[AWS] Export data từ RDS sang S3 sử dụng Glue
Bài đăng này đã không được cập nhật trong 4 năm
AWS Glue
AWS Glue là dịch vụ tích hợp dữ liệu server-less, giúp người dùng dễ dàng tìm kiếm, chuẩn bị và tổng hợp dữ liệu cho hoạt động phân tích, máy học và phát triển ứng dụng. AWS Glue cung cấp tất cả các chức năng cần thiết cho quá trình tích hợp dữ liệu để bạn có thể bắt đầu phân tích và đưa dữ liệu chỉ trong ít phút. Ở đây chúng ra có một database sử dụng dịch vụ RDS của AWS (hoặc Aurora), và sử dụng AWS Glue để đọc, tổng hợp dữ liệu, từ đó có thể gửi các dữ liệu này đến các nơi lưu trữ khác như S3, Redshift,...
1 Xây dựng môi trường chứa RDS database
1.1 Tạo VPC, subnet, internet gateway và route table
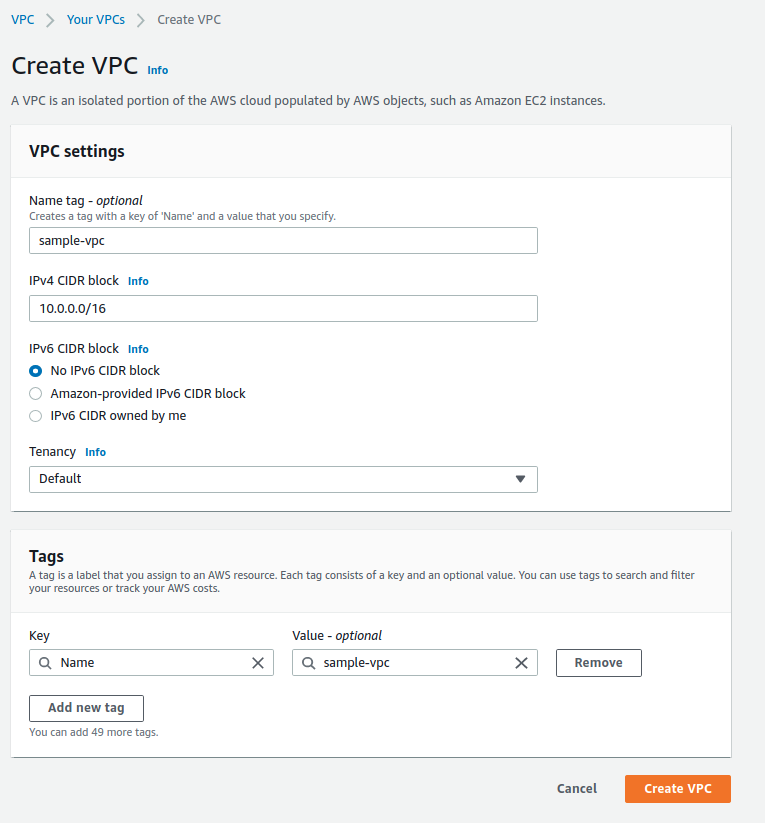
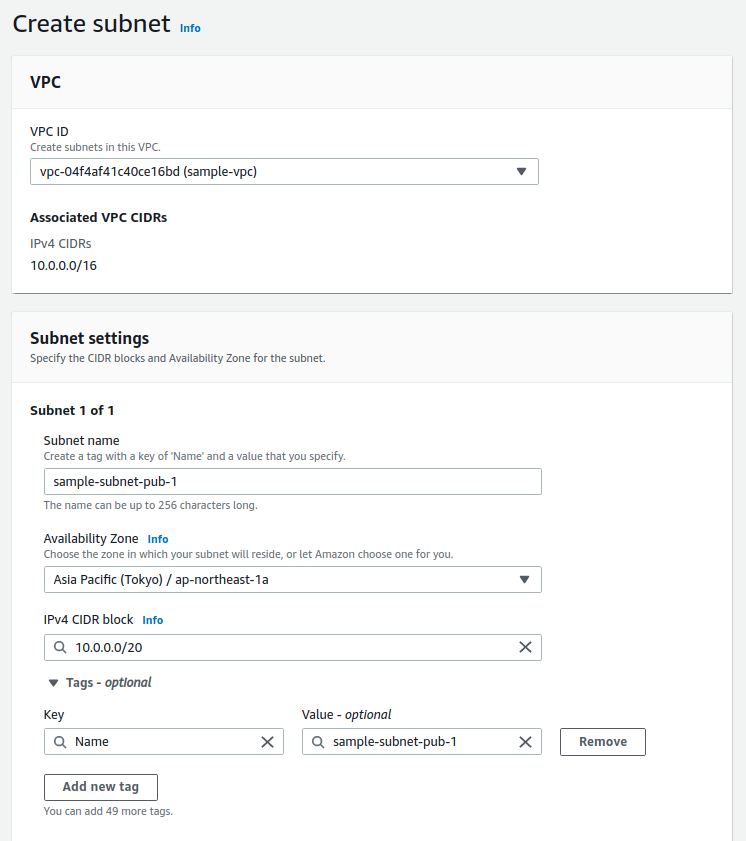
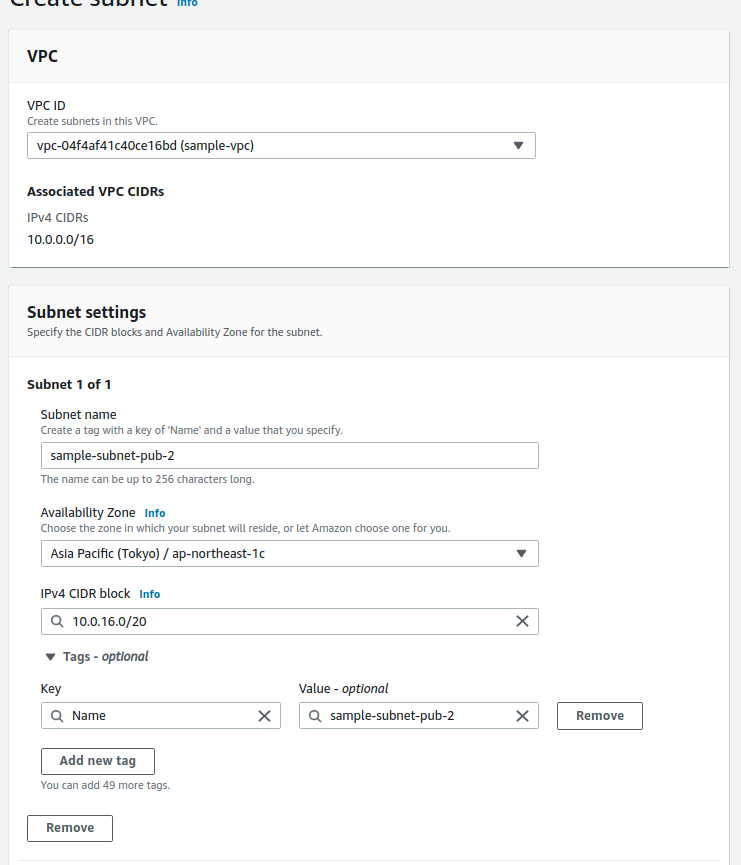
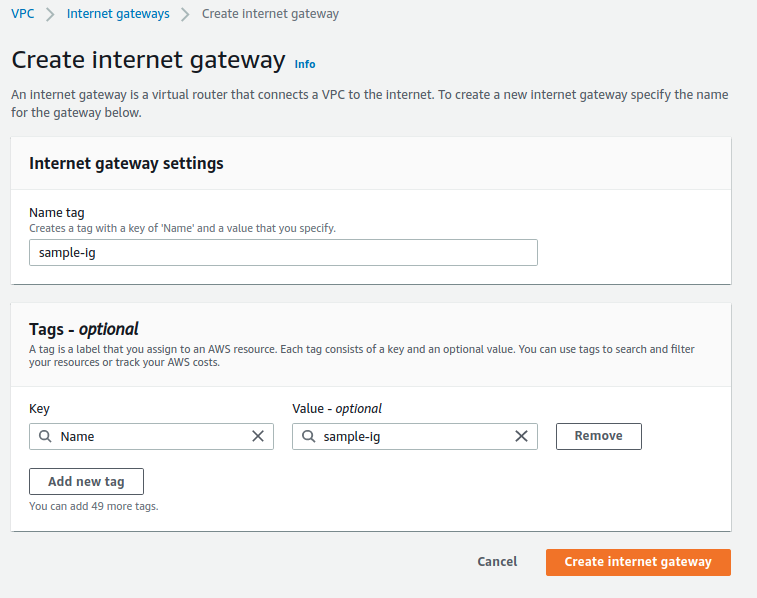
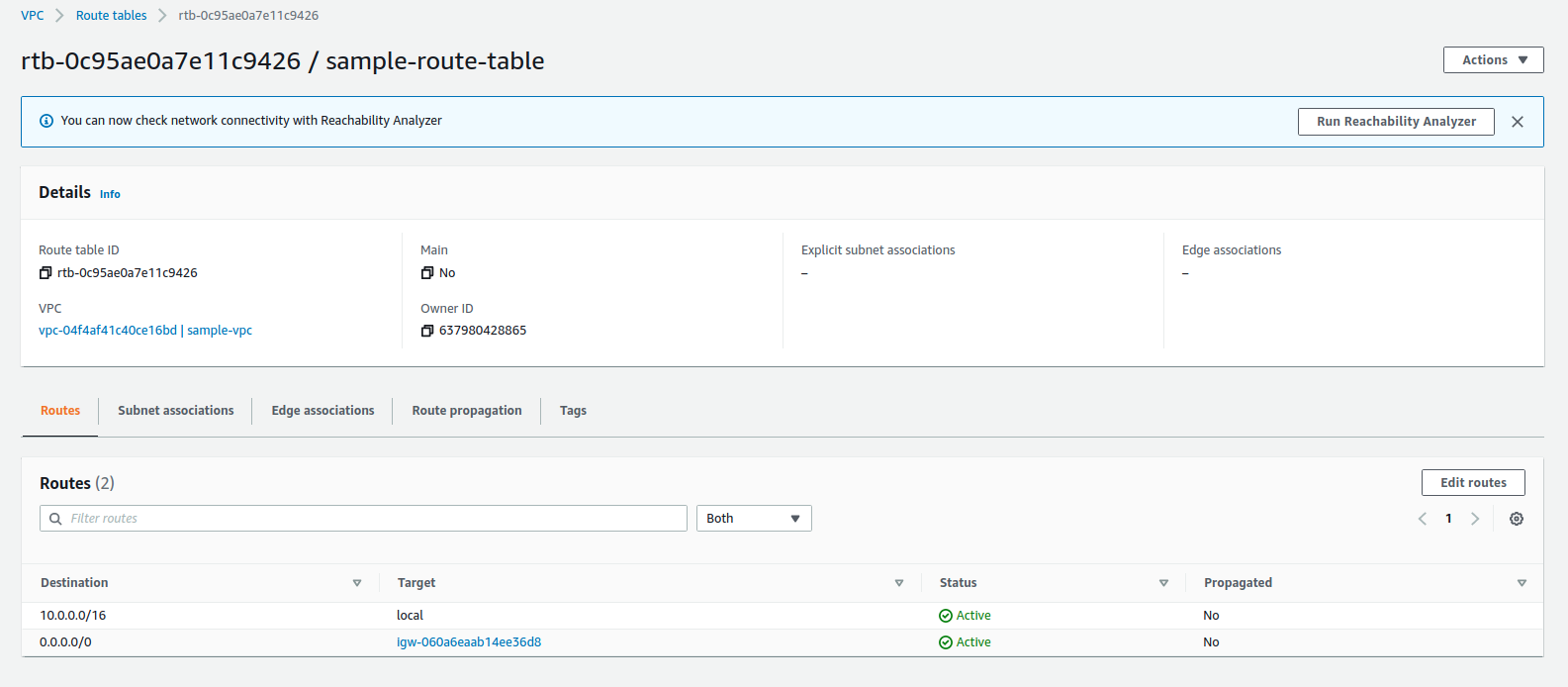

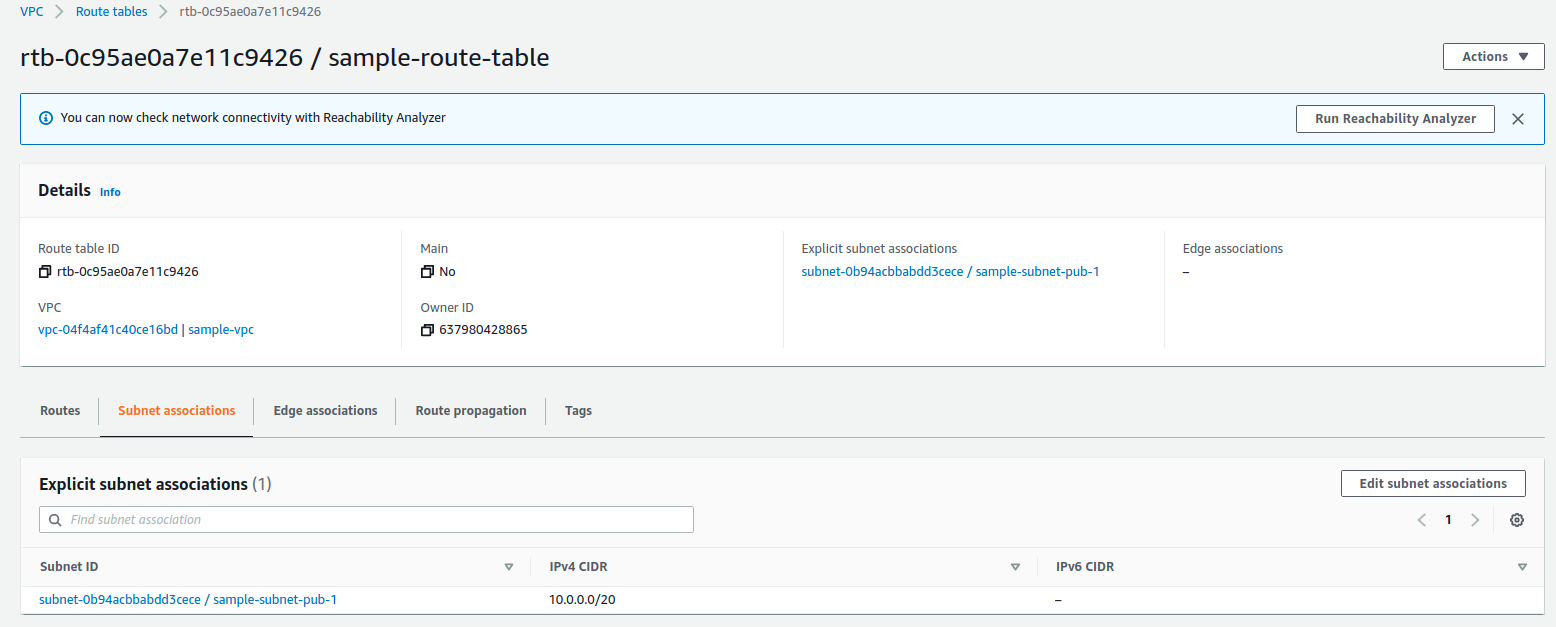
1.2 Tạo Security group để gắn vào database RDS
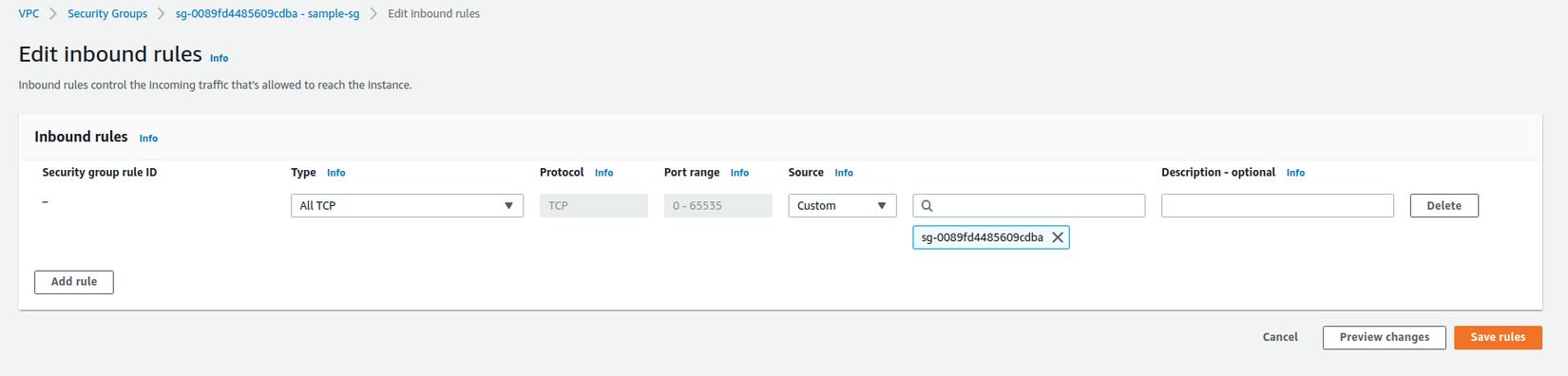
Sau khi tạo sercurity group, thêm một self reference để glue có thể truy cập RDS
