Các ideas để có thể sử dụng một cách tối ưu Treasure data
Bài đăng này đã không được cập nhật trong 7 năm
Treasure data là gì ?
Là service quản lý data theo dạng cloud dành cho mục đích thống kê, phân tích. Treasure data có đặc điểm là có thể thống kê, phân tích, liên kết data một cách đơn giản từ rất nhiều nguồn data khác nhau, chẳng hạn như data đa cấu trúc, hoặc data không cấu trúc của web, mobile application, sensor .... Treasure data cung cấp nền tảng để có thể thống kê, phân tích data số lượng lớn ngay lập tực, và liên kết tới system bên ngoài một cách đơn giản. Treasure data có một số điểm đặc trưng như : là kiểu database hướng cột, query tham chiếu có 2 loại là Hive và Presto .... Về chi tiết thì tham khảo ở page chính thức bên dưới :
https://support.treasuredata.com/hc/en-us
Dưới đây là một số point cần phải biết khi develop liên quan tới service Treasure data để đạt được kết quả tối ưu nhất.
Time column là keypoint để tối ưu hóa tốc độ !
Với database hướng cột (column-oriented) thì không có khái niệm Index, về cơ bản là sẽ scan tất cả record. Tuy nhiên, vì lí do database hướng cột của Treasure data đang phân chia table tới nhiều server khác nhau theo từng mốc thời gian, nên nếu có thể sử dụng đặc trưng đó một cách khôn ngoan thì hoàn toàn có thể tối ưu hóa tốc độ một cách đơn giản.
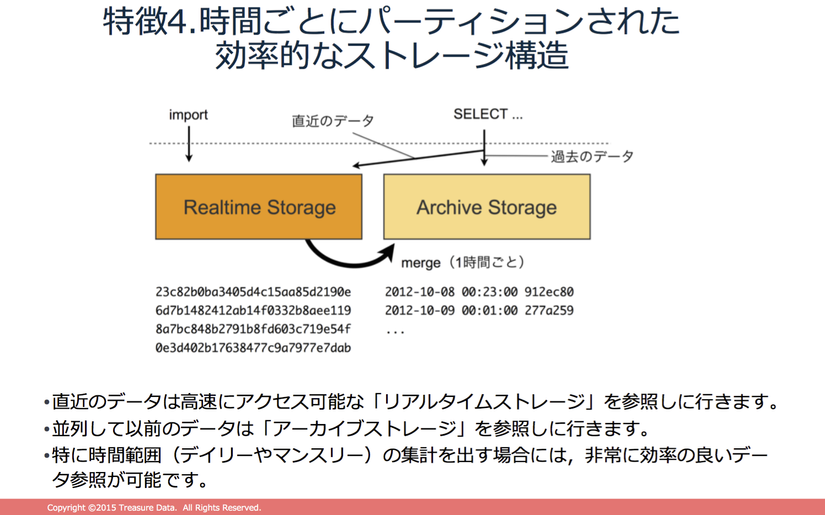
↑ ở database hướng cột của Treasure data, các data gần nhất mà được sử dụng thường xuyên thì sẽ được lưu ở 「Realtime Storage」, nên có thể tham chiếu tới rất nhanh. Sau đó, data của 「Realtime Storage」 sẽ được di chuyển sang 「Archive Storage」. Lúc này thì sẽ partitioning data theo đơn vị từng giờ một.
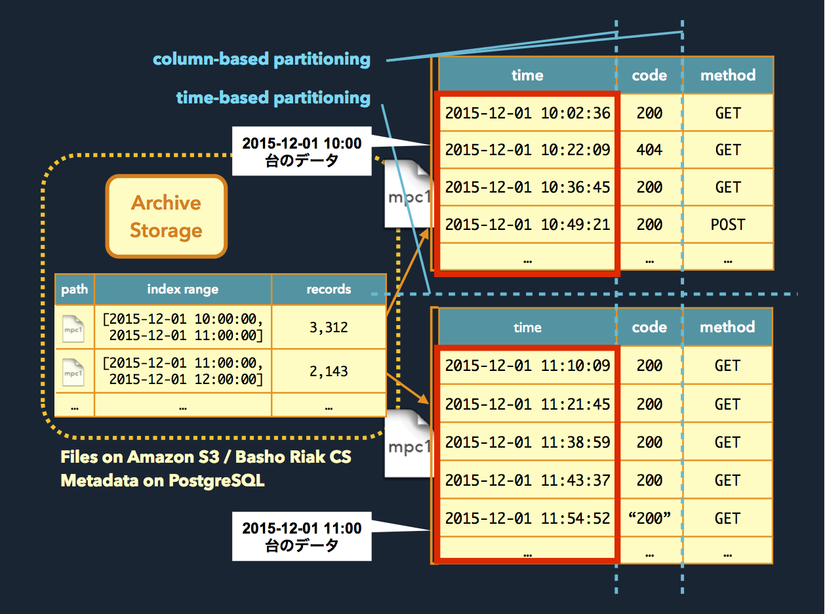
↑ đối với data đã được partitioning và lưu theo đơn vị từng giờ một, bằng cách đưa điều kiện column time vào bên trong SQL, thì sẽ có thể triệt bỏ các access tới các partition không cần thiết một cách vô ích.
