Bí Mật Tốc Độ Của Elasticsearch: Giải Phẫu Inverted Index (Chỉ Mục Đảo)
Ở những bài trước, chúng ta đã chê bôi thậm tệ câu query LIKE '%keyword%' trong SQL và tôn vinh Exact Match (=). Nhưng thực tế phũ phàng là: Người dùng luôn thích gõ tìm kiếm một cách "mơ hồ". Họ nhớ mang máng một đoạn văn, một cái tên sản phẩm, và họ muốn tìm ra nó.
Nếu hệ thống của bạn là một trang tin tức, blog, hay E-commerce với hàng triệu sản phẩm, ép user dùng Exact Match là tự sát. Bạn phải cung cấp tính năng Full-text Search (Tìm kiếm toàn văn bản). Và "vị thần" cai quản mảng này trong thế giới Backend chính là Elasticsearch.
Tại sao Elasticsearch có thể lục tung hàng chục triệu bài viết để tìm ra một từ khóa chỉ trong vài chục mili-giây, trong khi MySQL phải "rặn" cả phút? Bí mật nằm ở một cấu trúc dữ liệu thiên tài: Inverted Index (Chỉ Mục Đảo).
Chắc anh em từng trải qua cảm giác này: Mở file PDF tài liệu dài 1000 trang, bấm Ctrl + F, gõ từ "Microservices", và máy tính khựng lại 5 giây để quét từ trang 1 đến trang 1000. Đó chính là cách Database truyền thống (như MySQL) quét dữ liệu bằng câu lệnh LIKE '%Microservices%'. Nó phải lục lọi từng bản ghi một (Forward Index / Full Table Scan).
Nhưng hãy nhớ lại cách bạn tra cứu sách giấy hồi xưa. Bạn muốn tìm phần nói về "Microservices" trong một cuốn sách dày cộp? Bạn lật ngay ra phần Phụ Lục (Index) ở cuối sách. Bạn dò theo bảng chữ cái đến vần M, thấy chữ Microservices, bên cạnh nó ghi: Trang 45, 112, 890. Bạn lật đúng 3 trang đó là xong!
Đó chính xác là cách Inverted Index (Chỉ Mục Đảo) hoạt động.
1. Inverted Index là gì? Sự lật ngược thế cờ
Thay vì lưu trữ theo tư duy thông thường: ID Bài Viết -> Chứa những từ nào. Inverted Index lật ngược lại: Từ khóa -> Nằm ở những ID Bài Viết nào.
Hãy tưởng tượng bạn có 3 tài liệu (Documents) trong hệ thống:
- Doc 1: Hoàng code dạo
- Doc 2: Hoàng sửa bug
- Doc 3: Code dạo sửa bug
Khi bạn insert 3 tài liệu này vào Elasticsearch, nó không lưu nguyên cục. Nó sẽ mang đi "băm nát" ra (quá trình này gọi là Analysis/Tokenization). Sau khi băm, nó lập ra một cuốn danh bạ (Inverted Index) như sau:
| Term (Từ khóa) | Nằm ở Document ID |
|---|---|
| Hoàng | [1, 2] |
| code | [1, 3] |
| dạo | [1, 3] |
| sửa | [2, 3] |
| bug | [2, 3] |
Bây giờ, user lên thanh tìm kiếm gõ chữ bug. Elasticsearch không cần đi đọc lại nội dung của 3 tài liệu kia. Nó chọc thẳng vào cuốn danh bạ, tìm chữ bug, và ngay lập tức lấy ra được mảng [2, 3]. Tốc độ là O(1), chớp mắt là có kết quả!
2. Trải nghiệm trực quan: Máy Quét Inverted Index
Để hiểu rõ hơn sự kỳ diệu của cấu trúc này khi tìm kiếm nhiều từ khóa cùng lúc, mời bạn thử gõ vào thanh tìm kiếm của bộ giả lập Inverted Index dưới đây nhé:
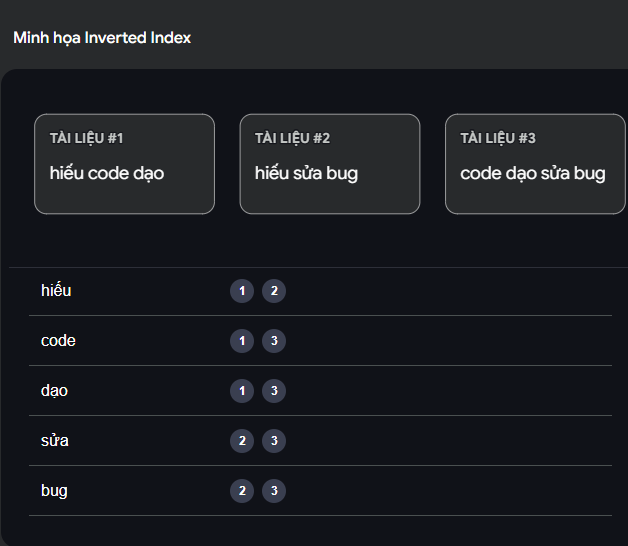
3. Bí thuật của "Máy Xay" (Analyzer)
Nếu Inverted Index chỉ đơn giản là tách khoảng trắng rồi lưu lại thì nó chưa đủ tầm làm "Trùm" tìm kiếm. Sức mạnh thực sự của Elasticsearch nằm ở cỗ máy băm thịt mang tên Analyzer.
