Bài toán hồi quy và mô hình hồi quy tuyến tính
Bài đăng này đã không được cập nhật trong 7 năm
Mình lại quay trở lại với series Machine Learning, Deep Learning cho người bắt đầu
Bài toán hồi quy (Regression)
- a. Mô hình Hồi quy tuyến tính (Linear Regression Model)
-
Bài toán đơn giản
Trước khi nhắc đến những công thức toán học dài dòng tôi muốn mô phỏng một bài toán đơn giản cho bạn dễ hình dung trước.
Một hôm đẹp trời, tôi sử dụng ứng dụng Grab để đặt 1 chuyến đi từ nhà tôi đến Bờ Hồ Hoàn Kiếm dài 5km nhưng xui thay ứng dụng này mất khả năng tính toán thành tiền và bác xe ôm đen đủi không thể biết được số tiền chính xác mà tôi cần phải trả.
May mắn thay, tôi vẫn còn truy cập được vào lịch sử các chuyến đi của mình như bảng bên dưới, liệu rằng dựa trên những thông tin này tôi có thể tính được số tiền mà tôi cần trả cho 5km ngày hôm nay?
Số Km (Km) Số tiền cần trả (1000 VND) 2 13 7 35 9 41 3 19 10 45 6 28 1 10 8 55 Giả sử Số KM tôi đi và số tiền cần trả Grab phụ thuộc tuyến tính vào nhau, tức là số KM tăng thì số tiền cần trả Grab tăng hoặc số KM giảm thì số tiền cần trả Grab giảm, tôi có thể tìm ra được 1 hàm biểu thị được mối quan hệ giữa 2 đại lượng này không? Câu trả lời là Có.
Tại sao lại cần tìm ra hàm đó? Vì nếu tìm ra được nó, việc tôi cần làm chỉ thay số KM tôi đi ngày hôm nay vào hàm và tìm ra được số tiền tôi cần trả.
Tôi đặt: - X là số Km tôi đi - Y là số tiền cần trả Grab
Hàm cần tìm sẽ có dạng Y= aX + b. Bài toán quy về: Với X và Y cho trước trên bảng trên, tìm 2 tham số a và b.
Biểu thị data bằng đồ thị
Bài toán của chúng ta là phải đi tìm hàm F thể hiện được mối quan hệ giữa Y và X có dạng Y= aX + b. Chú ý X và Y đều là ma trận/vector.
-
Định nghĩa
Trong thống kê, hồi quy tuyến tính là một phương pháp dùng để mô hình hóa mối quan hệ giữa một đại lượng vô hướng với một hoặc nhiều biến độc lập.
Các dạng của mô hình hồi quy tuyến tính:
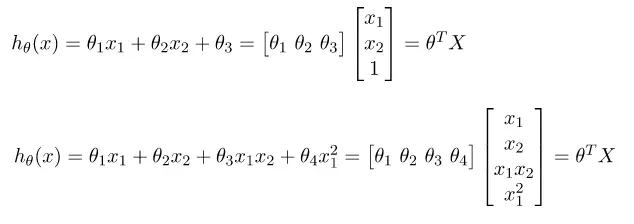
Công thức tổng quát:
-


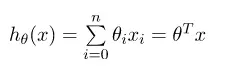
-
b. Hàm mất mát (Loss Function)
- Định nghĩa
Hàm mất mát trả về một số không âm thể hiện mức độ chênh lệch giữa giá trị mà model của chúng ta dự đoán và giá trị thực tế.
- Ordinary Least Squares
Mức độ chênh lệch như chúng ta nhắc bên trên chính là tất cả các đường màu xanh được biểu diễn dưới đây. Ta sẽ có một hàm thể hiện trung bình tổng các đại lượng sai lệch.
