Apache Kafka cho người mới bắt đầu
Bài đăng này đã không được cập nhật trong 4 năm
Giới thiệu về Apache Kafka
Để có thể giúp bạn dễ hình dung Apache Kafka là gì hãy cùng xem ví dụ thực tế sau đây.
Một công ty bắt đầu với hệ thống đơn giản chỉ bao gồm một source system có thể là database hay 1 file log nào đó, rồi xử lý để chuyển đến hệ thống khác.
 Rất đơn giản đúng không, nhưng một khoảng thời gian sau đó, công ty phát triển, họ xây thêm nhiều source system khác cũng như sẽ có thêm nhiều nơi muốn sử dụng các dữ liệu đó. Các hệ thống sẽ gọi một cách riêng lẻ, tức là source system phải gửi dữ liệu đến từng hệ thống khác.
Rất đơn giản đúng không, nhưng một khoảng thời gian sau đó, công ty phát triển, họ xây thêm nhiều source system khác cũng như sẽ có thêm nhiều nơi muốn sử dụng các dữ liệu đó. Các hệ thống sẽ gọi một cách riêng lẻ, tức là source system phải gửi dữ liệu đến từng hệ thống khác.
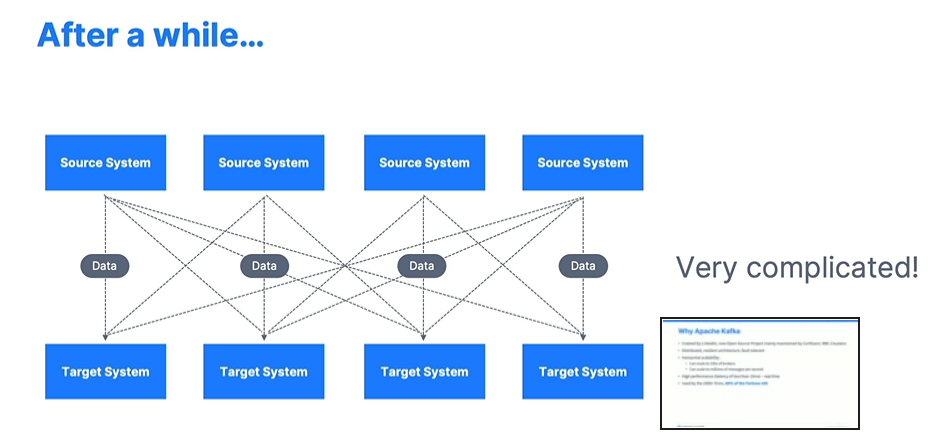
Chưa kể đến tùy vào công nghệ hệ thống đang sử dụng mà kiểu phương phức cũng như kiểu dữ liệu cũng sẽ khác nhau gây nên sự phức tạp trong việc truyền và nhận dữ liệu giữa các hệ thống khác nhau.
Apache Kafke xử lý vấn đề đó bằng cách biến nó thành hệ thống trung gian giữa nơi nhận và gửi. Hệ thống nguồn chỉ cần gửi dữ liệu đến Kafka và hệ thống đích chỉ việc lấy dữ liệu từ trong Kafka ra mà thôi
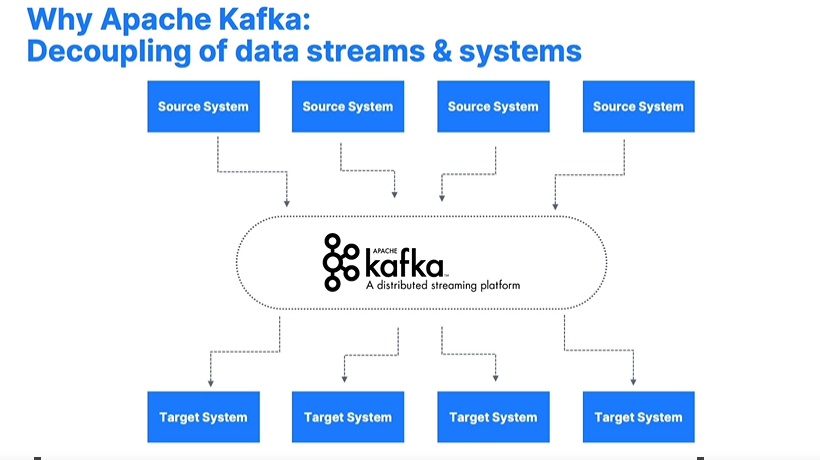
Khái niệm chính
Kafka Topic
Kafka Topic là một luồng dữ liệu cụ thể, bạn có thể đặt tên nó bất kì như logs, purchases, products,...Nó giống như là bảng (table) trong database vậy đó, khác là nó không có bất cứ ràng buộc nào. Bạn có thể có nhiều Topic trong một cụm Kafka và được phân biệt bằng tên của nó. Kiểu dữ liệu của một Topic có thể là bất cứ gì như json, avro, binary...Chúng ta không thể truy cấn trực tiếp dữ liệu chứa bên trong Topic mà phải thông qua Producer (nơi gửi dữ liệu đến Topic) và Consumer (nơi đọc dữ liệu từ Topic).
