
Bạn đang ở level nào trong SQL
Bài đăng này đã không được cập nhật trong 2 năm
Chúng mình có tạo Group cho các bạn cùng chia sẻ và học hỏi về thiết kế hệ thống nha 😄😄😄
Các bạn tham gia để gây dựng cộng đồng System Design Việt Nam thật lớn mạnh nhé 😍😍😍
Cộng Đồng System Design Việt Nam: https://www.facebook.com/groups/sydexa
Kênh TikTok: https://www.tiktok.com/@sydexa.com
Bắt đầu cuộc dạo của chúng ta ngay thôi nào
Đừng chỉ dừng hành trình SQL của bạn với JOIN.
Các cấp độ của SQL
Về cấp độ, tôi chia kiến thức SQL được chia ra làm 6 giai đoạn.

- Very Basic: gồm các lệnh select, from, where
- Basic: gồm các lệnh group by và having
- Beginners: lệnh join, left/right/outer/inner/self join.
- Intermediate: Subqueries.
(Hầu hết mọi người dừng ở giai đoạn 4- intermediate 🤣🤣🤣. Giai đoạn 5 có thể giúp bạn cải thiện đáng kể khả năng viết những câu truy vấn phức tạp (complex queries). Điều này xảy ra do 95% các trường hợp, nó đủ với một backend CRUD cơ bản. Hôm nay ta sẽ vượt qua khoảng cách từ 4 đến 5, tức là từ Intermediate tới Advanced.)
- Advanced: Làm việc với CTEs (Common Table Expressions), window functions, lệnh partition by.
Nội dung ở cấp độ ‘Pro’ cũng rất hay và hữu ích.
- Pro
- Đọc một chiến lược thực thi.
- Cách indexes hoạt động (Không chỉ là việc CREATE INDEX trên mỗi cột).
- Một hiểu biết sâu rộng về cách DB hoạt động.
Tại sao ta cần biết SQL?
Viết truy vấn SQL là một trong những công cụ tuyệt vời, hữu ích nhất mà một manager cần có, vì 3 lý do chính sau:
-
Bạn có thể trả lời câu hỏi kinh doanh. Kĩ năng này vô cùng giá trị cho sự gắn kết giữa bạn với những người từ phía thương mại.
-
Hầu hết các thiết kế kỹ thuật bắt đầu với dữ liệu. Mặc dù bạn không cần khả năng viết truy vấn ở cấp độ cao để tạo và hiểu ERD, nhưng nó vẫn có thể giúp bạn hiểu được tình huống chính xác và DB cũng như cách mọi thứ được kết nối với nhau.
-
Tỉ lệ effort/benefit lớn. SQL rất dễ thành thạo. Đó có thể là kỹ năng ‘Át chủ bài’ của bạn, trở thành người tiếp cận những câu hỏi/truy vấn phức tạp.
Thử viết một vài câu lệnh SQL đơn giản
Tôi giả sử rằng các bạn đã quen thuộc với các câu lệnh cơ bản, joins, subqueries.
Ví dụ dưới đây dựa trên một bảng đơn với 5 cột, có kiểu dữ liệu đơn giản. Bảng này đại diện cho các ưu đãi của khách hàng trên các khu vực khác nhau.
CREATE TABLE deals (
deal_id INT PRIMARY KEY,
deal_amount DECIMAL(10, 2),
customer_name VARCHAR(255),
region VARCHAR(255),
deal_date DATE
);
Ta có 20 dòng dữ liệu như dưới đây: Ta tiến hành chèn 20 dòng dữ liệu vào trong bảng trên
INSERT INTO deals
(deal_id, deal_amount, customer_name, region, deal_date)
VALUES
(1, 25000.00, 'Acme Corporation', 'North America', '2023-01-15'),
(2, 25000.00, 'Globex Corporation', 'North America', '2023-01-20'),
(3, 12500.00, 'Acme Corporation', 'North America', '2023-02-11'),
(4, 30000.00, 'Initech', 'Europe', '2023-03-22'),
(5, 20000.00, 'Hooli', 'Europe', '2023-03-27'),
(6, 20000.00, 'Vehement Capital Partners', 'Europe', '2023-04-05'),
(7, 15000.00, 'Massive Dynamic', 'North America', '2023-04-15'),
(8, 15000.00, 'Soylent Corp', 'Asia', '2023-05-01'),
(9, 17000.00, 'Initech', 'Europe', '2023-05-20'),
(10, 15000.00, 'Pied Piper', 'Asia', '2023-06-03'),
(11, 7500.00, 'Globex Corporation', 'North America', '2023-06-25'),
(12, 8000.00, 'Pied Piper', 'Asia', '2023-07-12'),
(13, 17000.00, 'Hooli', 'Europe', '2023-07-18'),
(14, 12000.00, 'Soylent Corp', 'Asia', '2023-08-02'),
(15, 9000.00, 'Massive Dynamic', 'North America', '2023-08-21'),
(16, 23000.00, 'Vehement Capital Partners', 'Europe', '2023-09-11'),
(17, 3000.00, 'Pied Piper', 'Asia', '2023-09-30'),
(18, 40000.00, 'E Corp', 'North America', '2023-10-05'),
(19, 35000.00, 'E Corp', 'North America', '2023-10-20'),
(20, 6000.00, 'Hooli', 'Europe', '2023-11-04');
Ta bắt đầu với các truy vấn con:
SELECT deal lớn nhất trong mỗi khu vực.
