Big O - Học DSA để phỏng vấn (Bài 0)
Hello anh em, lại là mình NekoArcoder đây...

Tình hình là mình đang trong giai đoạn tìm việc, mà DSA học từ hồi học đại học thì cũng mù mờ qua môn, lâu lắm rồi chưa ôn lại.
Vừa hay trong giai đoạn các job đang cực kỳ nhiều trong giai đoạn ra Tết hiện nay, nhận thấy cơ hội này, mình đã tìm một số khóa học DSA để học, sẵn tiện viết lại các bài blog chia sẻ để dễ nhớ hơn, cũng như mọi người cùng ôn lại với mình nha!!!
Nếu thấy hay thì xin anh em một Upvote nhaaaa, xia xìa mọi người rất nhìuuuuu!!!
I. Vì sao chúng ta cần Big O?
Khi bạn được giao một bài toán và yêu cầu giải, việc giải một bài toán với mỗi người có thể là khác nhau.
Với mỗi bài toán, thường có rất nhiều cách giải khác nhau. Không chỉ 2–3 cách, mà có thể 10–20 cách, thậm chí nhiều hơn.

Câu hỏi quan trọng là:
Làm sao biết cách nào tốt hơn?
Ví dụ đơn giản: Bạn được yêu cầu giải bài toán Đảo ngược chuỗi
Giả sử đề bài là:
Viết một hàm nhận vào một chuỗi và trả về chuỗi đó theo thứ tự đảo ngược.
Vậy thật sự sẽ có bao nhiêu cách làm?
- Dùng vòng lặp for
- Dùng while
- Dùng array
- Dùng method có sẵn
- Dùng đệ quy
- Kết hợp nhiều cách
Trên StackOverflow có thể tìm thấy đến 10 cách khác nhau bằng các ngôn ngữ khác nhau.
Và đó không chỉ là đổi tên biến hay đổi for thành while, mà là những cách tiếp cận hoàn toàn khác nhau.
Tất cả đều chạy đúng.
Vậy: Cách nào là tốt nhất?
1. Big O là gì trong bối cảnh này?
Big O là một hệ thống để phân loại và so sánh code.
Nó cho phép chúng ta:
- Tổng quát hóa hành vi của code
- So sánh hiệu năng giữa các thuật toán
- Diễn đạt hiệu suất bằng một cách chuẩn hóa
Thay vì nói:
- “Cách này hay”
- “Cách kia tệ”
Chúng ta có thể nói:
- Thuật toán này là O(n)
- Thuật toán kia là O(n²)
2. Một phép so sánh dễ hiểu: Thang đo động đất
Hãy tưởng tượng bạn học môn địa chấn học (seismology).

Thay vì nói:
- “Có một trận động đất lớn”
- “Có một trận lớn hơn nữa”
Chúng ta dùng thang đo Richter:
- 7.5 độ
- 9.2 độ
Điều đó giúp đặt mọi thứ vào bối cảnh rõ ràng.
Big O cũng tương tự như vậy, nó chính là thang đo cho các thuật toán.
3. Nhưng có cần quan tâm đến “tốt nhất” không?
Một số bạn có thể nghĩ:
“Miễn là code chạy được thì ổn rồi, đúng không?”
Trong nhiều trường hợp, điều đó đúng. Đặc biệt với:
- Dự án nhỏ
- Dữ liệu ít
- Ứng dụng đơn giản
Nhưng khi:
- Bạn đi phỏng vấn kỹ thuật
- Làm việc với hệ thống lớn
- Xử lý hàng trăm triệu bản ghi dữ liệu
Thì hiệu năng rất quan trọng.
Ví dụ: Nếu một thuật toán tiết kiệm được 1 giờ mỗi lần chạy so với thuật toán khác, và nó chạy mỗi ngày, thì sự khác biệt đó là cực kỳ lớn.
Khi đó, thực sự tồn tại khái niệm:
Thuật toán tốt hơn
4. Big O giúp gì trong thực tế?
1. So sánh hiệu năng giữa các giải pháp
Ngay cả khi bạn hài lòng với lời giải của mình, việc hiểu nó hiệu quả đến đâu vẫn rất quan trọng.
2. Phân tích trade-off
Không phải lúc nào cũng:
- Cái này tốt hoàn toàn
- Cái kia tệ hoàn toàn
Có thể:
- Một thuật toán xử lý dữ liệu lớn rất tốt
- Thuật toán khác ổn định hơn nhưng chậm hơn một chút
- Một cách dùng ít bộ nhớ hơn nhưng tốn thời gian hơn
Big O giúp ta phân tích những đánh đổi đó.
3. Debug hiệu năng
Code có thể chạy đúng nhưng:
- Chạy quá chậm
- Trình duyệt bị lag
- CPU tăng vọt
Nếu hiểu Big O, bạn có thể:
- Xác định đoạn code kém hiệu quả
- Tìm ra nút thắt cổ chai
4. Phỏng vấn kỹ thuật
Rất nhiều nhà tuyển dụng hỏi:
- “Big O của thuật toán này là gì?”
- “So sánh Big O của 3 hàm này”
- “Cải thiện Big O của lời giải này”
Dù mục tiêu không nên chỉ là vượt qua phỏng vấn, nhưng thực tế là Big O xuất hiện rất nhiều trong các buổi technical interview.
5. So sánh hai cách giải cho cùng một bài toán
Bây giờ chúng ta sẽ xem một ví dụ cụ thể hơn và so sánh hai lời giải khác nhau cho cùng một bài toán.
Bài toán
Giả sử bạn cần viết một hàm tính tổng tất cả các số từ 1 đến n (bao gồm cả n).
Ví dụ:
- Nếu n = 3 → Kết quả phải là: 1 + 2 + 3 = 6
Cách 1: Dùng vòng lặp
Cách phổ biến và dễ nghĩ ra nhất là:
- Tạo một biến total
- Duyệt từ 1 đến n
- Cộng từng số vào total
- Trả về total
Ví dụ JavaScript:
function addUpTo(n) {
let total = 0;
for (let i = 1; i <= n; i++) {
total += i;
}
return total;
}
Cách hoạt động:
- total bắt đầu từ 0
- Vòng lặp chạy từ 1 đến n
- Mỗi lần lặp cộng thêm i
- Cuối cùng trả về tổng
Kiểm tra:
- addUpTo(3) → 6
- addUpTo(6) → 21
- addUpTo(100) → 5050
Cách này hoạt động tốt và rất dễ hiểu.
