Atlas - cách giữ chân hơn 200 triệu khách hàng của Baidu
Bài đăng này đã không được cập nhật trong 2 năm
Đa số mọi người đều chỉ biết đến Baidu như là một công cụ tìm kiếm, hay "Google của Trung Quốc". Nhưng chính xác hơn thì, Baidu là một công ty cung cấp dịch vụ lưu trữ đám mây và tìm kiếm lớn nhất Trung Quốc. Tính đến năm 2014, Baidu có tới hơn 200 triệu triệu khách hàng, trong đó, mỗi người được cung cấp 2TB không gian lưu trữ. Điều này đã đặt ra một thách thức rất lớn đối với Baidu. Vậy, Baidu đã làm gì và thay đổi như thế nào để hệ thống của họ có thể đáp ứng được nhu cầu của hàng trăm triệu khách hàng như thế? Hãy cùng mình tìm hiểu về thiết kế storage của Baidu để trả lời câu hỏi này nhé!
1. Tổng quan
Ngày nay hâu hết các dịch vụ dựa trên Internet, trong đó các ông lớn như Google, Amazon, Microsoft, đều cung cấp dịch vụ lưu trữ đám mây. Ngoài ra cũng có nhiều công ty như Dropbox và Box, cũng chuyên phục vụ trong thị trường này. Để thu hút khách hàng và cạnh tranh với các đối thủ, họ cần phải cung cấp không gian lưu trữ lớn, đảm bảo chất lượng với giá cả hợp lý. Cụ thể, dịch vụ lưu trữ đám mây tốt cần đáp ứng các ít nhất các yêu cầu sau:
- Độ tin cậy cao
- Tính khả dụng cao
- Khả năng ghi nhanh
- Khả năng chịu lỗi tốt (Khả năng phục hồi sau lỗi)
- Tính nhất quán cao
- Chi phí thấp
Do lượng người dùng và nhu cầu sử dụng tăng quá nhanh , hệ thống cũ của Baidu không thể đáp ứng được. Lúc đó, họ đã gặp phải 3 vấn đề lớn:
- Thứ nhất: Khi nhu cầu về dung lượng lưu trữ tăng nhanh hơn nhiều so với sức mạnh của CPU, các cấu hình máy chủ hiện tại có thể dẫn đến việc sử dụng CPU kém và lưu trữ không đầy đủ.
- Thứ hai: Độ bền dữ liệu là điều vô cùng quan trọng, nhưng nếu bảo vệ dữ liệu bằng cách sao chép thì khả năng lưu trữ của hệ thống sẽ bị hạn chế.
- Thứ ba: Khi chỉ có một phân chia cho kích thước đối tượng dữ liệu (chủ yếu là vài KBytes), đĩa cứng có thể bị thiệt hại do tỉ lệ yêu cầu cao không cần thiêt (khi dữ liệu được lưu trữ dưới dạng cặp KV và cần tổ chức lại liên tục) hoặc quá nhiều lần ghi ngẫu nhiên (khi dữ liệu được lưu trữ dưới dạng tệp tương đối nhỏ).
Để giải quyết được những vấn đề trên, đáp ứng được các yêu cầu của một hệ thống lưu trữ đám mây, Baidu đã áp dụng một thiết kế hệ thống có:
- Sử dụng bộ vi xử lý ARM thay thế cho Intelx86, để cải thiện hiệu năng phần cứng.
- Thay thế bản sao ba bản (three-copy replication) bằng mã hóa Reed-Solomon nhằm cho phép lưu trữ với công suất thấp và mật độ cao hơn.
- Tách siêu dữ liệu (metadata) và dữ liệu (data) và mã hóa dữ liệu để lưu trữ hiệu quả.
- Sử dụng LSM-tree (Log-Structured Merge-tree ) để quản lý metadata hiệu quả.
Hệ thống đó được gọi là Atlas, là kho lưu trữ key - value (KV) có khả năng mở rộng cao, đáng tin cậy và tiết kiệm chi phí, hỗ trợ tốt dịch vụ lưu trữ đám mây của Baidu.
Để lưu trữ dữ liệu dưới dạng KV hiệu quả hơn, Atlas tách riêng Key với Value (data), và lưu trữ Value lên một server khác. Do đó, Value trong cặp KV ban đầu sẽ được thay thế bởi tham chiếu (con trỏ) tới vị trí data tương ứng với nó trong server. Các cặp KV sẽ được coi là metadata và dữ liệu được tham chiếu tới được gọi là data.
