Asynchronous microservices
Bài đăng này đã không được cập nhật trong 6 năm
Trong bài viết này mình sẽ chia sẻ một vài hiểu biết về "asynchronous microservices" - "xử lý bất đồng bộ trong microservices".
Như bài trước mình đã nói tới việc, mỗi service sẽ có một data riêng - "each service has its own private database" để đảm bảo việc các service được kết nối với nhau. Vì điều đó, nên nếu muốn triển khai microservice cho ứng dụng của bạn, việc đầu tiên cần phải làm là giải quyết vấn đề "quản lý dữ liệu phân tán" - "distributed data management". (link previous post )
Trước hết hãy xem xem việc xử lý một cơ sử dữ liệu duy nhất với nhiều thì nó sẽ có những lợi ích và hạn chế như thế nào nhé (có khi nào đến đây rồi bạn sẽ suy nghĩ lại và chọn lựa giữ nguyên mô hình monolithic cũ cũng nên :3)
1. The Problem of Distributed Data Management
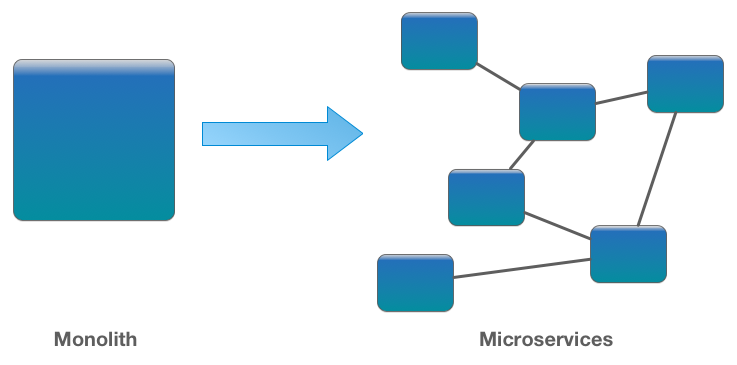
Với mô hình monolithic cũ sử dụng duy nhất một database, lợi ích đầu tiên mà nó mang lại đó chính là việc ứng dụng của bạn có thể sử dụng được ACID transaction - là các thuộc tính quan trọng của 1 database nhằm đảm bảo tính toàn vẹn khi xử lý bất kì giao dịch nào (dù có sự cố lỗi hay mất điện):
- Atomicity - Các thay đổi được hiện hiện 1 cách nguyên tố (ý ở đây là trong 1 giao dịch có nhiều thao tác một là toàn bộ 2 là không một thao tác nào được thực hiện)
- Consistency - Tính nhất quán (hợp lệ -> commit, lỗi -> rollback)
- Isolation - Tính độc lập (các giao dịch được thực hiện đồng thời nhưng cũng đảm bảo riêng biệt với nhau)
- Durable - Tính bền vững (một khi đã commit -> không thể rollback lại)
-> Hiểu đơn giản, thực hiện cũng đơn giản: chỉ cần bắt đầu 1 transaction -> change(insert, update, delete) records, và sau đó là commit transaction
Điều tuyệt vời khác mà việc sử dụng 1 database duy nhất đem lại đó là có thể sử dụng câu lệnh SQL - là một ngôn ngữ truy vấn phong phú, tiêu chuẩn để các databases sử dụng. Điều này thì có vẻ các bạn khá thân thuộc rồi, viết một câu query đơn giản kết nối giữa các bảng trong database thì thật easy. Thậm chí cũng chẳng cần lo lắng việc phải truy cập các bảng khác như thế nào - vì tất cả data trong ứng dụng của bạn đều nằm trong 1 database -> rất dễ dàng để query.
Còn khi áp dụng microservices thì ta phải giải quyết được 2 vấn đề:
- Làm sao để thực hiện giao dịch mà vẫn duy trì được tính nhất quán giữa nhiều
services.
- Ví dụ: ta có 2 services Customer Service và Order service. Order Service quản lý các
ordersvà phải xác nhận rằng các bản ghi mới không được vượt hạn mức thẻ tín dụng của người dùng. Đối với ứng dụng có cấu trúc monolithic, đơn giản ta chỉ cần sử dụng ACID transaction để check những thẻ tín dụng có sẵn và tạo mới order. Nhưng với microservice bảng ORDER và CUSTOMER là 2 bảng riêng biệt trong 2 service. Order service không thể truy cập trực tiếp vào bảng CUSTOMER để truy vấn, mà chỉ có thể sử dụng API được cung cấp bởi Customer Service.
- Làm sao để thực hiện query lấy data từ nhiều
services.
