Các Phương Pháp Triển Khai MongoDB Database - Từ Standalone Đến Sharded Cluster
Chào các bạn! Sau khi đã tìm hiểu về các phương pháp triển khai MySQL trong bài viết trước, hôm nay chúng ta sẽ khám phá thế giới của MongoDB - một trong những NoSQL database phổ biến nhất hiện nay. MongoDB có kiến trúc và cách triển khai khác biệt hoàn toàn so với MySQL, mang đến những ưu điểm độc đáo cho các use cases hiện đại! 🍃

Tại Sao MongoDB Cần Các Phương Pháp Triển Khai Khác Nhau?
Đặc Điểm Riêng Của MongoDB
MongoDB là document-oriented database, khác biệt cơ bản so với relational database như MySQL:
🎯 Điểm Khác Biệt Cốt Lõi:
- Schema-less: Không cần định nghĩa schema cứng nhắc
- Document Model: Lưu trữ dữ liệu dưới dạng JSON-like documents (BSON)
- Horizontal Scaling Native: Được thiết kế để scale ngang từ đầu
- Flexible Data Structure: Dễ dàng thay đổi structure mà không migration phức tạp
- Rich Query Language: Truy vấn mạnh mẽ với aggregation framework
- Built-in Replication và Sharding: HA và scaling được tích hợp sẵn
Thách Thức Triển Khai MongoDB
📊 Yêu Cầu Khác Với SQL Database:
- Write-Heavy Workloads: MongoDB tối ưu cho ghi nhiều
- Large Data Volumes: Xử lý petabytes data với sharding
- Geographic Distribution: Đặt data gần users (zone sharding)
- High Throughput: Millions operations per second
- Flexible Schema Evolution: Thay đổi structure không downtime
MongoDB cung cấp ba cấp độ triển khai chính để đáp ứng các nhu cầu từ đơn giản đến phức tạp.
I. Standalone Instance - Triển Khai Đơn Giản Nhất
Bản Chất và Đặc Điểm
Standalone MongoDB là một server MongoDB duy nhất chạy độc lập, không có replication hay sharding.
🏗️ Kiến Trúc Đơn Giản:
┌─────────────────┐
│ Application │
└────────┬────────┘
│
▼
┌─────────────────┐
│ MongoDB Server │
│ (Standalone) │
│ Port 27017 │
└─────────────────┘
📊 Đặc Điểm Chính:
- Single Process: Một mongod process duy nhất
- No Redundancy: Không có backup tự động
- Simple Configuration: Config đơn giản
- Development Friendly: Lý tưởng cho dev và testing
- No Automatic Failover: Không có khả năng tự động phục hồi
Ưu Điểm của Standalone
✅ Đơn Giản và Dễ Setup:
- Cài đặt nhanh chóng, chỉ mất vài phút
- Configuration đơn giản
- Không cần quan tâm đến replication/sharding phức tạp
✅ Chi Phí Thấp:
- Chỉ cần 1 server
- RAM requirements thấp
- Phù hợp cho budget hạn chế
✅ Performance Tốt Cho Workload Nhỏ:
// Với traffic nhỏ, standalone hoạt động tốt
// Ví dụ: Simple CRUD operations
db.posts.find({
status: "published"
}).sort({
created_at: -1
}).limit(10);
// Response time: < 5ms với proper indexing
✅ Flexibility Cao:
// Schema-less nature của MongoDB
// Document 1
{
"_id": ObjectId("..."),
"name": "Product A",
"price": 100,
"category": "Electronics"
}
// Document 2 - Different structure, same collection!
