Apache Kafka và Confluent Kafka khác nhau thế nào ở góc nhìn kiến trúc hệ thống
Trong các hệ thống dữ liệu hiện đại, bài toán không còn dừng ở việc “truyền message từ A sang B”, mà nằm ở khả năng xây dựng một nền tảng event streaming đủ ổn định để phục vụ đồng thời nhiều nhu cầu như thu thập dữ liệu, tích hợp hệ thống, xử lý thời gian thực, phân tích hành vi và phản ứng tức thời theo sự kiện. Chính vì vậy, khi doanh nghiệp triển khai kiến trúc hướng sự kiện, hai cái tên thường được đặt lên bàn cân là Apache Kafka và Confluent Kafka.
Điểm đáng chú ý là đây không phải hai công nghệ hoàn toàn tách biệt. Confluent Kafka được xây dựng trên nền Kafka, nhưng mở rộng thêm lớp công cụ, dịch vụ và khả năng quản trị dành cho môi trường doanh nghiệp. Vì thế, lựa chọn giữa hai bên thực chất không đơn giản là chọn phần mềm nào tốt hơn, mà là chọn mô hình vận hành nào phù hợp hơn với năng lực kỹ thuật, mức độ phức tạp của hệ thống và chiến lược mở rộng trong dài hạn.
Nhìn đúng bản chất Apache Kafka và Confluent Kafka

Apache Kafka là nền tảng event streaming mã nguồn mở, được thiết kế để xử lý dữ liệu theo thời gian thực với thông lượng cao, độ trễ thấp và khả năng mở rộng theo chiều ngang. Về bản chất, Kafka hoạt động như một distributed commit log, nơi dữ liệu được ghi tuần tự vào các topic, chia nhỏ thành partition và được tiêu thụ bởi nhiều consumer độc lập. Nhờ kiến trúc này, Kafka không chỉ là message broker mà còn là một hạ tầng truyền dẫn sự kiện có thể trở thành xương sống dữ liệu cho cả hệ thống.
Confluent Kafka lại đi theo một hướng khác. Thay vì chỉ cung cấp lõi truyền dữ liệu như Kafka thuần, Confluent bổ sung một hệ sinh thái hoàn chỉnh hơn để doanh nghiệp triển khai, giám sát, bảo vệ và mở rộng nền tảng streaming. Nói cách khác, nếu Kafka là “engine”, thì Confluent giống như một lớp platform được xây dựng quanh engine đó để giảm độ khó trong vận hành thực tế.
Sự khác biệt lớn nhất nằm ở chỗ: Kafka cho bạn quyền kiểm soát rất sâu, nhưng đổi lại bạn phải tự gánh nhiều trách nhiệm kỹ thuật; còn Confluent giúp rút bớt độ phức tạp đó bằng cách đóng gói nhiều thành phần quan trọng thành một nền tảng dễ vận hành hơn.
So sánh từ góc độ kiến trúc triển khai
Apache Kafka phù hợp với mô hình tự xây dựng hạ tầng
Khi dùng Apache Kafka, doanh nghiệp thường phải tự thiết kế cluster, cấu hình broker, phân vùng topic, replication factor, retention policy, cơ chế bảo mật, theo dõi độ trễ, cân bằng tải và xử lý sự cố. Điều này phù hợp với các tổ chức muốn kiểm soát chi tiết toàn bộ hệ thống và có đội ngũ platform engineering hoặc DevOps đủ mạnh để quản lý hạ tầng ở mức sâu.
Ưu điểm của cách tiếp cận này là mức độ tùy biến rất lớn. Doanh nghiệp có thể chọn cách triển khai on-premise, private cloud hoặc hybrid tùy bài toán tuân thủ dữ liệu, độ trễ nội bộ và mô hình hạ tầng sẵn có. Kafka thuần đặc biệt phù hợp khi tổ chức muốn thiết kế một data backbone riêng, tích hợp chặt chẽ với hệ thống nội bộ thay vì phụ thuộc nhiều vào nền tảng bên ngoài.
Tuy nhiên, càng đi sâu vào triển khai thực tế, Kafka càng bộc lộ rõ việc không phải cứ cài cluster là xong. Để cluster hoạt động ổn định trong môi trường production, đội ngũ kỹ thuật phải làm tốt nhiều lớp việc: capacity planning, tuning disk I/O, tối ưu network throughput, phân phối partition hợp lý, chống skew tải, giám sát consumer lag và xây dựng quy trình backup, restore, failover.
