Cách chạy Qwen3 với LMStudio - Kỹ thuật sử dụng AI cục bộ
Gần đây, thế giới AI thực sự đang rất sôi động. Đặc biệt là sự phát triển của các mô hình ngôn ngữ lớn (LLM) thật đáng kinh ngạc. Mới đây, nhóm Qwen đã phát hành mô hình mới "Qwen3", và nó thực sự là một con quái vật đấy. Nó đạt được kết quả tuyệt vời trong các nhiệm vụ lập trình, toán học và suy luận.
Tôi thường thích chạy các mô hình AI cục bộ, và lần này tôi đã thử chạy Qwen3 trên máy của mình bằng LMStudio. Mặc dù API đám mây cũng tiện lợi, nhưng việc chạy trên PC của riêng mình giúp tôi không phải lo lắng về quyền riêng tư và dễ dàng quản lý chi phí. Hơn nữa, có thể sử dụng ngoại tuyến thật tuyệt vời!
Qwen3 có gì đặc biệt?
Qwen3 là LLM thế hệ thứ 3 được phát hành vào ngày 29 tháng 4 năm 2025, với nhiều cải tiến so với phiên bản trước. Đặc biệt là khả năng suy luận được nâng cao, và một số mô hình còn áp dụng kiến trúc Mixture-of-Experts (MoE).
https://github.com/QwenLM/Qwen3
Các biến thể của mô hình
Qwen3 có nhiều kích thước mô hình khác nhau:
-
Mô hình MoE:
- Qwen3-235B-A22B (tổng số tham số 235B, tham số hoạt động 22B)
- Qwen3-30B-A3B (tổng số tham số 30B, tham số hoạt động 3B)
-
Mô hình dày đặc (Dense):
- Qwen3-32B
- Qwen3-14B
- Qwen3-8B
- Qwen3-4B
- Qwen3-1.7B
- Qwen3-0.6B
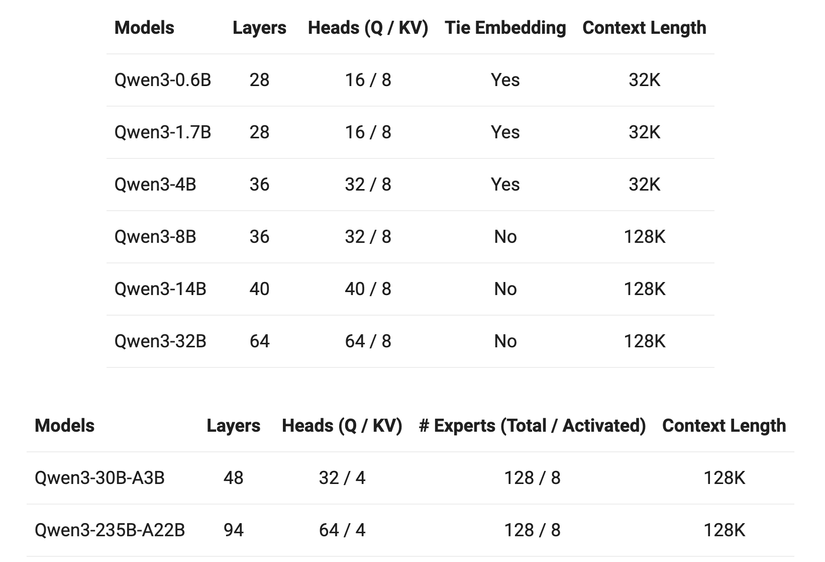
Tất cả đều được mã nguồn mở dưới giấy phép Apache 2.0, thật tuyệt vời phải không?
