ASR - Paper reading | Tìm hiểu mô hình Whisper
Bài đăng này đã không được cập nhật trong 2 năm
Giới thiệu
Các mô hình Nhận dạng giọng nói tự động (ASR) đóng một vai trò quan trọng trong cuộc sống và công nghệ hiện đại. Chúng giúp cải thiện khả năng tiếp cận cho người khuyết tật, đặc biệt là những người khiếm thị, bằng cách cho phép họ sử dụng các thiết bị công nghệ thông qua giọng nói. Trong môi trường doanh nghiệp, ASR tiết kiệm thời gian và tăng cường hiệu quả làm việc bằng cách hỗ trợ soạn thảo văn bản, gửi email và tìm kiếm thông tin mà không cần gõ phím. Các trợ lý ảo như Siri, Google Assistant và Alexa nâng cao trải nghiệm người dùng bằng cách cung cấp phương thức tương tác tự nhiên với thiết bị và dịch vụ.
Ngoài ra, ASR có ứng dụng rộng rãi trong nhiều lĩnh vực như y tế, giáo dục và dịch vụ khách hàng. Trong y tế, ASR hỗ trợ bác sĩ ghi chép và truy cập thông tin bệnh án nhanh chóng; trong giáo dục, ASR tạo ra các công cụ học tập đa dạng, hỗ trợ học sinh và giáo viên; và trong dịch vụ khách hàng, ASR cải thiện chất lượng và tốc độ của các dịch vụ hỗ trợ qua điện thoại. Không chỉ là công cụ tiện lợi, ASR còn là nền tảng cho sự phát triển của các công nghệ tiên tiến khác như trí tuệ nhân tạo và học máy, đóng góp vào tiến bộ của khoa học và công nghệ, mở ra nhiều cơ hội mới cho con người.
Một trong những mô hình ASR mạnh mẽ nhất hiện nay là Whisper. Đây là mô hình có khả năng nhận diện giọng nói ở nhiều ngông ngữ khác nhau. Trong bàu viết này, chúng ta sẽ cùng tìm hiểu cách nhóm tác giả xây dựng Whisper và 1 số kỹ thuật training sử dụng trong mô hình.
Cách tiếp cận
Data Processing
Như các cách làm phổ thông mà chúng ta thường thấy, nhóm tác giả tận dụng lượng dữ liệu khổng lồ trên Internet để train model. Mục tiêu là xây dựng 1 bộ dữ liệu đa dạng về môi trường, cách ghi âm, nhiều người và giọng nói khác nhau, đặc biệt là phải đa dạng về ngôn ngữ.
Sự đa dạng về chất lượng âm thanh giúp train mô hình tốt hơn. Tuy nhiên, nếu không đảm bảo chất lượng transcription ứng với mỗi file audio thì sẽ làm giảm hiệu suất mô hình. Nhóm tác giả nhận thấy rằng, có rất nhiều transcript trên internet là do hệ thống ASR tạo ra chứ không phải từ con người. Một số nghiên cứu chỉ ra rằng, việc train model trên bộ data mix giữa người và máy gán nhãn có thể làm giảm đáng kể hiệu suất mô hình. Vì vậy, nhóm tác giả thực hiện một số phương pháp heuristics để xoá các transcription tạo bởi máy, giúp cho training dataset được sạch sẽ hơn  .
.
Bên cạnh đó, nhiều hệ thống ASR hiện nay chỉ generate ra một phần nhỏ của ngôn ngữ viết. Các mô hình này thường loại bỏ hoặc thay đổi những yếu tố khó đoán từ âm thanh, ví dụ như dấu câu (dấu chấm than, dấu phẩy, dấu chấm hỏi), khoảng trắng (như khoảng cách giữa các đoạn văn), hoặc các chi tiết như viết hoa chữ cái đầu. Ví dụ, một transcription toàn chữ in hoa hoặc chữ thường thường không phải do con người tạo ra.
Mặc dù nhiều hệ thống ASR thực hiện thêm bước postprocessing, nhưng thường khá đơn giản, chỉ dựa trên rule base. Do đó, ta vẫn dễ phát hiện ra những điểm chưa xử lý, chẳng hạn như việc không bao giờ có dấu phẩy.
Nhóm tác giả cũng sử dụng một audio language detector. Model này được train trên phiên bản prototype của tập dataset VoxLingua107. Mục tiêu của việc sử dụng model này là để đảm bảo rằng phần ngôn ngữ được nói giống với ngôn ngữ trong transcription.