Confluent Kafka thiên về mô hình platform hóa Kafka
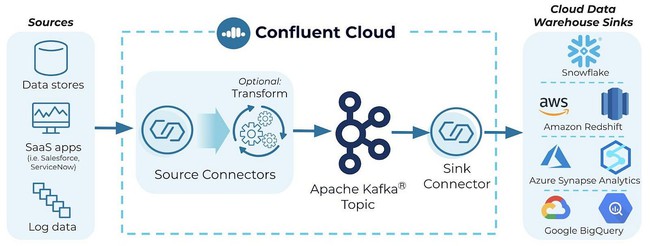
Confluent Kafka giải quyết bài toán khác. Thay vì để doanh nghiệp tự lắp ghép quá nhiều thành phần, Confluent cung cấp sẵn các công cụ và dịch vụ hỗ trợ để triển khai Kafka theo hướng platform hóa. Điều này giúp rút ngắn thời gian đưa hệ thống vào vận hành, đồng thời giảm rủi ro do sai sót cấu hình hoặc thiếu kinh nghiệm quản trị cluster.
Ở góc nhìn kiến trúc, Confluent phù hợp với các tổ chức muốn dùng Kafka như một năng lực nền tảng, nhưng không muốn biến đội ngũ nội bộ thành “đơn vị vận hành Kafka toàn thời gian”. Đây là khác biệt rất quan trọng. Trong nhiều doanh nghiệp, thứ họ cần không chỉ là một cụm broker chạy được, mà là một nền tảng event streaming có thể đưa vào sử dụng nhanh, dễ mở rộng, dễ tích hợp và có chuẩn hỗ trợ rõ ràng.
Khác biệt ở lớp vận hành và độ phức tạp kỹ thuật
Một trong những yếu tố tạo ra khoảng cách lớn nhất giữa Kafka thuần và Confluent là chi phí vận hành ẩn phía sau.
Với Apache Kafka, doanh nghiệp có thể không mất tiền license, nhưng sẽ phải đầu tư mạnh vào kỹ năng kỹ thuật. Vận hành Kafka không chỉ là theo dõi CPU hay RAM. Hệ thống còn chịu ảnh hưởng lớn bởi tốc độ ghi đĩa, băng thông mạng, chính sách retention, số lượng partition, tốc độ rebalance của consumer group và độ ổn định của cơ chế replication. Khi quy mô tăng lên, các bài toán như leader election, ISR consistency, log compaction, throughput bottleneck hay lag accumulation trở nên khó kiểm soát hơn nhiều.
Confluent giúp giảm đáng kể sức ép này bằng cách bổ sung các công cụ quản trị, giám sát và tối ưu ở mức platform. Điều đó đặc biệt có giá trị trong các môi trường nhiều team cùng sử dụng event streaming, nơi hạ tầng Kafka không chỉ phục vụ một ứng dụng mà trở thành dịch vụ dùng chung cho toàn doanh nghiệp. Khi đó, bài toán không còn là cài Kafka thế nào, mà là vận hành nó như một nền tảng nội bộ có SLA, quy chuẩn truy cập và khả năng mở rộng ổn định.
So sánh khả năng mở rộng ở quy mô lớn
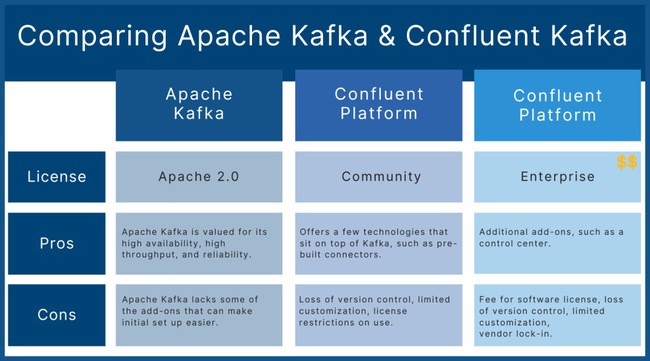
Kafka mạnh ở khả năng scale ngang, nhưng cần kinh nghiệm thực chiến
Về lý thuyết, Kafka có thể mở rộng rất tốt bằng cách tăng số broker và phân phối lại partition. Nhưng trên thực tế, scale không chỉ là “thêm node”. Khi lưu lượng tăng mạnh, doanh nghiệp cần tính tới rất nhiều yếu tố như số lượng partition tối ưu, sự phân bố leader giữa các broker, mức replication phù hợp, ảnh hưởng của network cross-zone và độ trễ tiêu thụ ở consumer side.