2 Tạo database RDS
- Chọn MySql 5.x . Hiện tại Glue chưa hỗ trợ MySQL 8, có thể tham khảo cách config ở topic này https://stackoverflow.com/questions/56240778/aws-glue-unable-to-connect-to-mysql
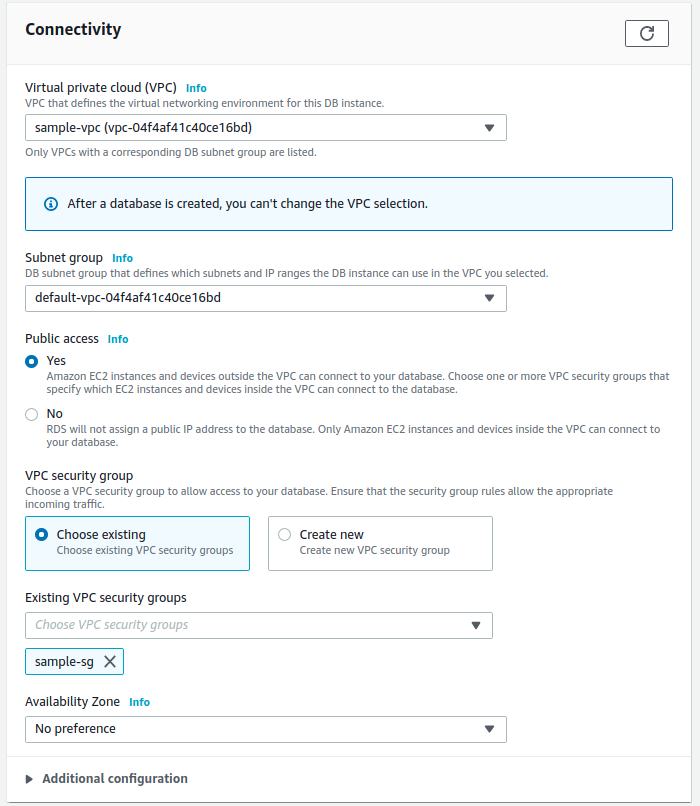
- Chọn VPC và Security Group đã tạo ở mục 1, set public access để phục vụ việc fake data
- Tạo dữ liệu mẫu
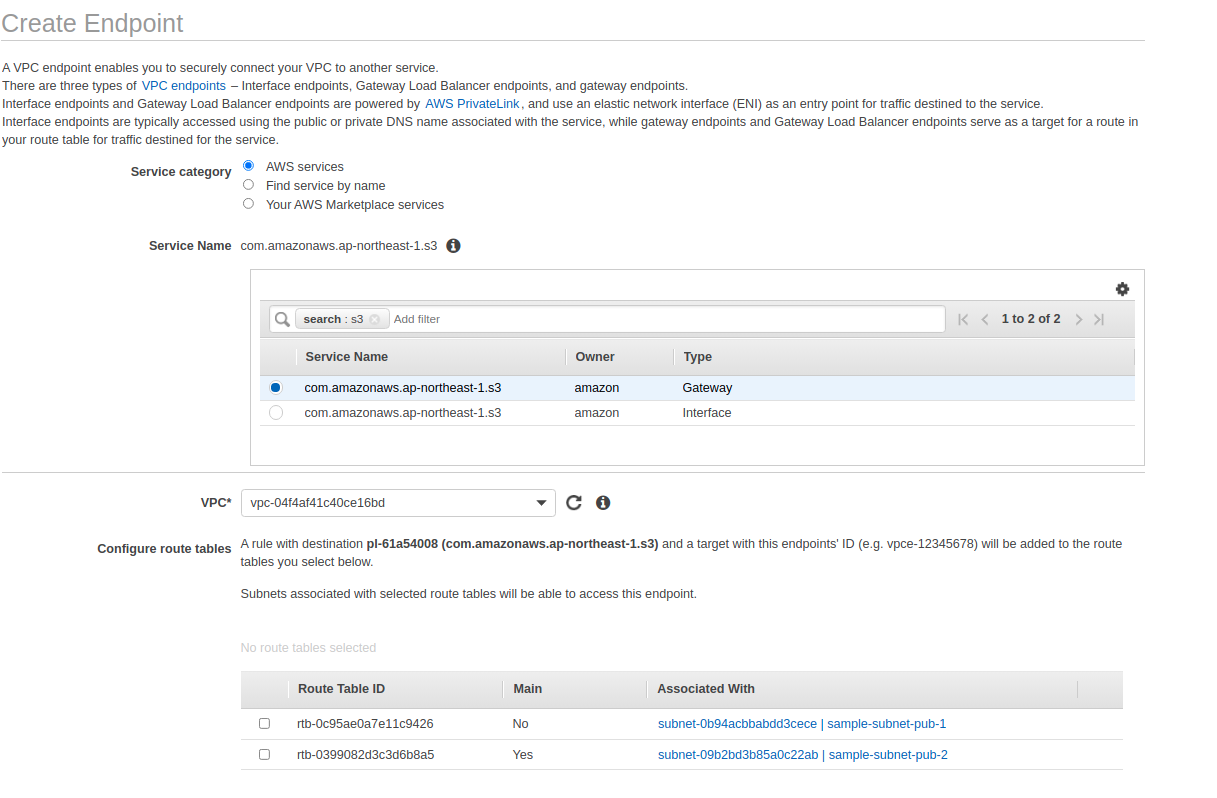
- Tạo một VPC Endpoint với service type là S3 gateway
![image.png]()
3 Tạo các service ở AWS Glue
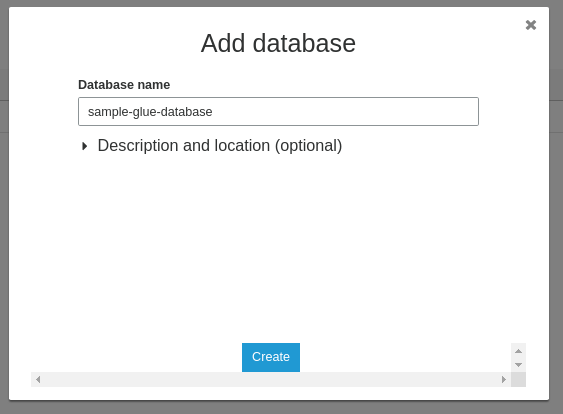