Đặc điểm kỹ thuật
-
Chuyển đổi chế độ suy nghĩ
- Chế độ suy nghĩ: Lập luận từng bước đối với các vấn đề phức tạp, suy nghĩ sâu trước khi trả lời
- Chế độ không suy nghĩ: Trả lời ngay lập tức cho các câu hỏi đơn giản
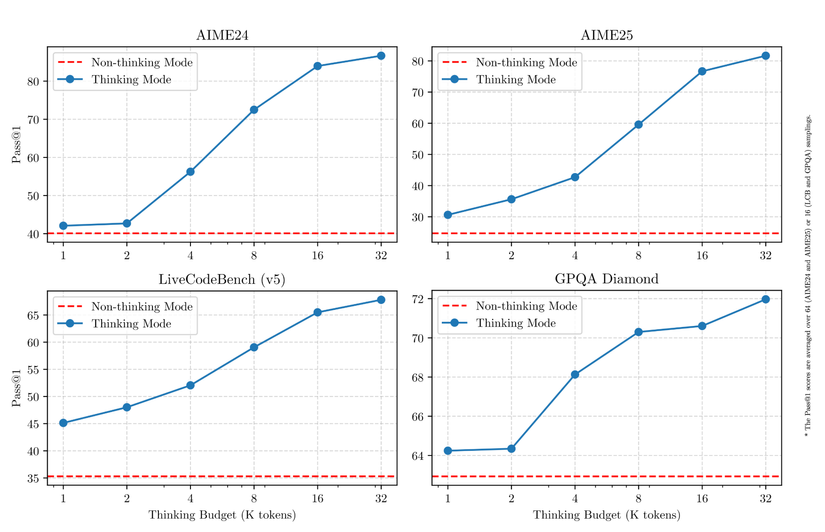
Khi sử dụng thực tế, tính năng này rất tiện lợi. Tôi có thể yêu cầu "suy nghĩ kỹ" cho các vấn đề phức tạp, và nhận câu trả lời nhanh chóng cho các câu hỏi đơn giản.
-
Hỗ trợ đa ngôn ngữ Hỗ trợ 119 ngôn ngữ và phương ngữ, nên bạn có thể sử dụng tiếng Việt mà không gặp vấn đề gì.
-
Tăng cường chức năng đại lý (agent) Khả năng tạo mã được cải thiện, điều này thực sự tuyệt vời đối với các lập trình viên.
-
Phương pháp đào tạo tiến hóa
- Tiền xử lý: Học từ khoảng 36 nghìn tỷ token (gấp đôi Qwen2.5)
- Hậu xử lý: Đường ống đào tạo 4 giai đoạn để tăng cường khả năng suy nghĩ
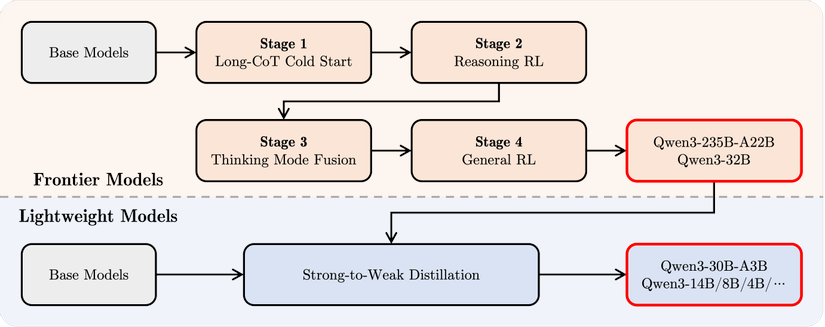
- Tiền xử lý: Học từ khoảng 36 nghìn tỷ token (gấp đôi Qwen2.5)
Hiệu suất đánh giá
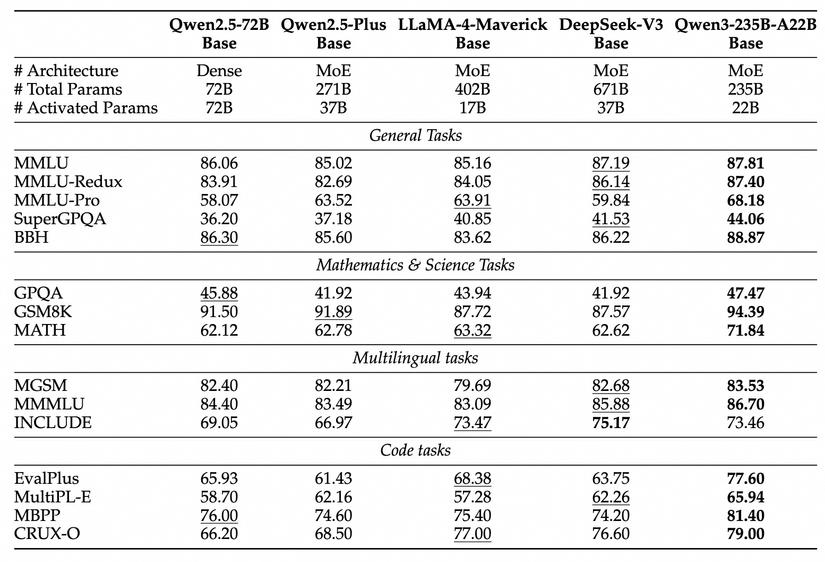
Điều đáng ngạc nhiên là các mô hình nhỏ của Qwen3 có hiệu suất tương đương hoặc thậm chí vượt trội so với các mô hình lớn của thế hệ trước:
Qwen3-1.7B≈Qwen2.5-3BQwen3-4B≈Qwen2.5-7B(trong một số khía cạnh còn tương đương vớiQwen2.5-72B-Instruct!)Qwen3-8B≈Qwen2.5-14BQwen3-14B≈Qwen2.5-32BQwen3-32B≈Qwen2.5-72B
Đặc biệt là hiệu suất trong các nhiệm vụ STEM, lập trình và suy luận được cải thiện đáng kể. Đối với các mô hình MoE, mặc dù chỉ có khoảng 10% tham số hoạt động, nhưng chúng vẫn có hiệu suất tương đương với các mô hình dày đặc lớn hơn. Điều này giúp giảm đáng kể chi phí đào tạo và suy luận.
