
[B5'] - Tìm hiểu về BlazePose: On-device Real-time Body Pose tracking
Bài đăng này đã không được cập nhật trong 5 năm
Giới thiệu về bài toán Pose Estimation
Bài toán Pose Estimation là một trong những bài toán phổ biến trong xử lý ảnh. Chúng ta đã từng có những nghiên cứu rất thành công trước đây trong lĩnh vực này như OpenPose, PoseNet. Một điểm quan trọng cần cải thiện của các mô hình này đó chính là cải thiện tốc độ xử lý. Trong paper này các tác giả của Google AI Research đã đề xuất một kiến trúc có thể chạy được realtime trên các thiết bị di động với tốc độ xử lý khoảng 30FPS. Chúng ta sẽ cùng tìm hiểu về kiến trúc mạng cũng như cách thức mà BlazePose thực hiện để đạt được kết quả như trên nhé.
Tìm hiểu cách Blaze Pose thực hiên tracking
Tổng quan về kiến trúc
BlazePose bao gồm hai thành phần chính là:
- Pose Detector: Để detect ra vùng chứa person trên bức ảnh
- Pose Tracker: Để trích xuất ra các keypoints trên vùng chứa vị trí của person đã được crop ra từ bức ảnh đồng thời dự đoán vị trí của person trong next frame.
Trong trường hợp đầu vào là video thì detector sẽ chỉ chạy trong một số keyframe và vị trí của person sẽ được tracking trong các frame sau đó. Việc tracking này thực hiện bởi mô hình Pose Tracker
Phần Pose Detector
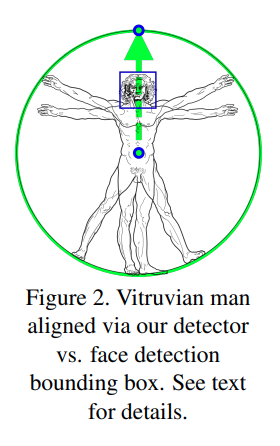
Trong bài báo thay vì detect toàn thân thì tác giả sử dụng bộ detect khuôn mặt cùng với điểm giữa hông của người hiện tại, kích thước của vòng tròn bao quanh toàn bộ người, góc nghiêng (góc được đo bởi đường thẳng nối bởi điểm giữa hông - điểm giữa vai với phương thẳng đứng). Đây là một bộ detector đơn giản và light-weight
![]()
Từ các thông tin detect được thì detector tiến hành alignment để xoay person theo phương thẳng đứng.
Phần Pose Tracker để tracking
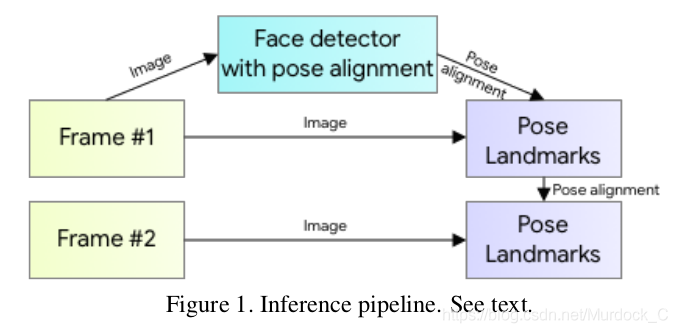
Trong bài báo này tác giả tiếp cận theotư tưởng, đó là nếu như pose tracker có thể dự đoán được vị trí của person trong next frame thì Pose Detector sẽ không cần phải chạy lại nữa và sẽ luôn luôn sử dụng kết quả dự đoán của pose tracker và chỉ detect lại khi tracker dự đoán sai (dưới một ngưỡng nào đó). Luồng hoạt động như sau
Mạng Pose Tracking được chia làm hai phần đó là Keypoints Detection Part và Keypoints Regression Part như hình bên đưới
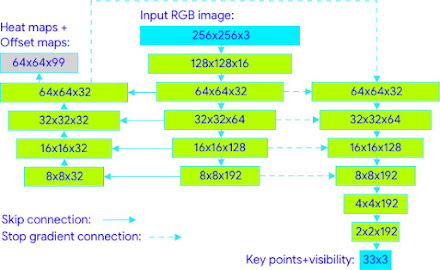
Đầu tiên tác giả training mạng bên trái và ở giữa trước sử dụng heatmap and offset loss. Sau đó phần regression bên phải sẽ được training bằng việc share feature với mạng detector (không thực hiện back propagate mà chỉ share feature). Khi tésting tác giả sẽ bỏ đi hoàn toàn detection part và chỉ giữ lại phần regression. Đầu ra của mạng này sẽ bao gồm 33 keyponts và 2 điểm sử dụng để alignment được mô tả phía trên phần Pose Detector
Cách BlazePose thực hiện smooth landmarks
Cách mà BlazePose thực hiện smooth landmarks