Công thức:
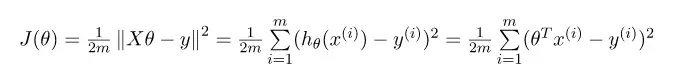
Vậy để hàm F càng xấp xỉ data của chúng ta thì hàm
</a> chúng ta phải đạt giá trị nhỏ nhất theo **
**.
-
c. Thuật toán tối ưu Loss Function (Optimization Algorithms)
- Normal Equation
Một liên tưởng đơn giản, như chúng ta học từ cấp 3, cách đơn giản nhất để tìm giá trị nhỏ nhất của một hàm số (cực tiểu), ta sẽ cho đạo hàm bằng 0 và tìm
.
-
Công thức toán học
Tìm đạo hàm của
Một chút biến đổi:
Chúng ta đơn giản hàm bằng cách bỏ đi
vì cuối cùng chúng ta cũng cho đạo hàm bằng 0.
Chú ý vì
và
đều là vector nên khi chúng ta nhân chúng lại với nhau, vị trí của chúng trong tích không quan trọng nữa. Cho nên:
Cho nên:
Tiến hành đạo hàm:
Tương đương:
Giả sử
có thể nghịch đảo, chuyển vế ta có:
- Điểm mạnh: Công thức đơn giản và chỉ cần đổ data vào tính toán
- Điểm yếu: Tài nguyên để tính toán ma trận nghịch đảo với lượng data lớn là rất tốn kém nên trong thực tế các bài toán hồi quy tuyến tính rất ít khi sử dụng phương pháp này
-
Gradient Descent
Thay vì sử dụng công thức ăn liền Normal Equation, thì trong thực tế chúng ta sẽ sử dụng thuật toán Gradient Descent. Giải thích một cách đơn giản, chúng ta sẽ cho
giảm dần đến giá trị cực tiểu.
Như bạn có thể thấy trên hình: Lúc ban đầu hàm
-
Công thức toán học
- Diễn giải công thức toán:
Tương đương với:
Nếu bạn đã từng lập trình thì có thể tinh tế nhận ra cách tính toán này. Chúng ta sẽ tạo ra một vòng lặp và qua mỗi vòng lặp đó ta sẽ gán giá trị mới cho
-
Chú ý:
được gọi là một hyper hyper parameters. Nó sẽ được đặt bởi một giá trị cho trước. Ví dụ mình hay đặt sử dụng 0.01 hoặc 0.0001. Ý nghĩa của nó là một tham số quyết định tốc độ học nhanh hay chậm của mô hình.
-
Nếu
-
Nếu
-
-
Điểm mạnh
Tính toán nhẹ nhàng hơn rất nhiều so với phương pháp ban đầu. Về sau chúng ta sẽ tìm hiểu các phương thức khác kết hợp với Gradient Descent để giảm nhẹ khối lượng tính toán.
-
Điểm yếu
Kết quả thường không chính xác 100%, nhiều vấn đề liên quan xảy ra ví dụ như giá trị của hàm Loss không thể giảm thêm mà bị mắc kẹt tại một điểm local nào đó. (Như hình mình họa bên trên)
Có rất nhiều phương pháp để giải quyết vấn đề này, tôi sẽ trình bày ở các bài tiếp theo.
-
-
d. Bài toán thực tế
-
Bài Toán Grab
-
- Mô phỏng data
Số Km (Km) Số tiền cần trả (1000 VND) 2 13 7 35 9 41 3 19 10 45 6 28 1 10 8 55 Ta sẽ phải mô phỏng data này bằng code.
Gọi Số KM là
và số tiền cần phải trả là
. Gọi
là hàm chúng ta sẽ dự đoán.