Cách 2: Dùng công thức toán học
Có một công thức tính tổng từ 1 đến n:
n × ( n + 1 ) / 2
Vậy ta có thể viết:
function addUpTo(n) {
return n * (n + 1) / 2;
}
Cách này:
- Không có vòng lặp
- Chỉ một dòng duy nhất
- Dựa trên công thức toán học
Ví dụ với n = 6:
- 6 × (6 + 1) = 42
- 42 / 2 = 21
Kết quả giống hệt cách 1.
Vậy cách nào tốt hơn?
Trước tiên, cần hỏi:
Tốt hơn nghĩa là gì?
Có nhiều tiêu chí để đánh giá như sau:
1. Tốc độ (speed)
- Chạy nhanh hơn?
- Với n nhỏ hay n lớn?
2. Bộ nhớ (memory usage)
- Dùng bao nhiêu biến?
- Lưu trữ bao nhiêu dữ liệu?
3. Độ dễ đọc (readability)
- Code có dễ hiểu không?
- Người khác có đọc được không?
Tất cả đều hợp lý. Nhưng trong phần này, chúng ta sẽ tập trung vào:
Tốc độ thực thi (execution time)
Thử đo thời gian chạy
Cách đơn giản nhất là đo thời gian trước và sau khi chạy hàm.
Trong trình duyệt, ta có thể dùng:
performance.now()
Ý tưởng:
- Ghi lại thời điểm trước khi gọi hàm
- Gọi hàm
- Ghi lại thời điểm sau khi chạy xong
- Lấy hiệu hai giá trị
let t1 = performance.now();
addUpTo(1000000000);
let t2 = performance.now();
console.log((t2 - t1) / 1000);
Kết quả đo thực tế
Khi chạy:
- Cách dùng vòng lặp có thể mất khoảng ~1.2 giây
- Cách dùng công thức gần như tức thì (gần 0 giây)
Rõ ràng cách 2 nhanh hơn rất nhiều.
Nhưng đo thời gian có vấn đề gì?
Đây là điểm quan trọng.
1. Máy khác nhau → kết quả khác nhau
- Máy mạnh → nhanh hơn
- Máy yếu → chậm hơn
- Ứng dụng khác đang chạy → ảnh hưởng kết quả
2. Cùng một máy → kết quả vẫn khác
Ngay cả khi chạy lại cùng một đoạn code trên cùng máy, thời gian vẫn dao động một chút.
3. Với thuật toán rất nhanh → khó đo chính xác
Nếu các thuật toán đều rất nhanh:
- Thời gian đo có thể quá nhỏ
- Công cụ đo không đủ chính xác để phân biệt
Vấn đề lớn hơn
Giả sử:
- Một thuật toán chạy 1 giờ
- Thuật toán khác chạy 4 giờ
Bạn không muốn phải đợi cả tiếng chỉ để biết cái nào nhanh hơn.
Chúng ta cần một cách:
- Không phụ thuộc vào máy
- Không cần đo thực tế
- Có thể nói tổng quát về hiệu năng
- So sánh hai thuật toán một cách chuẩn hóa
6. Và đó là lý do Big O tồn tại
Big O cho phép chúng ta:
- Phân tích hiệu năng bằng lý thuyết
- Không cần chạy thử
- Không phụ thuộc phần cứng
- So sánh thuật toán một cách tổng quát
Trong ví dụ này:
- Cách dùng vòng lặp tăng thời gian theo n
- Cách dùng công thức không phụ thuộc vào n theo cùng cách đó
- Nhưng chi tiết cụ thể sẽ được giải thích ngay phần tiếp theo.
7. Nếu không đo thời gian, ta nên làm gì?
Chúng ta đã nói về vấn đề khi dùng thời gian chạy thực tế (seconds/milliseconds) để so sánh code:
- Máy khác nhau → kết quả khác nhau
- Cùng một máy → vẫn dao động
- Thuật toán quá nhanh → khó đo chính xác
Vậy nếu không dùng thời gian, ta dùng gì?
Ý tưởng cốt lõi: Đếm số phép toán đơn giản
Thay vì đo số giây, chúng ta sẽ:
Đếm số simple operations (phép toán cơ bản) mà máy tính phải thực hiện.
Các phép toán cơ bản sẽ gồm cộng, trừ, nhân, chia, phép gán,....
Vì sao cách này tốt hơn?
- Số phép toán không phụ thuộc vào máy
- Không phụ thuộc CPU mạnh hay yếu
- Không phụ thuộc “tâm trạng” của laptop hôm đó

Ví dụ đơn giản:
- Thuật toán A có 5 phép toán
- Thuật toán B có 7 phép toán
Dù chạy trên máy nào, B vẫn nhiều thao tác hơn A.
Xem lại lời giải thứ hai (dùng công thức)
function addUpTo(n) {
return n * (n + 1) / 2;
}
Ta có:
- Một phép cộng
(n + 1) - Một phép nhân
n * (...) - Một phép chia
/ 2
Tổng cộng: 3 phép toán chính
Điều quan trọng:
- Dù n = 2
- Hay n = 1 tỷ
→ Vẫn chỉ có 3 phép toán
Số phép toán không thay đổi theo n
Xem lại lời giải dùng vòng lặp
function addUpTo(n) {
let total = 0;
for (let i = 1; i <= n; i++) {
total += i;
}
return total;
}
Bây giờ mọi thứ phức tạp hơn rồi nhỉ.
Phân tích từng phần
1. total += i
Mỗi vòng lặp có:
- Một phép cộng
- Một phép gán (=)
Nếu n = 5 → 5 lần cộng
Nếu n = 20 → 20 lần cộng
Nếu n = 1 tỷ → 1 tỷ lần cộng
Tức là số phép toán phụ thuộc vào n
2. i++
i++ thực chất tương đương:
i = i + 1
Nó gồm:
- Một phép cộng
- Một phép gán
Và cũng chạy n lần.
3. So sánh i <= n
Mỗi vòng lặp đều phải kiểm tra điều kiện.
