9 Thư viện Python giúp tôi ép xung tiến độ dự án AI từ 1 tháng xuống còn 3 ngày
Người Trái Đất ai cũng biết Python là "bá chủ" trong mảng trí tuệ nhân tạo. Nhưng để làm một app có thể gọi cùng lúc cả OpenAI và Claude, bạn thường phải viết mấy lớp wrapper dày cộp. Tôi thậm chí từng tự cào phím viết Regex chỉ để bóc tách mấy file PDF lộn xộn mà khách hàng gửi tới. Hậu quả là? Codebase ngày càng phình to, và chi phí maintain thì tăng chóng mặt.
Hôm nay, tôi sẽ giới thiệu 9 thư viện Python giúp giảm thiểu triệt để việc lặp lại code, bao trọn toàn bộ quy trình từ lúc nạp dữ liệu cho đến lúc đánh giá model.
Thiết lập môi trường lập trình Python
Trước khi xài mấy thư viện này, một nền tảng ổn định và dễ quản lý là thứ bắt buộc. Với mấy anh em mới vào nghề, việc nhảy qua nhảy lại giữa các version, virtual environment và fix conflict dependency có khi ngốn xừ nó nửa ngày trời.
Bạn có thể dùng ServBay để triển khai môi trường Python chỉ với một cú click chuột. Dù là cần đổi version Python hay quản lý database, mọi thứ chỉ tốn vài thao tác bấm chuột. Tư duy giải phóng developer khỏi mớ config lằng nhằng này cực kỳ ăn khớp với logic của các công cụ mà tôi sắp chia sẻ dưới đây.
Khi môi trường đã sẵn sàng, hãy chọn các công cụ dưới đây tùy theo nhu cầu của bạn.
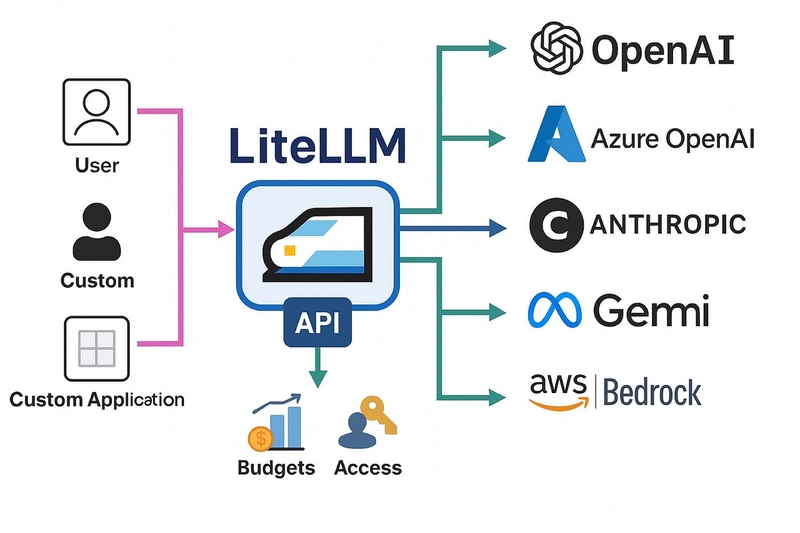
1. LiteLLM: Thống nhất gọi API đa nền tảng
Các "pháp sư" (nhà cung cấp) khác nhau thì tiêu chuẩn API cũng khác nhau. Ngày xưa để so sánh kết quả của GPT, Claude hay Llama, tôi phải viết 3 bộ logic request và 3 bộ xử lý lỗi khác nhau. Từ khi LiteLLM ra đời, nó đã chuẩn hóa toàn bộ các interface này, giúp chuyển đổi mượt mà không tì vết.
from litellm import completion
Dù gọi GPT hay Claude thì logic vẫn y chang
def ask_ai(model_name, prompt): res = completion( model=model_name, messages=[{"role": "user", "content": prompt}] ) return res.choices[0].message.content
Đổi model chỉ cần đổi cái string
print(ask_ai("gpt-4o", "RAG là gì?")) print(ask_ai("claude-3-5-sonnet", "RAG là gì?"))
