Các model của Trung Quốc liệu rằng có đang Fake chỉ số benchmark và SWE-ReBench là gì ?
1. Sự thật mất lòng về các LLM Leaderboard
Vào hôm qua - 14/02/2026 mình có đọc được một chia sẻ từ David Ondrej (CEO của AgentZero) đã gây chú ý khi chỉ ra một thực trạng trớ trêu: Các mô hình LLM đến Trung Quốc như Qwen3-Coder-Next, Kimi K2.5, ....đang ngày càng cho chỉ số benchmark cao nhưng lại cho kết quả kém thực tế. Khi các bộ dữ liệu benchmark (như SWE-bench) trở nên quá phổ biến và công khai, đến mức các lab — đặc biệt là các lab Trung Quốc — đã thiết kế dữ liệu huấn luyện để overfit các task trong những bài toán đến từ SWE-bench benchmark. Các lab đến từ Trung Quốc họ không cố gắng để xây dựng mô hình tốt hơn mà là đang cố đạt điểm cao hơn trên đúng các bài test benchmark này. Kết quả là các mô hình AI không phải đang "giải quyết vấn đề", mà là đang "nhớ lại lời giải". David nhấn mạnh rằng nếu cứ tiếp tục dùng những thước đo cũ, chúng ta sẽ xây dựng những AI Agent chỉ giỏi học vẹt thay vì có tư duy lập trình thực thụ và anh ấy đề xuất SWE-ReBench (độ khó thì vẫn tương tự SWE-bench) như một giải pháp thay thế đáng tin cậy hơn và kết quả thật bất ngờ
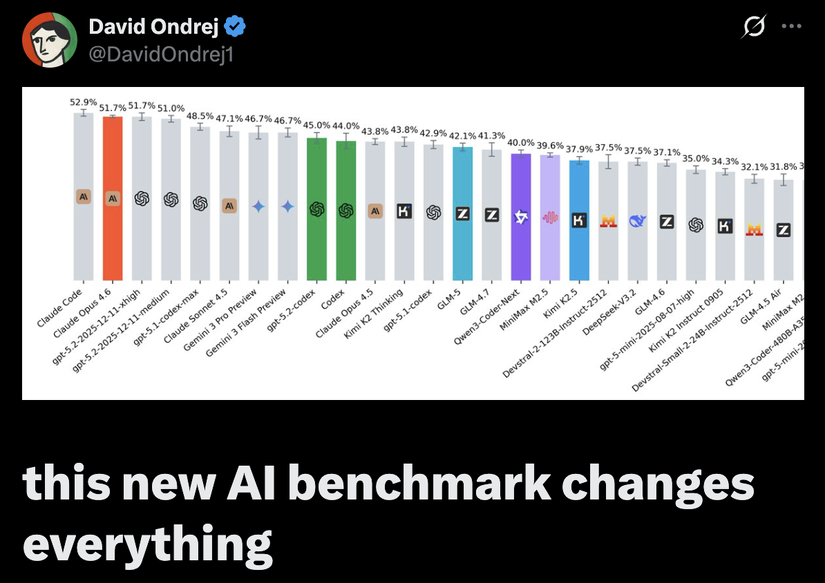
Các mô hình mà Trung Quốc đang gáy là vượt cả các mô hình đến từ Claude Opus hay GPT thì đều gãy hết khi sử dụng độ đo SWE-ReBench. Nhìn vào thì có thể thấy thậm chí model đang cho kết quả tốt nhất trên SWE-ReBench lại là Kimi K2 Thinking chứ không phải Kimi K2.5 cơ 🤣 và chỉ đang đạt 43.8% so với 52.9% của Claude Code. Hàng loạt các model mới nhất của Trung Quốc như là GLM-5, MiniMax M2.5, Qwen3-Coder-Next hay Kimi K2.5 đều mới ra gần đây và đều bảo là ngang cơ so với model đến của Anthropic rồi là Vượt GPT-4o thì bây giờ khi đo bằng SWE-ReBench thì các model đến từ Trung Quốc đều cho các score kém hơn 10% so với Claude Code. Kiểu này chắc các pháp sư Trung Hoa chỉ còn lấy giá rẻ là đem đi khè được thôi chứ score kiểu này gẫy quá 🙃. Sau khi có bảng benchmark mới này thì David Ondrej có nói là " Trung Quốc từ trước đến nay luôn giỏi sao chép công nghệ. Không phải phát minh, mà là sao chép. Họ làm điều đó với smartphone. Mạng xã hội. Xe điện. Và giờ là AI" - nghe câu này xong chắc các pháp sư Trung Hoa cay hơn ăn ớt 😂

2. SWE-ReBench là gì?
Paper “SWE-rebench: An Automated Pipeline for Task Collection and Decontaminated Evaluation of Software Engineering Agents” (arXiv 2505.20411) được team Nebius giới thiệu và vấn đề mà paper giải quyết đó là:
- Contamination: SWE-bench ra mắt năm 2023, giờ đã bị rò rỉ khắp nơi trên internet → model mới train trên data đó sẽ “biết trước đáp án”.