Nếu thiết kế không tốt, cluster vẫn có thể gặp các vấn đề như broker hotspot, lag cục bộ, rebalance kéo dài hoặc tăng độ trễ toàn hệ thống khi có một nhóm consumer hoạt động thiếu ổn định. Điều này khiến Kafka trở thành công nghệ rất mạnh, nhưng không hề “dễ scale” theo nghĩa đơn giản.
Confluent có lợi thế ở lớp tự động hóa và tối ưu vận hành
Confluent tiếp cận khả năng mở rộng theo hướng giảm thao tác thủ công và giảm rủi ro vận hành. Thay vì để đội ngũ kỹ thuật phải tự xử lý toàn bộ các tác vụ scale cluster, cân bằng tải hay theo dõi hiệu năng, nền tảng này mang lại trải nghiệm dễ kiểm soát hơn ở các môi trường production lớn.
Lợi ích của điều đó đặc biệt rõ với doanh nghiệp đang tăng trưởng nhanh, nơi dữ liệu không tăng tuyến tính mà thường tăng đột biến theo chiến dịch, mùa cao điểm hoặc nhu cầu tích hợp thêm hệ thống. Trong bối cảnh đó, một nền tảng có khả năng scale linh hoạt và ít phụ thuộc thao tác thủ công sẽ giúp doanh nghiệp tránh được nhiều rủi ro downtime hoặc nghẽn cục bộ.
Khác biệt ở bảo mật và quản trị truy cập
Bảo mật trong hệ thống streaming không đơn giản là bật SSL hay gắn ACL. Khi Kafka trở thành trục dữ liệu của doanh nghiệp, mỗi topic đều có thể chứa dữ liệu nhạy cảm liên quan đến giao dịch, hành vi người dùng, log hệ thống, thông tin nội bộ hoặc dữ liệu tích hợp đa dịch vụ. Vì thế, lớp bảo mật cần được nhìn như một phần của kiến trúc nền tảng chứ không chỉ là phụ kiện kèm theo.
Apache Kafka có hỗ trợ các cơ chế quan trọng như TLS, SASL và ACL. Tuy nhiên, phần khó nằm ở việc triển khai, chuẩn hóa và duy trì nhất quán các cơ chế đó trong thực tế. Khi số lượng topic, producer, consumer và team phát triển tăng lên, việc kiểm soát quyền truy cập, audit hành vi và quản lý thay đổi cấu hình sẽ phức tạp hơn rất nhiều.
Confluent thường được đánh giá cao hơn ở điểm này vì cung cấp thêm các lớp bảo mật và công cụ quản trị phù hợp hơn với môi trường doanh nghiệp. Điều đó giúp giảm khoảng cách giữa yêu cầu an toàn dữ liệu trên giấy và khả năng vận hành thực tế trong hệ thống production.
Hỗ trợ kỹ thuật và tính liên tục của dịch vụ
Đây là điểm mà nhiều doanh nghiệp chỉ nhận ra tầm quan trọng khi hệ thống bắt đầu đi vào production với lưu lượng thật.
Với Apache Kafka, tổ chức thường dựa vào cộng đồng, tài liệu kỹ thuật, GitHub issues, forum và kinh nghiệm nội bộ để xử lý lỗi. Cách tiếp cận này hoàn toàn hợp lý với các team kỹ thuật mạnh, chủ động và có thể tự giải quyết phần lớn sự cố. Nhưng khi hệ thống đóng vai trò sống còn trong chuỗi xử lý dữ liệu, việc không có đầu mối hỗ trợ chính thức có thể trở thành rủi ro lớn.
Confluent giải quyết vấn đề này bằng dịch vụ hỗ trợ và cam kết SLA rõ ràng hơn. Điều đó không chỉ mang ý nghĩa “có người hỗ trợ khi lỗi”, mà còn giúp doanh nghiệp xây dựng niềm tin khi đưa Kafka vào các nghiệp vụ quan trọng, nơi downtime hay mất dữ liệu có thể kéo theo ảnh hưởng lớn đến vận hành và doanh thu.
Bài toán chi phí không chỉ là license hay miễn phí
Nhiều người nhìn vào Apache Kafka và cho rằng đây là lựa chọn tiết kiệm hơn vì không mất chi phí bản quyền. Cách nhìn này chỉ đúng một phần.