2. Kiến trúc của Atlas
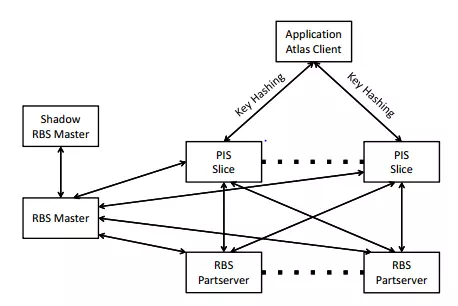
Như trong hình vẽ, Atlas có 2 hệ thống con chính.
- PIS (Patch and Index System): để quản lý metadata và chuẩn bị dữ liệu cho việc lưu trữ chúng.
- RBS (RAID-like Block System): để lưu trữ data.
và một RBS Master, cùng bộ phận dự phòng của nó - Shadow.

Tương tự như 1 kho lưu trữ KV đa năng, Atlas cung cấp một giao diện API ngắn gọn tới các các applications, như minh họa trong bảng. Trong đó, Key là một định danh toàn cục duy nhất 128-bit GUID (Globally Unique Identifier) và Value là một chuỗi các kí tự lên tới 256KB.
3. Cơ chế hoạt động của Atlas
3.1 Cơ chế ghi
Đầu tiên là PIS:
Hệ thống con PIS cung cấp dịch vụ metadata cho toàn bộ hệ thống. Ngoài việc lập chỉ mục dữ liệu, PIS cũng tiến hành nhân bản dữ liệu và tích lũy để cho phép dữ liệu được lưu trữ một cách đáng tin cậy và hiệu quả vào hệ thống con RBS.
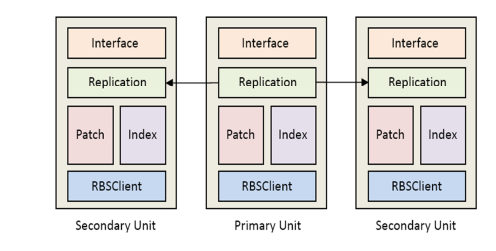
Cấu trúc của một PIS Slide được minh họa như hình. Mỗi PIS Slice có 3 đơn vị gần như giống hệt nhau về các thành phần cấu tạo và các chức năng, ngoại trừ primary unit có thể phục vụ các yêu cầu đọc/xóa và 2 secondary units được sử dụng để dự phòng, tránh làm mất mát dữ liệu.
Quy trình hoạt động:
-
Sử dụng một hàm băm để xác định 1 PIS Slide duy nhất để xử lý request.
Ví dụ: MD5 (key) module n (với n là số lượng các slice PIS)
Điều này giúp đảm bảo các keys được phân bố đều giữa tất cả các slices, giúp hệ thống tránh các nút thắt cổ chai tiềm ẩn về hiệu suất.
-
Các request đến Atlas sẽ được xử lý bởi module Replication của primary unit. Nó sẽ gán một định danh 64-bit (ID) cho data chứa trong request. Sau đó nó sẽ gửi data cùng với ID của data tới các module Replication trong các secondary units trong cùng một slice.
-
Khi module Replication trong một secondary unit nhận được data, nó sẽ yêu cầu module Patch của nó thêm dữ liệu vào bản ghi. Sau khi hoàn thành, nó sẽ xác nhận module Replication trong primary unit.
-
Khi module Replication trong primary unit nhận được xác nhận từ ít nhất một secondary unit, nó mới ghi dữ liệu vào Patch của nó và xác nhận request lưu thành công.
-
Module Patch theo dõi offset và độ dài của mỗi dữ liệu được thêm vào Patch hiện tại. Khi Patch tăng lên tới 64MB, dữ liệu được đóng gói thành 1 block. Module Patch tại primary unit sẽ truyền block tới module RBSClient. Module RBSClient sẽ chia đều block đó thành 8 phần, mỗi phần 8MB, sau đó gọi hàm Write API để ghi block vào các RBS Partservers.
-
Sau khi ghi thành công, RBSClient sẽ trả về 1 blockID. Vì module Patch đã ghi lại offset và độ dài cho mỗi dữ liệu trong block, 2 thành phần này cùng với blockID sẽ tạo thành value để hình thành nên cặp KV, với key là key của request.