- Ví dụ: bạn muốn hiển thị thông tin khách hàng với các đơn đặt hàng gần đây. Order service cung cấp API truy cập để lấy data của tất cả các đơn đặt hàng của khách hàng đó, sau đó bạn có thể lọc ra những dữ liệu bạn muốn. Tuy nhiên, Order Service chỉ hỗ trợ tìm kiếm các đơn đặt hàng bằng khóa chính. Rõ ràng không thể lấy được dữ liệu y/c trong tình huống này được.
Vậy ta có cách nào để giải quyết 2 vấn đề này? Cùng tìm hiểu nào.
2. Event-Driven Architecture
Cấu trúc hướng sự kiện đã được áp dụng ở rất nhiều ứng dụng thực tế. Nhưng làm thế nào mà phương pháp này có thể giải quết được cả 2 vấn đề trên? Đầu tiên, một microservice sẽ gửi đi một event - sự kiện khi có 1 điều gì đó gây ảnh hưởng xảy ra, như là khi 1 bản ghi được update chẳng hạn. Các microservices khác sẽ đăng ký vào mỗi events đó. Và khi 1 microservice nhận được 1 event rồi cập nhật những bản ghi trong service của mình, việc này cũng dẫn đến việc nhiều events sẽ được gửi đi.
Bạn cũng có thể sử dụng các events để thực hiện các transaction ở nhiều services. 1 transaction bao gồm rất nhiều bước. Mỗi bước bao gồm 1 service đang thực hiện update 1 bản ghi trong nó và gửi event tới bước tiếp theo. Microservices gọi qua lại các sự kiện thông qua Message Broker, cùng xem ví dụ để hình dung rõ hơn cơ chế của nó nhé.
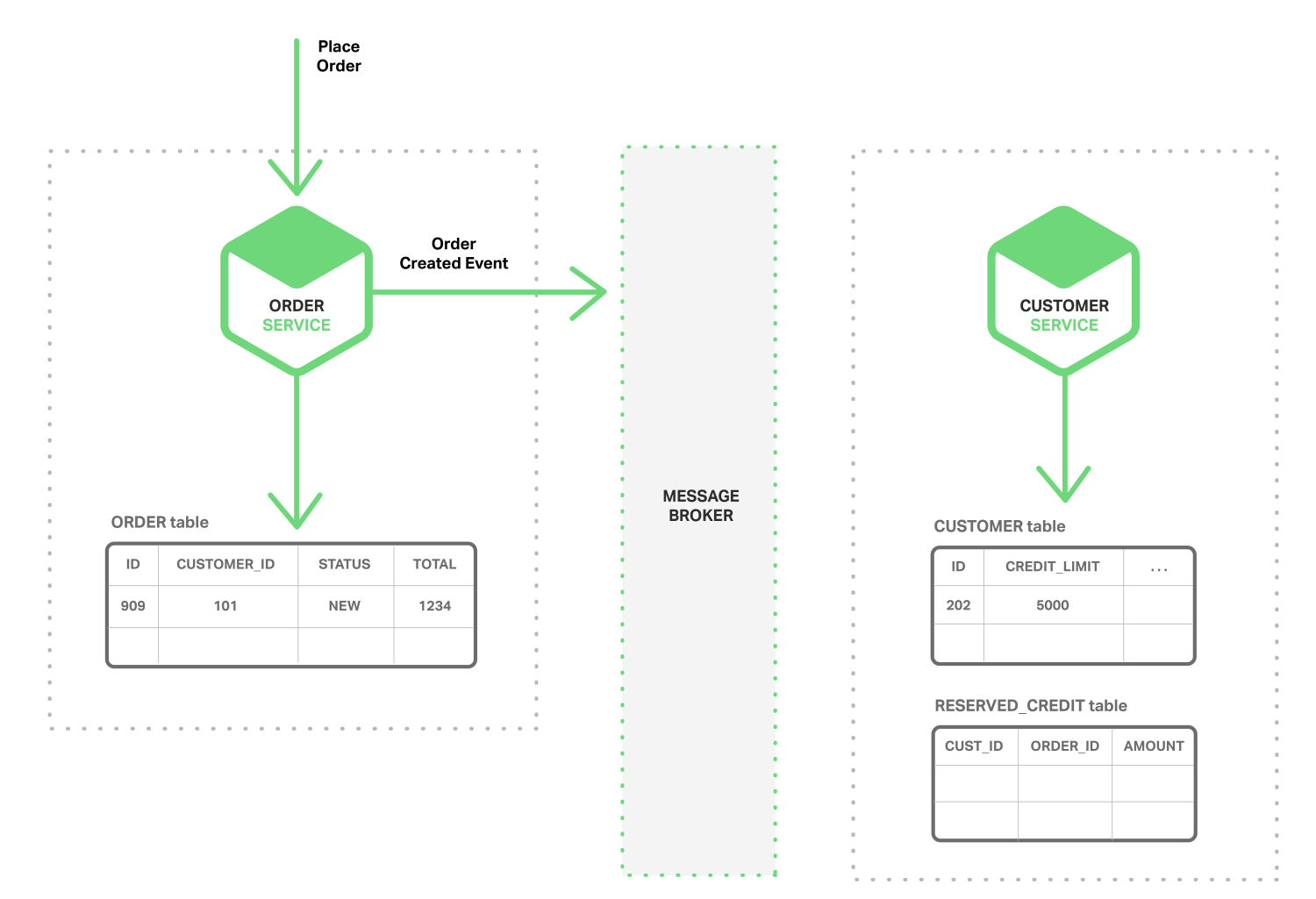
-
Order Service tạo mới 1 bản ghi với trạng thái ban đầu là