{
"_id": ObjectId("..."),
"name": "Product B",
"price": 50,
"category": "Books",
"author": "John Doe", // Field mới
"isbn": "123-456" // Field mới
}
Nhược Điểm và Hạn Chế
❌ Single Point of Failure:
MongoDB Server crash = Application down
├── Hardware failure
├── Process crash
├── Disk full
└── Network issues
❌ Không Có High Availability:
- Maintenance = downtime
- No automatic failover
- Recovery phụ thuộc manual intervention
❌ Giới Hạn Về Scalability:
// Khi data lớn, single server gặp bottleneck
// Ví dụ: 100GB+ data, 1000+ concurrent connections
db.serverStatus().connections
// {
// "current": 950,
// "available": 51200, // Giới hạn connections
// "totalCreated": NumberLong(12345)
// }
❌ Limited Performance:
- Vertical scaling expensive (RAM, CPU, Disk)
- Không thể phân tán load
- Disk I/O bottleneck với heavy writes
Khi Nào Nên Dùng Standalone?
| Tình Huống | Lý Do Phù Hợp |
|---|---|
| Development/Testing | Môi trường dev, không cần HA |
| Prototypes/MVP | Triển khai nhanh, validate idea |
| Small Applications | < 10GB data, < 100 concurrent users |
| Learning MongoDB | Học tập và thực hành |
| Temporary/Cache Data | Dữ liệu có thể mất không ảnh hưởng lớn |
II. Replica Set - High Availability Với Automatic Failover
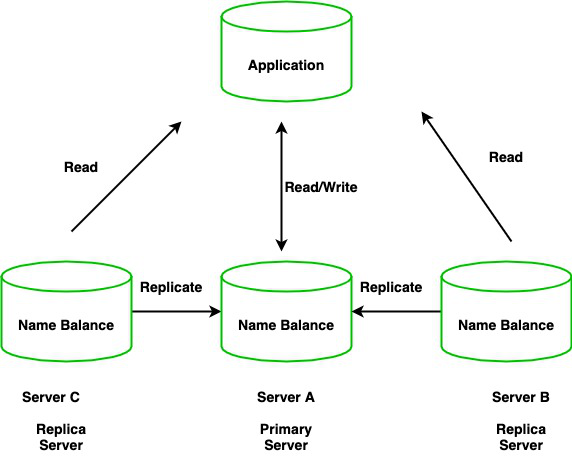
Bản Chất và Mục Tiêu
Replica Set là nhóm các MongoDB instances duy trì cùng một dataset, cung cấp redundancy và high availability.
🎯 Mục Tiêu Chính:
- Automatic Failover: Tự động chuyển Primary khi node chết
- Data Redundancy: Nhiều copies của data
- Read Scalability: Phân tán read operations đến Secondaries
- Zero Downtime Maintenance: Upgrade từng node mà không downtime
- Disaster Recovery: Backup tự động và realtime
🔑 Khái Niệm Quan Trọng:
- Primary: Node duy nhất nhận write operations
- Secondary: Replicate data từ Primary, có thể serve reads
- Arbiter: Node không chứa data, chỉ tham gia voting (optional)
Kiến Trúc Replica Set
🏗️ Standard 3-Node Replica Set:
┌────────────────────────────────────────────────────┐
│ Application Layer │
└────────────┬──────────────────────┬────────────────┘
│ │
Write│ Read │(optional)
│ │
┌──────▼─────┐ ┌──────▼─────┐
│ Primary │◄───────►│ Secondary │
│ (R/W) │ Sync │ (Read) │
│ Port 27017 │ │ Port 27017 │
└──────┬─────┘ └──────┬─────┘
│ │
│ Heartbeat & Sync │
│ │
│ ┌───────────────┘
│ │
┌────▼──────▼────┐
│ Secondary │
│ (Read) │
│ Port 27017 │
└────────────────┘
Automatic Failover: Nếu Primary chết,
một Secondary được bầu làm Primary mới
Cơ Chế Hoạt Động
📝 Replication Process:
1. Application ghi vào Primary
↓
2. Primary ghi vào local oplog (operations log)
↓
3. Secondaries đọc oplog từ Primary
↓
4. Secondaries apply operations từ oplog
↓
5. Secondaries có data giống Primary (eventually)
🔄 Automatic Failover:
Primary node chết
↓
Secondaries phát hiện (heartbeat timeout)
↓
Secondaries bầu cử Primary mới (election)
↓
Secondary với data mới nhất trở thành Primary
↓
Application reconnect và tiếp tục hoạt động
↓
Downtime: ~10-15 giây (election time)
Connection String Cho Replica Set
// Connection String với TẤT CẢ nodes trong Replica Set
const uri = "mongodb://user:pass@node1:27017,node2:27017,node3:27017/mydb?replicaSet=myReplicaSet";
const client = new MongoClient(uri);
await client.connect();
// Write tự động vào Primary, Read có thể từ Secondary
await collection.insertOne({ user_id: "user123", total: 1500000 });
const orders = await collection.find({ user_id: "user123" }).toArray();
✨ Ưu Điểm Lớn: Connection String KHÔNG BAO GIỜ Thay Đổi!