Nếu n = 20 → có 20 lần so sánh
Nếu n = 1 tỷ → có 1 tỷ lần so sánh
4. Các phép gán ngoài vòng lặp
let total = 0;
let i = 1;
Những cái này chỉ chạy 1 lần, không phụ thuộc vào n. Ta sẽ không quan tâm những giá trị này.
Tổng số phép toán là bao nhiêu?
Ta có thể ước lượng:
- Cộng trong vòng lặp
- Gán trong vòng lặp
- So sánh
- Tăng biến đếm
Tùy cách đếm, có thể ra:
- 3n
- 4n
- 5n + 2
- 2n + 3
- v.v.
Nhưng đây là điểm quan trọng:
Con số chính xác không quan trọng.
Điều quan trọng là xu hướng tăng.
Điểm mấu chốt của Big O
Trong lời giải dùng vòng lặp:
- Khi n tăng
- Số phép toán tăng tỷ lệ thuận với n
Nếu n gấp đôi → số phép toán gần như gấp đôi
Nếu n tăng 1000 lần → số phép toán tăng 1000 lần
Ta nói rằng số phép toán tăng tuyến tính theo n.
So sánh hai lời giải
| Cách | Số phép toán |
|---|---|
| Công thức | Luôn ~3 |
| Vòng lặp | Tăng theo n |
Điểm khác biệt lớn nhất:
- Công thức → số phép toán không phụ thuộc n
- Vòng lặp → số phép toán phụ thuộc n
Tư duy Big O là nhìn vào xu hướng lớn
Big O không quan tâm:
- Chính xác là 3n hay 5n
- Là 5n + 2 hay 2n + 7
Big O chỉ quan tâm:
Khi n lớn lên, số phép toán tăng như thế nào?
Trong ví dụ này:
- Lời giải công thức: tăng = hằng số
- Lời giải vòng lặp: tăng tuyến tính theo n
Và đó chính là nền tảng để bước sang phần tiếp theo:
Chính thức định nghĩa và ký hiệu bằng Big O.

II. Minh họa trực quan: Vẽ biểu đồ thời gian chạy
Truy cập url này để thực hiện nhé các bạn: https://rithmschool.github.io/function-timer-demo/
Mục tiêu của chúng ta không phải là đo chính xác tuyệt đối, mà là:
Quan sát xu hướng tổng quát khi đầu vào tăng.
Hai hàm được so sánh
Chúng ta tập trung vào 2 hàm: addUpToFirst và addUpToSecond
1. Cách tool hoạt động
Quy trình mỗi lần nhấn nút Plot:
- Bắt đầu timer
- Gọi hàm với giá trị n
- Dừng timer
- Lưu thời gian
- Vẽ điểm lên biểu đồ
- Nối các điểm lại thành đường xu hướng
Sau đó tăng n lên và lặp lại.
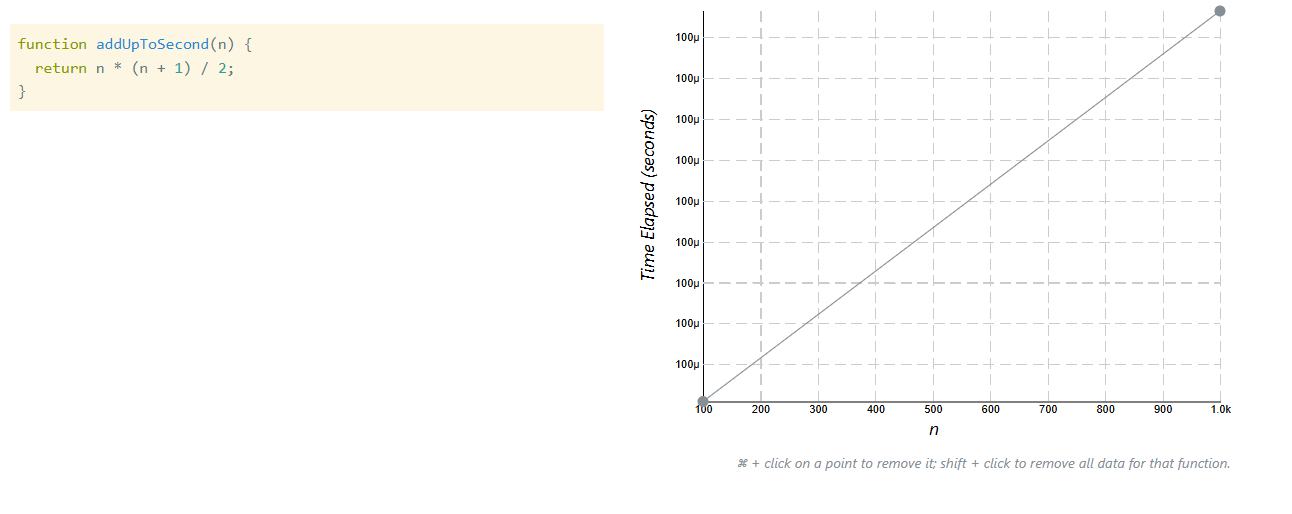
Kết quả với addUpToSecond (công thức)
Ta thử lần lượt với:
-
n = 100
![image.png]()
-
n = 1000
![image.png]()
-
n = 10000
![image.png]()
Biểu đồ có thể dao động lên xuống nhẹ vì:
- Đơn vị đo rất nhỏ (micro/nanoseconds)
- Sai số đo lường nhỏ
Nhưng điều quan trọng là:
Đường biểu đồ gần như nằm ngang.
Điều đó là vì:
- Luôn chỉ có 3 phép toán
- Không phụ thuộc n
- Thời gian gần như không đổi
Dù n tăng từ 100 lên 10.000 hay lớn hơn nữa, thời gian hầu như không thay đổi đáng kể.