NEWvà gửi đi 1 sự kiện khởi tạoOrder Created![]()
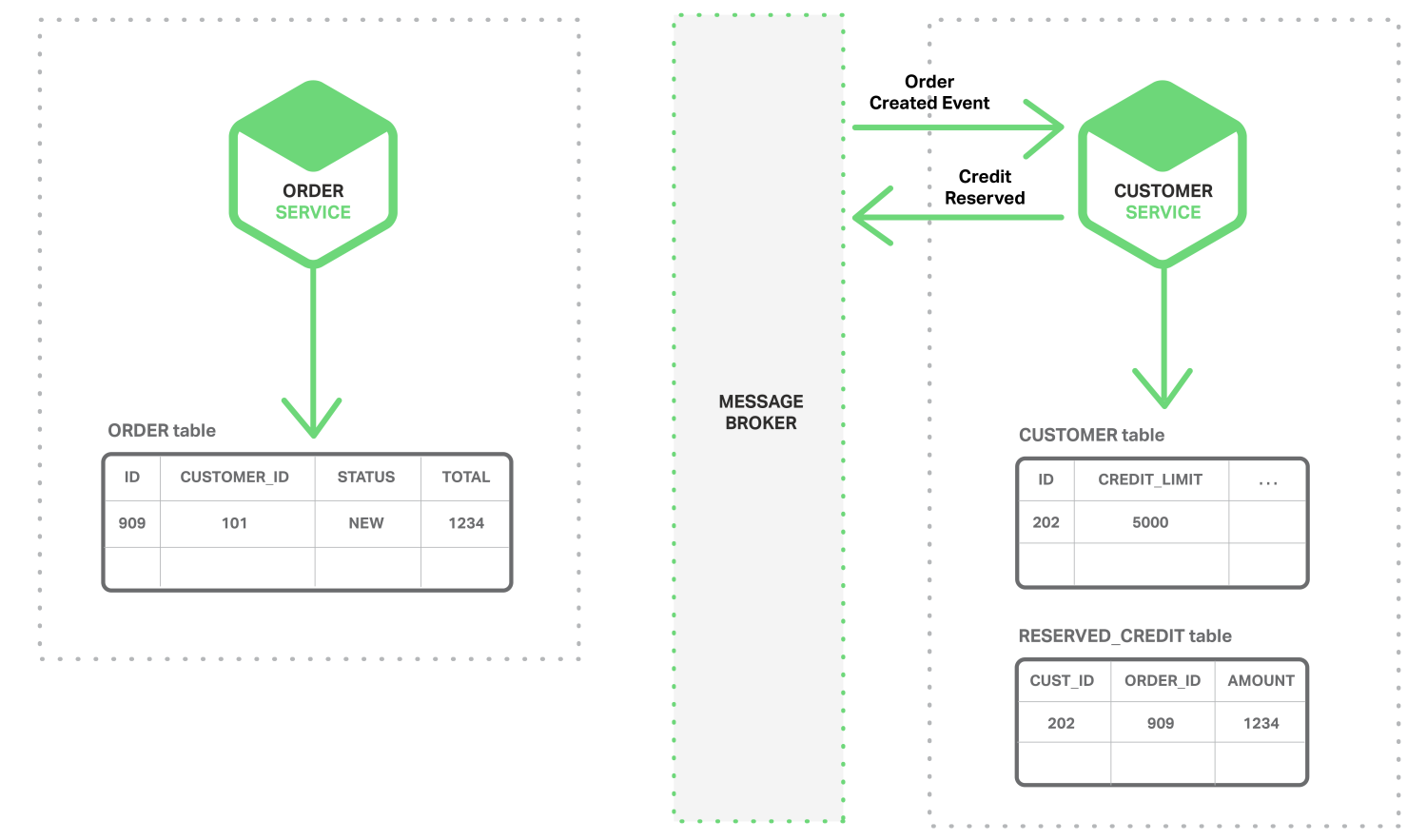
-
Customer Service tiếp nhận sự kiện
Order Created, lưu trữcreditcho Order đó, và gửi đi 1 sự kiệnCredit Reserved![]()
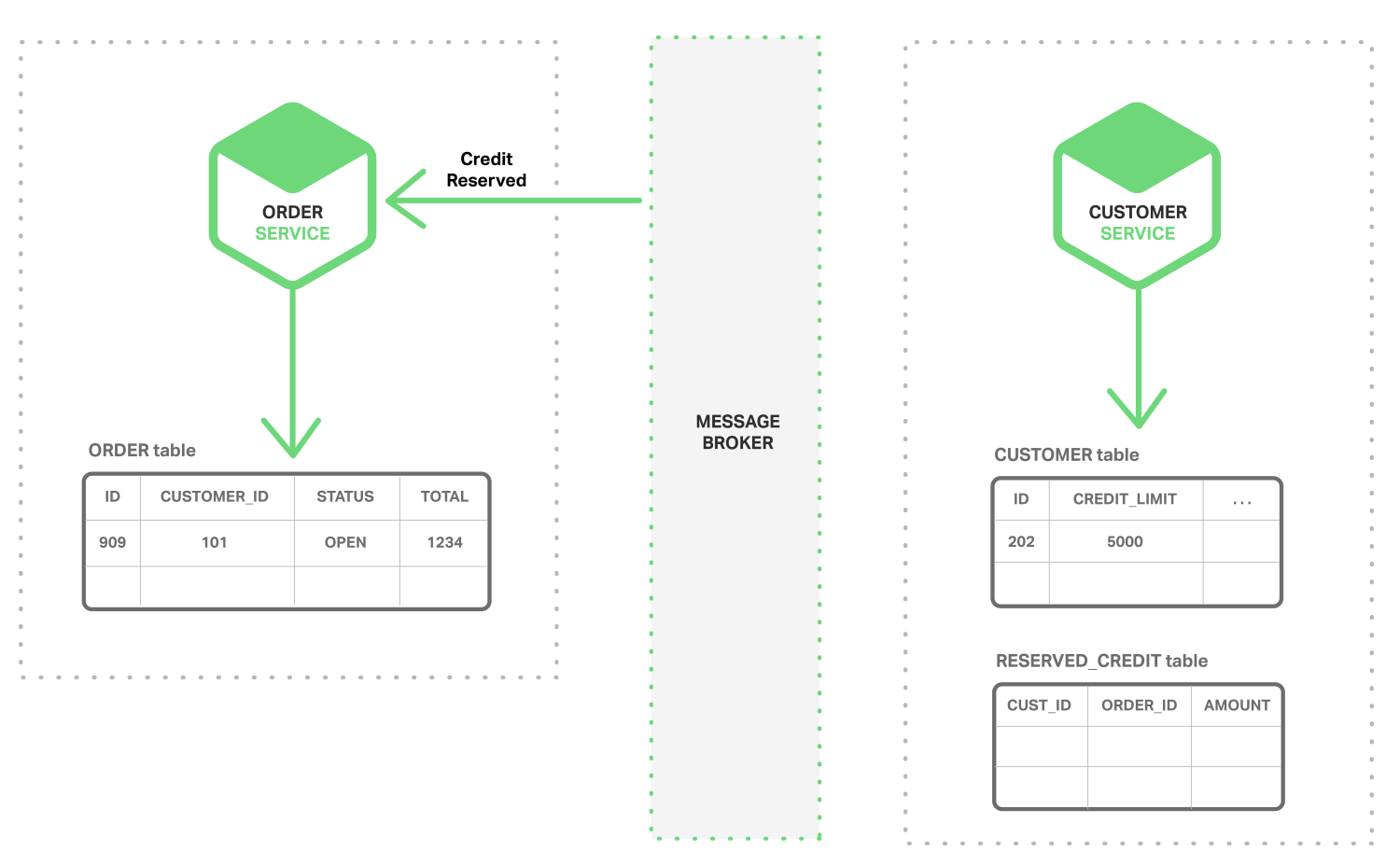
-
Order Serice tiếp nhận sự kiện
Credit Reservedvà thay đổi trạng thái của Order ->OPEN![]()
Ưu điểm:
- Nó cho phép thực hiện nhiều
transactionstrên nhiều services và cũng đảm bảo sự thống nhất giữa cáctransactionđến cuối cùng. - Nó cho phép các ứng dụng duy trì các
viewscụ thể
Nhược điểm:
- Mô hình lập trình sẽ trở nên phức tạp hơn khi áp dụng ACID transactions
- Muốn đăng ký được các sự kiện thì phải phát hiện và loại bỏ những sự kiện trùng lặp.