Value: [block id(int64), offset(int64), length(int64)]
-
Các cặp KV sẽ được gửi tới 2 secondary unit. Tại mỗi unit, các cặp KV được viết vào trong module Index của nó, module Index được quản lý bởi LSM-tree.
-
Khi các secondary units hoàn thành các thao tác, chúng sẽ gửi xác nhận tới primary unit. Khi đó, primary unit mới lưu KV vào module Index của nó.
Tiếp theo là RBS Master
Khi một RBSClient gửi yêu cầu tới RBS master cho 1 block ID và RBS master sẽ trả về cho nó 15 địa chỉ IP của RBS partservers. Trong đó, 3 IP thêm là để RBS không cần gọi tới với master server nếu có một vài partservers bị lỗi. Trong trường hợp hết IP, nó sẽ lại gọi tới RBS master để nhận thêm IP.
Khi RBSClient lưu trữ thành công, nó sẽ gửi block ID và danh sách các partserverIPs trên tới RBS master. Trên master server, metadata được quản lý dưới dạng các cặp KV theo phương pháp LSM-tree, với key là block ID và value là danh sách các IP tương ứng lưu trữ các phần của block đó.
Master server cũng duy trì bảng partserver, đó là một bảng block ngược, chứa các cặp KV. Key chính là partserver IP và value là danh sách định danh toàn cục của các part (global part IDs) đại diện cho tất cả các parts được lưu trữ trên partserver.
Master server có một Shadow master server kèm theo, luôn được đồng bộ với master server. Trường hợp master server ngừng phục vụ, shadow master server sẽ đảm nhận vai trò của nó.
Định kỳ, RBS master sẽ gửi các "heartbeat messages" tới tất cả các partservers để kiểm tra sự mất mát của các partservers. Nếu một partserver được phát hiện là bị mất mát, thao tác phục hồi sẽ được thực hiện. Master server sẽ tra cứu bảng partserver để xác định tất cả các parts bị mất trên partserver.
3.2 Cơ chế đọc
Request được xử lý đầu tiên bởi module patch của unit. Nếu key trùng với một key đã có trong patch, value tương ứng sẽ ngay lập tức được trả về cho requester. Ngược lại, key sẽ được xử lý bởi module index của unit. Nếu không có bất kì dữ liệu nào được kết hợp với key, không chỉ trong PIS slice hiện tại mà là trong toàn bộ hệ thống, bởi vì các keys được phân phối vào các slices bằng cách sử dụng hàm băm. Ngược lại, Index sẽ trả về Value (tham chiếu) tương ứng với key. Sau đó, hàm đọc trong RBS API sẽ được gọi bởi module RBSClient để yêu cầu lấy dữ liệu từ RBS.
Đầu tiên, hàm đọc sẽ xác định IP của các partservers để xác định vị trí các parts của block. Các thông tin này có thể được lưu lại trong cache trên các PIS slices để giảm tải cho master server. Nếu nó không được tìm thấy trong cache, slice sẽ lấy nó từ master server. Khi đã có các thông tin, hàm đọc sẽ tính toán xem những part nào cần được lấy và gửi các yêu cầu đọc tới các partserver tương ứng. Nếu lấy được tất cả dữ liệu của yêu cầu, nó sẽ trả về cho requester. Nếu không, hàm đọc sẽ lấy ra 8 parts trong số các parts có sẵn của block để đọc và giải mã nhằm phục hồi dữ liệu được yêu cầu. Nếu thao tác này cũng thất bại, hàm đọc sẽ yêu cầu master server cung cấp một danh sách các IP mới nhất trong trường hợp danh sách các IP được lưu trong cached cục bộ bị lỗi thời hoặc master server đã cập nhật danh sách IP kể từ lần truy xuất cuối cùng. Nó sẽ tiếp tục thử cho tới khi dữ liệu được đọc thành công hoặc đạt tới ngưỡng thử lại tối đa.
Ngưỡng thử tối đa thường là 100ms và nó sẽ tăng lên sau mỗi lần hệ thống thất bại.
3.3 Cơ chế xóa
Để đảm bảo hiệu suất của hệ thống, các cặp KV được lưu trữ trong Atlas là bất biến. Chúng có thể bị xóa và ghi đè bằng cách chèn thêm các cặp KV có cùng key, nhưng không thể sửa đổi trực tiếp. Theo đó, các blocks trong Atlas cũng bất biến và không gian bị chiếm bởi các cặp KV đã bị xóa chỉ có thể được giải phóng nhờ bộ thu gom rác.