Phương pháp này không được đề cập trong paper gốc của BlazePose tuy nhiên có thể tham khảo phương pháp sử dụng trong thư viên mediapipe. Trong thư viên này người ta sử dụng tracking dựa trên vận tốc (velocity). Nếu như vận tốc vượt quá một ngưỡng threshold nhất định thì sẽ tiến hành detect lại. Hàm tính vận tốc được định nghĩa tại đây
Nhưng smooth landmarks sẽ chỉ thực hiện khi ở mode tracking tức là static_image_mode=False bởi trong static mode chúng ta đã giả định các ảnh truyền vào không có liên quan gì đến nhau (có thể là 1 batch các ảnh thuộc nhiều background, context khác nhau). Nên ở static_mode thì bắt buộc phải thực hiện cả hai mô hình Pose Detect và Pose Tracker tại mỗi ảnh trong batch. Nên tham số smooth_landmarks sẽ bị ignore
Ý nghĩa các tham số trong thư viện Mediapipe
static_image_mode (boolean)
- Trường hợp static_image_mode=True:: Trong trường hợp tham số này được đặt bằng
Truetrong trường hợp chúng ta coi các hình ảnh đầu vào là một loạt ảnh tĩnh hoặc có thể là những hình ảnh không liên quan đến nhau trong cùng 1 batch. Lúc này mô hình detect person sẽ chạy trên mọi frame mà không có tracking - Trường hợp static_image_mode=False: Trong trường hợp tham số này được đặt bằng
Falsethì thuật toán sẽ coi input đầu vào là một luồng video. Lúc này thuật toán thực hiện detect vị trí của person trong frame chỉ thực hiện tại một số key frame. Sau khi đã có vị trí của person trên keyframe thì các frame sau đó sẽ sử dụng thuật toán tracking để tracking vị trí đó mà không phải detect lại. Đến khi nào output của model tracking dưới một ngưỡng nhất định (quy định bởi tham sốmin_tracking_confidence) thì việc detect person mới được thực hiện lại.
smooth_landmarks (boolean)
Tham số này chỉ có tác dụng với trường hợp static_image_mode=False tức là trong trường hợp đầu vào là một luồng video và có thực hiện tracking. Ở mode static_image_mode=True thì smooth_landmarks sẽ bị ignore
- Trường hợp smooth_landmarks = True: trong trường hợp này thì thuật toán filter landmarks sẽ được thực hiện trên các điểm keypoints để làm giảm độ rung của các keypoints. Giúp vị trí của các keypoint được stable qua các frame
- Trường hợp smooth_landmarks = False: không áp dụng thuật toán filter landmarks.
min_detection_confidence (float in [0.0, 1.0])
Giá trị tối thiểu để mô hình detect person được coi là detect thành công. Nếu output của mô hình dưới ngưỡng này thì coi như không detect được keypoints. Giá trị mặc định là 0.5
min_tracking_confidence (float in [0.0, 1.0])
Giá trị tối thiểu để mô hình tracking được coi là tracking thành công. Nếu output của mô hình tracking dưới ngưỡng này thì có thể coi như việc tracking đã thất bại (không còn truy vết được person nữa) và lúc đó sẽ thực hiện việc detect lại vị trí của person trong frame tiếp theo. Giá trị này nếu được đặt cao thì sẽ tăng tính chính xác của mô hình nhưng lại làm giảm đi thời gian tính toán (do có nhiều lần phải detect lại person). Giá trị mặc định là 0.5
Ứng dụng
BlazePose được sử dụng rộng rãi trong các ứng dụng như fitness hay yoga tracker. Ví dụ dưới dây là đếm số lượng squat và chống đẩy

All rights reserved