- MongoDB Driver tự động detect Primary hiện tại
- Khi failover xảy ra → Driver tự động reconnect đến Primary mới
- Application KHÔNG CẦN update connection string hoặc thêm logic phức tạp
- Transparent failover - Chỉ cần retry connection khi bị disconnect
Read Preference - Điều Hướng Đọc
// 5 Options:
collection.find({}).toArray(); // 1. Mặc định đọc từ Primary
collection.find({}).readPref('primaryPreferred'); // 2. Đọc từ Primary nếu có, nếu không thì đọc từ Secondary
collection.find({}).readPref('secondary'); // 3. Đọc từ Secondary
collection.find({}).readPref('secondaryPreferred'); // 4. Đọc từ Secondary nếu có, nếu không thì đọc từ Primary
collection.find({}).readPref('nearest'); // 5. Đọc từ node gần nhất
// Use Cases:
// Analytics → secondary (không ảnh hưởng Primary)
// Critical reads → primary (data mới nhất)
// Geo-distributed → nearest (giảm latency)
Write Concern - Đảm Bảo Write Success
// w: 1 (default) - Chỉ ghi vào Primary và xác nhận ngay
// Nhanh nhất nhưng có thể mất data nếu Primary chết trước khi sync sang Secondary
// Latency: ~1-5ms
await collection.insertOne(doc, { writeConcern: { w: 1 } });
// w: "majority" - Ghi vào Primary VÀ đợi đến khi đa số nodes (>50%) đã nhận được data
// An toàn hơn: nếu Primary chết, data vẫn còn ở Secondary
// Latency: ~10-20ms (Recommended cho Production)
await collection.insertOne(doc, { writeConcern: { w: "majority" } });
// w: "majority", j: true - Ghi vào đa số nodes VÀ phải lưu xuống ổ cứng (journal)
// An toàn nhất: đảm bảo data không mất ngay cả khi server bị mất điện đột ngột
// Latency: ~20-50ms (Dùng cho data cực kỳ quan trọng: giao dịch tiền, đơn hàng...)
await collection.insertOne(doc, { writeConcern: { w: "majority", j: true } });
Ưu Điểm của Replica Set
✅ Tự động chuyển đổi khi Primary chết (Automatic Failover + Transparent Connection)
- Primary chết → Tự động bầu Primary mới → MongoDB Driver tự động reconnect
- Downtime chỉ ~10-15 giây, không cần sửa code hay update connection string
- Khác MySQL Group Replication: MySQL cần application tự detect và update connection, MongoDB Driver tự handle tất cả!
✅ Sao lưu dữ liệu (Data Redundancy)
- Data được lưu trên nhiều nodes, tự động sync liên tục
- Bảo vệ khỏi hỏng ổ cứng, server chết
✅ Tăng hiệu năng đọc (Read Scalability)
- Phân tán đọc đến Secondary → Tổng throughput tăng ~3x
- Primary xử lý: 100% writes + critical reads
- Secondary 1 + 2: Xử lý 80% reads còn lại
✅ Bảo trì không downtime (Zero Downtime Maintenance)
# Upgrade/Restart từng node một, không ảnh hưởng service
# 1. Upgrade Secondary 1 → Secondary 2
# 2. Hạ cấp Primary xuống Secondary: rs.stepDown()
# 3. Upgrade node cũ (former Primary)
✅ Geographic Distribution
// Đặt nodes ở nhiều vùng để giảm latency và tăng độ an toàn
{ _id: 0, host: "node1-us-east.example.com:27017" }, // Mỹ Đông
{ _id: 1, host: "node2-us-west.example.com:27017" }, // Mỹ Tây
{ _id: 2, host: "node3-eu.example.com:27017" } // Châu Âu
Nhược Điểm và Hạn Chế
❌ Trễ đồng bộ (Replication Lag)
- Secondary có thể chậm hơn Primary vài giây
- Ví dụ: User vừa tạo đơn hàng → Đọc từ Secondary → Chưa thấy đơn
- Cần dùng
readPref('primary')cho data quan trọng
❌ Chỉ 1 node được ghi (Write Bottleneck)
- Không thể tăng hiệu năng ghi bằng cách thêm Secondary
- Primary có thể quá tải với app write-heavy
- Giải pháp: Dùng Sharding (phần sau)
❌ Chi phí tăng gấp 3
- 3 nodes × 100GB data = 300GB tổng storage
- 3 nodes × $50/tháng = $150/tháng
❌ Tốn băng thông mạng
- Primary phải sync liên tục sang Secondary
- Cần network tốt giữa các nodes (đặc biệt khi phân tán địa lý)
Khi Nào Nên Dùng Replica Set?
