Allocating Memory on HPC ( Slurm Scripts)
Bài đăng này đã không được cập nhật trong 3 năm
Bài viết này giải thích cách yêu cầu bộ nhớ trong các Slurm Scripts và cách xử lý các lỗi thường gặp liên quan đến bộ nhớ CPU và GPU. Lưu ý rằng "memory" luôn đề cập đến RAM .
CPU Memory
Một vài lỗi thường gặp khi chạy jobs trên HPC Cluster đó là:
srun: error: tiger-i23g11: task 0: Out Of Memory
srun: Terminating job step 3955284.0
slurmstepd: error: Detected 1 oom-kill event(s) in step 3955284.0 cgroup. Some of
your processes may have been killed by the cgroup out-of-memory handler.
Đây là lỗi chỉ ra rằng job đang cố sử dụng nhiều memory(RAM) hơn so với yêu cầu của tập lệnh Slurm. Theo mặc định ở một số HPC, ở hầu hết các cluster, bạn được nhận 4GB mỗi CPU-core bởi Slurm Scheduler. Nếu bạn cần nhiều hơn hoặc ít hơn mức này thì bạn cần đặt rõ ràng trong Slurm Script. Dưới đây là một ví dụ
#SBATCH --mem-per-cpu=8G # memory per cpu-core
Một cách thay thế để chỉ định memory yêu cầu đó là
#SBATCH --mem=2G # total memory per node
Nhưng làm thế nào để bạn biết bao nhiêu bộ nhớ để requests? Đối với một vài dòng code đơn giản, một người có thể nhìn vào cấu trúc dữ liệu sử dụng và có thể tính toán bằng tay. Chẳng hạn, một mảng khai báo gồm 1 triệu phần tử với kiểu double sẽ cần 8MB vì một double cần 8 bytes. Đối với các trường hợp khác, chẳng hạn như một tệp thực thi được biên dịch trước hoặc một mã động cấp phát bộ nhớ trong quá trình thực thi, ước tính yêu cầu bộ nhớ trở nên khó khăn hơn.
Checking the Memory Usage of a Running Job
Trong một số trường hợp, bạn có thể ước tính bộ nhớ yêu cầu bằng cách chạy code trên laptop hoặc workstation và sử dụng câu lệnh Linux htop -u $USER hoặc trên máy Mac là Activity Monitor, được tìm thấy trong /Applications/Utilities. Nếu sử dụng htop, hãy nhìn vào cột RES để quan sát lượng Mem. Cột RES sẽ show lượng memory sử dụng cho job.
PID USER PRI NI VIRT RES SHR S CPU% MEM% TIME+ Command
176776 aturing 21 1 4173M 3846M 13604 R 98.2 2.0 0:36.32 python myscript.py
Trong trường hợp này nó sử dụng 3846M hay là 3.846GB. Để thoát htop ta sử dụng Ctrl+C. Chạy exit command để thoát compute node và trở về login node.
Empirical Approach
Cách thứ 2 để ước tính lượng memory yêu cầu là bắt đầu với mặc định là 4GB mỗi CPU-Core và chạy job. Nếu chúng chạy thành công và sau đó bạn nhìn vào báo cáo ở email ( nhìn bên dưới ) và điều chỉnh lượng memory cần thiết. Nếu chúng bị lỗi out-of-memory thì sau đó chúng ta gấp đôi memory và re-submit. Tiếp tục quy trình đến khi job chạy thành cộng và sau đó sử dụng báo cáo ở email để đặt giá trị chính xác hơn.
Để nhận được báo cáo qua email, thêm dòng này vào Slurm script:
#SBATCH --mail-type=begin # send email when job begins
#SBATCH --mail-type=end # send email when job ends
#SBATCH --mail-type=fail # send email if job fails
#SBATCH --mail-user=<YourNetID>@email.com
Dưới đây là một mẫu email report từ Slurm:
================================================================================
Slurm Job Statistics
================================================================================
Job ID: 1234567
NetID/Account: aturing/math
Job Name: myjob
State: RUNNING
Nodes: 1
CPU Cores: 4
CPU Memory: 20GB (5GB per CPU-core)
QOS/Partition: medium/cpu
Cluster: della
Start Time: Sun Jun 26, 2022 at 1:34 PM
Run Time: 1-01:18:59 (in progress)
Time Limit: 2-23:59:00
Overall Utilization
================================================================================
CPU utilization [|||||||||||||||||||||||||||||||||||||||||||||||97%]
CPU memory usage [||||||||||||||| 31%]
Detailed Utilization
================================================================================
CPU utilization per node (CPU time used/run time)
della-i13n7: 4-02:20:54/4-05:15:58 (efficiency=97.1%)
CPU memory usage per node - used/allocated
della-i13n7: 6.0GB/19.5GB (1.5GB/4.9GB per core of 4)
Notes
================================================================================
* For additional job metrics including metrics plotted against time:
https://mydella.princeton.edu/pun/sys/jobstats (VPN required off-campus)
Chúng ta thấy từ report rằng job chỉ sử dụng 1.89GB nhưng chúng yêu cầu 4GB dẫn đến hiệu suất bộ nhớ là 47.37%. Trong trường hợp này chúng ta nên giảm lượng memory yêu cầu bởi câu lệnh như sau #SBATCH --mem-per-cpu=3G . Nhưng cũng sẽ là tốt hơn nếu bạn yêu cầu bộ nhớ hơn mức bạn thực sự cần để đảm bảo an toàn. Vì 1 điều khá nghiêm trọng đó là * Job sẽ bị faill nếu runs out of memory 🥲* . Tuy nhiên, điều quan trọng là không yêu cầu số lượng quá nhiều vì điều đó sẽ khiến job scheduler khó khăn hơn dẫn đến queue times dài hơn.