- Scaffolding không chuẩn: Mỗi team dùng prompt, framework, evaluation khác nhau → so sánh không công bằng.
- Stochasticity: Model chạy nhiều lần cho kết quả khác nhau, nhưng người ta hay report “best run” → làm đẹp điểm số.
- Dữ liệu ít + không interactive: Khó train agent bằng RL (Reinforcement Learning) vì thiếu task thực tế có thể verify tự động.
Vậy SWE-ReBench giải quyết các vấn đề trên như thế nào? Họ xây dựng một pipeline hoàn toàn tự động để khai thác dữ liệu trên GitHub liên tục:
-
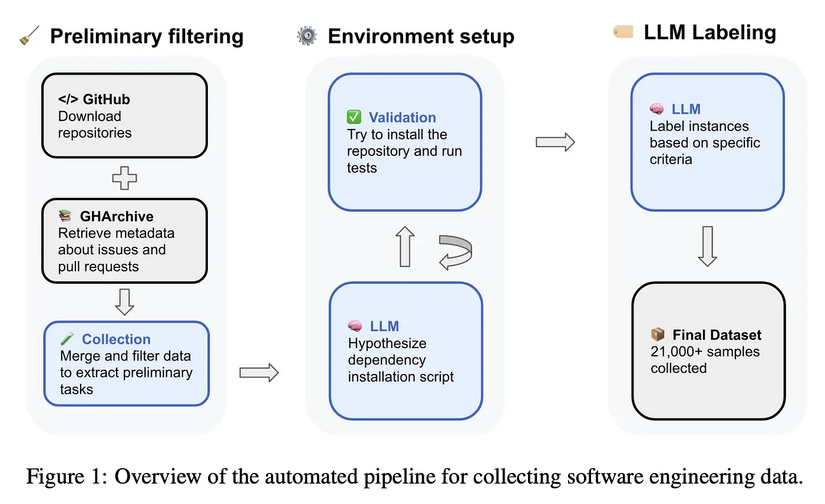
Thu thập task: Quét > 450k Pull Request từ 30.000+ repo Python (license permissive). Chỉ giữ những issue được giải quyết bởi PR sửa 1–15 file, có test thay đổi, và mô tả rõ ràng → còn lại 21.336 task chất lượng cao.
-
Cấu hình môi trường tự động: Dùng LLM (Qwen2.5-72B) đọc README, setup.py, requirements… để sinh lệnh install. Sau đó chạy thử trong Docker, fix lỗi tự động. Kết quả: 31% repo được cấu hình thành công.
-
Verify task: Phải thỏa mãn 3 điều kiện nghiêm ngặt:
- Trước patch: ít nhất 1 test fail
- Sau patch: tất cả test fail trước giờ pass
- Test pass ban đầu vẫn pass
-
Đánh giá chất lượng: Dùng model fine-tune trên SWE-bench Verified để chấm điểm clarity (rõ ràng), complexity (độ khó), test correctness. Và bạn có thể filter task theo các tiêu chí này.
-
Decontamination triệt để: Task lấy từ GitHub sau cutoff của model (Ví dụ nếu model như GPT-4o có cutoff khoảng 2024, thì bất kỳ task nào tạo sau ngày đó đều "an toàn" vì model chưa từng thấy), leaderboard đánh dấu đỏ task có nguy cơ leak ( Ví dụ: Nếu một task từ tháng 10/2025, nhưng model release tháng 12/2025 → task đó được highlight đỏ → cảnh báo "có nguy cơ contaminated"), update hàng tháng.
2.1 Verify task là gì ?
Vì phần veriry task này hơi khó hiểu với một số người nên mình sẽ nói kĩ ở phần này ae nào rõ rồi có thể skip nhé :
Giả sử có một bug trong code → dev fix bằng cách commit patch (thay đổi code) → và họ cũng thêm/sửa test để chứng minh bug đã hết. Benchmark muốn task phải thật sự là fix bug, chứ không phải thay đổi linh tinh hay test kém chất lượng. Nên họ kiểm tra trước và sau khi áp dụng patch (gold patch từ PR thật trên GitHub):
- Trước patch (trên code buggy gốc): Phải có ít nhất 1 test fail (thường là test mới thêm/sửa để phát hiện bug). → Nghĩa là: "Bug này thật, test chứng minh được bug tồn tại". Nếu tất cả test đều pass từ đầu → thì chẳng có bug gì để fix, task vô nghĩa.
- Sau patch (áp dụng fix): Tất cả test mà trước đó fail → giờ phải pass hết. → Nghĩa là: "Fix đã sửa đúng bug, làm cho các test fail trước đây giờ pass". Đây là Fail-to-Pass (F2P) – tiêu chuẩn vàng để xác nhận fix thành công.
