Các bước để khắc phục vấn đề Encoding trong Ruby
Bài đăng này đã không được cập nhật trong 4 năm
Gần đây khi là dự án với khách hàng Nhật tôi gặp chút rắc rối trong việc encoding các chuỗi ký tự khác nhau, để cho dễ hình dung thì tôi xin đưa ra 1 đoạn exception mình nhận được khi format vài ký tự sang SHIFT-JIS từ UTF-8
irb(main):005:0> x = "㈱"
irb(main):007:0> x.encode "SHIFT_JIS", "UTF-8"
Encoding::UndefinedConversionError: U+3231 from UTF-8 to Shift_JIS
Và bạn sẽ làm gì để tìm ra nguyên nhân bị lỗi như vậy và làm thế nào để khắc phục chúng Bài viết này sẽ làm rõ 1 vài khái niệm cơ bản về Encoding, và những vấn đề gặp phải khi Encoding hay Charset, từ đó để các bạn có phương án giải quyết phù hợp.
1. Bảng mã kí tự là gì?
Bảng mã kí tự (char code table) là một bảng dùng để đánh chỉ số cho một tâp kí tự (char) ,sao cho mỗi kí tự được ánh xạ từ số duy nhất (code).
Giá trị của code luôn được đánh số liên tiếp tăng. Điều này sẽ tạo thứ tự cho từng kí tự trong tập kí tự ở trên.
Quen thuộc nhất mà chúng ta, ai cũng biết hoặc từng nghe tên là bảng mã ASCII
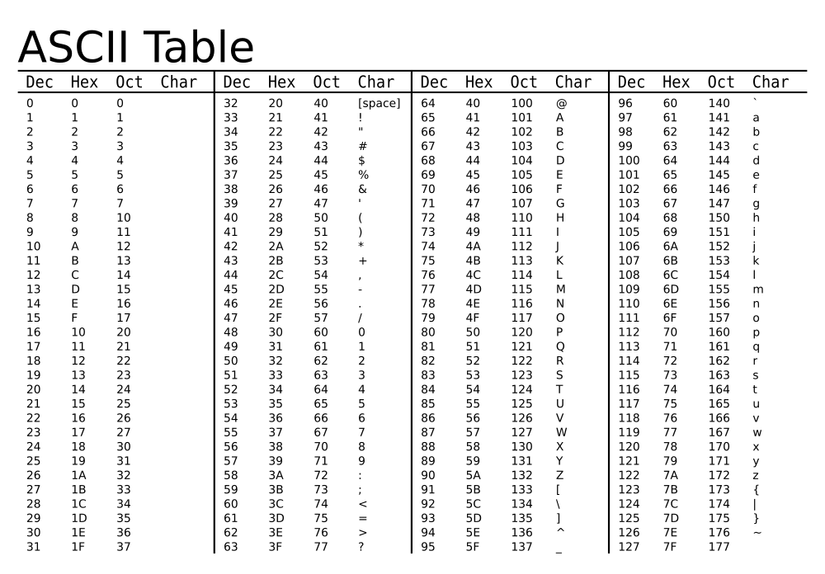
2. Encoding (Mã hóa) là gì?
Các khái niệm Encoding thường tương đối khó hiểu Để cho đơn giản nhất thì hãy hiểu String như 1 mảng các bytes hoặc đơn giản hơn nữa là mảng các số nhỏ, ví dụ:
irb(main):001:0> "hello!".bytes
=> [104, 101, 108, 108, 111, 33]
Nhìn vào đoạn encoding trên thì 104 tương ứng với h, 33 tương ứng là ! và các ký tự khác cũng tương tự Mảng các số này sẽ tăng dần độ phức tạp khi các ký tự của chuỗi ít phổ biến hơn, ví dụ
irb(main):002:0> "hellṏ!".bytes
=> [104, 101, 108, 108, 225, 185, 143, 33]
Nào nhìn vào đây thì thật khó để nói số nào đang đại diện cho ký tự nào. Thay vì 1 byte (hay đơn giản là 1 số) thì ṏ được đại diện bằng 1 nhóm các byte [255, 183, 143]. Từ đây chúng ta, có thể thấy 1 mỗi quan hệ giữa các bytes và các ký tự. Hay nói cách khác là việc encoding (mã hóa) 1 chuỗi sẽ xác định mối quan hệ đó.
Hãy xem những mảng tập hợp các bytes sẽ trông khác nhau như thế nào khi các bạn thử mã hóa khác nhau
Try an ISO-8859-1 string with a special character!
irb(main):003:0> str = "hellÔ!".encode("ISO-8859-1"); str.encode("UTF-8")
=> "hellÔ!"
irb(main):004:0> str.bytes
=> [104, 101, 108, 108, 212, 33]
What would that string look like interpreted as ISO-8859-5 instead?
irb(main):005:0> str.force_encoding("ISO-8859-5"); str.encode("UTF-8")
=> "hellд!"
