Binary data và GridFS trên MongoDB
Bài đăng này đã không được cập nhật trong 7 năm
1. GridFS - Introduction
Nếu bạn từng sử dùng mongoDB và trải nghiệm những điều mà hệ quản trị cơ sở dữ liệu này đem lại, chúng ta không thể phủ nhận những ưu thế của nó so với RDBMS, ví dụ như:
- Mongo lưu trữ dữ liệu dưới dạng document JSON, không ràng buộc về số lượng field, kiểu dữ liệu nên chúng ta có thể tự do insert dữ liệu mà mình mong muốn, đồng thời khi insert, update hoặc xoá nó không cần mất thời gian validate các bảng liên quan như RDBMSRDBMS
- Ngoài việc dữ liệu được lưu dưới dạng JSON, cộng thêm việc dữ liệu được đánh index nên tốc độ truy vấn trên MongoDB vượt trội hơn hẳn
- MongoDB còn hỗ trợ replica set giúp sao lưu và phục hồi dữ liệu. Tuy nhiên rắc rối xảy ra khi thao tác với dữ liệu large binary như images, audios hay videos, đó là maximum document size trên MongoDB chỉ là 16MB. Hẳn bạn sẽ cho rằng cái giới hạn này thật là nực cười khi mà MongoDB ra đời nhằm phục vụ cho thời đại công nghệ cao khi mà hình ảnh, videos chụp từ camera điện thoại có dung lượng vài chục MB cho đến hàng GB này. Thực chât đây là câu chuyện về hiệu suất. Bạn thử tưởng tượng nếu dữ liệu được lưu trong document, rõ ràng nó rất lớnlớn, nó khiến cho thao tác lấy dữ liệu khó khăn hơn khi bạn phải tải toàn bộ files trong documentdocument ngay cả khi chúng ta chỉ cần lấy một phần nhỏ trong document đó. May mắn thay, MongoDB có một giải pháp độc đáo giúp chúng ta lưu trữ các files lớn khá dễ dàng, đồng thời cho phép truy xuất một phần dữ liệu của file mà không cần load toàn bộ nội dung trong khi vẫn đảm bảo hiệu suất cao. Công cụ mà tôi muốn nhắc đến đó là GridFS.
2. Grids-Architechture
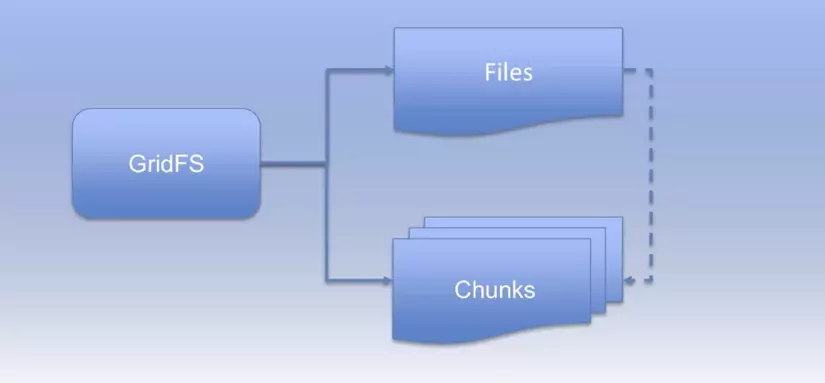 (Hình minh hoạ từ Coursera)
GridFS gồm 2 phần, chính xác là 2 collections
(Hình minh hoạ từ Coursera)
GridFS gồm 2 phần, chính xác là 2 collections
fs.files: Collection này chứa tên file và các thông tin liên quan(metadata)fs.chunks: Collection này chứa dữ liệu các file chunks, dung lượng các file này thường là 256k. Mặc địnhfilesvàchunksđặt trong namespacefs, tuy nhiên chúng ta cũng có thể thay đổi default namespace cho phù hợp với loại file muốn lưu, ví dụ file ảnh hoặc videos.