Ở đây ta sẽ đi tìm những các để giải quyết vấn đề 1 trước
Use local Transaction
Một trong những cách để đảm bảo được tính atomicity trong ACID đó là để việc gửi đi các sự kiện có sử dụng multi‑step process involving only local transactions. Nghĩa là ta có thêm một bảng sự kiện, trong database sẽ lưu trạng thái của các đối tượng có trong nó. Ứng dụng khởi đầu với 1 database transaction, update trạng thái của đối tượng, insert một sự kiện vào bảng EVENT và commit transaction đó. Một ứng dụng riêng biệt được truy vấn theo luồng hoặc theo quá trình, để gửi đi các sự kiện đến Message Broker, và sau đó sẽ sử dụng local transaction để đánh dấu các sự kiện đã được gửi đi.
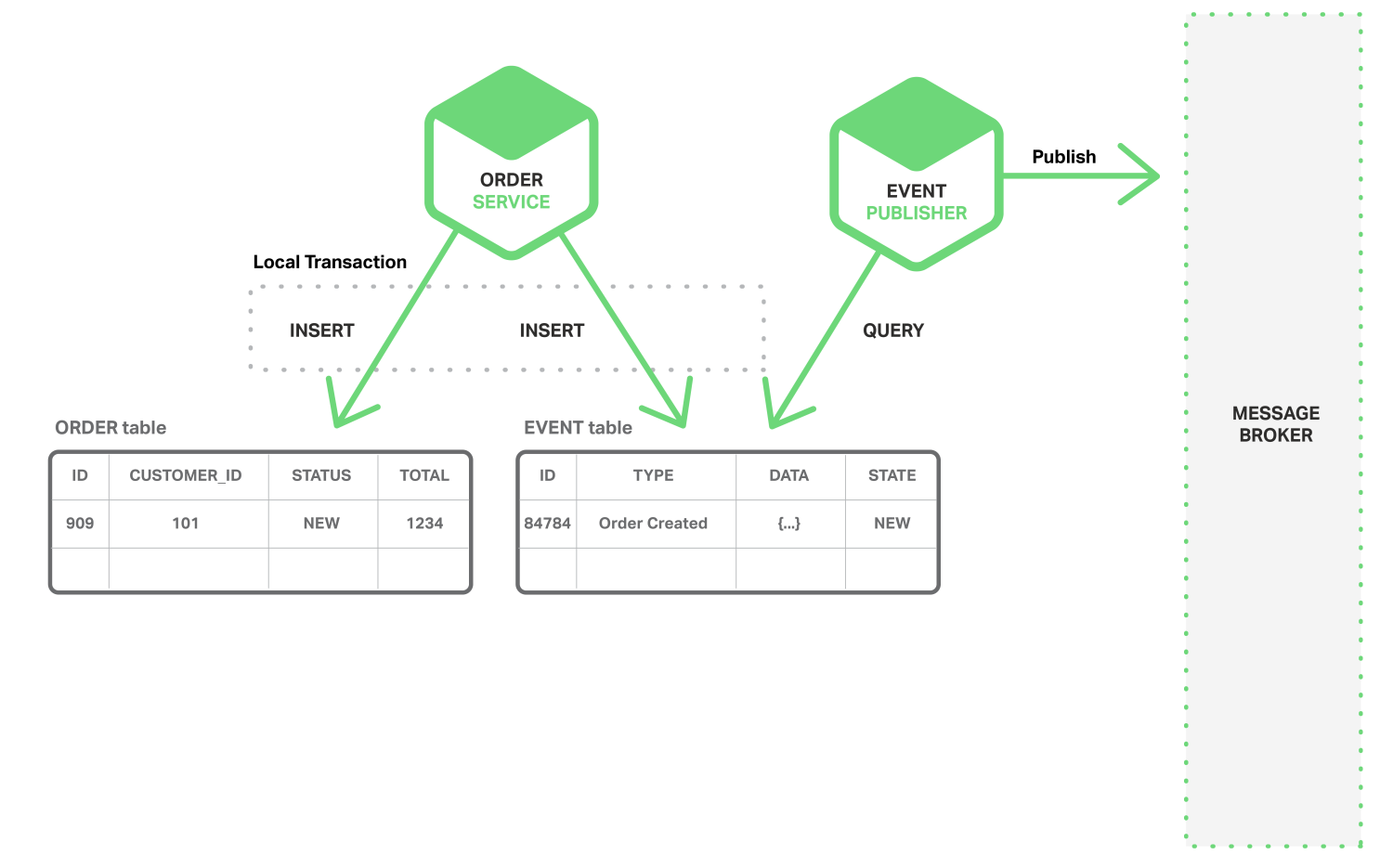
Order Service insert 1 bản ghi vào bảng ORDER và insert 1 sự kiện Order Created và bảng EVENT. Event Publisher truy vấn theo luồng hoặc theo quy trình và bảng EVENT để xác định các sự kiện chưa được gửi, gửi đi các sự kiện và update bảng EVENT để đánh dấu các sự kiện đã được gửi đi.