- Test pass ban đầu vẫn pass (sau patch): → Nghĩa là: "Fix không làm hỏng những phần code khác". Không được có test nào trước pass → sau lại fail (gọi là Pass-to-Fail regression). Đây là kiểm tra không gây side-effect, fix phải sạch sẽ.
2. Vậy SWE-rebench có gì khác biệt?
-
Tự động hóa hoàn toàn (Automated Pipeline): Thay vì dựa vào một tập dữ liệu tĩnh, SWE-rebench thiết lập một quy trình tự động thu thập các Task từ GitHub. Nó quét qua hàng trăm nghìn Pull Requests để tìm ra những vấn đề thực tế, có lời giải và quan trọng nhất là có các bài kiểm tra (test cases) đi kèm.
-
Chống "Decontamination": Đây là điểm mấu chốt. Hệ thống này liên tục cập nhật các tác vụ mới nhất. Bằng cách so sánh ngày phát hành của mô hình với ngày xuất hiện của lỗi trên GitHub, SWE-rebench đảm bảo rằng mô hình AI chưa bao giờ nhìn thấy lỗi đó trong quá trình huấn luyện.
-
Quy mô lớn: Với hơn 21.000 tác vụ được lọc từ 30.000 kho mã nguồn Python, đây là một bước nhảy vọt so với các phiên bản trước đó.
3. Tóm lại
Nếu bạn nào dùng Claude Opus rồi chuyển sang MiniMax, GLM hay Qwen3-Coder-Next, bạn sẽ nhận ra sự khác biệt ngay lập tức. Ngay cả khi benchmark cũ nói chúng tương đương, trong thực tế các mô hình này chưa bao giờ cho kết quả tương đương như vậy. Với SWE-rebench có thể kết luận rằng Claude Code đang đứng số 1 trên SWE-rebench với 52.9%, Pass@5 đạt 70.8% ( Pass@5 là Xác suất mà trong 5 lần thử độc lập (independent generations), ít nhất một lần agent tạo ra giải pháp đúng (pass hết các test)) và Claude Code đang là AI coding tốt nhất thế giới hiện tại. Ngoài ra mình còn thấy một cái khá là hay nữa là khi so SWE-rebench benchmark giữa Codex và Claude Code
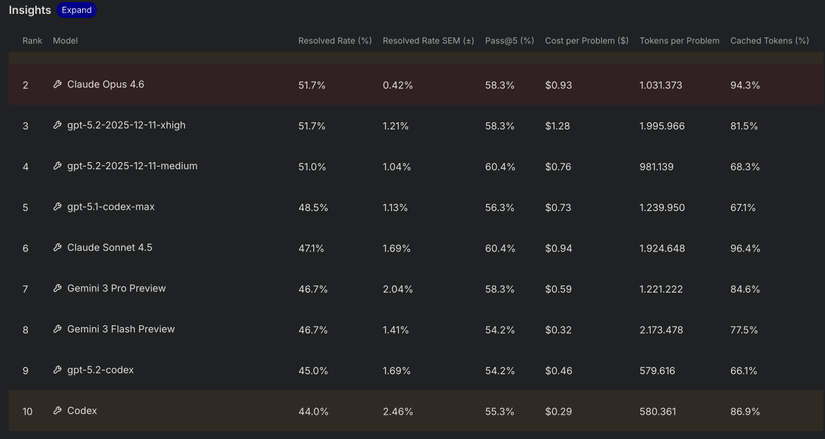
Khi Codex mới ra thì rất nhiều anh em nghĩ rằng Codex đang ngon hơn Claude Code nhưng khi nhìn vào SWE-rebench benchmark thì có thể thấy Codex vẫn không bằng được Claude Code mà chỉ cho giá rẻ hơn thôi. Claude Code cho score 52.9% và rank 1 còn Codex cho score 44% và rank 10 lệch nhau tận ~9% tuy nhiên khi so Cost per Problem thì Claude code đang ngốn tận 3.5$ cho một task còn Codex thì chỉ 0.29$ trên một task. Claude Code đúng là đắt vãi kinh anh em ạ, đắt hơn tận 12 lần so với Codex 🥲. Ngoài lề thế thôi tóm lại là:
- Đừng tin mù quáng leaderboard cũ (SWE-Bench Verified giờ đã "cũ" và contaminated).
- Các công ty/lab muốn "tỏ ra vượt trội" thường chạy đua chỉ số trên benchmark leak → marketing hiệu quả nhưng không phản ánh thực tế.
- Model thực sự tốt là model giữ phong độ trên task mới, chưa từng thấy trước.
4. Tham khảo
- Thread X: https://x.com/DavidOndrej1/status/2022597312024056285
- Paper review: https://artgor.medium.com/paper-review-swe-rebench-an-automated-pipeline-for-task-collection-and-decontaminated-evaluation-8741b3ebd712
- Leaderboard: https://swe-rebench.com/
- Paper arXiv: 2505.20411
All rights reserved