3.1 Tạo Glue database
- Vào Glue > Databases > Create. Đây sẽ là nơi chứa dữ liệu được craw từ RDS trước khi export sang các service khác như S3, Redshift
3.2 Tạo Glue connection
- Tạo connection đến database RDS để Glue có thể truy cập vào và đọc dữ liệu
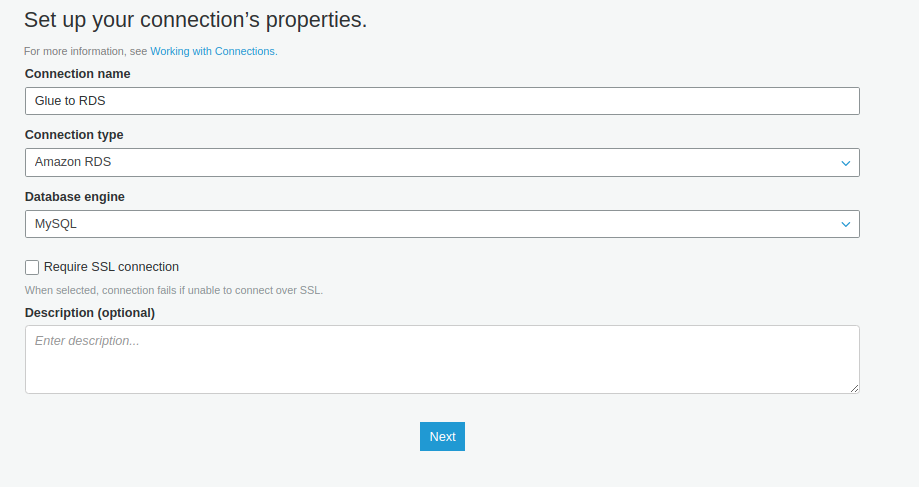
- Data store là RDS instance đã tạo trước đó
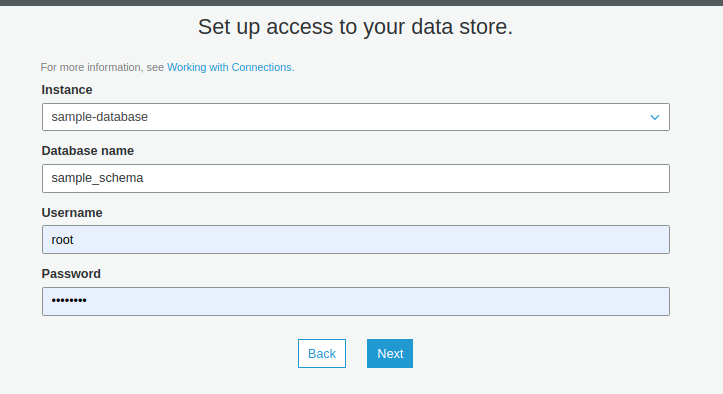
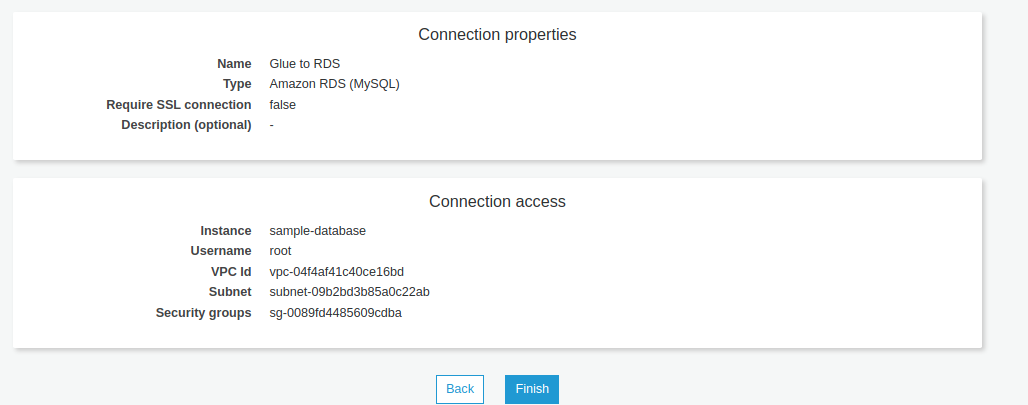
3.3 Tạo Glue table để lưu dữ liệu bằng Glue crawler
- Vào Glue > Databases > Tables > Add tables using a arawler