Kết quả với addUpToFirst (vòng lặp)
Ta thử lại:
-
n = 100
![image.png]()
-
n = 1000
![image.png]()
-
n = 10000
![image.png]()
-
n = 100000
![image.png]()
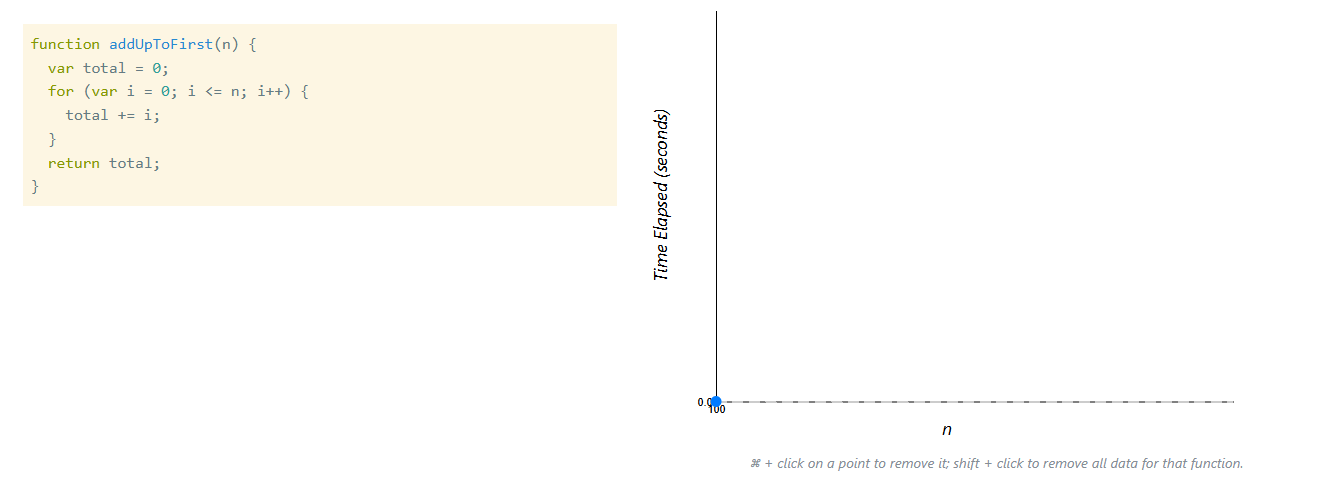
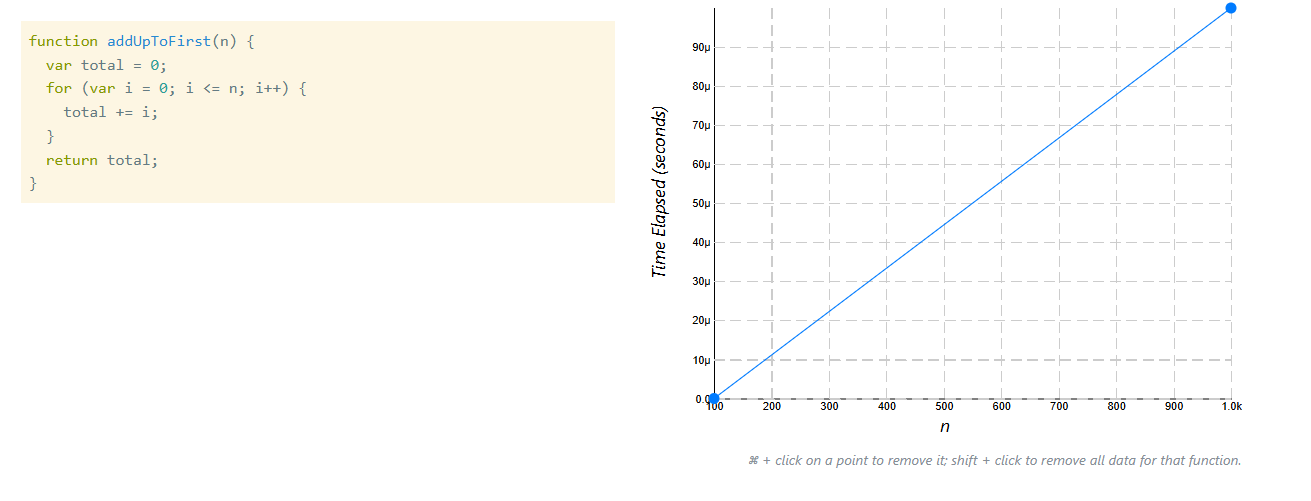
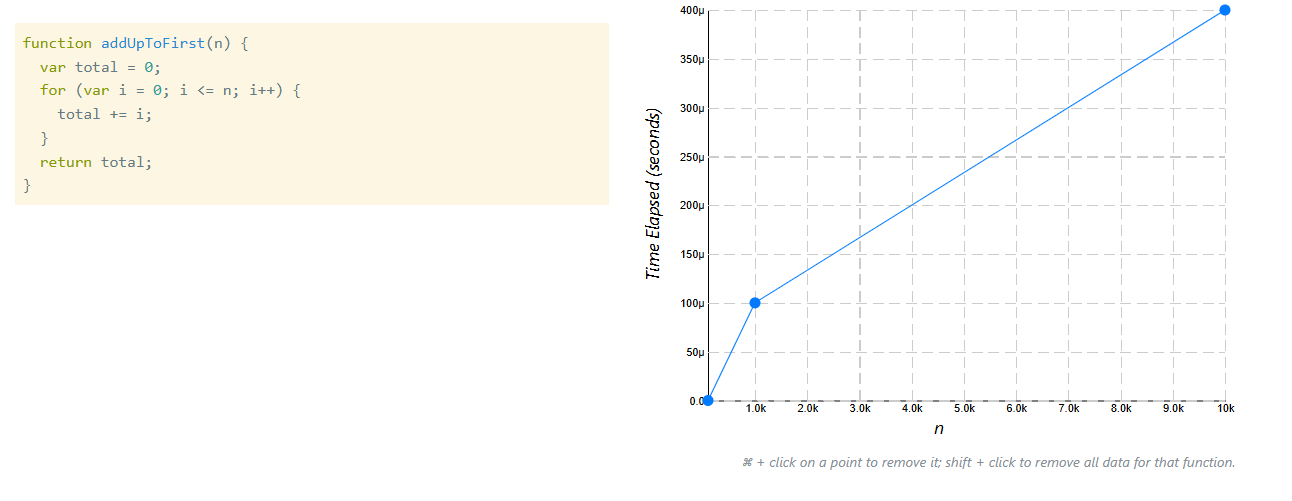
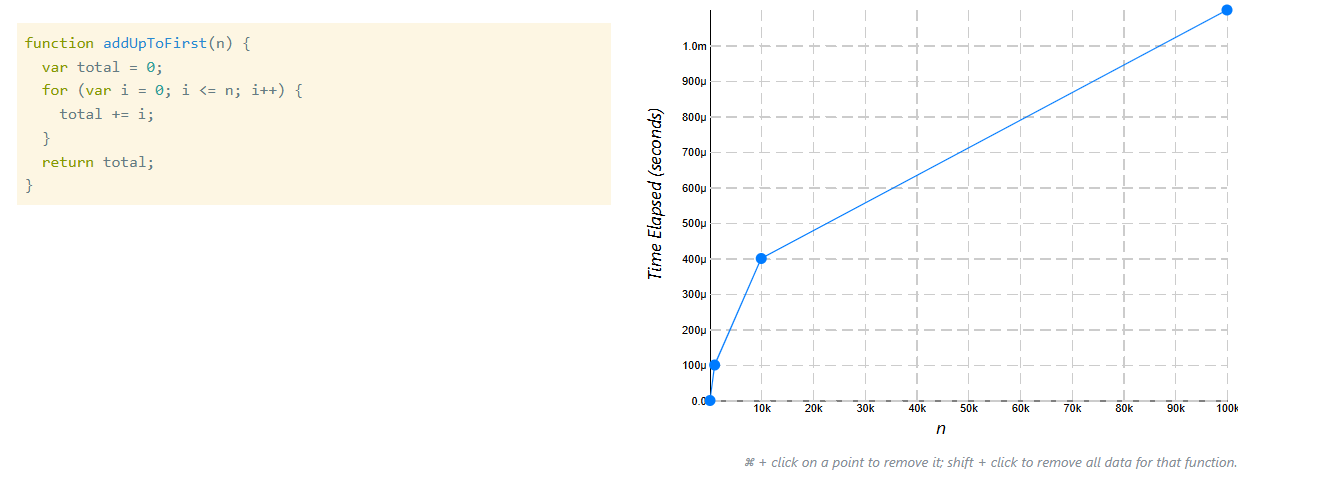
Lúc này ta thấy:
- Thời gian tăng rõ rệt
- Biểu đồ tạo thành một đường gần như thẳng đi lên
Khi n tăng:
- Số phép toán tăng
- Thời gian tăng theo tỷ lệ tương ứng
Số phép toán tăng → Thời gian tăng theo tỷ lệ tương ứng
Đây là điều ta đã phân tích lý thuyết ở phần trước.
2. So sánh hai xu hướng
1. addUpToSecond
- Thời gian ≈ hằng số
- Biểu đồ gần như phẳng
- Không phụ thuộc n
2. addUpToFirst
- Thời gian tăng theo n
- Biểu đồ dốc lên tuyến tính
- Phụ thuộc trực tiếp vào kích thước đầu vào
Điều quan trọng nhất: Nhìn vào bức tranh toàn cảnh
Biểu đồ có thể hơi nhiễu ở mức nhỏ. Số liệu có thể dao động.
Nhưng Big O không quan tâm đến:
- Sai số nhỏ
- Microseconds
- Biến động nhẹ
Big O quan tâm đến:
Khi n rất lớn, xu hướng tổng thể là gì?
Ở đây ta thấy rõ:
- Một thuật toán có xu hướng phẳng (constant)
- Một thuật toán tăng tuyến tính (linear)
Và sự khác biệt là cực kỳ lớn:
- 1.2 giây so với
- vài mili-giây
3. Ý nghĩa của ví dụ này
Hai thuật toán:
- Làm cùng một việc
- Trả về cùng kết quả
Nhưng:
Có hiệu năng hoàn toàn khác nhau.
Đây chính là điều Big O giúp ta mô tả một cách chính xác.
III. Big O là gì? Giải thích đầy đủ và dễ hiểu