Cách chạy Qwen3 với LMStudio
LMStudio là một công cụ giúp chạy LLM cục bộ một cách dễ dàng, cho phép quản lý và thực thi các mô hình mà không cần cấu hình phức tạp. Nó cũng cung cấp công cụ dòng lệnh và máy chủ API, rất thuận tiện cho các nhà phát triển.
Cài đặt và thiết lập
Đầu tiên, bạn cần cài đặt LMStudio và khởi động ít nhất một lần. Sau đó, bootstrap công cụ dòng lệnh "lms".
Đối với macOS và Linux:
~/.lmstudio/bin/lms bootstrap
Đối với Windows:
cmd /c %USERPROFILE%/.lmstudio/bin/lms.exe bootstrap
Để xác nhận cài đặt, mở cửa sổ terminal mới và chạy lệnh lms:
lms
Bạn sẽ thấy kết quả như sau:
lms - LM Studio CLI - v0.2.22
GitHub: https://github.com/lmstudio-ai/lmstudio-cli
Usage
lms <subcommand>
where <subcommand> can be one of:
- status - Prints the status of LM Studio
- server - Commands for managing the local server
- ls - List all downloaded models
- ps - List all loaded models
- load - Load a model
- unload - Unload a model
- create - Create a new project with scaffolding
- log - Log operations. Currently only supports streaming logs from LM Studio via `lms log stream`
- version - Prints the version of the CLI
- bootstrap - Bootstrap the CLI
For more help, try running `lms <subcommand> --help`
Tải xuống và chạy mô hình Qwen3
LMStudio hỗ trợ nhiều mô hình khác nhau, bao gồm cả Qwen3. Các mô hình Qwen3 có sẵn bao gồm:
qwen3:0.6bqwen3:1.7bqwen3:4bqwen3:8bqwen3:14bqwen3:32bqwen3:30b-a3b(mô hình MoE nhỏ)
Ví dụ, để tải xuống và chạy mô hình 1.7B tham số:
lms get qwen3-1.7b
Lệnh này sẽ tải xuống mô hình và bắt đầu một phiên trò chuyện tương tác.
Khởi động và dừng máy chủ API
Để sử dụng như một API, khởi động máy chủ:
lms server start
Khi sử dụng xong, dừng máy chủ:
lms server stop
Gọi Qwen3 từ mã
Sử dụng curl:
curl http://localhost:1234/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen3-1.7b",
"messages": [
{ "role": "system", "content": "Always answer in rhymes." },
{ "role": "user", "content": "Introduce yourself." }
],
"temperature": 0.7,
"max_tokens": -1,
"stream": true
}'
Sử dụng Python:
from openai import OpenAI
# Kết nối đến máy chủ cục bộ
client = OpenAI(base_url="http://localhost:1234/v1",
api_key="lm-studio")
completion = client.chat.completions.create(
model="qwen3-1.7b",
messages=[
{"role": "system", "content": "Always answer in rhymes."},
{"role": "user", "content": "Introduce yourself."}
],
temperature=0.7,
)
print(completion.choices[0].message)
Sử dụng TypeScript:
import OpenAI from 'openai';
const client = new OpenAI({
apiKey: "lm-studio", // Thực tế không cần thiết
baseUrl: "http://localhost:1234/v1"
});
async function main() {
const chatCompletion = await client.chat.completions.create({
messages: [{ role: 'user', content: 'Say this is a test' }],
model: "qwen3-1.7b",
});
}
main();
Kiểm tra API của LMStudio với Apidog
Cá nhân tôi thấy Apidog rất tiện lợi cho việc kiểm tra API. Nó tương thích tốt với chế độ API của LMStudio, giúp gửi yêu cầu và kiểm tra phản hồi một cách dễ dàng.
