Apache Kafka là gì? Tìm hiểu nền tảng xử lý dữ liệu thời gian thực được sử dụng bởi hàng nghìn hệ thống lớn
Giới thiệu
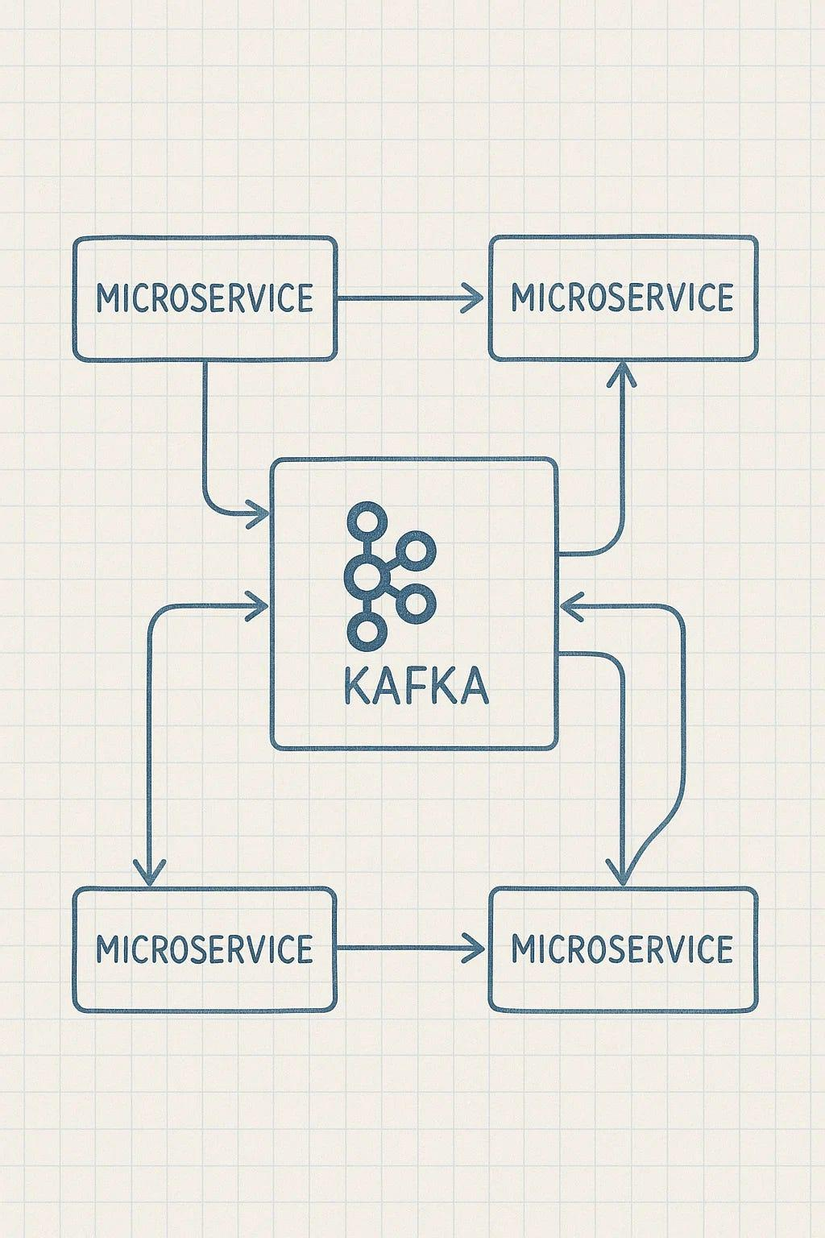
Trong các hệ thống phần mềm hiện đại, đặc biệt là các hệ thống Microservices hoặc xử lý dữ liệu lớn (Big Data), việc truyền dữ liệu giữa các thành phần là một bài toán quan trọng.