Ngoài ra, nhóm tác giả chia các tệp âm thanh thành các đoạn 30 giây và ghép chúng với phần transcript tương ứng để train mô hình nhận diện giọng nói, bao gồm cả các đoạn không có lời nói nhằm cải thiện khả năng phát hiện giọng nói. Sau khi train mô hình ban đầu, nhóm nghiên cứu lọc dữ liệu bằng cách kiểm tra thủ công các nguồn dữ liệu có tỷ lệ lỗi cao và loại bỏ những bản ghi chất lượng kém. Ngoài ra, họ cũng loại bỏ trùng lặp giữa tập dữ liệu đào tạo và tập dữ liệu đánh giá.
Model
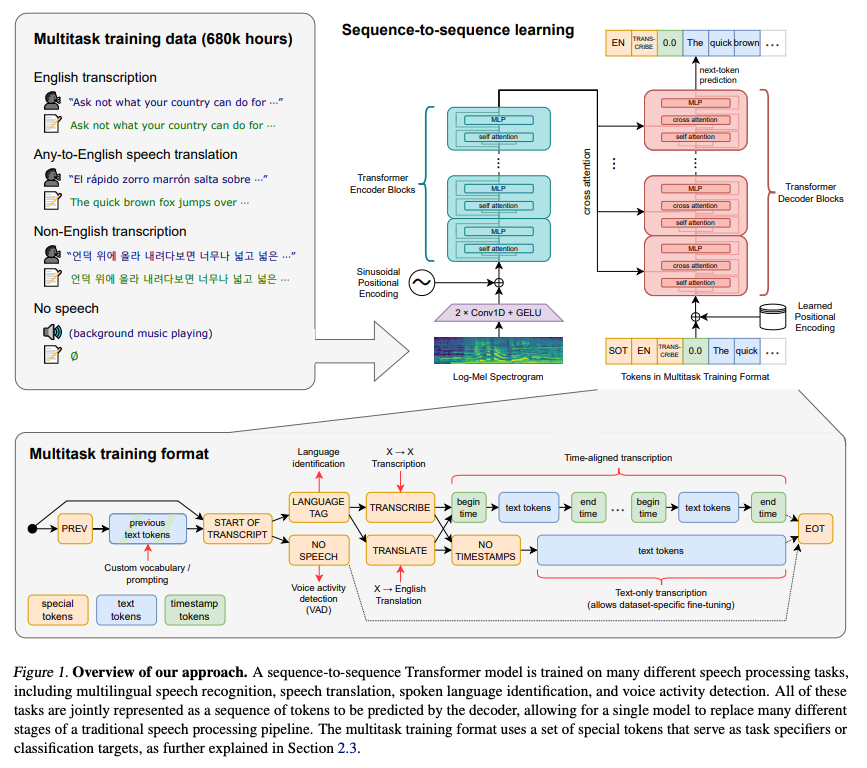
Trong bài báo, nhóm tác giả tập trung vào việc nghiên cứu khả năng của mô hình supervised pre-training với kích thước lớn cho bài toán speech recognition. Để bắt đầu 1 cách đơn giản nhóm tác giả sử dụng một kiến trúc có sẵn là mô hình encoder-decoder Transformer.
Tất cả các tệp âm thanh đều được điều chỉnh lại thành tần số 16,000 Hz và được chuyển đổi thành Mel spectrogram với 80-channel với kích thước window là 25ms và khoảng cách 10ms. Để chuẩn hóa đặc trưng âm thanh, nhóm tác giả scale dữ liệu đầu vào nằm trong khoảng từ -1 đến 1 với giá trị trung bình xấp xỉ 0 trên toàn bộ tập dữ liệu pretrain.
Mô hình encoder xử lý dữ liệu đầu vào thông qua một phần mở đầu nhỏ gồm 2 layer convolution với chiều rộng bộ lọc là 3 và activation function là GELU. Lớp convolution thứ hai có stride là 2. Sau đó, các positional sinusoidal embedding được thêm vào đầu ra của phần mở đầu, sau đó các block Transformer encoder được sử dụng. Kiến trúc cũng rất là cơ bản
Các block Transformer này sử dụng các block residual pre-activation và một layer chuẩn hóa cuối cùng được áp dụng cho đầu ra của encoder. Bên cạnh đó, phía decoder sử dụng các positional embedding được học và các biểu diễn token đầu vào-đầu ra được liên kết. Cả encoder và decoder đều có cùng chiều rộng và số lượng block transformer.