Cách sử dụng Apidog để kiểm tra API của LMStudio:
- Tạo yêu cầu API mới
- Đặt endpoint là
http://localhost:1234/v1/chat/completions - Gửi yêu cầu và theo dõi phản hồi trong dòng thời gian thực
- Sử dụng tính năng trích xuất JSONPath để phân tích phản hồi tự động (tính năng này tốt hơn Postman theo tôi)
Để kiểm tra phản hồi dạng stream, thêm "stream": true vào nội dung yêu cầu:
{
"model": "qwen3-1.7b",
"messages": [
{ "role": "system", "content": "Luôn trả lời theo vần điệu." },
{ "role": "user", "content": "Giới thiệu bản thân." }
],
"temperature": 0.7,
"max_tokens": -1,
"stream": true
}
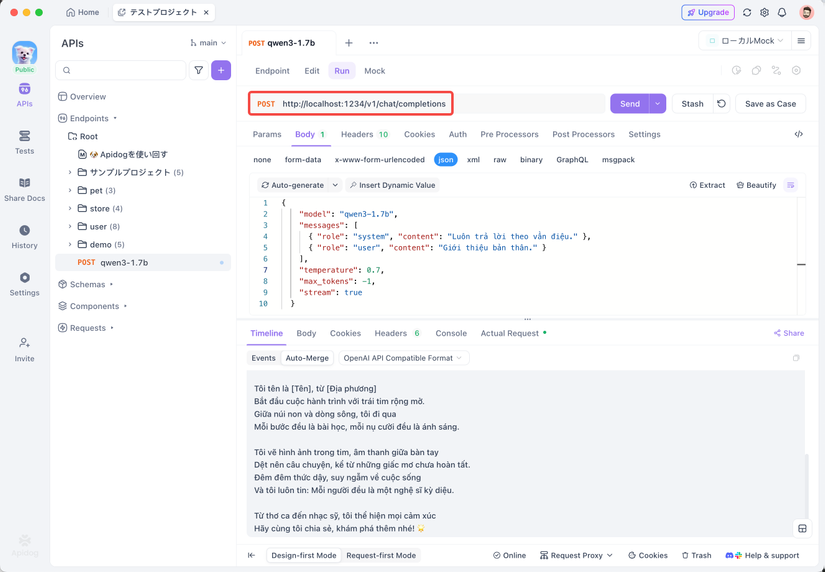
Tính năng stream nâng cao của Apidog giúp tích hợp các thông điệp stream, giúp việc gỡ lỗi dễ dàng hơn. Điều này rất hữu ích trong phát triển ứng dụng thực tế.
Kết luận
Qwen3 thực sự là một mô hình tuyệt vời, đặc biệt ấn tượng là các mô hình nhỏ vẫn có hiệu suất tương đương hoặc vượt trội so với các mô hình lớn của thế hệ trước. Với LMStudio, bạn có thể dễ dàng chạy các mô hình mạnh mẽ này cục bộ, đảm bảo quyền riêng tư và sử dụng công nghệ AI mới nhất một cách hiệu quả về chi phí.
Cá nhân tôi đặc biệt thích Qwen3-4B. Mặc dù có kích thước tương đối nhỏ, nhưng hiệu suất đáng kinh ngạc và chạy mượt mà trên PC thông thường. Các tính năng như chế độ suy nghĩ lai và hỗ trợ đa ngôn ngữ rất hữu ích trong các dự án thực tế.
Trong bối cảnh hệ sinh thái phần cứng và phần mềm không ngừng phát triển, sức mạnh của các mô hình ngôn ngữ lớn ngày càng được dân chủ hóa, chuyển từ máy chủ đám mây đến máy tính cục bộ của chúng ta. Hãy thử Qwen3 với LMStudio và Apidog để trải nghiệm tiền tuyến của cuộc cách mạng AI cục bộ này!
Bạn đã thử chưa? Hãy cho tôi biết bạn đang sử dụng nó cho mục đích gì trong phần bình luận. Tôi cũng rất muốn thảo luận về sự so sánh với các mô hình khác và sự khác biệt về hiệu suất.
All rights reserved