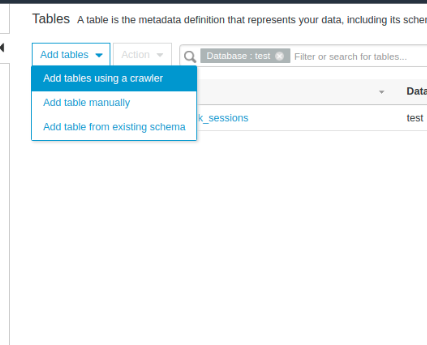
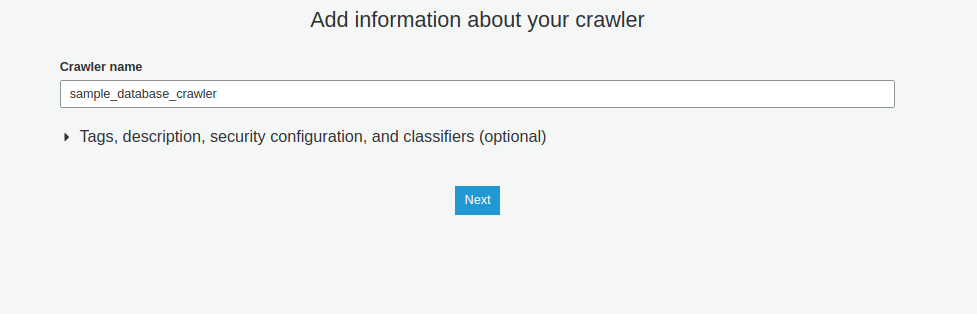
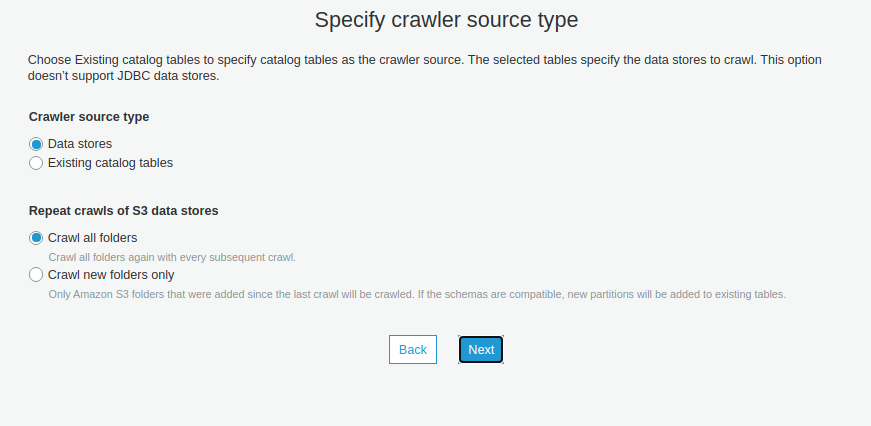
- Chọn connection là connection đã tạo ở 3.2, include path là <Tên database trong RDS>/< Tên table muốn lấy dữ liệu>
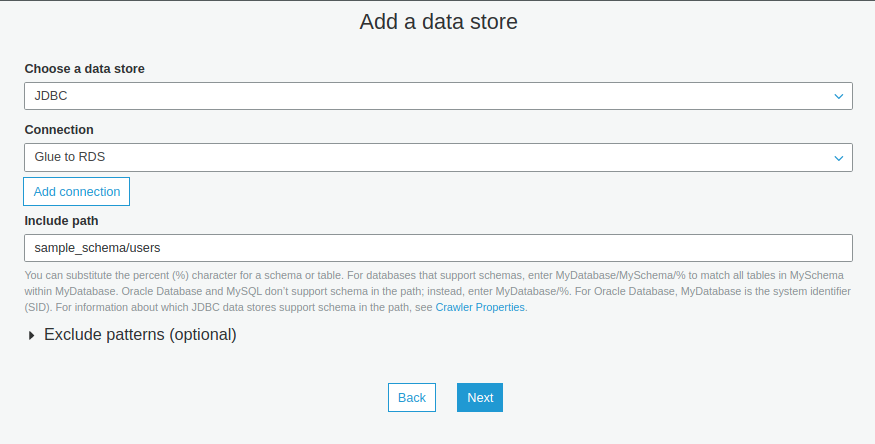
- Tạo một IAM role với policy là AmazonS3FullAccess và AWSGlueServiceRole
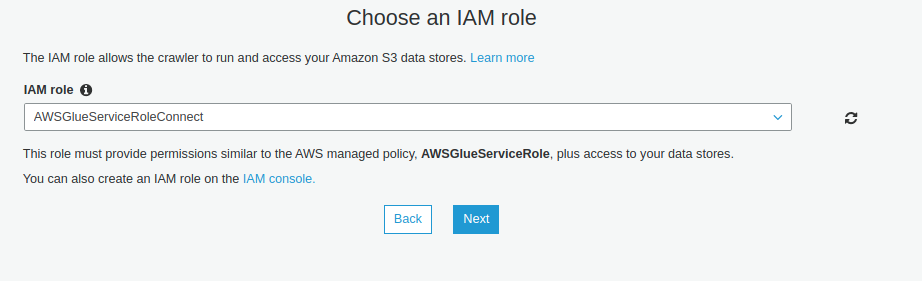
-
Đặt lịch chạy cho crawler, có thể đặt Run on demand (khi nào bấm nút thì chạy), custom (cron syntax), hằng ngày, hằng tuần, hằng tháng ...
