ByteTrack: Multi-object detector hiện đại nhất hiện nay 🐱👓
This post hasn't been updated for 3 years
1. Giới thiệu
Chào mọi người, đây là bài viết đầu tiên trong quá trình tìm hiểu về bài toán multi-object tracking (MOT) của mình. Nói qua một chút thì mình cũng mới tìm hiểu về mảng này cho nên cũng còn khá nhiều kiến thức còn thiếu sót 😅, vậy nên mình sẽ cố gắng giải thích thuật toán này một cách thật rõ ràng và dễ hiểu nhất.
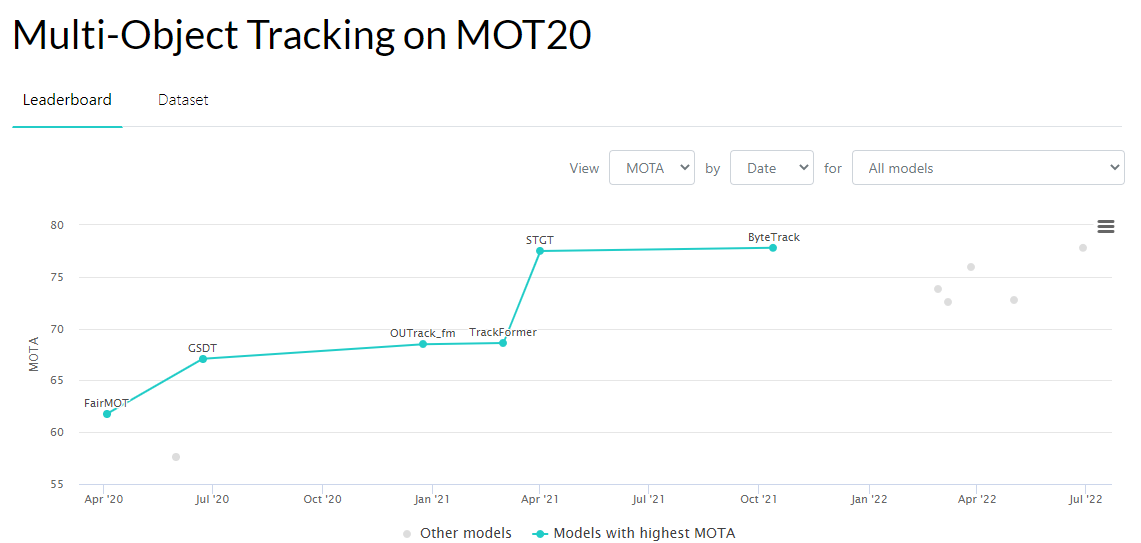
ByteTrack được ra đời vào tháng 11 năm 2021 và hiện tại vẫn đang là SOTA theo thang đánh giá về MOTA trên Papers With Code (các bạn có thể tìm và theo dõi thêm một vài thuật toán khác về MOT ở đây). Nhưng trước khi giải thích về ByteTrack , mình sẽ giải thích sơ qua về ý tưởng chính của Simple Online and Realtime Tracking (SORT) - một thuật toán về tracking trực quan và đơn giản nhất, từ đó xem sự cải tiến của ByteTrack so với các trình tracking cũ như thế nào.
Давай поехали!!!
2. Simple Online and Realtime Tracking (SORT) là như thế nào?
Nếu ai đã từng đọc qua về SORT paper, bạn sẽ thấy tác giả nói về Kalman Filter và Hungarian algorithm, nhưng chi tiết về 2 thuật toán này mình sẽ không bàn luận ở đây vì nó khá dài và hay nên mình sẽ để dành trong một bài post khác.