Chi phí thực sự của Kafka nằm ở tổng chi phí sở hữu. Ngoài hạ tầng phần cứng hoặc cloud resource, doanh nghiệp còn phải tính tới chi phí nhân sự, thời gian triển khai, công sức vận hành, xử lý sự cố, tối ưu hiệu năng, xây dashboard giám sát, xây quy trình backup và đào tạo đội ngũ. Khi hệ thống càng phức tạp, các chi phí này càng tăng mạnh và đôi khi vượt xa phần license mà doanh nghiệp cố gắng tiết kiệm ban đầu.
Confluent có thể khiến chi phí trực tiếp cao hơn, nhưng bù lại giúp giảm đáng kể chi phí gián tiếp liên quan đến vận hành và độ trễ triển khai. Với doanh nghiệp cần đưa sản phẩm ra thị trường nhanh, hoặc không muốn dồn quá nhiều nguồn lực kỹ thuật cho bài toán hạ tầng streaming, đây lại có thể là phương án tối ưu hơn về kinh tế tổng thể.
Nên chọn Apache Kafka trong trường hợp nào
Apache Kafka là lựa chọn đáng cân nhắc khi doanh nghiệp muốn nắm quyền kiểm soát sâu đối với kiến trúc hệ thống, có đội ngũ kỹ thuật mạnh và sẵn sàng đầu tư vào năng lực vận hành nội bộ. Nó đặc biệt phù hợp với các tổ chức đã có nền tảng DevOps, SRE hoặc platform engineering trưởng thành, đủ khả năng tự xây dựng một streaming platform riêng.
Ngoài ra, Kafka thuần cũng thích hợp trong các tình huống mà doanh nghiệp có yêu cầu đặc thù về hạ tầng, muốn triển khai linh hoạt trong môi trường on-premise hoặc private cloud, hoặc cần tối ưu chi phí license ở giai đoạn đầu nhưng chấp nhận đánh đổi bằng nguồn lực vận hành.
Nếu mục tiêu của tổ chức là làm chủ công nghệ, tự thiết kế kiến trúc, tự tối ưu hiệu năng và không phụ thuộc vào hệ sinh thái thương mại, dịch vụ Kafka là lựa chọn rất mạnh.
Khi nào Confluent Kafka là phương án hợp lý hơn
Confluent Kafka phù hợp hơn với doanh nghiệp muốn dùng Kafka như một năng lực nền tảng sẵn sàng cho production, thay vì tự gánh toàn bộ phần nặng nhất của vận hành. Điều này đặc biệt đúng với các tổ chức đang chạy nhiều use case dữ liệu thời gian thực cùng lúc, cần cơ chế quản trị rõ ràng, yêu cầu bảo mật cao và không muốn chậm tiến độ chỉ vì hạ tầng streaming quá phức tạp.
Confluent cũng phù hợp trong bối cảnh doanh nghiệp ưu tiên tốc độ triển khai, độ ổn định, khả năng mở rộng nhanh và cần có hỗ trợ chính thức khi sự cố xảy ra. Với các team sản phẩm, data hoặc tích hợp hệ thống, giá trị lớn nhất của Confluent không nằm ở việc “Kafka chạy tốt hơn”, mà ở chỗ nền tảng này giúp họ bớt phải lo về Kafka để tập trung vào nghiệp vụ chính.
Kết luận
Apache Kafka và Confluent Kafka không đại diện cho hai công nghệ đối đầu hoàn toàn, mà phản ánh hai cách tiếp cận khác nhau trong việc xây dựng nền tảng event streaming.
Apache Kafka phù hợp với doanh nghiệp muốn tự làm chủ hạ tầng, có đội ngũ kỹ thuật đủ mạnh và sẵn sàng đầu tư dài hạn cho vận hành. Ngược lại, Confluent Kafka phù hợp với tổ chức cần một nền tảng hoàn chỉnh hơn, giảm độ phức tạp triển khai, tăng khả năng quản trị và đảm bảo tính liên tục của dịch vụ ở môi trường doanh nghiệp.
Nói ngắn gọn, nếu bài toán của bạn là quyền kiểm soát và tùy biến sâu, Kafka thuần là hướng đi hợp lý. Nếu bài toán là giảm gánh nặng vận hành và tăng tốc triển khai hệ thống dữ liệu thời gian thực, Confluent Kafka sẽ là phương án đáng cân nhắc hơn.
Nguồn tham khảo: https://bizflycloud.vn/tin-tuc/so-sanh-apache-kafka-voi-confluent-kafka-20260323172939288.htm
All rights reserved