Giả sử một sàn thương mại điện tử phát sinh hàng nghìn đơn hàng mỗi phút. Sau khi khách hàng đặt hàng thành công, hệ thống cần thực hiện đồng thời nhiều công việc:
- Gửi email xác nhận
- Gửi thông báo đến ứng dụng di động
- Cập nhật tồn kho
- Tính toán doanh thu
- Ghi log hoạt động
- Đồng bộ dữ liệu sang hệ thống phân tích
Nếu mỗi dịch vụ gọi trực tiếp lẫn nhau, hệ thống sẽ nhanh chóng trở nên phức tạp và khó mở rộng.
Đây chính là lúc Apache Kafka phát huy vai trò của mình.
Apache Kafka là gì?
Apache Kafka là một nền tảng xử lý luồng dữ liệu (Event Streaming Platform) mã nguồn mở được phát triển ban đầu tại LinkedIn và sau đó được đóng góp cho Apache Software Foundation.
Kafka được thiết kế để:
- Thu thập dữ liệu
- Lưu trữ dữ liệu
- Truyền tải dữ liệu
- Xử lý dữ liệu theo thời gian thực
Kafka có khả năng xử lý hàng triệu sự kiện (event) mỗi giây với độ trễ thấp và độ tin cậy cao.
Hiện nay Kafka được sử dụng rộng rãi trong:
- Thương mại điện tử
- Ngân hàng
- Viễn thông
- IoT
- Hệ thống phân tích dữ liệu
- Các nền tảng mạng xã hội
Vì sao cần Kafka?
Hãy xem một ví dụ đơn giản.
Cách tiếp cận truyền thống
Order Service
|
+--> Email Service
|
+--> Inventory Service
|
+--> Analytics Service
|
+--> Notification Service
Mỗi khi có đơn hàng mới, Order Service phải gọi trực tiếp đến nhiều dịch vụ khác.
Vấn đề:
- Tăng độ phụ thuộc giữa các service
- Khó mở rộng
- Dễ xảy ra lỗi dây chuyền
- Khó thêm chức năng mới
Sử dụng Kafka
Order Service
|
v
Kafka
|
+--> Email Service
|
+--> Inventory Service
|
+--> Analytics Service
|
+--> Notification Service
Lúc này Order Service chỉ cần gửi một sự kiện vào Kafka.
Các service khác sẽ tự đọc dữ liệu từ Kafka và xử lý theo nhu cầu của mình.
Điều này giúp giảm sự phụ thuộc giữa các thành phần trong hệ thống.
Các thành phần chính của Kafka
Producer
Producer là thành phần gửi dữ liệu vào Kafka.
Ví dụ:
- Order Service gửi sự kiện tạo đơn hàng
- Payment Service gửi sự kiện thanh toán thành công
producer.send(orderCreatedEvent);
Producer chỉ quan tâm đến việc gửi dữ liệu mà không cần biết ai sẽ nhận dữ liệu đó.
Topic
Topic có thể hiểu là nơi chứa các sự kiện.
Ví dụ:
order-created
payment-success
user-registered
Khi Producer gửi dữ liệu, dữ liệu sẽ được ghi vào một Topic.
Consumer
Consumer là thành phần đọc dữ liệu từ Kafka.
Ví dụ:
- Email Service đọc sự kiện order-created
- Analytics Service đọc sự kiện order-created
- Notification Service đọc sự kiện order-created
Một sự kiện có thể được nhiều Consumer xử lý độc lập.
Broker
Broker là máy chủ Kafka thực tế lưu trữ dữ liệu.
Trong môi trường production, Kafka thường gồm nhiều Broker tạo thành một Cluster nhằm tăng khả năng mở rộng và đảm bảo tính sẵn sàng.
Kafka hoạt động như thế nào?
Giả sử khách hàng tạo đơn hàng.
Bước 1
Order Service tạo sự kiện:
{
"orderId": 1001,
"userId": 50,
"amount": 1500000
}
Bước 2
Producer gửi sự kiện vào Topic:
order-created
Bước 3
Kafka lưu trữ sự kiện.