Cuối cùng thì chúng ta cũng chính thức nhắc đến thuật ngữ Big O.
Dù thực tế từ trước đến giờ chúng ta đã nói về nó rồi, chỉ là chưa gọi đúng tên thôi.
1. Big O là gì?
Big O là một cách đếm “fuzzy” nhưng có hệ thống. (Thuật ngữ Fuzzy có thể hiểu là thứ mập mờ, không cần quá đúng chính xác, mang tính khái quát)
Nó giúp chúng ta mô tả một cách chính thức:
Khi kích thước đầu vào (n) tăng lên thì thời gian chạy của thuật toán thay đổi như thế nào?
Nói cho đơn giản thì là:
- Đầu vào tăng → chương trình chạy lâu hơn bao nhiêu?
- Mối quan hệ giữa kích thước input (n) và runtime là gì?
Big O không quan tâm đến chi tiết nhỏ lẻ, mà chỉ quan tâm đến xu hướng tổng thể.
2. Chúng ta đã dùng Big O rồi mà chưa biết
Trước đó, ta đã xem hai cách tính tổng từ 1 đến n:
Ví dụ 1: Công thức toán học (3 phép toán cố định)
return n * (n + 1) / 2
Dù n là 10 hay 1 triệu:
- Vẫn chỉ thực hiện 3 phép toán
- Thời gian gần như không đổi
→ Đây là một O(1) (constant time)
Ví dụ 2: Dùng vòng lặp
for (let i = 1; i <= n; i++) {
total += i
}
- n tăng gấp đôi → số lần lặp tăng gấp đôi
- Runtime tăng tỷ lệ 1:1 với n
→ Đây là một O(n) (linear time)
Lưu ý quan trọng:
Nếu có 5n hay 100n thì ta vẫn viết là O(n). Tương tự O(500) thì ta viết là O(1)).
Vì Big O bỏ qua hệ số hằng số. Ta chỉ quan tâm đến bậc tăng trưởng của nó mà thôi.
3. Định nghĩa chính thức (Đừng lo, bạn không phải nhớ nó đâu)
Định nghĩa chuẩn khô khan như sau:
Một thuật toán là O(f(n)) nếu số phép toán của nó cuối cùng nhỏ hơn một hằng số nhân với f(n) khi n tăng.