Nhóm tác giả sử dụng bộ tokenizer byte-level BPE tương tự như trong mô hình GPT-2 cho các mô hình chỉ dùng cho tiếng Anh. Đối với các mô hình đa ngôn ngữ, nhóm tác giả điều chỉnh lại từ vựng (nhưng vẫn giữ nguyên kích thước bộ từ vựng) để tránh vấn đề phân mảnh khi xử lý các ngôn ngữ khác, vì từ vựng BPE của GPT-2 chỉ hỗ trợ tiếng Anh. Điều này giúp mô hình hoạt động hiệu quả hơn khi phải xử lý nhiều ngôn ngữ khác nhau.
Multitask Format
Trong nghiên cứu này, nhóm tác giả tìm cách giảm bớt sự phức tạp của hệ thống nhận dạng giọng nói bằng cách phát triển một mô hình duy nhất để thực hiện toàn bộ quy trình xử lý giọng nói, thay vì chỉ dựa vào mô hình nhận dạng chính. Một hệ thống nhận dạng giọng nói đầy đủ không chỉ bao gồm việc dự đoán từ ngữ mà còn có các thành phần khác như phát hiện hoạt động giọng nói, phân biệt người nói, chuẩn hóa văn bản,... Những thành phần này trước đây thường được xử lý riêng lẻ, dẫn đến một hệ thống phức tạp.
Để đơn giản hóa, nhóm tác giả thiết kế một mô hình có thể thực hiện nhiều nhiệm vụ khác nhau trên cùng một tín hiệu âm thanh đầu vào. Họ sử dụng một định dạng đơn giản để xác định tất cả các nhiệm vụ và thông tin điều kiện dưới dạng chuỗi các token đầu vào cho bộ decoder (xem trên hình).
Nhóm tác giả đã thiết kế một mô hình đơn giản nhưng mạnh mẽ có thể thực hiện nhiều nhiệm vụ khác nhau trên cùng một tín hiệu âm thanh đầu vào. Để đạt được điều này, họ sử dụng một định dạng dễ hiểu, trong đó tất cả các nhiệm vụ và thông tin điều kiện được biểu diễn dưới dạng một chuỗi các token đầu vào cho bộ decoder.
Quy trình dự đoán của mô hình bao gồm việc xác định ngôn ngữ đang được nói, xác định nhiệm vụ (dịch <|translate|> hay phiên âm <|transcribe|>), và quyết định có dự đoán thời gian hay không. Nếu đoạn âm thanh không chứa giọng nói, mô hình dự đoán một token đặc biệt <|nospeech|> để chỉ ra điều này. Khi dự đoán timestamps, mô hình sử dụng độ phân giải thời gian 20ms và chèn các token <|notimestamps|> vào trước và sau mỗi đoạn văn bản. Cuối cùng, mô hình dự đoán một token kết thúc |endoftranscript|> để hoàn thành quy trình.
Quá trình training
Thông tin trong quá trình train Whisper như sau:
2.4. Chi tiết huấn luyện
-
Huấn luyện mô hình:
- Các mô hình với kích thước khác nhau được huấn luyện để nghiên cứu khả năng mở rộng của Whisper.
-
Kỹ thuật huấn luyện:
- Chạy dữ liệu song song trên các accelerators
- FP16 với dynamic loss scaling và activation checkpointing.
- Optimizer:
- AdamW optimizer.
- Gradient norm clipping.
- Learning rate giảm tuyến tính xuống 0 sau khi warmup trong 2048 updates đầu tiên.
- Batchsize là 256.
- Các mô hình được huấn luyện trong 220 updates (tương đương 2-3 epochs).
-
Vấn đề về Overfitting và tổng quát hóa:
- Over-fitting không phải là vấn đề do chỉ huấn luyện trong một vài epochs đầu tiên.
- Không sử dụng data augmentation hoặc regularization.
- Dựa vào sự đa dạng của tập dữ liệu lớn để khuyến khích khả năng tổng quát hóa của mô hình.
-
Quan sát đánh giá:
- Các mô hình Whisper có xu hướng ghi lại các tên người nói có vẻ hợp lý nhưng không chính xác.