| Tình Huống | Lý Do Phù Hợp |
|---|---|
| Production Applications | Cần HA và automatic failover |
| Mission-Critical Data | Không thể mất dữ liệu, cần redundancy |
| Read-Heavy Workloads | Scale reads với Secondaries |
| 24/7 Services | Zero downtime maintenance |
| Distributed Teams | Geographic distribution |
III. Sharded Cluster

Lý Do Ra Đời
Replica Set giải quyết được High Availability nhưng không giải quyết được horizontal write scaling và storage limits. Khi:
- Data > 2TB trên một replica set
- Write throughput > khả năng của Primary
- Cần phân tán data theo địa lý (zone sharding)
→ Sharded Cluster ra đời để phân tán data ngang (horizontal partitioning)
🎯 Mục Tiêu của Sharding:
- Horizontal Scalability: Thêm shards để tăng capacity và throughput
- Distribute Data: Phân tán data theo shard key
- Geographic Sharding: Đặt data gần users (zone sharding)
- Parallel Processing: Query parallel trên nhiều shards
- No Single Bottleneck: Mỗi shard là replica set riêng
Kiến Trúc Sharded Cluster
🏗️ Complete Sharded Cluster Architecture:
┌─────────────┐
│ Application │
└──────┬──────┘
│
┌──────▼───────────────────────────┐
│ mongos (Router - Định tuyến) │
│ Nhận query → Gửi đến đúng shard │
└──┬────────────┬────────────┬─────┘
│ │ │
┌───────▼──────┐ ┌──▼────────┐ ┌─▼──────────┐
│ Shard 1 │ │ Shard 2 │ │ Shard N │
│ (Replica Set)│ │(Replica Set)│(Replica Set)│
│ user: 1-1M │ │ user: 1M-2M│ │ user: 2M+ │
└──────────────┘ └───────────┘ └────────────┘
┌────────────────────────────────────────┐
│ Config Servers (Replica Set 3 nodes) │
│ Lưu metadata: Data nằm ở shard nào? │
└────────────────────────────────────────┘
📦 3 Thành Phần Chính:
- Shards (Các mảnh): Mỗi shard là 1 Replica Set, chứa 1 phần data
- Config Servers: Lưu metadata (data nằm ở shard nào), bắt buộc 3 nodes
- mongos (Router): Định tuyến query đến đúng shard, app chỉ kết nối với mongos
💡 mongos = MySQL Router:
- Application chỉ cần connect đến mongos (IP cố định)
- mongos tự động route query đến shard phù hợp
- Khi topology thay đổi → mongos tự động cập nhật → Application không biết
- 100% Transparent như InnoDB Cluster + Router của MySQL
Sharding Key - Quyết Định Data Nằm Ở Shard Nào
🔑 Shard Key là gì? Là 1 field (hoặc nhiều fields) mà MongoDB dùng để quyết định document này bỏ vào shard nào.