Một cách khác để thấy lượng memory sử dụng của một job đã hoàn thành đó là sử dụng câu lệnh jobstats
$ jobstats <JobID>
Tóm lại, nếu bạn yêu cầu quá ít bộ nhớ thì job của bạn sẽ bị out-of-memory (OOM). Nếu bạn yêu cầu quá nhiều thì job sẽ chạy thành công nhưng có thể bạn phải đợi lâu hơn 1 chút để có đủ bộ nhớ để job bắt đầu. Sử dụng email report từ Slurm và jobstats để thiết lập được lượng memory thích hợp cho job. Và nên nhớ, hãy đảm bảo yêu cầu bộ nhớ nhiều hơn 1 chút so với mức bạn nghĩ sẽ cần for safety 😊.
Memory per Cluster
Để biết có bao nhiêu memory trên mỗi node trên 1 cluster nhất định, sử dụng lệnh snodes và xem cột MEMORY được liệt kê theo đơn vị MB. Lưu ý rằng một số note not be available với bạn vì chúng có thể giới hạn nhất định cho 1 số nhóm hoặc bộ phần.
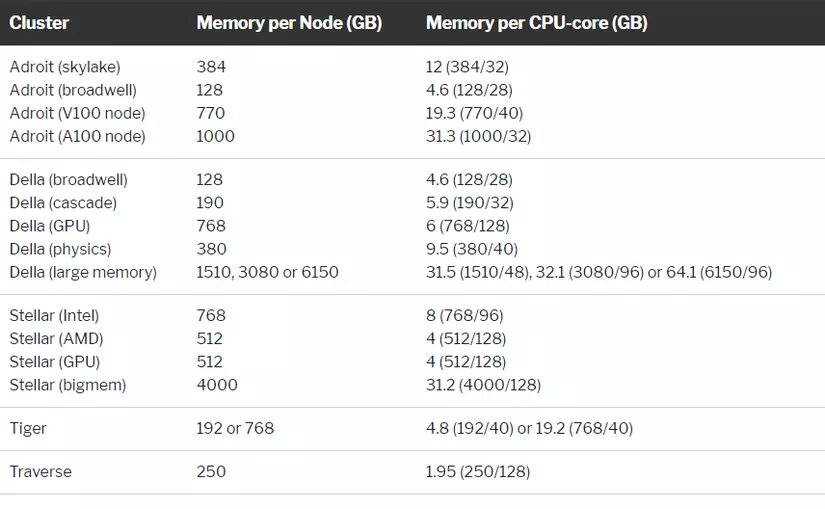
Lưu ý rằng bạn có thể yêu cầu nhiều hơn bộ nhớ nhiều hơn bộ nhớ trên mỗi lõi CPU, tối đa là tổng bộ nhớ của 1 node. Ví dụ, bạn có thể request 1 CPU-core và tổng 50GB trên bất kì node nào đề cập ở trên. Lưu ý là snode sử dụng quy ước 1MB bằng 1024 kilobyte ( binary). Nếu bạn đang yêu cầu tất cả bộ nhớ của nút thì bạn phải tính đến điều này khi chỉ định giá trị. Giải pháp là chỉ định giá trị tính bằng megabytes ( ví dụ, #SBATCH --mem=192000M). Nếu không bạn sẽ bị lỗi như sau:
sbatch: error: Memory specification can not be satisfied
sbatch: error: Batch job submission failed: Requested node configuration is not available
Bạn cũng không thể nhập vào 1 giá trị không phải là số nguyên ( ví dụ 4.2G ). Nếu không bạn sẽ bị lỗi như sau:
sbatch: error: Invalid --mem specification
Giải pháp cho lỗi phía trên là ... 4200M 🖐🏻
GPU memory
Giống như CPU có bộ nhớ riêng, GPU cũng vậy. Nhưng bộ nhớ GPU nhỏ hơn nhiều so với bộ nhớ CPU. Ví dụ, mỗi cụm GPU trên Traverse cluster chỉ có 32GB bộ nhớ so với 250GB trên các lõi CPU. Khi chương trình cố gắng phân bổ nhiều GPU memory hơn có thể, chúng sẽ gây ra lỗi. Đây là một ví dụ cho Pytorch:
Traceback (most recent call last):
File "mem.py", line 8, in <module>
y = torch.randn(N, dtype=torch.float64, device=torch.device('cuda:0'))
RuntimeError: CUDA out of memory. Tried to allocate 8.94 GiB (GPU 0; 15.90 GiB total
capacity; 8.94 GiB already allocated; 6.34 GiB free; 0 bytes cached)
srun: error: tiger-i23g11: task 0: Exited with exit code 1
srun: Terminating job step 3955266.0
Khi train các mô hình hình lớn, các nguyên nhân phoor biển gây ra lỗi out-of-memory trên GPU đó chính là sử dụng batch size, bạn có thể khắc phục bằng cách giảm batch-size hoặc là yêu cầu thêm GPU ( nếu có thể ) 😀
Tham khảo
All rights reserved