irb(main):006:0> str.bytes
=> [104, 101, 108, 108, 212, 33]
Nhìn qua, thì ta thấy các bytes không thay đổi. Điều đó trông có vẻ không đúng. nhưng nhìn xuống dưới ta thấy các ký tự được in ra là khác nhau Vậy có thể hiểu là việc thay đổi mã hóa (encoding) sẽ chỉ thay đổi cách in ra của chuỗi đó mà không thay đổi các byte. Điều này cũng có nghĩa là không phải tất cả các String (chuỗi) đều có thể được đại diện bởi "1 kiểu in ra nào đó" trong tất cả các mã hóa,
irb(main):006:0> "hi∑".encode("Windows-1252")
Encoding::UndefinedConversionError: U+2211 to WINDOWS-1252 in conversion from UTF-8 to WINDOWS-1252
from (irb):61:in `encode'
from (irb):61
from /usr/local/bin/irb:11:in `<main>'
Nhìn ví dụ trên có thể thấy, kí tự ∑ đang không được định nghĩa với kiểu encoding Windows-1252
Như vậy, hầu hết các kiểu mã hóa nhỏ sẽ không thể xử lý được mọi ký tự có thể. Và bạn sẽ nhìn thấy lỗi xảy ra tương tự như bên trên khi 1 kí tự trong 1 mã hóa không tồn tại kiểu khác hoặc khi Ruby không thể tìm ra cách dịch qua lại của 1 ký tự giữa 2 kiểu mã hóa
Nếu bạn chấp nhận lỗi này và không đòi hỏi nhiều hơn ở mã hóa đang sử dụng phải có 1 ký tự thay thế cụ thể thì thật may hàm encode mặc định của Ruby có thêm Option để thay vì bắn ra 1 exception tương tự như ví dụ ta thấy ở trên
Các bước khắc phục lỗi khi encoding
- Tìm xem chuỗi đó đang thực sự được mã hóa kiểu gì? Điều này nghe qua thì có vẻ đơn giản. Nhưng nhìn vào ví dụ dưới đây bạn sẽ phải suy nghĩ lại
irb(main):078:0> "hi\x99!".encoding
=> #<Encoding:UTF-8>
Chuỗi phía trên encoding là UTF-8, điều đó là không đúng, nếu thực sự là UTF-8 nó sẽ không có "\x99" trong đó. Vì vậy, làm thế nào để bạn tìm ra mã hóa chính xác của chuỗi đó
Rất nhiều phần mềm cũ sẽ được gắn kèm với 1 mã hóa mặc định duy nhất, vì vậy bạn có thể bắt đầu tìm hiểu từ đây. Bạn đã từng copy 1 đoạn string từ file Word. Nó có thể là Windows=125. Hay 1 đoạn String được lấy từ 1 file hoặc 1 website cũ, nó có thể là ISO-8859-1
Vậy cách nào để biết chính xác String đang được mã hóa kiểu gì, rất tiếc Ruby không có 1 hàm cụ thể nào cho bạn biết chính xác kiểu Unicode đang được dùng. Tạm thời, mình nghĩ chúng ta chỉ có thể tìm kiếm hoặc tham khảo những trang như kiểu Wikipedia, Stack Over Flow để tìm ra các bảng ký tự. Từ bảng này mình có thể tìm kiếm các ký tự được tham chiếu bởi 1 con số xác định và đặt chúng vào trong từng trường hợp cụ thể.
Nhìn vào ví dụ trên, ở bảng của kiểu encoding Window-1252 thì ta thấy byte 99 là đại diện cho ký tự "™". Nhưng byte 99 lại không tồn tại dưới kiểu ISO-8859-1. Nếu để "™" có ý nghĩa trong trường hợp này, bạn có thể giả sử đầu vào đó được sử dụng với Windows-1252 và tiếp tục. Nếu không, bạn có thể tiếp tục tìm kiếm cho đến khi tìm 1 được ký tự thay thế có vẻ hợp lý hơn
-
Quyết định sử dụng mã hóa nào cho chuỗi. Điều này thì tương đối dễ dàng. Trừ khi bạn có 1 lý do nào đó đặc biệt, hoặc nghiệp vụ bài toán yêu cầu tham số phải encoding như thế này như thế nọ, còn không bạn có thể sử dụng kiểu encoding chuỗi là "UTF-8". Có vài kiểu mã hóa phổ biến khác mà bạn có thể sử dụng trong Ruby như: ASCII-8BIT. Trong ASCII-8BIT, mỗi ký tự được biểu diễn bởi 1 byte đơn.
str.chars.length == str.bytes.lengthVì vậy, nếu bạn muốn kiểm soát nhiều byte cụ thể trong chuỗi của bạn thì ASCC-8BIT có thể sẽ là 1 lựa chọn tốt -
Hãy mã hóa lại chuỗi của bạn từ kiểu này sang kiểu khác Bạn có thể làm như vậy với phương thức
encode. Nhìn vào ví dụ ngay phía trên, chuỗi đó như đã nói, được xuất hiện trong mã hóaWindow-1252và bây giờ tôi muốn nó trở thành "UTF-8". Điều này khá đơn giản
irb(main):088:0> "hi\x99!".encode("UTF-8", "Windows-1252")
=> "hi™!"
Bonus
Quay về bài toán đầu bài mình chia sẻ, vì bên khách hàng Nhật sử dụng kiểu encode "SHIFT-JIS", nên mình phải loay hoay tìm cách encode từ UTF8 sang, và với cách mò mẫm các bảng ký tự (thực ra, mình mò mẫm mãi không ra, nhưng có 1 anh ở công ty suggest đó =)) )
Mình dùng kiểu encode CP932, còn CP932 là gì các bạn tự tim hiểu nha thì ok
irb(main):005:0> x = "㈱"
irb(main):008:0> x.encode "CP932", "UTF-8"
=> "\x{878A}"
Với kiểu encoding CP932thì có vẻ ok đó, tuy nhiên cũng chưa bắt hết case, và không may input vào không tìm được ký tự thay thế, nên để cho chắc chắn mình sẽ replace nếu bị invalid
encode "cp932", "utf-8", undef: :replace
Tài liệu tham khảo
https://ruby-doc.org/core-2.2.0/Encoding.html http://www.justinweiss.com/articles/3-steps-to-fix-encoding-problems-in-ruby/
All rights reserved