3 Cách Chọn Shard Key:
1️⃣ Range-Based (Chia theo khoảng số)
sh.shardCollection("myapp_db.users", { user_id: 1 })
Shard 1: user_id từ 1 → 1 triệu
Shard 2: user_id từ 1 triệu → 2 triệu
Shard 3: user_id từ 2 triệu trở lên
✅ Tốt cho query theo khoảng: "Tìm user từ 100k-200k" → Chỉ tìm 1 shard
❌ Xấu nếu ID tăng dần: User mới luôn rơi vào shard cuối → Shard đó quá tải
2️⃣ Hashed (Băm - Trộn lẫn)
sh.shardCollection("myapp_db.orders", { user_id: "hashed" })
MongoDB hash user_id thành số ngẫu nhiên:
- user_id 123 → hash abc123 → Shard 2
- user_id 124 → hash xyz789 → Shard 1
- user_id 125 → hash def456 → Shard 3
✅ Ghi đều khắp nơi, không có shard nào quá tải
❌ Query theo khoảng phải tìm khắp nơi: "Tìm user > 100k" → Phải hỏi cả 3 shards
3️⃣ Compound (Kết hợp nhiều fields)
sh.shardCollection("myapp_db.users", { country: 1, user_id: 1 })
Chia theo quốc gia TRƯỚC, rồi mới chia theo user_id:
- country: "VN", user_id: 1-500k → Shard 1
- country: "VN", user_id: 500k+ → Shard 2
- country: "US", user_id: bất kỳ → Shard 3
✅ Query theo quốc gia rất nhanh: "Tìm user VN" → Chỉ tìm Shard 1-2
✅ Có thể đặt data gần người dùng: VN → Server ASIA, US → Server US
⚠️ Lưu Ý Khi Chọn Shard Key:
❌ TRÁNH: Ít giá trị khác nhau
{ gender: 1 } // Chỉ có Nam/Nữ → Không chia được nhiều shard
❌ TRÁNH: Giá trị cứ tăng mãi (timestamp, _id, auto-increment)
{ created_at: 1 } // Document mới luôn vào shard cuối → Quá tải
✅ NÊN: Nhiều giá trị khác nhau + phân tán đều
{ order_id: "hashed" } // order_id có hàng triệu giá trị, hash để chia đều
✅ NÊN: Theo cách app hay query
{ category: 1, product_id: 1 } // Nếu app hay tìm theo category
Kết Nối và Query với Sharded Cluster
🔗 Connection (Qua mongos - Router):
const uri = "mongodb://localhost:27016/myapp_db"; // Kết nối tới mongos, KHÔNG phải shard
const client = new MongoClient(uri);
// App không biết có bao nhiêu shards, mongos tự động routing
await orders.insertOne(order); // mongos tự route đến shard đúng
💡 Lưu Ý Quan Trọng:
- Connection string chỉ trỏ đến mongos, KHÔNG trỏ trực tiếp đến shards
- mongos handle tất cả routing logic
- Application code cực kỳ đơn giản, không cần biết topology
📍 2 Loại Query:
1. Targeted Query (Nhanh ⚡)
db.orders.find({ order_id: "ORD123" }) // Có shard key
// → mongos biết chính xác shard nào có data → Chỉ query 1 shard
2. Scatter-Gather Query (Chậm 🐢)
db.orders.find({ total: { $gt: 1000000 } }) // KHÔNG có shard key
// → mongos phải hỏi TẤT CẢ shards → Gộp kết quả lại
💡 Bí quyết tăng tốc: Luôn thêm shard key vào query!