Cách này có một số ưu điểm cũng như nhược điểm sau:
- Ưu điểm
- Nó đảm bảo 1 sự kiện là đã được gửi đi trong mỗi lần update mà không cần đến 2PC (two phase commit)
- Ứng dụng gửi đi những sự kiện ở các mức độ khác nhau -> không cần quan tâm đến việc phân loại các sự kiện
- Nhược điểm
- Có khả năng phát sinh lỗi vì nhà phát triển phải nhớ việc gửi đi các sự kiện
- Một giới hạn của phương pháp này đó là việc sử dụng NoSQL database bởi vì khả năng giao dịch và truy vấn hạn chế của nó.
Túm lại thì với phương pháp này, ta không cần đến 2PC để update trạng thái cũng như gửi đi các sự kiện thay vào đó là sử dụng local transaction. Nếu vẫn thấy chưa thỏa mãn thì cùng qua cách tiếp theo nhé
Mining a Database Transaction Log
Ứng dụng update database, đó là kết quả của việc thay đổi record - và đó cũng là mục đích chính của phương pháp này đó. Transaction Log Miner đọc nhật ký giao dịch và gửi đi các sự kiện đến Message Broker.
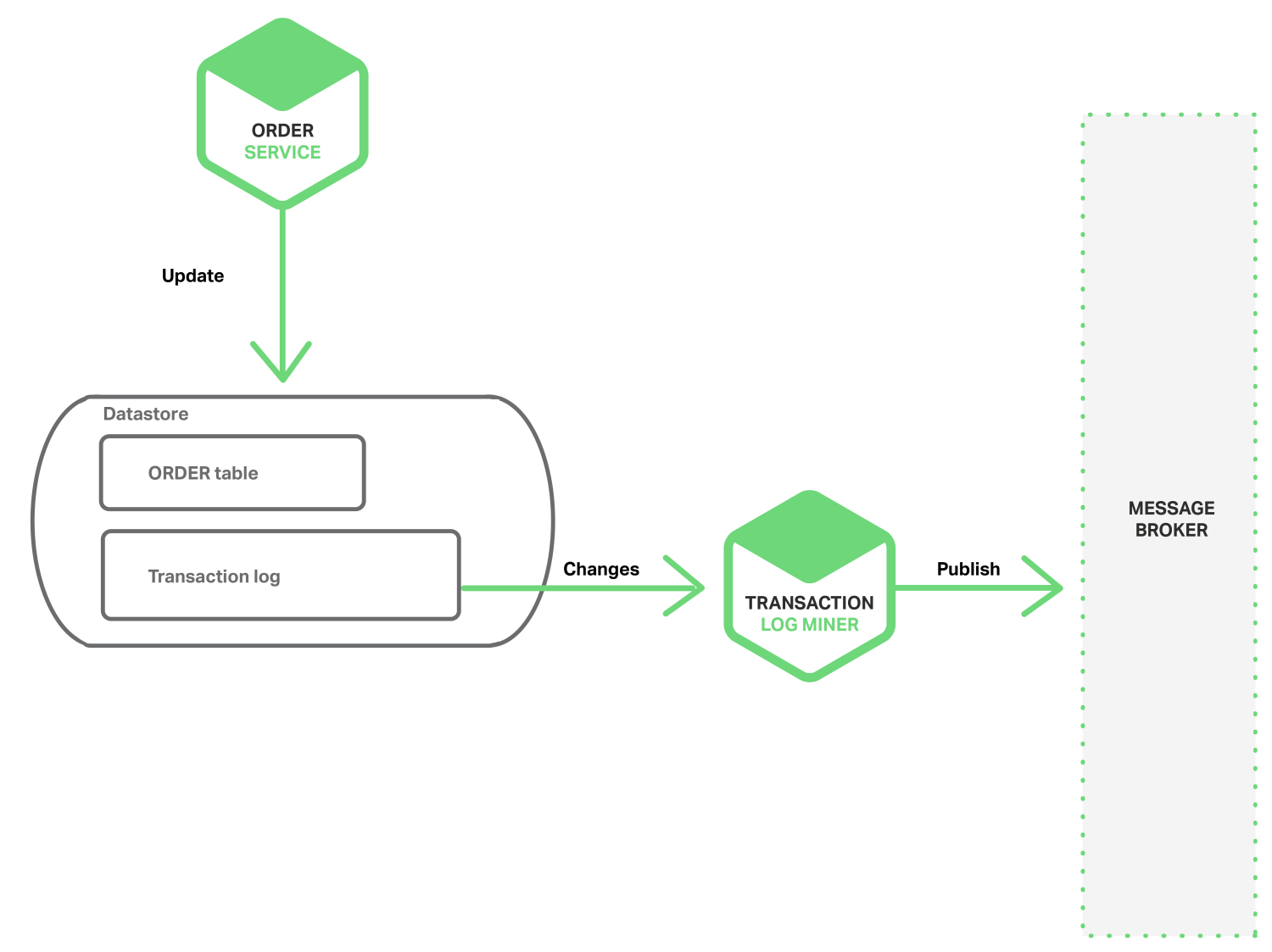
Ví dụ: project LinkedIn Databus . Databus khai thác Oracle nhật ký giao dịch và gửi đi các sự kiện tương ứng với mỗi sự thay đổi(như update bản ghi, tạo mới, ...). LinkedIn sử dụng Databus để giữ cho các dữ liệu từ các nguồn khác nhau được lưu trữ lại 1 cách thống nhất.
Như trên, phương pháp này cũng có những ưu nhược điểm riêng.