Việc chúng ta cần phải làm là tìm
Mô phỏng X0:
X0 = np.array([[2], [7], [9], [3], [10], [6], [1], [8]])Tạo X: X là một ma trận kích thước (8, 2) được ghép bởi X0 kích thước (8, 1) và một vector ones kích thước (8, 1) tất cả các giá trị là 1.
ones = np.ones_like(X0) # Nối 2 vector/ma trận theo chiều dọc X = np.concatenate((X0, ones), axis=1)Giá trị của X sẽ là:
array([[ 2, 1], [ 7, 1], [ 9, 1], [ 3, 1], [10, 1], [ 6, 1], [ 1, 1], [ 8, 1]])Mô phỏng Y:
Y = np.array([[13], [35], [41], [19], [45], [28], [10], [55]])Giá trị của Y sẽ là:
array([[13], [35], [41], [19], [45], [28], [10], [55]])Sử dụng matplotlib mô phỏng các dữ liệu với hàm
plt.scatter(X_begin,Y); plt.show() -
- Sử dụng phương pháp Normal Equation.
Tính trực tiếp
# API np.linalg.inv() dùng để tính ma trận nghịch đảo theta = np.linalg.inv(X.T.dot(X)).dot(X.T.dot(Y))Chúng ta sẽ tính ra được kết quả của
array([[4.40880503], [5.39937107]])Vậy
Miêu tả dạng này:
# See how it fits: plt.scatter(X_begin, Y) plot_polynomial(0, 10, theta) plt.show()Chúng ta có thể thấy hàm
-
- Sử dụng phương pháp Gradient Descent.
Khởi tạo
theta_gd = np.random.normal(size=2).reshape([2,1])Giá trị của
array([[-1.31237748], [ 0.22471167]])Đặt learning Rate
learning_rate = 0.02Tạo hàm tính gradient theo công thức
def grad_cal(X, Y, theta_gd, m): """ X: X's value Y: Y's value theta_gd: theta's value m: number of samples """ g = 1/m * X.T.dot(X.dot(theta_gd) - Y) return g.reshape(theta_gd.shape)Tạo hàm tính loss function theo công thức :
def loss(X, Y, theta_gd, m): """ X: X's value Y: Y's value theta_gd: theta's value m: number of samples """ return 1/(2*m) * np.sum((X.dot(theta_gd) - Y)**2)Tiến hành tạo vòng lặp, qua mỗi vòng lặp sẽ tính lại gradident đồng thời cập nhật lại
for i in range(10000): grad_value = grad_cal(X, Y, theta_gd, m) theta_gd = theta_gd - learning_rate*grad_value print(loss(X, Y, theta_gd, m))Giá trị của hàm Loss:
890.0619039221115 33.23288932117509 19.912233421433992 19.674950415271216 19.640872759091934 19.61022229452672 19.579897901246316 19.54984900715867 19.520072377582952 19.49056553425761Chúng ta có thể thấy lúc đầu khi
Ở vòng lặp cuối cùng 10000 giá trị
[[4.40880503] [5.39937107]]Vậy hàm
Biểu diễn hàm:
Chúng ta có thể thấy trong bài toán này, hai kết quả ra tương đồng nhau.
-
- Dự đoán
Như 2 phương pháp trên chúng ta đã nắm được dạng hàm của
def predict(X): return X.dot(theta)a. Tôi muốn dự đoán số tiền phải trả khi tôi đi mất 20km
# Chú ý: luôn phải nối 1 vào bên phải của vector đầu vào giống như ta đã training. X_new_1 = np.array([[20, 1]]) predict(X_new_1)Ta thu được kết quả:
[[93.5754717]] -> Số tiền cần phải trả chính là 93.5754717 (đơn vị 1000 đồng)b. Tôi muốn dự đoán số tiền phải trả khi tôi đi mất 40km
X_new_2 = np.array([[40, 1]]) predict(X_new_2)[[181.75157233]] -> Số tiền cần phải trả chính là 93.5754717 (đơn vị 1000 đồng)
-
-
Bài toán đo lường Hiệu quả sản xuất
- Vấn đề
- Giải quyết bằng mô hình Hồi quy tuyến tính
-







Đang cập nhật, mời các bạn đón đọc trong phần sau của series Machine Learning, Deep Learning cho người bắt đầu
All rights reserved