Đầu tiên, ta cần có bước khởi tạo để xác định những đối tượng cần được theo dõi.
Giả sử ta muốn bắt đầu tracking từ frame có được tại thời gian t1 (hình ở trên). Đầu tiên sẽ đưa frame đó vào mô hình Detection để có thể detect các đối tượng có trong frame đó, thu được các bounding boxes (bboxes) và các Confidence score (các số trên bboxes màu vàng trong hình). Từ đó loại bỏ các bboxes mà có Confidence score thấp (bé hơn 0.5). Chúng ta hãy cứ coi như Confidence score là xác suất đối tượng detec được là con người. Từ đó có thể thu được:

Sau đó ta sẽ gán ID cho các bboxes còn lại. Trong quá trình khởi tạo này, ta có thể gán bất kỳ giá trị nào cho các bboxes. Ở đây mình sẽ để là: [0], [1], [2] (3 đối tượng).

Ở đây mình sẽ gán cho 3 bboxes trong hình 3 IDs: 1, 2, 3. Sau đó mình sẽ tạo một mảng để lưu các đối tượng được tracking như sau: [(ID0, bounding box0), (ID1, bounding box1), (ID2, bounding box2)].

Tại frame t2, detector sẽ phát hiện được ra các đối tượng trong bboxes như ở trên. Nhưng 🤨...! Như các bạn có thể thấy, bbox thứ 2 được phát hiện với Confidence score khá thấp (0.4), và nó không chắc chắn đây có phải một con người hay không vì thông tin hình ảnh của nó đã bị mất khi bị che khuất bởi người đằng trước. Và vì Confidence score bé hơn 0.5, nên bbox này sẽ bị loại bỏ.

Sau khi loại bỏ các bboxes dựa vào Confidence score, ta thu được 2 bboxes còn lại. Bây giờ chúng ta cần thực hiện match 3 ID0, ID1, ID2 bboxes mà được bắt đầu tracking từ frame t1 và 2 bboxes phát hiện được tại frame t2. Quá trình matching sẽ tính tất cả IoU (Intersection over Union) giữa ID0, ID1, ID2 bboxes và các bboxes ở frame t2 tạo thành một ma trận 3x2 (3 bboxes ở frame t1, 2 bboxes ở frame t2), ứng với mỗi cột ta sẽ lựa chọn ra IoU cao nhất. Điều này được thực hiện với giả định rằng, các đối tượng được phát hiện trong frame trước đó sẽ ở gần vị trí mà chúng ta đang tracking trong frame hiện tại,trừ khi người ấy di chuyển với vận tốc ánh sáng 🙄
Thực ra, trong bước này, Kalman Filter được áp dụng để dự đoán vị trí của đối được được theo dõi trong quá trình matching, và chúng ta sẽ tính được IoU giữa bboxes thu được bởi Kalman Filter (predicted boxes) và bboxes thu được bởi detector (detected boxes). Nhưng ở đây mình sẽ không nói kỹ về vấn đề này 😝
Tại thời điểm này, số đối tượng đang được theo dõi là 3 (ID0, ID1, ID2), và số lượng đối tượng được phát hiện trong frame hiện tại (t2) là 2. Ở đây, chúng ta cần phải tối đa hóa số lượng đối tượng cần được tracking, vì thế cần phải match toàn bộ 2 bboxes ở frame t2 vào các đối tượng ở frame trước đó. Điều này là bởi vì, nếu IoU giữa 2 đối tượng giống nhau quá thấp, thuật toán sẽ coi đây là 2 đối tượng khác nhau và gán cho nó ID mới, làm giảm độ chính xác của thuật toán. Vì thế, trong quá trình này, Hungarian Algorithm đã được sử dụng (mình cũng sẽ không bàn kỹ trong bài này).