Nhưng ta có thể hiểu đơn giản là:
Big O mô tả mối quan hệ giữa Input (n) và Runtime
Các dạng f(n) phổ biến:
| Ký hiệu O(f(n)) | Ý nghĩa |
|---|---|
| O(1) | Hằng số |
| O(n) | Tuyến tính |
| O(n²) | Bình phương |
| O(log n) | Logarithmic |
| O(n log n) | Tuyến tính nhân log |
4. Big O luôn nói về Worst Case
Khi nói Big O, ta đang nói về:
Trường hợp tệ nhất (upper bound)
Tức là nếu n tăng lớn, thời gian tối đa có thể tăng theo xu hướng nào.
5. Ví dụ mới: Count Up and Down
Ta có hàm js như sau:
function countUpAndDown(n) {
console.log("Going up!");
for (let i = 0; i < n; i++) {
console.log(i);
}
console.log("At the top!\nGoing down...");
for (let j = n - 1; j >= 0; j--) {
console.log(j);
}
console.log("Back down. Bye!");
}
Hàm này sẽ là:
- Đếm từ 0 đến n
- Sau đó đếm ngược từ n về 0
Ta có:
- Một vòng lặp O(n)
- Một vòng lặp nữa O(n)
Tổng là O(n + n) = O(2n)
Nhưng vì bỏ hệ số 2 nên ta có là O(n)
Như vậy ta có thể suy ra được rằng: Hai vòng lặp nối tiếp → cộng lại → Nhưng vẫn là tuyến tính!
6. Ví dụ 4: Nested Loop – O(n²)
Giờ chúng ta sẽ đến ví dụ quan trọng hơn:
Hàm printAllPairs(n):
function printAllPairs(n) {
for (let i = 0; i < n; i++) <- Vòng lặp O(n) bên ngoài
for(let j = 0; j < n; j++) <- Vòng lặp O(n) con bên trong
console.log(i, j)
}
Nếu n = 2:
(0,0)
(0,1)
(1,0)
(1,1)
→ Ta có 4 cặp
Nếu n = 3 → 9 cặp
Nếu n = 4 → 16 cặp
Ta thấy Số cặp = n × n = n²
Vì có:
- 1 vòng lặp O(n)
- Bên trong lại có 1 vòng lặp O(n)
Ta nhân lại:
O(n × n) = O(n²)
7. So sánh O(n) và O(n²)
Sự khác biệt rất lớn khi input n tăng dần:
| n | O(n) | O(n²) |
|---|---|---|
| 10 | 10 | 100 |
| 100 | 100 | 10,000 |
| 500 | 500 | 250,000 |
Khi n tăng lên:
- O(n) tăng đều
- O(n²) tăng cực nhanh
Vì vậy nested loop nguy hiểm hơn nhiều.
Nhìn dưới góc độ đồ thị
-
O(1): đường ngang
![image.png]()
-
O(n): đường thẳng tăng đều
![image.png]()
-
O(n²): đường cong dốc lên rất nhanh
![image.png]()
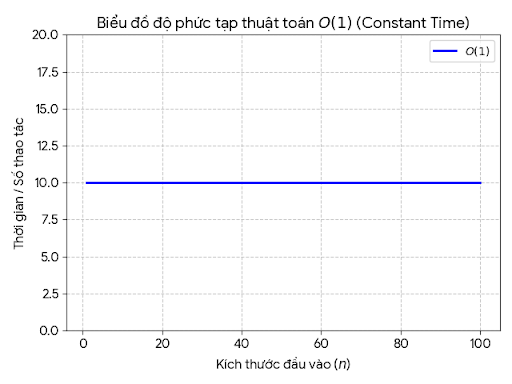
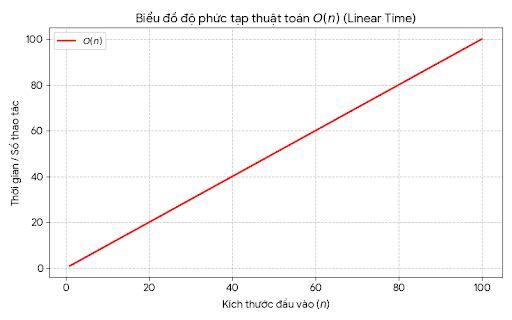
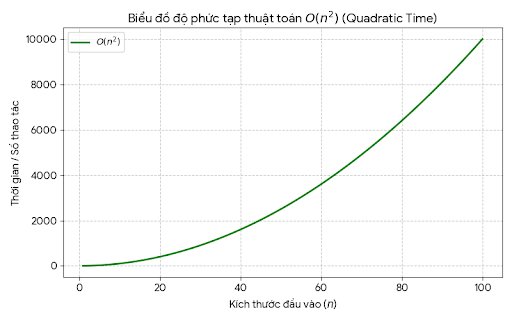
Khi n càng lớn, sự khác biệt càng rõ.
8. Tổng kết các ví dụ đã thấy
| Hàm | Big O | Ý nghĩa |
|---|---|---|
| addUpTo (cách 1) | O(n) | Tăng tuyến tính |
| addUpTo (cách 2) | O(1) | Thời gian không đổi |
| countUpAndDown | O(n) | Tuyến tính |
| printAllPairs | O(n²) | Bình phương |
Cốt lõi cần nhớ
Big O là cách trả lời câu hỏi:
Khi input tăng lên rất lớn, runtime sẽ tăng theo kiểu gì?
- Không quan tâm chi tiết nhỏ
- Không quan tâm hệ số
- Không quan tâm dao động nhẹ
- Chỉ quan tâm xu hướng lớn
9. Bỏ túi những kiến thức cốt lõi
Ở đây mình sẽ đưa đến cho bạn một số quy tắc khi xác định Big O mà không cần nhớ quá nhiều chi tiết phức tạp nhé
Quy tắc 1: Bỏ qua hằng số
1. Bỏ hệ số phía trước
O(2n) → O(n)
O(500n) → O(n)
O(13n²) → O(n²)
Vì sao? Khi n rất lớn, đồ thị của:
- n²
- 13n²
- 1000n²
Đều có cùng hình dạng tăng trưởng.
Khác biệt hệ số chỉ làm đường cong cao hơn một chút, nhưng không đổi bản chất tốc độ tăng.
2. Hằng số độc lập
O(500) → O(1)
Điều này có nghĩa:
- Mỗi lần chạy đều tốn 500 phép toán
- Không phụ thuộc vào n
Đồ thị là một đường ngang → đó chính là O(1) (constant time).