- Ưu điểm
- Nó đảm bảo 1 sự kiện là đã được gửi đi trong mỗi lần update mà không cần đến 2PC (two phase commit)
- Làm đơn giản hóa ứng dụng của bạn bằng việc chia các sự kiện được gửi đi ra khỏi các đoạn logic của ứng dụng
- Nhược điểm
- Format của
transaction loglà duy nhất cho mỗi database và thậm chí ta có thể thay đổi giữa các phiên bản database. Vậy là mỗi service có sử các loại database khác nhau ta phải cần tìm đúng format củatransaction logphù hợp đau đầu phết ta.
đau đầu phết ta. - Khó khăn khi thiết kế để đảo ngược các event có cấp mức độ cao từ event có cấp mức độ thấp bên trong
transaction log
Để loại bỏ 2PC, trong giải pháp này thì ta chỉ cần update database :v
Using Event Sourcing
Cùng nhìn lại vấn đề ta gặp phải ở đây là gì nào: Làm thế nào để update database(atomicity) và gửi đi các sự kiện 1 cách đáng tin cậy và chính xác nhất? và yêu cầu là không được sử dụng 2PC nhé!
Và giải pháp của chúng ta là Event Sourcing. Bằng cách lưu giữ các đối tượng như Order hay Customer giống như là một chuỗi các sự kiện thay đổi trạng thái. Mỗi khi trạng thái của một đối tượng được thay đổi, 1 sự kiện mới được gán vào danh sách các sự kiện hiện đó. Lưu 1 sự kiện là một hoạt động riêng rẽ, cho nên điều này đã thực sự đảm bảo được độ tin cậy(atomicity).