Sau khi kết thúc quá trình matching, ta cần cập nhật lại các giá trị trong mảng tracking. Kalman Filter cũng được sử dụng tại bước này 😅
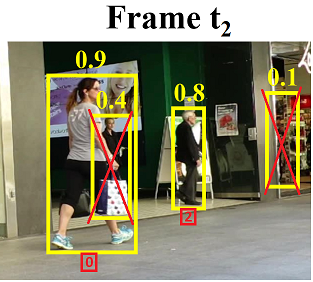
Thuật toán này sẽ fail khi track người thứ 2 từ bên trái qua (người có ID1 ở frame t1) tại frame t2 vì Confidence score của đối tượng này thấp (bé hơn threshold: 0.5). Vậy nếu ta giảm ngưỡng của Confidence score xuống thì sao nhỉ? 🤔🤔🤔

Bùm! Kết quả như các bạn cũng đã thấy ở trên. Bằng cách giảm ngưỡng của Confidence score xuống thấp, ta có thể giữ lại những đối tượng mà bị che khuất, nhưng bây giờ số lượng dương tính giả (False Positive) sẽ bị tăng lên.
Tuy nhiên, ByteTrack lại nghĩ theo một hướng khác. Các tác giả của ByteTrack đưa ra ý tưởng rằng: thay vì loại bỏ các đối tượng có Confidence score thấp, tại sao lại không xem xét chúng trong quá trình matching?
3. ByteTrack
Theo như tác giả, khi lựa chọn những đối tượng để bắt đầu theo dõi, hãy theo dõi những đối tượng có Confidence score cao. Sau đó, khi matching các bboxes của các đối tượng nằm trong danh sách được theo dõi với các bboxes được phát hiện trong các frame tiếp theo, kể cả những bboxes có Confidence score thấp cũng vẫn sẽ được xem xét.
Đầu tiên, quá trình matching sẽ được thực hiện giữa bboxes của các đối tượng đã được track tại frame t1 và các bboxes được detect tại frame t2, những bboxes này có Confidence score cao (lớn hơn threshold: 0.5) và các bước cũng giống như SORT được giới thiệu ở trên.

Sau khi match xong những bboxes mà có Confidence score cao, trong frame thứ 2 ta có thể thấy còn 2 bboxes nữa với Confidence score lần lượt là: 0.4 và 0.1 chưa được match (những bboxes có hình tam giác màu cam bên trong). Với 2 bboxes còn lại này, các tác giả lại cho nó đi qua quá trình matching một lần nữa để tính IoU giữa nó và các đối tượng được track ở các frame trước.

Từ đó có thể thấy bbox của người thứ 2 từ bên trái qua khi bị che khuất bây giờ đã được match. Còn bbox được detect với Confidence score 0.1 thì được loại bỏ vì IoU giữa nó và bbox được track từ các frame phía trước là 0.
Khi áp dụng kỹ thuật này vào các phương pháp theo dõi hiện có, các tác giả đã chỉ ra cho thấy rằng hiệu suất được cải thiện một cách nhất quán. Đặc biệt có thể thấy rằng, số lượng IDs giảm đi rất nhiều (IDs càng ít càng tốt). Ở đây, số lượng chuyển đổi ID có nghĩa là số lần ID được thay đổi trong quá trình theo dõi đối với từng đối tượng.
Cùng với đó, bằng cách áp dụng detector tốt (YOLOX) và nội suy Tracklet (Track vs Tracklet) để bổ sung thêm cho quá trình xử lý hậu kỳ (post-processing) với các đối tượng bị che khuất hoàn toàn, ByteTrack đã đạt được SOTA trong lĩnh vực tracking.
4. Kết luận
Qua 3 phần ở trên, mình đã giới thiệu với mọi người ý tưởng đằng sau ByteTrack là như thế nào, nó có điểm gì mới so với các thuật toán về tracking trước đây. Để tìm hiểu sâu hơn về nó, trong các phần tiếp theo, mình sẽ cố gắng giải thích từng thành phần cấu tạo nên ByteTrack, từ YOLOX đến các thuật toán như Kalman Filter, Hungarian,... 😉
Mong rằng bài viết này sẽ nhận được ủng hộ từ mọi người để mình có động lực viết tiếp các phần sau. Спасибо ❤
5. Further reading
All Rights Reserved