Tự Động Cân Bằng (Balancing)
🔄 MongoDB tự động cân bằng data giữa các shards:
- Data được chia thành chunks (mảnh 64MB)
- Balancer tự động di chuyển chunks từ shard đầy → shard ít data hơn
- Ví dụ: Shard 1 có 100 chunks, Shard 2 có 50 chunks → Balancer tự chuyển
sh.status() // Xem phân bố chunks
// Có thể tắt balancer khi bảo trì (tránh ảnh hưởng performance)
sh.stopBalancer()
sh.startBalancer()
Ưu Điểm của Sharded Cluster
✅ Tăng hiệu năng ghi không giới hạn
- Thêm shard → Tăng write capacity tuyến tính
- 2 shards: 20K writes/sec | 4 shards: 40K writes/sec | 8 shards: 80K writes/sec
✅ Lưu trữ không giới hạn
- 10 shards × 2TB = 20TB tổng cộng
✅ Phân tán địa lý (Zone Sharding)
- Data VN → Shard ASIA, Data EU → Shard EU
- Giảm latency cho user ở từng khu vực
✅ Xử lý song song
- Aggregation chạy đồng thời trên nhiều shards → Nhanh hơn nhiều
Nhược Điểm và Hạn Chế
❌ Phức tạp và đắt tiền
- Cần tối thiểu 11+ servers (Config 3 + Shard1 3 + Shard2 3 + mongos 2)
- Setup và vận hành phức tạp, khó troubleshoot
❌ Không thể đổi shard key
- Chọn shard key sai → Phải migrate toàn bộ data (rất đau đầu!)
❌ Query không có shard key rất chậm
- Phải hỏi tất cả shards → N lần chậm hơn
❌ Transaction qua nhiều shards chậm
- MongoDB 4.2+ hỗ trợ nhưng latency cao
Khi Nào Nên Dùng Sharded Cluster?
| Tình Huống | Lý Do Phù Hợp |
|---|---|
| Big Data (> 2TB) | Storage capacity vượt quá 1 replica set |
| High Write Throughput | Write load > khả năng của 1 Primary |
| Global Applications | Cần distribute data theo địa lý |
| Predictable Growth | Biết data sẽ grow exponentially |
| Budget Sufficient | Đủ resources cho complex infrastructure |
IV. So Sánh Ba Phương Pháp Triển Khai
Bảng So Sánh Chi Tiết
| Tiêu Chí | Standalone | Replica Set | Sharded Cluster |
|---|---|---|---|
| 🎯 Mục tiêu | Đơn giản, dev/test | High Availability | Horizontal scaling + HA |
| 📊 Số nodes tối thiểu | 1 | 3 | 11+ (3 config + 2×3 shards + 2 mongos) |
| 🔄 Automatic Failover | ❌ Không | ✅ Có (~10-15s) | ✅ Có (per shard) |
| 🔌 Connection Management | Direct DB | Driver auto-handle | Via mongos (router) |
| 📈 Write Scalability | ❌ Limited | ❌ Limited (1 Primary) | ✅ Linear (N shards) |
| 📖 Read Scalability | ❌ Không | ✅ Có (Secondaries) | ✅✅ Cao (N shards × replicas) |
| 💾 Storage Capacity | Limited by single server | Limited by replica set | Unlimited (add shards) |
| 🌐 Geographic Distribution | ❌ Không | ⚡ Có (replicas) | ✅✅ Tốt (zone sharding) |
| 🔧 Complexity | ⭐ Rất thấp | ⭐⭐ Trung bình | ⭐⭐⭐⭐⭐ Rất cao |
| 💰 Chi phí | $ | $$$ | $$$$$+ |
| ⚡ Query Performance | Fast (single node) | Fast (local reads) | Variable (depends on query) |
| 🛠️ Maintenance | Dễ | Trung bình | Phức tạp |
| 📚 Use Cases | Dev, small apps | Most production apps | Big data, global apps |
Decision Tree - Cây Quyết Định
Bạn cần triển khai MongoDB?
│
├─→ Development/Testing/Learning?
│ └─→ ✅ Standalone
│
├─→ Production application?
│ │
│ ├─→ Data < 500GB và write moderate?
│ │ │
│ │ ├─→ Cần High Availability?
│ │ │ └─→ ✅ Replica Set (3 nodes)
│ │ │
│ │ └─→ Không cần HA (low budget)?
│ │ └─→ ⚠️ Standalone với backup tốt
│ │
│ └─→ Data > 2TB hoặc write very high?
│ │
│ ├─→ Budget sufficient?
│ │ └─→ ✅ Sharded Cluster
│ │
│ └─→ Budget limited?
│ └─→ 💡 Xem xét MongoDB Atlas (managed)
│
└─→ Global application với users worldwide?