![image.png]()
-
Chọn Glue database
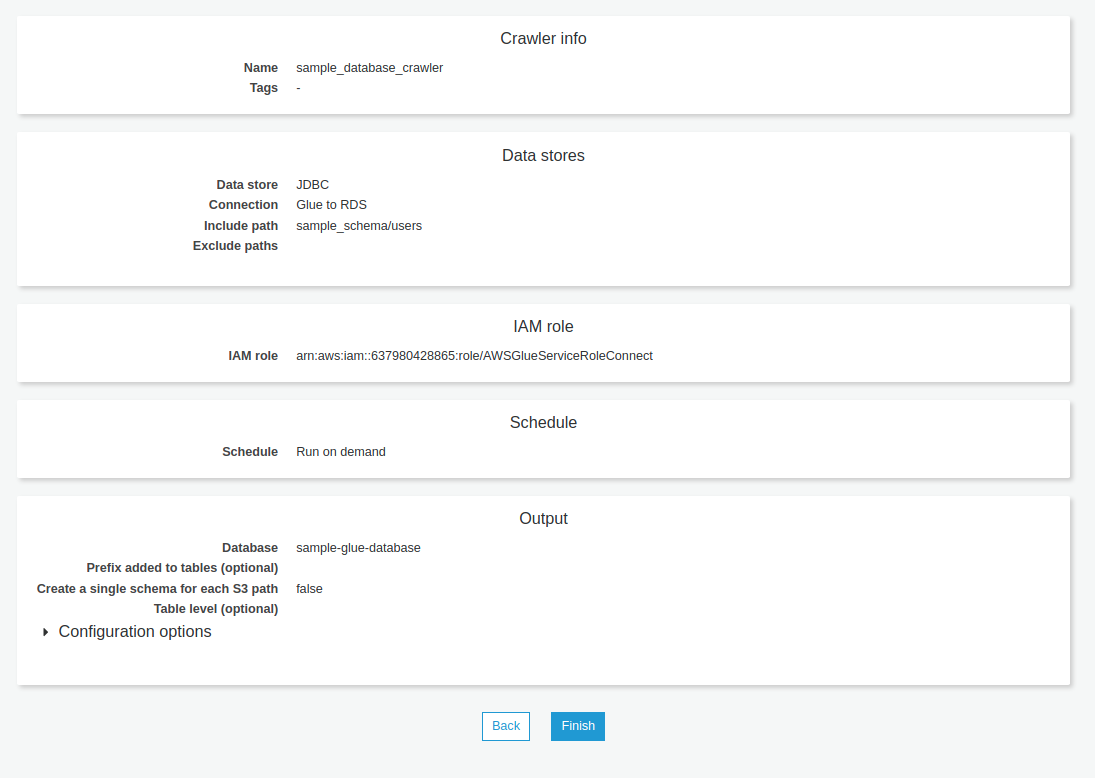
- Nhấn finish và bạn sẽ được chuyển hướng đến trang list crawler, tại đây, nhấn nút Run crawler để chạy crawler
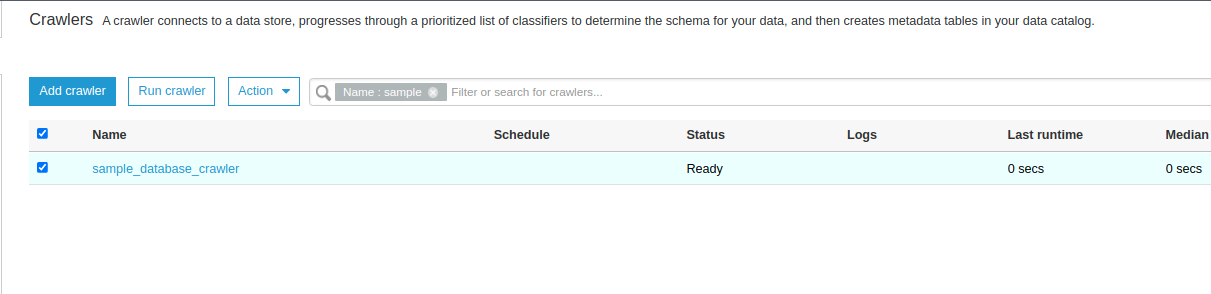
- Thông báo chạy thành công

- Vào Glue > Databases > Tables sẽ thấy một table đã được tạo với tên là <Tên database RDS> _ <Tên bảng được crawl ở RDS>

3.4 Tạo S3 Bucket để lưu trữ file export