Trước khi một từ được đưa vào danh bạ Inverted Index, nó phải đi qua các bước lọc cực kỳ gắt gao:
- Character Filters: Gọt bỏ thẻ HTML (VD:
<b>Hoàng</b>->Hoàng). - Tokenizer: Tách câu thành các từ đơn (Token).
- Token Filters (Cực kỳ quan trọng): * Lowercasing: Biến mọi chữ hoa thành chữ thường (Hoàng -> Hoàng).
-
Stop words: Xóa bỏ những từ vô nghĩa, xuất hiện quá nhiều nhưng không mang lại giá trị tìm kiếm (VD trong tiếng Việt: `là`,` của`, `và`, `thì`, `mà`...). -
Stemming: Cắt bỏ hậu tố, đưa từ về dạng gốc (VD tiếng Anh: `running`, `ran`, `runs` đều quy về một chữ run).
Nhờ cỗ máy xay này, danh bạ Inverted Index của bạn cực kỳ "sạch" và tối ưu dung lượng. Người dùng gõ "Running", máy xay thành "run", chọc vào danh bạ tìm chữ "run" và trả về kết quả chính xác!
4. Vibe Coder Mindset: Không có bữa trưa miễn phí (Trade-offs)
Làm hệ thống là nghệ thuật của sự đánh đổi. Inverted Index mang lại tốc độ tìm kiếm bàn thờ (Read), nhưng đổi lại, bạn phải trả giá cực đắt ở khâu Ghi (Write).
Mỗi khi bạn INSERT hoặc UPDATE một bài viết mới, Elasticsearch phải chạy lại toàn bộ quy trình: Băm văn bản -> Chạy qua Analyzer -> Mở Inverted Index ra -> Cập nhật thêm Document ID vào từng từ khóa tương ứng. Quá trình này tốn rất nhiều CPU và RAM.
Đó là lý do TUYỆT ĐỐI KHÔNG DÙNG ELASTICSEARCH ĐỂ LÀM DATABASE CHÍNH (Primary DB) cho các tác vụ thay đổi liên tục (như số dư tài khoản, trạng thái giao hàng). Vibe Coder sẽ dùng MySQL/PostgreSQL làm chân lý gốc (lưu trữ và ghi nhanh), sau đó đồng bộ (Sync) dữ liệu văn bản sang Elasticsearch chỉ để phục vụ riêng cho API Tìm kiếm.
Lời kết
Hiểu được Inverted Index, bạn sẽ không còn coi Elasticsearch như một "hộp đen" ma thuật nữa. Bất cứ khi nào bạn thiết kế tính năng Search cho ứng dụng, hãy hình dung về cuốn danh bạ phía sau cuốn sách, và bạn sẽ biết cách "prompt" cho Elasticsearch làm việc một cách tối ưu nhất.
Chủ đề tiếp theo: Ma Thuật Fuzzy Search - Gõ "Híeủ codẹ dạp" Vẫn Tìm Ra Kết Quả
Inverted Index tìm kiếm rất nhanh, nhưng nó có một điểm yếu: Nó đòi hỏi từ khóa trong danh bạ phải khớp hoàn toàn với từ bạn gõ (sau khi đã qua máy xay).
Nếu danh bạ lưu chữ hiếu, mà người dùng lại lỡ tay gõ sai chính tả thành heếu hoặc híeủ, thì Inverted Index sẽ bó tay và trả về 0 kết quả. Trải nghiệm người dùng lúc này sẽ rất tệ!
Làm sao để hệ thống có thể "bao dung" cho những lỗi đánh máy ngớ ngẩn của khách hàng? Làm sao để Google biết bạn gõ sai và hỏi "Có phải bạn muốn tìm..."? Ở bài viết tới, mình sẽ đàm đạo về Fuzzy Search (Tìm kiếm mờ) và thuật toán Levenshtein Distance (Khoảng cách chỉnh sửa) trong Elasticsearch. Anh em nhớ đón đọc nhé!
All rights reserved