└─→ ✅ Sharded Cluster với Zone Sharding
Nhu Cầu và Giải Pháp
| Nhu Cầu | Giải Pháp Phù Hợp | Lý Do |
|---|---|---|
| Learning MongoDB | Standalone | Đơn giản, setup nhanh |
| Startup MVP | Standalone → Replica Set | Start simple, upgrade when needed |
| SaaS Application | Replica Set | HA + read scaling |
| Mobile App Backend | Replica Set | Flexible schema + HA |
| E-commerce (small-mid) | Replica Set | Good balance cost/features |
| Social Media Platform | Sharded Cluster | Billions documents, high writes |
| IoT Platform | Sharded Cluster | Massive data ingestion |
| Global E-commerce | Sharded Cluster + Zone | Data locality + HA |
| Analytics Platform | Sharded Cluster | Large historical data |
V. Best Practices - Những Điều Quan Trọng Nhất
1. Thiết Kế Schema Đúng Cách
Embed (Nhúng) vs Reference (Tham chiếu):
// ✅ Embed - Khi data nhỏ và luôn dùng cùng nhau
{
"name": "Nguyễn Văn A",
"address": { "city": "TP.HCM", "street": "Nguyễn Huệ" } // Nhúng vào
}
// → 1 query lấy hết
// ✅ Reference - Khi data lớn hoặc dùng riêng lẻ
{
"title": "My Blog Post",
"author_id": ObjectId("...") // Tham chiếu đến collection Users
}
// → Tách ra, query riêng khi cần
⚠️ Tránh array quá lớn (max 16MB):
- Dùng Bucket pattern: Chia array thành nhiều documents theo tháng/ngày
2. Index - Chìa Khóa Tăng Tốc
// Luôn tạo index cho fields hay query
db.users.createIndex({ email: 1 }) // Tìm user theo email
db.posts.createIndex({ author_id: 1, created_at: -1 }) // Tìm posts + sort
// Thứ tự quan trọng: Bằng (=) trước, khoảng (>, <) sau
db.users.createIndex({ country: 1, city: 1, age: 1 }) // ✅ ĐÚNG
db.users.createIndex({ age: 1, country: 1 }) // ❌ SAI
// Kiểm tra query có dùng index không:
db.users.find({ email: "..." }).explain("executionStats")
// Xem winningPlan.stage: "IXSCAN" (tốt) hay "COLLSCAN" (tệ)
3. Connection Pooling
const client = new MongoClient(uri, {
maxPoolSize: 50, // Tối đa 50 connections
minPoolSize: 10 // Luôn giữ sẵn 10 connections
});
// ✅ Tạo 1 lần, dùng mãi - KHÔNG tạo mới mỗi request!
4. Backup - Sao Lưu Thường Xuyên
# mongodump - Backup đơn giản
mongodump --uri="mongodb://localhost:27017" --gzip --out=/backup
# Lên lịch backup hàng ngày, lưu 7 ngày gần nhất
# Upload lên S3/Google Cloud để an toàn
5. Bảo Mật
// 1. Bật authentication (bắt buộc đăng nhập)
security:
authorization: enabled
// 2. Tạo user với quyền hạn phù hợp
db.createUser({
user: "app_user",
pwd: "password",
roles: [{ role: "readWrite", db: "myapp_db" }] // Chỉ đọc/ghi myapp_db
})
// 3. SSL/TLS cho kết nối
// 4. Chỉ cho phép IP cụ thể kết nối
6. Giám Sát (Monitoring)
Cần theo dõi:
- Connections: Đang dùng bao nhiêu/tối đa bao nhiêu
- Replication Lag: Secondary chậm hơn Primary bao nhiêu giây
- Slow queries: Query nào chạy > 100ms
db.serverStatus().connections // Xem connections
rs.printSecondaryReplicationInfo() // Xem replication lag
db.currentOp({ "secs_running": { $gt: 5 } }) // Query đang chạy > 5s
7. Xử Lý Sự Cố Thường Gặp
| Vấn đề | Nguyên nhân | Giải pháp |
|---|---|---|
| Query chậm | Thiếu index | Tạo index phù hợp |