- Điều này do các bản ghi trong tập dữ liệu pretrain trước đó bao gồm tên người nói -> khuyến khích model đưa ra những cái tên này
- Để tránh điều này, các mô hình Whisper được tinh chỉnh trên các bản ghi không bao gồm thông tin của người nói.
-
Chi tiết mô hình:
- Tiny: 4 layers, 384 width, 6 heads, 39M parameters.
- Base: 6 layers, 512 width, 8 heads, 74M parameters.
- Small: 12 layers, 768 width, 12 heads, 244M parameters.
- Medium: 24 layers, 1024 width, 16 heads, 769M parameters.
- Large: 32 layers, 1280 width, 20 heads, 1550M parameters.
-
Huấn luyện bổ sung:
- Sau mồ hình ban đầu, một mô hình Large bổ sung (V2) được huấn luyện với thời gian gấp 2.5 lần số epochs.
- Thêm các kỹ thuật regularization: SpecAugment, Stochastic Depth, và BPE Dropout.
Nhận xét
Các chiến lược decode cải tiến đã giúp các mô hình Whisper lớn giảm đáng kể các lỗi liên quan đến nhận thức, chẳng hạn nhầm lẫn giữa các từ có phát âm giống nhau. Tuy nhiên, vẫn còn tồn tại nhiều lỗi trong việc phiên âm dài, chẳng hạn như việc mô hình bị lặp lại, bỏ qua từ đầu hoặc cuối của đoạn âm thanh, hoặc thậm chí tạo ra các đoạn văn bản hoàn toàn không liên quan đến âm thanh thực tế. Bên cạnh đó, nhóm tác giả cho rằng việc finetune mô hình Whisper trên một bộ dữ liệu có nhãn chất lượng cao và/hoặc sử dụng học tăng cường để tối ưu hóa hiệu suất của decoder có thể giúp giảm thiểu các lỗi này hơn nữa.
Hiệu suất nhận dạng giọng nói của Whisper trên nhiều ngôn ngữ vẫn còn kém, đặc biệt là các ngôn ngữ thiểu số (chiếm số ít trong tập data train). Phân tích cho thấy hiệu suất của một ngôn ngữ được dự đoán tốt bởi lượng dữ liệu huấn luyện của ngôn ngữ đó. Do tập dữ liệu huấn luyện hiện tại chủ yếu là tiếng Anh, các ngôn ngữ khác thường có ít hơn 1000 giờ dữ liệu huấn luyện. Nhóm tác giả nhận thấy cần có nỗ lực tăng cường dữ liệu huấn luyện cho các ngôn ngữ ít phổ biến này, điều này có thể cải thiện đáng kể hiệu suất nhận dạng giọng nói tổng thể, ngay cả khi chỉ tăng một chút kích thước của tập dữ liệu training tổng thể.
Trong nghiên cứu này, nhóm tác giả tập trung vào tính mạnh mẽ của các hệ thống xử lý giọng nói và chỉ nghiên cứu hiệu suất transfer của Whisper mà không cần finetuning. Đây là một khía cạnh quan trọng vì nó thể hiện độ tin cậy chung của mô hình. Tuy nhiên, trong nhiều lĩnh vực có sẵn dữ liệu giọng nói được gán nhãn chất lượng cao, kết quả có thể được cải thiện hơn nữa thông qua việc finetuning.
Kết luận
Whisper đã chứng minh rằng việc mở rộng quy mô supervised training có thể mang lại hiệu quả đáng kể trong bài toán nhận dạng giọng nói, mặc dù trước đây chưa được đánh giá đúng mức. Nhóm tác giả đã đạt được kết quả ấn tượng mà không cần sử dụng các kỹ thuật self-supervised và self-training phức tạp. Thay vào đó, họ tập trung vào việc huấn luyện mô hình trên một tập dữ liệu được gán nhãn lớn, đa dạng, và áp dụng phương pháp zero-transfer mà không cần finetuning.
Cách tiếp cận này đã cải thiện đáng kể sức mạnh của hệ thống nhận dạng giọng nói. Điều này cho thấy rằng việc đơn giản hóa quy trình và tập trung vào chất lượng của dữ liệu huấn luyện có thể mang lại kết quả vượt trội. Nhóm tác giả đã chứng minh rằng một mô hình được train kỹ trên một tập dữ liệu phong phú có thể đạt được độ tin cậy cao và hiệu suất tốt mà không cần đến các phương pháp phức tạp hơn.
Tài liệu tham khảo
All rights reserved