Khi PIS nhận được một yêu cầu xóa, nếu key ở trong patch hiện tại, nó sẽ bị loại bỏ khỏi patch và không được ghi vào RBS. Ngược lại, nếu ở trong module index, thao tác xóa chỉ đơn giản là được ghi lại và đợi thao tác merge dữ liệu trong tương lai để loại bỏ metadata về key. Khi primary unit nhận được xác nhận từ ít nhất một secondary unit về việc hoàn thành các thao tác xóa, nó sẽ thông báo cho requester là đã hoàn thành. Kể từ thời điểm này, cặp KV sẽ không còn được nhìn thấy trong các ứng dụng, mặc dù nó có thể vẫn còn nằm trong hệ thống kho lưu trữ RBS.
Không gian bị chiếm bởi dữ liệu đã bị xóa được giải phóng định kỳ thông qua bộ thu gom rác, một cách offline.
4. Ưu điểm của Atlas
- Atlas sử dụng vi xử lý ARM thay cho Intelx86. Điều này giú cải thiện hiệu suất của hệ thống từ 20% lên tới 50%. Trong khi đó, ARM chỉ có chi phí và mức tiêu thụ điện năng bằng 1/10 so với Intelx86.
- Thay vì sử dụng phương pháp sao lưu 3 bản, Atlas sử dụng mã hóa Reed - Solomon. Vì vậy, thay vì cần tới 200% dữ liệu dự phòng (cho 2 bản sao), Atlas chỉ cần 50% (từ 8 phần của 1 block mã hóa thành 12 phần). Hơn nữa, theo tính chất của thuật toán mã hóa Reed-Solomon, 1 block không thể được phục hồi nếu có nhiều hơn 5 phần của block bị mất. Mà 12 phần được đảm bảo sẽ được phân phối trên 12 partservers khác nhau, nên chỉ khi 5 servers bị mất đồng loạt thì RBS mới có khả năng bị mất dữ liệu. Điều này giúp độ tin cậy của hệ thống tăng lên rất nhiều.
- LSM-tree có hiệu quả lưu trữ rất tốt vì nó hoạt động theo cơ chế truy cập tuần tự. Tập dữ liệu được tổ chức trong LSM-tree cho phép insert nhanh vì các item dữ liệu mới luôn thêm tuần tự vào cuối tệp log(nhật ký). Ngoài ra, cập nhật và xóa cũng được hỗ trợ hiệu quả vì hệ thống ghi lại một cách tuần tự các hoạt động tương ứng vào log, thay vì tiến hành sửa đổi dữ liệu tại chỗ. Tuy nhiên, để tạo điều kiện đọc dữ liệu hiệu quả và thực hiện các sửa đổi dữ liệu, dữ liệu trong cây luôn cần phải được sắp xếp. Điều này gây ra tốn kém đáng kể với lượng dữ liệu lớn. Nhưng thay vì sử dụng LSM-tree cho toàn bộ dữ liệu, Atlas sử dụng nó cho metadata. Do metadata có kích thước rất nhỏ so với data, nên việc sắp xếp dữ liệu không quá tốn kém với Atlas.
- Việc phân bố đều dữ liệu trên các PIS Slide và RBS partserver giúp hệ thống tránh các nút thắt cổ chai và mất mát dữ liệu hệ thống, tạo điều kiện để hệ thống khôi phục lại dữ liệu khi có sự cố xảy ra.
Trên đây là một số thông tin mà mình tìm hiểu được về hệ thống lưu trữ đám mây của Baidu. Trung Quốc là một cường quốc, họ có một mạng lưới Internet nội bộ độc lập nhưng không hề thua kém mạng Internet của toàn thế giới. Tất nhiên, cũng không thể nói rằng hệ thống của họ tốt nhất, hơn cả Google, Amazon,... nhưng mỗi hệ thống đều có những ưu điểm về tính năng và cấu trúc mà chúng ta có thể tìm hiểu và học tập. Nếu mọi người có hứng thú với hệ thống này, lần sau mình sẽ trình bày rõ hơn về hiệu năng của Atlas cũng như một vài so sánh của nó với các hệ thống phổ biến hiện nay.
Tài liệu tham khảo: http://ranger.uta.edu/~sjiang/pubs/papers/lai15-atlas.pdf
All rights reserved