Partitions và Offsets
Các Topic được chia thành những phần nhỏ hơn để lưu trữ trong cụm Kafka được gọi là Partition. Dữ liệu trong Partition còn được gọi là các message. Message trong một partition sẽ được ghi và đọc một cách có thứ tự. Do đó mỗi message sẽ có có một id riêng và sẽ được tăng dần khi có message khác thêm vào, id đó được gọi là offset. Message trong partition không thể thay đổi được, tức là một khi message được gửi vào partition thì chúng ta không thể xóa nó cũng như thay đổi kiểu dữ liệu bên trong nó.
Producers
Producers ghi dữ liệu vào các topic, nó biết được partition nào nó sẽ ghi vào. Kafka Producers sẽ có cơ chế tự phục hồi khi có bất kì sự cố máy chủ nào xảy ra và biết cân bằng tải dữ liệu giữa các partition của cùng 1 topic
Producers: Message keys
Message có thể được Producer gắn vào một giá trị gọi là key. Khi giá trị này không có thì các message sẽ được phân bố theo kĩ thuật chung chẳng hạn như message gửi đến partition A rồi mới đến partition B. Ngược lại các message có chung một key thì sẽ được Producer gửi đến cùng 1 partition. Rất phù hợp nếu như chúng ta muốn đọc message một cách có thứ tự
Consumers
Consumers lấy dữ liệu từ 1 topic, đọc các message lần lượt từ offset thấp đến cao trong mỗi partition. Dữ liệu lưu trong Kafka có dạng là bytes. Cho nên để Consumer có thể đọc cũng xử lý được các message này thì Consumer và Producer phải có chung một kiểu dữ liệu nếu kiểu dữ liệu Producer gửi thay đổi thì chúng ta sẽ phải tạo ra một Consumer khác để có thể xử lý kiểu dữ liệu đó
Consumer Groups
Các Consumers có thể tập hợp đọc dữ liệu như một Group. Tức là các thành viên trong một Group sẽ đọc các Partition khác nhau. Giả sử Topic A có 5 partitions, chúng ta có 3 Consumers thì mỗi Consumer sẽ đọc message từ các partition khác nhau không trùng lặp nhau.
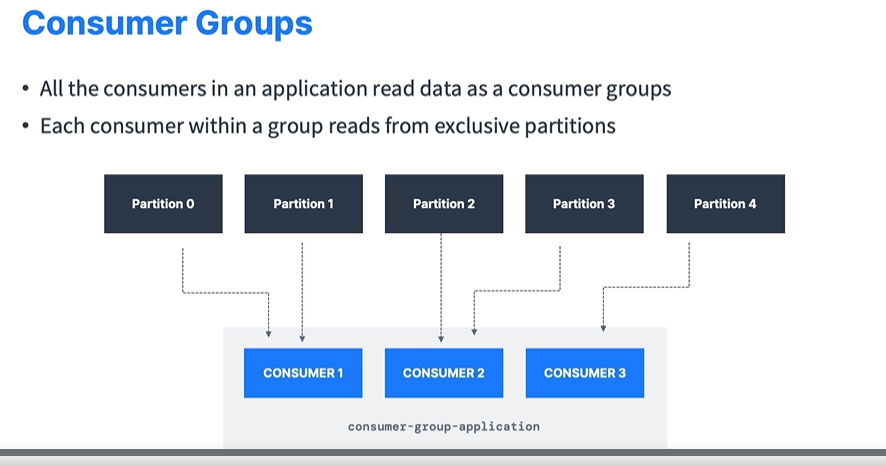
Nếu số lượng Consumer lớn hơn số lượng partition thì Consumer dư sẽ ở trạng thái inactive (không hoạt động ) đến khi nào chúng ta thêm partition thì Consumer sẽ active trở lại

Consumer Offsets
Đây là chứng năng khác quan trọng trong Kafka, mỗi Group sẽ có một group id cụ thể, group id này được dùng để đánh dấu vị trí offset mà Consumer Group có group id đó đã đọc được. Giả sử nếu Consumer Group này gặp sự cố và sau khi khắc phục xong thì Kafka sẽ biết Consumer Group đã đọc đến đâu và có thể dùng nó để đọc lại các tin nhắn bị miss trong lúc gặp sự cố.
Việc đánh dấu offset này được lưu lại trong Kafka Topic, Consumer sẽ không lưu trữ nó. Ngoài ra sẽ có 3 cơ chế cho việc đánh dấu này:
- At least once: Chỉ khi nào Consumer xử lý xong message thì mới đánh dấu offset, nếu khi gặp sự cố thì Kafka có thể đọc lại những tin nhắn này một lần nữa đến khi nào Consumer xử lý xong thì mới đánh dấu vị trí offset mới
- At most once: Đánh dấu offset ngay khi message được đọc, cho nên khi có sự cố thì không thế đọc lại các message đã bị miss
- Exactly once: Message chỉ được đọc 1 lần thông qua tranction API, Kafka Stream API.
Mặc định, Java consumers sẽ tự động đánh dấu offset theo cơ chế at least once để bảo đảm các message được đọc một cách đầy đủ
Trong bài viết tiếp theo mình sẽ tạo ra 2 application cho Producer và Consumer, cách thực hiện cũng như các cấu hình cần thiết để chạy bằng Java nhé
All rights reserved