Bước 4
Các Consumer lần lượt nhận dữ liệu:
- Email Service gửi email
- Inventory Service trừ tồn kho
- Analytics Service cập nhật báo cáo
- Notification Service gửi push notification
Mỗi service hoạt động độc lập với nhau.
Nếu Email Service gặp lỗi, Inventory Service vẫn có thể tiếp tục hoạt động bình thường.
Partition là gì?
Một trong những lý do Kafka có hiệu năng cao là nhờ Partition.
Ví dụ:
order-created
Partition 0
Partition 1
Partition 2
Partition 3
Dữ liệu được phân tán vào nhiều Partition khác nhau.
Lợi ích:
- Tăng tốc độ ghi dữ liệu
- Tăng tốc độ đọc dữ liệu
- Hỗ trợ xử lý song song
- Dễ dàng mở rộng hệ thống
Khi lượng dữ liệu tăng lên, chúng ta chỉ cần bổ sung thêm Broker và Partition.
Consumer Group
Consumer Group là khái niệm rất quan trọng trong Kafka.
Ví dụ:
Email Group
Consumer A
Consumer B
Consumer C
Kafka sẽ tự động phân phối Partition cho các Consumer.
Ưu điểm:
- Cân bằng tải
- Tăng khả năng xử lý
- Dễ scale hệ thống
Nếu một Consumer bị lỗi, Kafka sẽ phân phối lại công việc cho Consumer khác trong cùng Group.
Kafka lưu dữ liệu trong bao lâu?
Một điểm khác biệt giữa Kafka và các Message Queue truyền thống là Kafka không xóa message ngay sau khi Consumer đọc.
Ví dụ:
- Lưu 1 ngày
- Lưu 7 ngày
- Lưu 30 ngày
hoặc theo dung lượng lưu trữ.
Điều này cho phép:
- Replay dữ liệu
- Khôi phục hệ thống
- Chạy lại báo cáo
- Debug lỗi
Đây là tính năng cực kỳ hữu ích trong các hệ thống lớn.
Kafka và RabbitMQ khác nhau như thế nào?
Kafka và RabbitMQ đều là Message Broker nhưng được thiết kế cho các mục đích khác nhau.
Kafka phù hợp khi:
- Dữ liệu lớn
- Streaming realtime
- Event-driven architecture
- Analytics
- Microservices quy mô lớn
RabbitMQ phù hợp khi:
- Queue tác vụ
- Job processing
- Workflow nghiệp vụ
- Hệ thống vừa và nhỏ
Trong thực tế, nhiều doanh nghiệp vẫn sử dụng cả Kafka và RabbitMQ cho các mục đích khác nhau.
Kafka trong hệ sinh thái Java
Kafka được sử dụng rất phổ biến trong các dự án Java sử dụng:
- Spring Boot
- Microservices
- Event-Driven Architecture
- CQRS
- Saga Pattern
Ví dụ sử dụng Spring Kafka:
@KafkaListener(topics = "order-created")
public void consume(OrderCreatedEvent event) {
System.out.println(event);
}
Chỉ với vài dòng code, ứng dụng đã có thể lắng nghe và xử lý sự kiện từ Kafka.
Kết luận
Apache Kafka đã trở thành một trong những nền tảng quan trọng nhất trong kiến trúc hệ thống hiện đại. Thay vì để các service giao tiếp trực tiếp với nhau, Kafka đóng vai trò trung gian giúp truyền tải dữ liệu một cách hiệu quả, tin cậy và dễ mở rộng.
Đối với các Java Backend Developer, việc hiểu các khái niệm như Producer, Consumer, Topic, Partition và Consumer Group là bước khởi đầu quan trọng để xây dựng các hệ thống Microservices quy mô lớn. Mặc dù Kafka có nhiều khái niệm cần học, nhưng một khi đã nắm vững, đây sẽ là công cụ cực kỳ mạnh mẽ giúp giải quyết các bài toán xử lý dữ liệu thời gian thực trong doanh nghiệp.
All rights reserved