3.5 Tạo Glue Job để export dữ liệu từ Glue Database lên S3
- Vào Glue > Jobs > Add
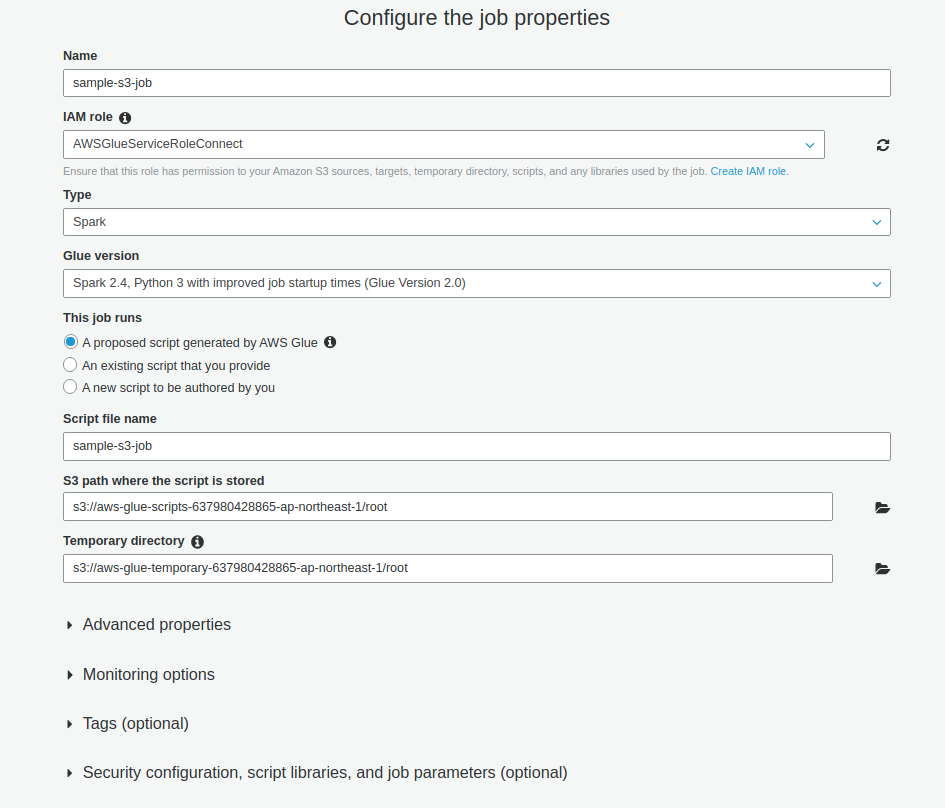
- Chọn data source là Glue table đã tạo bằng crawler trước đó

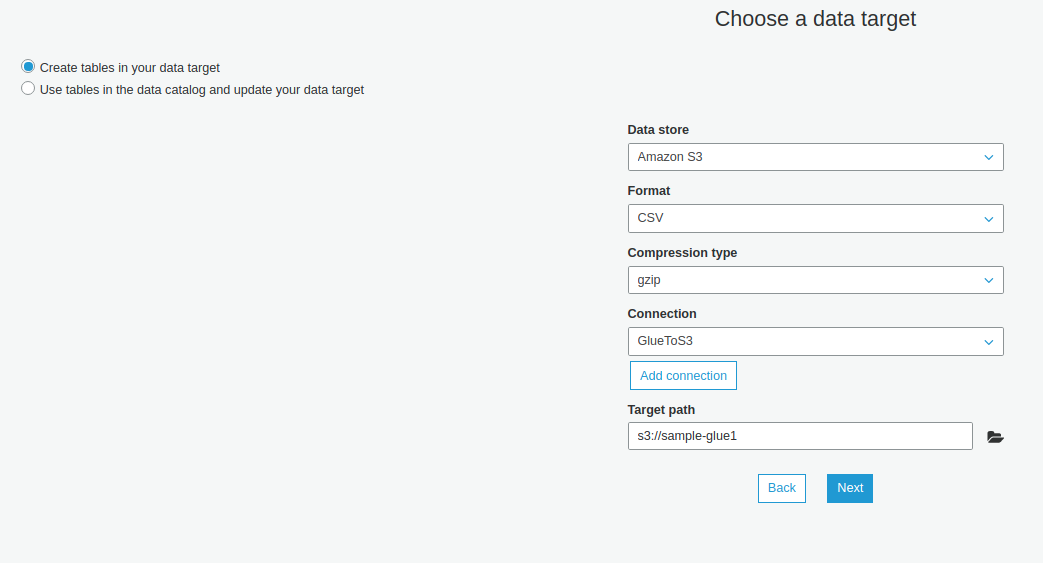
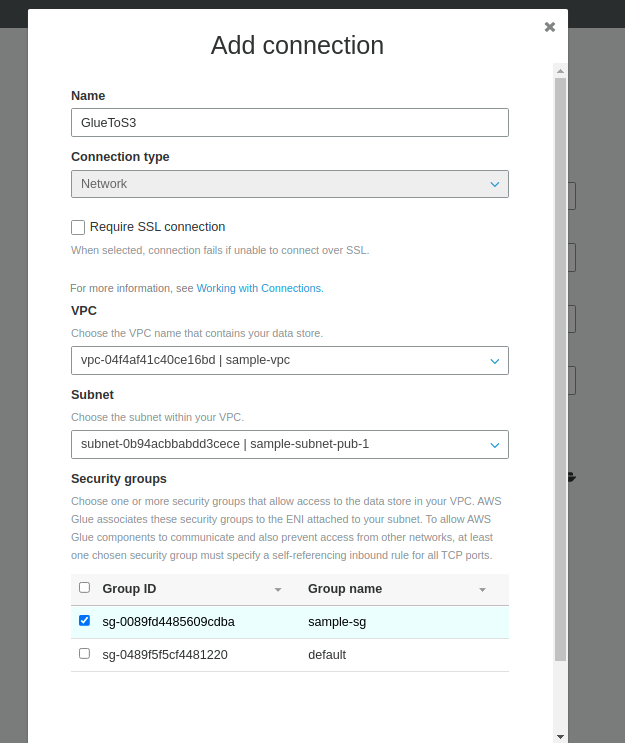
- Chọn các cột cần export
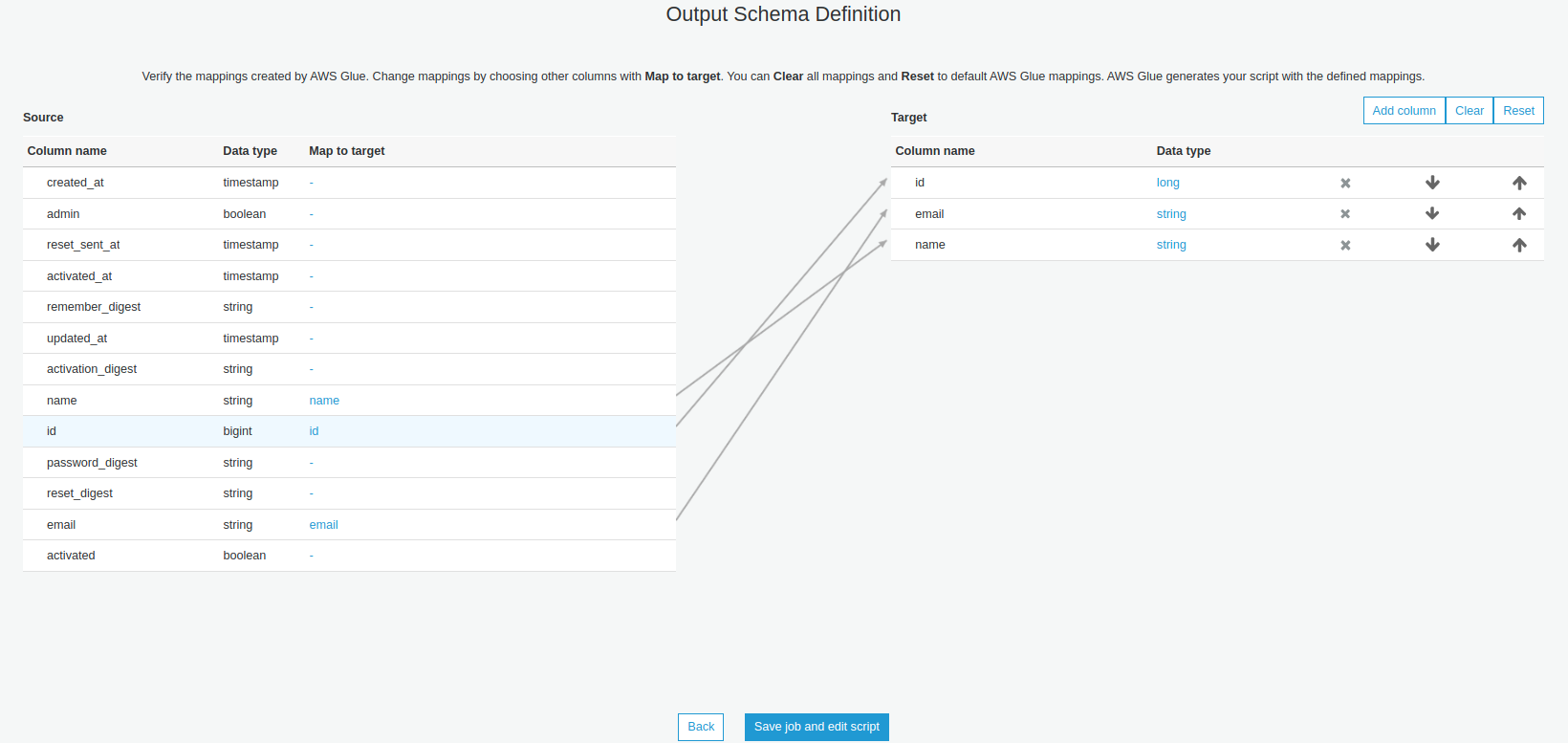
-
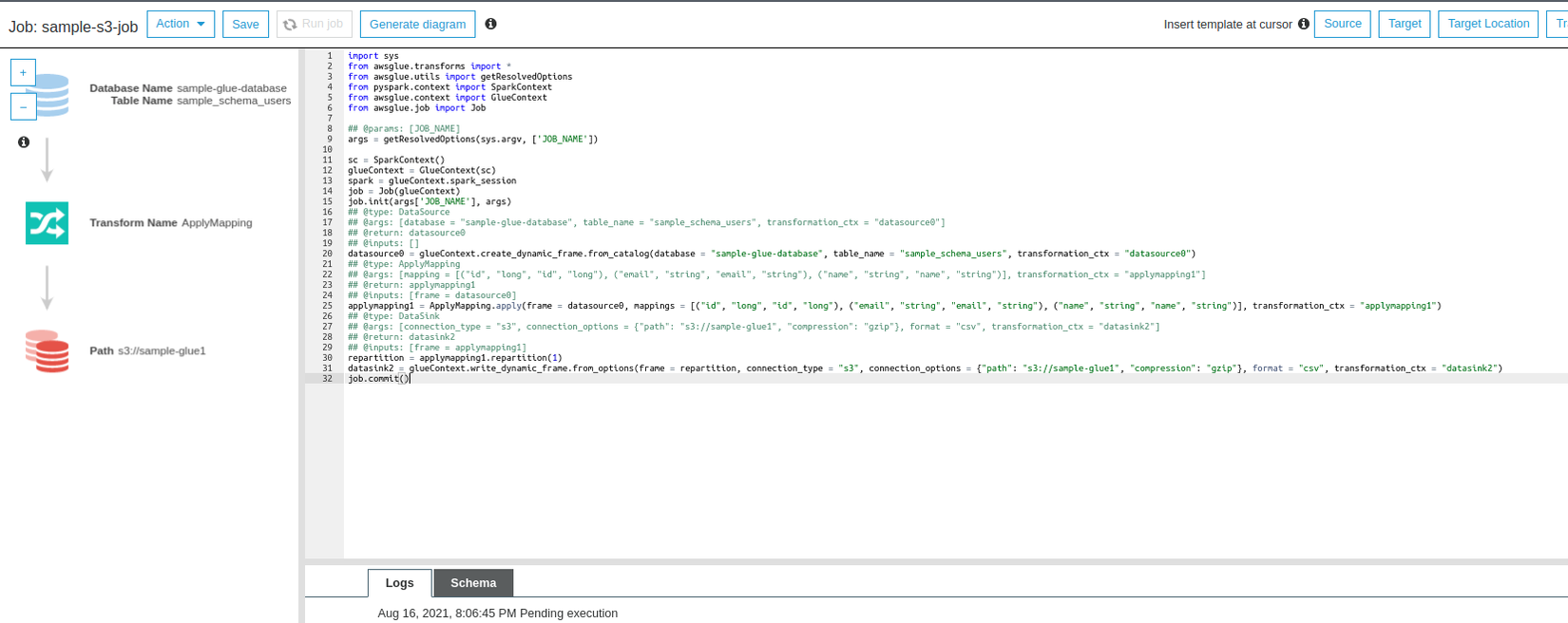
Một script sẽ được sinh ra, nhấn nút Run job để chạy job
![image.png]()
-