2.1 fs.files
{
"_id" : ObjectId("5ce528926e27f74141000003"),
"contentType" : "text/csv",
"length" : 19341217,
"chunkSize" : 4194304,
"uploadDate" : ISODate("2019-05-22T00:00:00Z"),
"md5" : "1d2cd4f69b28aa4202b6fe34cd702acc",
"filename" : "uploads/document/attachment/5ce528926e27f74141000001/organization_data_05_22.csv"
}
| Options | Descriptions |
|---|---|
| _id | unique key dùng định danh file |
| chunkSize | Kích thước file chunks lưu trong database |
| length | Muốn biết 1 file được tách thành bao nhiêu chunks thì chúng ta cần biết chunkSize và kích thước của file cần lưu |
| contentType | application/mp4, text/csv... |
| filename | Tên file |
| uploadDate | Ngày upload |
| md5 | Signature: Bảo mật và toàn vẹn dữ liệu |
2.2 fs.chunks
{ "_id" : ObjectId("5ce52bb06e27f795ae000009"), "n" : 0, "files_id" : ObjectId("5ce52bb06e27f795ae00000a") }
{ "_id" : ObjectId("5ce52bb06e27f795ae00000b"), "n" : 1, "files_id" : ObjectId("5ce52bb06e27f795ae00000a") }
{ "_id" : ObjectId("5ce52bb06e27f795ae00000c"), "n" : 2, "files_id" : ObjectId("5ce52bb06e27f795ae00000a") }
{ "_id" : ObjectId("5ce52bb06e27f795ae00000d"), "n" : 3, "files_id" : ObjectId("5ce52bb06e27f795ae00000a") }
{ "_id" : ObjectId("5ce52bb16e27f795ae00000e"), "n" : 4, "files_id" : ObjectId("5ce52bb06e27f795ae00000a") }
{ "_id" : ObjectId("5ce52bb16e27f795ae00000f"), "n" : 5, "files_id" : ObjectId("5ce52bb06e27f795ae00000a") }
{ "_id" : ObjectId("5ce52bb16e27f795ae000010"), "n" : 6, "files_id" : ObjectId("5ce52bb06e27f795ae00000a") }
| Options | Descriptions |
|---|---|
| chunks._id | Unique ObjectID |
| chunks.file_id | ID của collection fs.files |
| chunks.n | Số thứ tự file chunks, bắt đầu là 0 |
3. Grids-Index
GridFs sử dụng index trên cả 2 collections fs.files và fs.chunks để tăng hiệu suất truy xuất. GridFs tự động tạo ra các chỉ mục này, tuy nhiên chúng ta cũng có thể tạo bổ sung tuỳ theo nhu cầu.
3.1 File index
> db.fs.files.createIndex( { filename: 1, uploadDate: 1 } );
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
3.2 Chunks index
> db.fs.chunks.createIndex( { files_id: 1 , n: 5 }, { unique: true } );
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
4. Conclusion
Về lý thuyết GridFS thật tuyệt, cho phép giải quyết bài toán giới hạn document size của MongoDB (16MB). Dường như nó còn có thể xử lý vấn đề lưu trữ hàng ngàn ,thậm chí hàng triệu files mà không tiêu tốn nhiều tài nguyên hệ thống. Tuy nhiên không hẳn đã chính xác, đối với bất kỳ file nào được lưu trữ bằng GridFS thì đều được chia nhỏ thành các chunks có kích thước 255KB. Khi chúng ta truy xuất 1 file lớn nKB, nó sẽ lấy ra tất cả nKB/255k chunks liên quan. Nếu việc này xảy ra một cách thường xuyên, nó sẽ ngốn một lượng lớn tài nguyên(RAM). Vậy nên cần xem xét kỹ lương khi sử dùng GridFS, hoặc tạo riêng 1 server MongoDB rành riêng cho GridFS.
All rights reserved