Quy tắc 2: Bỏ các số hạng nhỏ hơn
1. Ví dụ đơn giản
O(n + 10) → O(n)
Vì khi n lớn thì số 10 không đáng kể
2. Ví dụ phức tạp hơn
O(n² + 5n + 8)
Ta giữ lại số hạng lớn nhất:
O(n²)
Vì sao?
Giả sử n = 1000:
- 5n = 5,000
- n² = 1,000,000
So sánh: 1,000,000 + 5,000 + 8
Phần 5,000 + 8 gần như vô nghĩa so với 1 triệu.
Nếu n = 1 tỷ thì sự chênh lệch còn lớn hơn rất nhiều.
Vì vậy, khi phân tích Big O, ta: Giữ số hạng tăng nhanh nhất và Bỏ phần còn lại
Quy tắc 3: Phép toán số học là O(1)
Ví dụ:
a + b
a * b
a / b
Máy tính mất gần như cùng thời gian cho 2 + 2 hay 1,000,000 + 2 nên đây sẽ là O(1)
Quy tắc 4: Gán biến là O(1)
x = 1000
x = 1000000
Thời gian là gần như nhau.
Quy tắc 5: Truy cập phần tử mảng bằng index là O(1)
arr[0]
arr[999]
Truy cập trực tiếp → không cần duyệt → O(1)
Quy tắc 6: Độ phức tạp của vòng lặp
Độ phức tạp của một vòng lặp:
Độ dài vòng lặp × độ phức tạp bên trong
Ví dụ:
for i = 1 → n
Một vòng lặp → O(n)
for i = 1 → n
for j = 1 → n
Nested loop → O(n × n) = O(n²)
10. Điều quan trọng nhất cần hiểu
Bạn không cần nhớ hết mọi công thức.
Điều quan trọng là:
- O(n²) tệ hơn O(n)
- O(n) tệ hơn O(1)
Khi n rất lớn, sự khác biệt trở nên cực kỳ rõ ràng
Nếu mình nói:
Thuật toán này có O(n²)
Bạn phải nhận ra ngay:
- Nó kém hiệu quả hơn O(n)
- Và càng tệ khi dữ liệu lớn
IV. Space Complexity – Độ phức tạp về bộ nhớ

Từ đầu đến giờ, chúng ta chỉ tập trung vào Time Complexity, thuật toán chạy nhanh hay chậm khi n tăng.
Bây giờ ta chuyển sang một khái niệm khác:
Space Complexity – Thuật toán dùng bao nhiêu bộ nhớ khi kích thước input tăng lên?
Chúng ta vẫn dùng ký hiệu Big O, nhưng thay vì đo thời gian, ta đo bộ nhớ.
1. Auxiliary Space – Ta đang đo cái gì vậy?
Có một khái niệm quan trọng:
Auxiliary Space Complexity
Nó có nghĩa là:
- Chỉ tính bộ nhớ dùng bên trong thuật toán
- Không tính bộ nhớ của input ban đầu
Ví dụ:
- Nếu input là mảng 1 triệu phần tử
- Dĩ nhiên nó đã chiếm bộ nhớ
- Nhưng ta không tính phần đó
Ta chỉ quan tâm:
Thuật toán tạo thêm bao nhiêu bộ nhớ ngoài input?
Khi nói space complexity, mặc định ta đang nói đến auxiliary space (Ta đọc auxiliary là /ɔːɡˈzɪl.i.ə.ri/).
2. Các quy tắc cơ bản về Space Complexity
Primitive types là O(1)
Trong JavaScript:
- number
- boolean
- null
- undefined
Đều chiếm constant space.
Ví dụ:
let x = 1let x = 1000000
Cả hai đều là một biến → O(1)
String là O(n)
String phụ thuộc vào độ dài.
Ví dụ:
- Chuỗi 1 ký tự
- Chuỗi 50 ký tự
- Chuỗi 50 ký tự chiếm bộ nhớ gấp 50 lần.
→ O(n) với n là độ dài chuỗi.
Array và Object là O(n)
Mảng và object là reference type.
- Mảng 2 phần tử
- Mảng 4 phần tử
Mảng 4 phần tử chiếm gấp đôi bộ nhớ.
→ O(n) với n là số phần tử.
4. Ví dụ: Hàm sum – O(1) Space
Giả sử ta có hàm:
function sum(arr) {
let total = 0;
for (let i = 0; i < arr.length; i++) {
total += arr[i];
}
return total;
}
Ta chỉ quan tâm đến bộ nhớ thêm vào.
Bộ nhớ được tạo:
- 1 biến total
- 1 biến i
Không có mảng mới.
Không tạo object mới.
Không lưu thêm dữ liệu theo kích thước arr.
Dù arr có:
- 10 phần tử
- 1000 phần tử
- 1 triệu phần tử
→ Số biến vẫn như cũ.
Space Complexity O(1) → constant space.
5. Ví dụ: Hàm double – O(n) Space
Giờ xem hàm này:
function double(arr) {
let newArr = [];
for (let i = 0; i < arr.length; i++) {
newArr.push(arr[i] * 2);
}
return newArr;
}
Điểm quan trọng:
- Nó tạo ra một mảng mới
- Mảng này có cùng độ dài với mảng input
Nếu input có:
- 3 phần tử → newArr có 3 phần tử
- 100 phần tử → newArr có 100 phần tử
- 1 triệu phần tử → newArr có 1 triệu phần tử
Bộ nhớ tăng theo input.
Space Complexity O(n)
Ta không cần viết: O(n + 2) Vì biến i và biến newArr là hằng số → bỏ qua.
6. Tư duy khi phân tích Space Complexity
Bạn hãy tự hỏi:
- Có tạo mảng mới không?
- Có tạo object mới không?
- Có tạo biến mới phụ thuộc vào n không?
- Có lưu trữ dữ liệu theo kích thước input không?
Nếu có → thường là O(n)
Nếu không → thường là O(1)
Điều quan trọng bạn cần hiểu
Bạn không cần phải thành thạo ngay lập tức.
