểu sự gián đoạn và thời gian ngừng hoạt động.
Xử lý lỗi
Với quy mô khổng lồ như Facebook, hỏng hóc linh kiện diễn ra thường xuyên, bao gồm cả máy chủ, ổ cứng và các phần cứng khác. Trung bình mỗi phút có một vài thành phần bị lỗi.
Để giải quyết vấn đề này, Facebook sử dụng một hệ thống tự động khắc phục sự cố. Hệ thống này sẽ tự động thay thế các máy chủ gặp sự cố bằng các máy chủ dự phòng.
Khoảng 1% số máy chủ memcache trong một cụm được phân bổ vào “Gutter pool” (bể dự phòng). Các máy chủ này chuyên dùng để thay thế các máy chủ chính bị hỏng hóc.
Kiến trúc tổng quan
Bài học kinh nghiệm từ Facebook
Dựa trên phần "Kết luận" (Section 9) của bài báo, đây là những bài học quan trọng nhất từ Facebook:
-
Tách biệt bộ nhớ cache và hệ thống lưu trữ bền vững: Cho phép mở rộng độc lập và linh hoạt hơn.
-
Tính năng giám sát, gỡ lỗi và hiệu quả vận hành quan trọng không kém hiệu suất: Đảm bảo hệ thống ổn định và dễ quản lý.
-
Quản lý thành phần có trạng thái phức tạp hơn thành phần không trạng thái: Giữ logic ở phần client không trạng thái giúp phát triển tính năng nhanh chóng và giảm gián đoạn dịch vụ.
-
Hệ thống phải hỗ trợ triển khai và thu hồi dần dần các tính năng mới, ngay cả khi dẫn đến sự khác biệt tạm thời giữa các phiên bản.
-
Sự đơn giản là tối quan trọng: Thiết kế hệ thống đơn giản, dễ hiểu để giảm chi phí bảo trì và nâng cao tính ổn định.
Những bài học này có giá trị cho bất kỳ ai đang xây dựng hệ thống phân tán quy mô lớn và phức tạp. Ngăn cách các thành phần, tập trung vào vận hành, và ưu tiên sự đơn giản là những nguyên tắc quan trọng để đảm bảo thành công.
Tôi hy vọng bản dịch này cho bạn cái nhìn rõ ràng về những điểm cốt lõi của bài báo. Hãy cho tôi biết nếu bạn có bất kỳ câu hỏi nào khác.
All rights reserved
