Apache Flink - Quick guide (Phần 1)
Bài đăng này đã không được cập nhật trong 6 năm
Apache Flink - Quick guide (Phần 1)
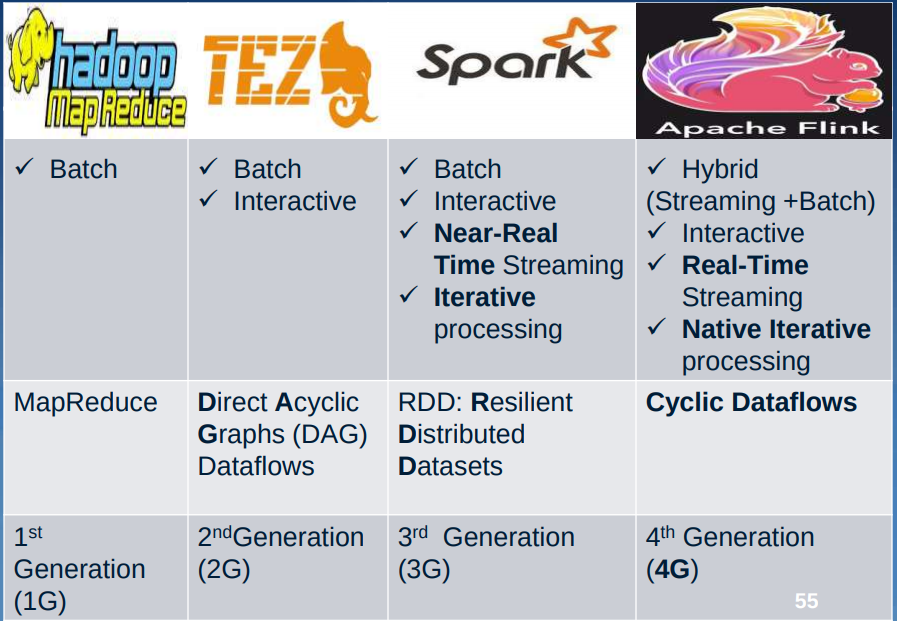
Hiện nay, Big data đã trở nên quá phổ biến, nó cũng là những vấn đề mà từ những công ty lớn cho đến nhiều start-up sẽ phải đối mặt. Từ đó cũng đã kéo theo sự xuất hiện, phát triển của nhiều công cụ và framework để giúp xử lý và lưu trữ dữ liệu. Có một vài framework phổ biến như Hadoop, Spark, Hive, Pig, Storm và Zookeeper. Trong bài này chúng ta sẽ thảo luận về Apache Flink - một framework được xem là 4G (4th Generation) của phân tích Bigdata.
I- Batch và Real-time Processing
Trong Bigdata có 2 loại xử lý:
• Batch Processing
• Real-time Processing
Xử lý trên data được thu thập theo thời gian được gọi là Batch Processing. Ví dụ, manager của ngân hàng muốn xử lý data trong một tháng vừa qua để biết số lượng tấm séc (chi phiếu) bị hủy trong tháng vừa qua.
Xử lý dựa trên dữ liệu tức thời trả về kết quả tức thời được gọi là Real-time Processing. Ví dụ, quản lý ngân hàng nhận được cảnh báo gian lận ngay sau khi giao dịch gian lận xẩy ra.
Bảng sau đây liệt kê sự khác biệt giữa Batch và Real-time Processing:

Ngày nay, Real-time Processing đang được sử dụng rất nhiều trong mọi tổ chức. Sử dụng trong những trường hợp như phát hiện gian lận, cảnh báo tấn công mạng yêu cầu xử lý dữ liệu tức,... ; một sự chậm trễ thậm chí vài mili giây có thể có tác động rất lớn. Một công cụ lý tưởng cho các trường hợp như vậy là một công cụ không chỉ nhập data dưới dạng Batch mà còn có thể nhập dưới dạng stream. Và Apache -Flink là một công cụ như vậy, có thể xử lý Real-time.
II-Hệ sinh thái trên Apache Flink
Sơ đồ dưới đây các lớp khác nhau của hệ sinh thái Apache Flink
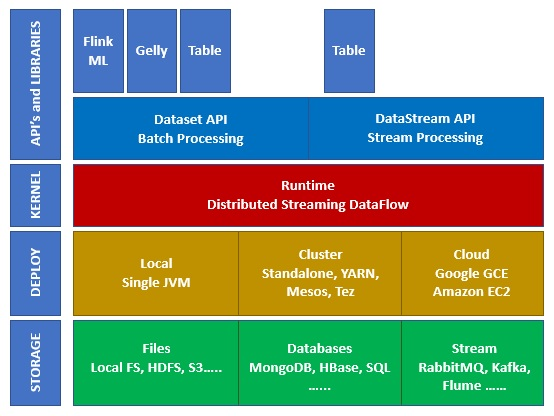
Store
Flink có nhiều lựa chọn từ đó có thể đọc ghi dữ liệu, dưới đây là một số hệ thống Flink có thể đọc ghi dữ liệu: HDFS – Hadoop Distributed File System Local-FS – Local File System S3 –Simple Storage Service (Amazon) Hbase – NoSQL Database trong hệ sinh thái Hadoop MongoDB – NoSQL Database RDBMS – Cơ sở dữ liệu quan hệ Kafka – Distributed messaging Queue RabbitMQ – Messaging Queue Flume – Data Collection and Aggregation Too
Deploy
Ở lớp thứ 2 là quản lý triển khai và tài nguyên. Flink có thể deploy ở những chế độ: + Local mode: ở trên 1 node, một JVM + Cluster: Trên cụm nhiều node với các trình quản lý tài nguyên - Standalone: đây là trình quản lý tài nguyên mặc định đi kèm với Flink - YARN: đây là trình quả lý tài nguyên rất phổ biến, một phần của Hadoop, được giới thiệu trong Hadoop 2.X - Mesos: + Cloud: Flink có thể deploy trên Amazon hoặc google cloud
Kernel
Đây là lớp runtime, là lớp chính giúp Flink xử lý phân tán, khả năng chị lỗi, độ ổn định...
** APIs & Libraries **
Đây là lớp trên cùng và là lớp quan trọng nhất của Apache Flink. Nó có Dataset APIs, đảm nhiệm việc Batch Processing, và Datastream APIs, phụ trách stream processing. Ngoài ra còn có các thư viện như Flink ML (cho học máy), Gelly (để xử lý đồ thị), Tables cho SQL. Ở tầng này cung cấp nhưng tính năng đa dạng cho Flink.
III- Tính năng của Flink
Dưới đây là một số tính năng của Apache Flink:
- Nó có streaming processor có thể chạy cả batch và stream processing.
- Nó có thể xử lý data với tốc độ rất nhanh.
- Có các API cho Java, Scala, Python.
- Cung cấp API cho các operator phổ biến và rất dễ dàng cho các lập trình viên sử dụng.
- Khả năng chịu lỗi cao, nếu một nút, một ứng dùng hoặc phần cứng bị lỗi nó không ảnh hưởng đến cụm.
- Có thể dễ dàng tích hợp với Apache Hadoop, Apache MapReduce, Apache Spark, HBase và các công cụ big data khác.
- Quản lý in-memory có thể tùy chỉnh để tính toán tốt hơn.
- Có khả năng mở rộng (scalable) cao, có thể mở rộng tới hàng nghìn node trong một cụm.
All rights reserved