Treasure data là kiểu ghi vào - bổ sung thêm !
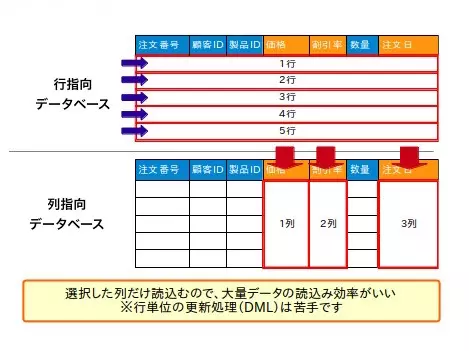
Bên trong database hướng cột thì vì lí do query chạy theo tính hướng cột, do đó sẽ rất hạn chế trong việc hỗ trợ thay đổi (UPDATE) tất cả column của một row chỉ định. Việc UPDATE một record hiện có thì về cơ bản sẽ add thêm record mới, rồi sẽ luôn đọc record mới nhất để tránh bị duplicate data. Xử lý DELETE cũng tương tự như vậy. Database kiểu này rất yếu trong việc tìm một record được chỉ định rồi xóa. Do đó, cơ bản của Treasure data là sẽ tiến hành với phương châm 「No DELETE,No UPDATE」.
Có thể thực hiện query search với Presto. Cần chú ý để thực hiện các xử lý đồng thời !
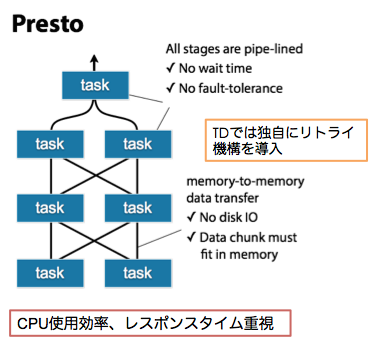
Với query Presto đối ứng cho xử lý ad-hoc thì có thể search tốc độ cao record mà có giá trị column chỉ định. Tuy nhiên, so sánh với các engine search thông thường thì không phù hợp với kiểu match bộ phận (Regular expression) giá trị column kiểu string. Ngoài ra, với Presto thì không có nhiều số lượng thực hiện đồng thời, nên hãy hạn chế việc gửi nhiều query search đồng thời.
Lọc column sử dụng thì sẽ tối ưu hóa tốc độ !
Với database hướng cột thì chỉ đọc các column sử dụng, do đó trong trường hợp muốn thống kê data một cách nhanh chóng thì không nên tham lam quá, mà chỉ lọc số lượng các column sử dụng ở mức tối thiểu thôi.
Trước tiên làm cho chạy được, việc nâng performance thì sẽ là sau đó đã !
Các query với mục đích phân tích thì về cơ bản là sự lặp đi lặp lại của try & error. Không thể viết một query mà ngay từ đầu không có error được. Hoặc có hoạt động đi nữa thì cũng là query có hiệu quả không tốt, hoặc bị dài dòng rườm rà thì đó cũng là đương nhiên. Do đó, ở ban đầu thì không nên nhắm đến một đích hoàn hảo. Trước tiên thì chưa cần quan tâm về performance, mà hãy cứ viết query và chạy cho được đã.
Sử dụng nhuần nhuyễn các UDF treasure data !
Bên trong Treasure data thì tuy không có đầy dủ trong SQL của Hive, Presto, nhưng những xử lý quan trọng, có tần suất sử dụng cao thì có chuẫn bị sẵn nhiều các Treasure data UDF (User Defined Function). Đặc biệt, các function để có thể sử dụng hiệu quả Index Time đã được nhắc ở trên thì có rất nhiều. Khi tìm hiểu các function liên quan tới date/time, thì trước khi xem reference của SQL hãy tìm hiểu về Treasure data UDF trước đã nhé.

All rights reserved