Điều quan trọng là khi nghe:
Thuật toán này có O(n²) time nhưng O(1) space
Bạn hiểu rằng:
- Nó chạy chậm khi n lớn
- Nhưng không tốn thêm bộ nhớ
Hoặc:
Thuật toán này O(n) time và O(n) space
Bạn hiểu rằng:
- Nó chạy tuyến tính
- Và cũng dùng bộ nhớ tăng theo input
V. Logarithm trong Big O – Hiểu vừa đủ để dùng
Chúng ta bây giờ sẽ bắt đầu nói về logarithm (log).
Bạn có thể:
- Đã từng học và quên hết,
- Hoặc chưa từng học bao giờ,
- Hoặc vẫn còn nhớ mơ hồ
Không sao cả.
Bạn không cần trở thành chuyên gia về log. Bạn chỉ cần hiểu đủ để khi thấy O(log n), bạn biết nó tốt đến mức nào so với O(n) hoặc O(n²) là được.
1. Vì sao cần biết log?
Cho đến giờ ta đã thấy:
- O(1)
- O(n)
- O(n²)
Đây là những độ phức tạp rất phổ biến và dễ hiểu.
Nhưng trong thực tế, có những thuật toán có độ phức tạp O(log n)
Và loại này xuất hiện nhiều hơn bạn nghĩ, đặc biệt trong:
- Thuật toán tìm kiếm
- Thuật toán sắp xếp hiệu quả
- Đệ quy (recursion)
Vì vậy, ta cần hiểu log là gì.
2. Logarithm là gì?
Hiểu đơn giản:
Logarithm là phép toán ngược lại của lũy thừa (exponent).
Giống như:
- Nhân ↔ Chia
- Lũy thừa ↔ Logarithm
Ví dụ cơ bản
Ta có: log₂(8) = 3
Câu hỏi thực sự đang được hỏi là:
2 mũ bao nhiêu thì bằng 8?
Ta biết là 2³ = 8, vậy log₂(8) = 3
Công thức tổng quát
Nghĩa là b^y = x
Log và lũy thừa là hai phép toán đảo ngược nhau.
3. Không chỉ có cơ số 2
Ta có thể có:
- log₂
- log₁₀
- log₃
- logₑ
Nhưng trong Big O, ta thường bỏ luôn cơ số mà viết đơn giản thành O(log n)
Vì sao? Vì trong phân tích Big O:
- log₂(n)
- log₁₀(n)
- log₃(n)
Đều có cùng xu hướng tăng trưởng.
Khác cơ số chỉ khác hệ số → mà Big O bỏ qua hệ số.
4. Cách hiểu log theo kiểu trực quan
Cách dễ hiểu nhất:
log₂(n) ≈ số lần bạn có thể chia n cho 2 cho đến khi ≤ 1
Ví dụ 1: log₂(8)
Ta chia liên tục cho 2 thì ta có: 8 → 4 → 2 → 1
Chia được 3 lần → log₂(8) = 3
Ví dụ 2: log₂(25)
25 → 12.5
→ 6.25
→ 3.125
→ 1.5625
→ 0.78125
Chia khoảng 4 đến 5 lần → log₂(25) ≈ 4.64
Không cần chính xác. Điều quan trọng là nó tăng rất chậm.
5. O(log n) trên đồ thị
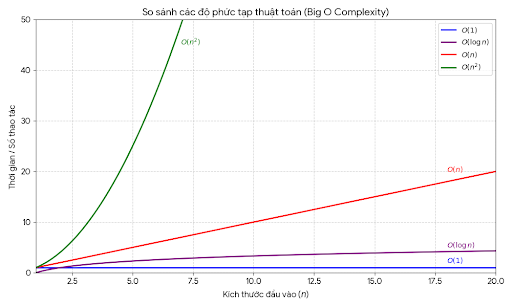
Nhìn vào đồ thị ta sẽ thấy:
- O(1): đường ngang
- O(log n): tăng rất chậm
- O(n): tăng tuyến tính
- O(n²): tăng cực nhanh
Điều quan trọng:
O(log n) gần như nằm sát O(1) khi n có giá trị lớn.
6. So sánh tốc độ tăng
Giả sử n tăng từ 1 → 1,000,000:
| n | log₂(n) | n |
|---|---|---|
| 8 | 3 | 8 |
| 1,024 | 10 | 1,024 |
| 1,000,000 | ~20 | 1,000,000 |
Khi n = 1 triệu thì log₂(n) ≈ 20. Tăng cực kỳ chậm.
7. Vì sao O(log n) tốt?
Nếu một thuật toán có:
O(log n)
Nghĩa là:
- Input tăng gấp đôi
- Runtime chỉ tăng thêm 1 đơn vị
Đó là lý do tại sao các thuật toán dạng này được xem là rất hiệu quả.
8. Log xuất hiện ở đâu?
Bạn sẽ gặp O(log n) trong:
Thuật toán tìm kiếm
Ví dụ: Binary Search
Mỗi lần chia đôi dữ liệu → log₂(n)

Thuật toán sắp xếp hiệu quả
Một số thuật toán tốt có:
O(n log n)

Đệ quy (Recursion)
Đặc biệt liên quan đến space complexity

VI. Điều quan trọng nhất cần nhớ
Bạn không cần tính log chính xác.
Bạn chỉ cần hiểu:
O(log n) tốt hơn rất nhiều so với O(n)
Và khi so sánh hai thuật toán:
- Thuật toán A: O(log n)
- Thuật toán B: O(n)
→ A hiệu quả hơn khi n lớn.
Tổng kết toàn bộ phần Big O
- Big O đo xu hướng tăng trưởng, không quan tâm chi tiết nhỏ, chỉ quan tâm khi n rất lớn
- Big O đo Time Complexity và Space Complexity
- Không phụ thuộc vào máy tính. Big O không đo mili giây thật sự. Nó đo số lượng thao tác theo xu hướng.
- Các độ phức tạp phổ biến: O(1), O(log n), O(n), O(n log n), O(n²)
VII. Tổng kết
Bài viết này đã dài quá rồi, nhưng mà nó đã đi qua hết những khái niệm cơ bản nhất khi bạn tìm hiểu về DSA.
Mình mong rằng bài viết này sẽ cho bạn cái nhìn tổng quát và dễ hiểu trước khi bắt đầu giải các bài toán thật sự.
Và đó là mình NekoArcoder, hẹn gặp lại bạn ở các bài viết sau, see yaaaaa!

All rights reserved