| RAM đầy | Cache quá lớn | Giảm cacheSizeGB |
| Replication lag | Secondary yếu hoặc write quá nhiều | Nâng cấp hardware hoặc giảm write |
| Hết connections | Pool quá nhỏ | Tăng maxPoolSize |
VII. Chi Phí và Lựa Chọn
💰 Chi phí ước tính (AWS/tháng):
| Deployment | Chi phí | Khi nào dùng |
|---|---|---|
| Standalone (Dev) | ~$15 | Học tập, test |
| Replica Set (3 nodes) | ~$90-350 | Production chuẩn - Dùng cho 90% trường hợp |
| Sharded Cluster | ~$900+ | Data > 2TB hoặc write cực cao |
| MongoDB Atlas M10 | ~$60 | Startup, không muốn quản lý server |
💡 Tiết kiệm chi phí:
- Dùng Reserved Instances: Giảm 30-50%
- Nén data, xóa index không dùng
- Archive data cũ lên S3
VII. So Sánh MongoDB vs MySQL - Connection Management
Điểm Khác Biệt Quan Trọng
| Tính Năng | MySQL | MongoDB |
|---|---|---|
| Replica Set / Group Replication | ❌ Application phải tự update connection đến Primary mới | ✅ Driver tự động handle, connection string không đổi |
| Router | Cần InnoDB Cluster + MySQL Router để transparent | Replica Set đã transparent nhờ Driver |
| Sharding + Router | InnoDB Cluster + Router | Sharded Cluster + mongos |
| Transparent Connection | Chỉ có khi dùng Router | Có sẵn từ Replica Set |
💡 Kết Luận:
- MongoDB driver thông minh hơn: Tự động handle failover ngay từ Replica Set
- MySQL cần Router: Để có transparent connection, phải dùng InnoDB Cluster + MySQL Router
- Cả 2 đều có Router cho Sharding: mongos (MongoDB) = MySQL Router (MySQL)
VIII. Tổng Kết
5 Điều Quan Trọng Nhất
1. MongoDB khác MySQL
- Linh hoạt schema, không cần chuẩn hóa nghiêm ngặt
- Nhúng data vào nhau (embed) thay vì tách bảng
2. Bắt đầu đơn giản, scale sau
- Dev: Standalone
- Production: Replica Set (đủ cho 90% app)
- Chỉ dùng Sharding khi thực sự cần
3. Shard Key không thể đổi
- Chọn sai = phải migrate lại toàn bộ data
- Chọn dựa trên cách app query nhiều nhất
4. Index là chìa khóa tăng tốc
- Không có index = query chậm
- Thứ tự quan trọng: Bằng (=) trước, khoảng (lớn hơn, nhỏ hơn) sau
5. Replica Set là lựa chọn an toàn
- Có High Availability (tự động failover)
- Tăng được hiệu năng đọc
- Đủ cho hầu hết ứng dụng
Chọn Loại Nào?
📝 Hỏi bản thân 3 câu:
-
Data có > 2TB không?
- Không → Replica Set
- Có → Sharded Cluster
-
Có cần High Availability không?
- Không (dev/test) → Standalone
- Có (production) → Replica Set trở lên
-
Team có kinh nghiệm quản MongoDB không?
- Không → MongoDB Atlas (managed)
- Có → Self-hosted
Khuyến Nghị Theo Quy Mô
🚀 Startup: Replica Set 3 nodes (hoặc Atlas M10)
🏢 Công ty vừa: Replica Set + Monitoring tốt
🏦 Enterprise: Sharded Cluster nếu cần, hoặc Atlas M40+
Kết Luận
MongoDB có 3 cấp độ:
- Standalone: Học tập, dev
- Replica Set: ⭐ Dùng cho production - An toàn, đủ mạnh
- Sharded Cluster: Data khổng lồ, cần scale cực mạnh
💡 Lời khuyên cuối: Bắt đầu đơn giản, theo dõi performance, chỉ scale khi thực sự cần. 90% ứng dụng chỉ cần Replica Set là đủ!
Chúc các bạn xây dựng hệ thống MongoDB thành công! 🍃
Về Tác Giả:
Xem thêm bài viết của tôi tại: codeeasy.blog
All rights reserved