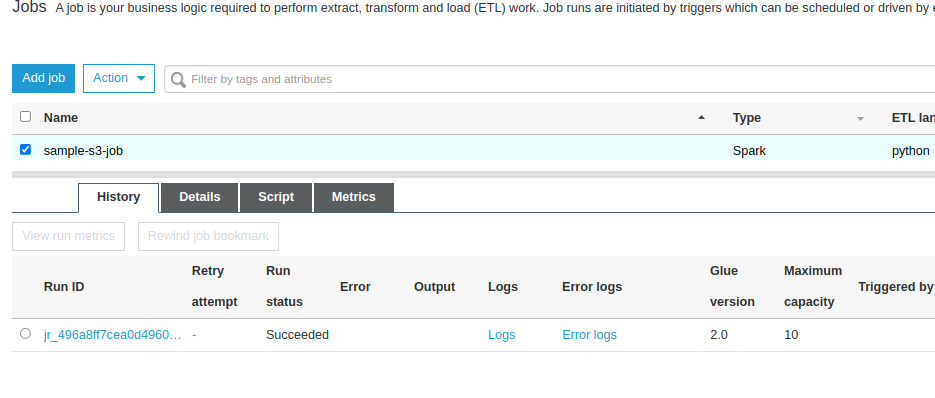
Trở về màn hình list job để kiểm tra, khi Job chạy thành công thì History sẽ có một record với Status là succeeded
![image.png]()
-
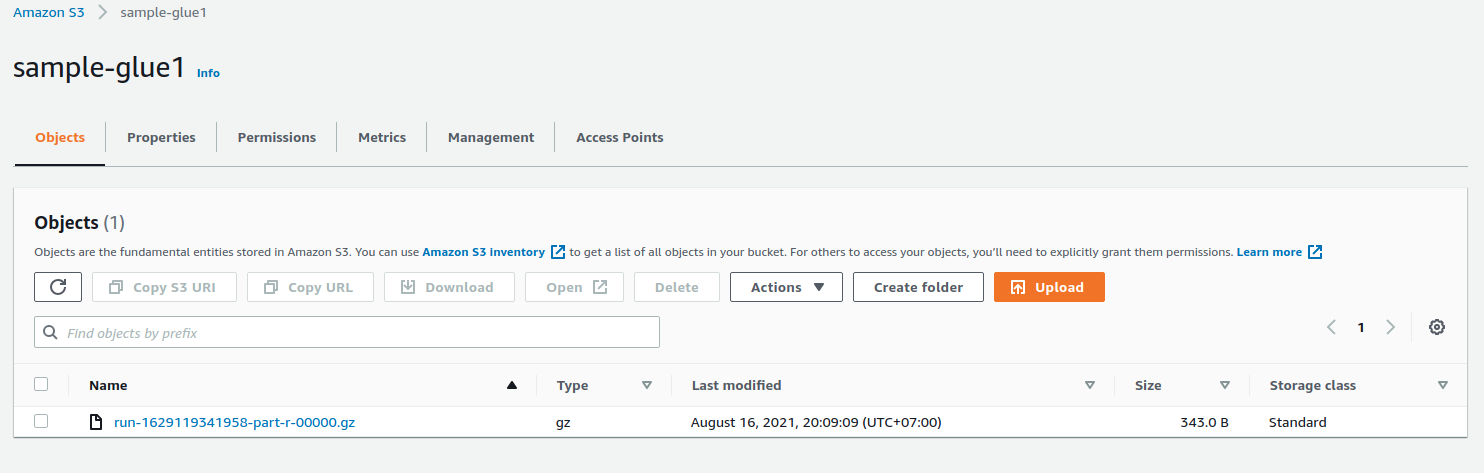
Sau khi chạy thành công, kiểm tra trên S3 Bucket sẽ có file dữ liệu
![image.png]()
Có thể đặt lịch để chạy Job export bằng Glue Trigger https://docs.aws.amazon.com/glue/latest/dg/about-triggers.html
Nguồn:
All rights reserved