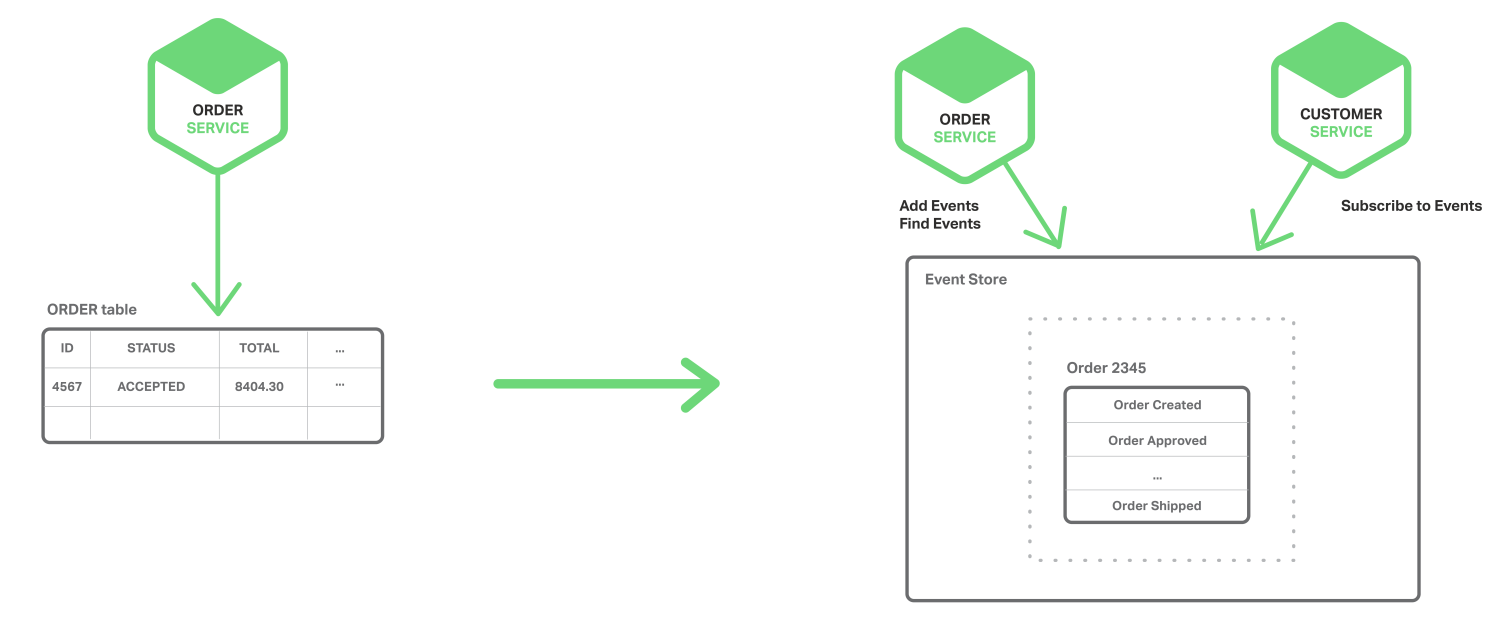
Các sự kiện sẽ tồn tại bên trong Event Store, nó chính là database của các sự kiện. Nơi lưu trữ cung cấp API để thêm và lưu trữ các đối tượng của các sự kiện. Event Store cũng giống như Message Broker. Nó cung cấp API để cho phép các services đăng ký vào các sự kiện. Event Store chuyền tất cả các sự kiện đến tất cả những người đăng ký. Event Store là trọng tâm của cấu trúc hướng sự kiện.
Cũng như các phương pháp khác Event sourcing cũng có những ưu điểm riêng.
- Ưu điểm:
- Nó giải quyết được vấn đề chính trong việc thực hiện theo cấu trúc hướng sự kiện và có thể gửi đi một sự kiện(đáng tin cậy) khi có bất cứ thay đổi nào. => Giải quyết được vấn đề thống nhất dữ liệu trong microservice
- Nó cung cấp nhật ký đáng tin cậy đến 100% về những thay đổi bên trong 1 đối tượng
- Có thể thực hiện được các truy vấn tạm thời để xác định trạng thái của các đối tượng ở bất cứ thời điểm nào
- Logic sẽ bao gồm các đối tượng được liên kết lỏng lẻo với nhau và trao đổi qua lại giữa các sự kiện. Điều này có tác dụng gì? Nó giúp cho việc chuyển từ
monolithicsangmicroservicesdễ dàng hơn.
- Nhược điểm
- Nó rất khó để học
 )
) - Các sự kiện được lưu trữ rất khó để lấy ra bởi vì điều này yêu cầu các câu query đặc trưng để có thể tái cấu trúc lại trạng thái của đối tượng. Hệ quả là chúng ta phải sử dụng thêm CQRS để thực hiện được việc query dễ dàng hơn
3. Summary
Mỗi một microservice sẽ có cho mình một database lưu trữ riêng. Và sự khác nhau giữa các microservice là việc sử dụng SQL hay NoSQL databases. Nếu mỗi service sử dụng 1 database để phù hợp với từng chức năng thì đây là 1 điều cần thiết, nhưng đồng thời cũng tạo thêm những khó khăn mới vì việc quản lý dữ liệu phân tán là điều không dễ thực hiện. Đầu tiên, đó là how to thực hiện giao dịch mà vẫn đảm bảo sự thống nhất giữa các services. Thứ hai, đó là how to query để lấy data giữa nhiều services.
Trong đó thì event-driven architecture là được áp dụng rộng rãi. Vấn đề còn lại ở đây đó là how to update trạng thái 1 cách đáng tin cậy và how to gửi các sự kiện đi. Đương nhiên sẽ có cách để giải quyết - đó là sử dụng message queue, transaction log và event sourcing.
Leave a comment !!! 
Source:
- https://microservices.io/patterns/data/database-per-service.html
- https://eventuate.io/whyeventdriven.html
- Microservices Designing Deploying Book
All rights reserved