-
Lời giải ngây thơ (naive solution)
SELECT * FROM deals d1 WHERE d1.deal_amount = ( SELECT MAX(d2.deal_amount) FROM deals d2 WHERE d2.region = d1.region );- Vấn đề ở đây là truy vấn con tham chiếu đến một cột của truy vấn bên ngoài. Điều này khiến cho truy vấn con phải thực hện một lệnh cho mỗi hàng ở bảng bên ngoài, nó có thể rất chậm.
-
Cách giải quyết:
- Ta có thể tạo truy vấn con tốt hơn nhưng tôi muốn giới thiệu CTE - Common Table Expression. Một CTE là một bảng tạm thời, nó trông như sau:
WITH max_deals_by_region AS ( SELECT region, MAX(deal_amount) AS max_deal_amount FROM deals GROUP BY region ) SELECT d.* FROM deals d JOIN max_deals_by_region rmd ON d.region = rmd.region AND d.deal_amount = rmd.max_deal_amount; - CTE được định nghĩa bằng mệnh đề WITH, theo sau đó là CTE name và sau dó là truy vấn để tạo ra CTE. Sau khi định nghĩa xong có thể chọn CTE như bảng bình thường trong cơ sở dữ liệu.
- Ta có thể tạo truy vấn con tốt hơn nhưng tôi muốn giới thiệu CTE - Common Table Expression. Một CTE là một bảng tạm thời, nó trông như sau:
-
Tại sao nó hữu ích?
- CTE không cho một khả năng mới (nghĩa là ta có thể giải quyết vấn đề với một truy vấn con thích hợp), nó chỉ hỗ trợ ta viết truy vấn tốt hơn:
- Khi sử dụng CTEs, ta không bị rơi vào bẫy truy vấn con liên quan, nó buộc ta phải suy nghĩ về cách giải quyết vấn đề một cách chính xác.
- Nó cải thiện khả năng dễ đọc của câu truy vấn.
- CTE không cho một khả năng mới (nghĩa là ta có thể giải quyết vấn đề với một truy vấn con thích hợp), nó chỉ hỗ trợ ta viết truy vấn tốt hơn:
Điều thú vị hơn nằm ở dưới đây!!!
Ta sẽ thử sức với câu truy vấn khó hơn một chút.
Select top 3 deals trong mỗi khu vực.
WITH ranked_deals AS (
SELECT
deal_id, deal_amount, customer_name, region, deal_date,
RANK() OVER (PARTITION BY region ORDER BY deal_amount DESC) AS deal_rank
FROM deals
)
SELECT deal_id, deal_amount, customer_name, region, deal_date
FROM ranked_deals
WHERE deal_rank <= 3
ORDER BY region, deal_rank;

Ta nhận được 11 bản ghi, trong khi đó chỉ có 3 khu vực, đáng ra là 9 bản ghi thôi chứ? Ta sẽ hiểu tại sao có điều này sớm thôi!
- Vậy
rank/over/partitionlà những câu lệnh gì mà thú vị như vậy?RANK()là một window function. Window function cho phép ta thực hiện các tính toán trên một tập các hàng liên quan tới hàng hiện tại. Một Windows Function được định nghĩa khi có mệnh đềOVER()đi kèm sau lệnh gọi hàm.- Để tạo ra tập hợp các hàng liên quan, chúng ta sử dụng từ khóa
PARTITION BY, chia dữ liệu thành các nhóm. Hiểu đơn giản, Aggregate function cóGROUP BYthì Window function cóPARTITION BY. - Lệnh
ORDER BYcho phép chúng ta sắp xếp các hàng trong mỗi nhóm.
Các kiểu window function
Có 3 kiểu chính:
- Ranking functions
- Aggregate functions
- Positional functions
1. Ranking Window Functions.
- Giống như cái tên của nó, họ xếp hạng các hàng trong mỗi phân vùng. Các Ranking function chính là:
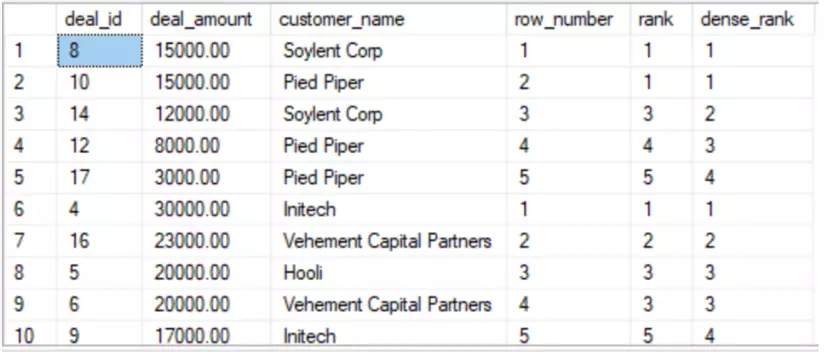
ROW_NUMBER(): Xếp hạng các giá trị trong từng partition theo thứ tự tăng dần mà không quan tâm đến giá trị giống nhau. Ví dụ: row_number (): 1,2,3,4,5RANK(): Xếp hạng các giá trị theo thứ tự tăng dần nhưng sẽ trả về thứ hạng giống nhau với các giá trị giống nhau và bỏ qua thứ hạng đó. Ví dụ: rank(): 1,1,3,4,5DENSE_RANK(): Xếp hạng các giá trị theo thứ tự tăng dần nhưng sẽ trả về thứ hạng giống nhau với các giá trị giống nhau và không bỏ qua thứ hạng đó. Ví dụ: dense_rank (): 1,1,2,3,4
SELECT deal_id, deal_amount, customer_name,
ROW_NUMBER() OVER (PARTITION BY region ORDER BY deal_amount DESC)
AS row_number,
RANK() OVER (PARTITION BY region ORDER BY deal_amount DESC)
AS rank,
DENSE_RANK() OVER (PARTITION BY region ORDER BY deal_amount DESC)
AS dense_rank
FROM deals
ORDER BY region, deal_amount DESC;
2. Aggregation Window Functions.
- Rất giống với GROUP BY nhưng có một ưu điểm rất lớn là có thể giữ toàn bộ dữ liệu của mỗi dòng.
- Có thể sử dụng tất cả những cái quen thuộc như: SUM(), AVG(), MAX(),…
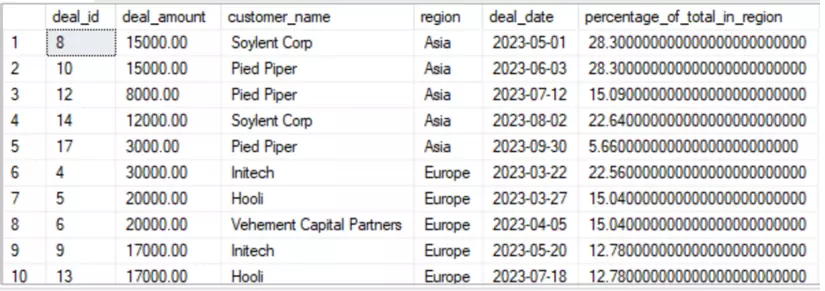
Với mỗi deal, tính % deal trong mỗi khu vực.
SELECT
deal_id, deal_amount, customer_name, region, deal_date,
ROUND((deal_amount / SUM(deal_amount) OVER (PARTITION BY region)) * 100, 2) AS percentage_of_total_in_region
FROM deals
ORDER BY region, deal_date;
3. Positional Window Functions
- Các hàm này trả về một giá trị từ một hàng cụ thể trong mỗi window frame. Ví dụ:
LEAD(): Trả về một giá trị từ một hàng đằng sau hàng hiện tại trong phân vùng.LAG(): Trả về một giá trị từ hàng trước hàng hiện tại trong phân vùng.FIRST_VALUE(): Trả về giá trị đầu tiên trong phân vùng.LAST_VALUE(): Trả về giá trị cuối cùng trong phân vùng.
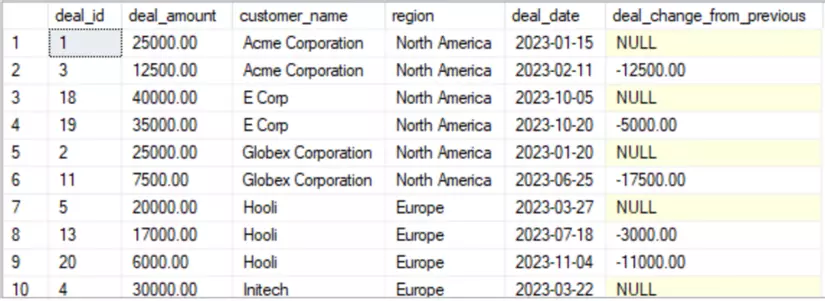
Đối với mỗi deals, tính toán sự thay đổi về deal_amount so với deals trước đó của cùng một khách hàng trong cùng khu vực.
SELECT deal_id, deal_amount, customer_name, region, deal_date,
deal_amount - LAG(deal_amount)
OVER (PARTITION BY customer_name, region ORDER BY deal_date)
AS deal_change_from_previous
FROM deals
ORDER BY customer_name, region, deal_date;
Sydexa.com xin hẹn gặp lại các bạn ở các bài viết thú vị hơn nha
Lời nhắn
Chúng mình có tạo Group cho các bạn cùng chia sẻ và học hỏi về thiết kế hệ thống nha 😄😄😄
Các bạn tham gia để gây dựng cộng đồng System Design Việt Nam thật lớn mạnh nhé 😍😍😍
Cộng Đồng System Design Việt Nam: https://www.facebook.com/groups/sydexa
Kênh TikTok: https://www.tiktok.com/@sydexa.com
All rights reserved