Cái này giúp giảm độ coupling (ràng buộc) của code xuống mức cực thấp. Nhưng khi lên Production cần lưu ý: nếu nhà cung cấp tung ra các tham số mới đặc thù, bạn có thể phải đợi LiteLLM update để hỗ trợ.
2. MarkItDown: Đổi mọi thể loại file tài liệu sang Markdown
Việc parse (phân tích) tài liệu từng làm tôi cực kỳ đau đầu. Để xử lý Word, Excel và PDF, tôi phải cài tận 4 cái thư viện, và handle 4 loại lỗi văng app khác nhau. Tạ ơn MarkItDown của Microsoft, nó gom tất cả các loại tài liệu về một định dạng mà LLM thích nhất: Markdown.
from markitdown import MarkItDown
md_converter = MarkItDown()
Bóc PDF hay Excel đều cân tất
doc_result = md_converter.convert("annual_report.pdf") table_result = md_converter.convert("budget.xlsx")
print(doc_result.text_content)
Nó giữ lại cấu trúc của các thẻ Heading và Table cực tốt, giảm bớt hẳn khối lượng công việc clean data. Dù vậy, nó chủ yếu xử lý lớp text, nên với các file scan hoặc bảng biểu dạng hình ảnh phức tạp, kết quả có thể bị dao động.
3. LlamaIndex: Khung xương nối Dữ liệu với LLM
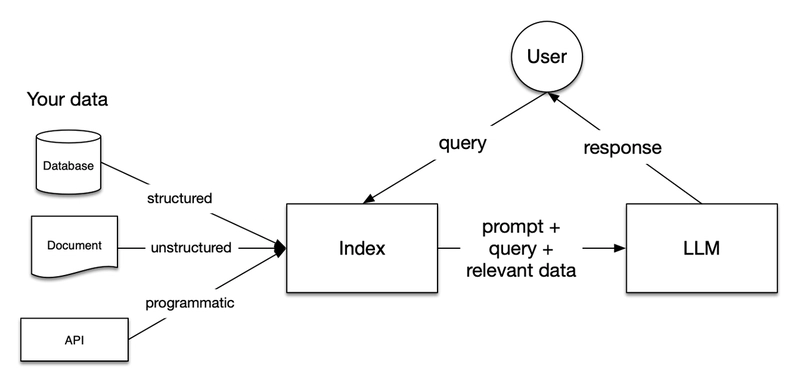
Tiền thân là GPT Index, LlamaIndex tập trung giải quyết bài toán nhét dữ liệu nội bộ (private data) vào LLM. Nó cung cấp một quy trình trọn gói từ lúc đọc file, build index cho đến interface để query.
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
Tự động đọc sạc data trong thư mục và build index
data_docs = SimpleDirectoryReader("./docs").load_data() data_index = VectorStoreIndex.from_documents(data_docs)
Khởi tạo query engine siêu tốc
engine = data_index.as_query_engine() print(engine.query("Tóm tắt các luận điểm chính của tài liệu"))
Nó hoạt động cực kỳ ổn định khi phải xử lý các file tài liệu cấu trúc phức tạp và xây hệ thống RAG, xứng đáng là một trong những framework xử lý data mainstream nhất hiện nay.
4. PydanticAI: Build Agent an toàn kiểu dữ liệu (Type-Safe)
Ngày xưa tôi hay phải "lạy lục" AI trả về chuẩn JSON, kết quả là nó toàn chèn thêm câu "Vâng, đây là JSON của bạn" ở đầu, làm sập luôn cái script parse của tôi. PydanticAI giải quyết việc này bằng cách định nghĩa chặt chẽ ranh giới của dữ liệu.
from pydantic import BaseModel from pydantic_ai import Agent
class AnalysisResult(BaseModel): summary: str score: float
analysis_agent = Agent( "openai:gpt-4o", result_type=AnalysisResult, system_prompt="Phân tích feedback của người dùng và chấm điểm" )
output = analysis_agent.run_sync("Tính năng này xài sướng thật, năng suất tăng hẳn") print(output.data.summary)
Nó cơ bản biến một lời gọi API AI đầy tính hên xui thành một function call Type-Safe chuẩn chỉ.
5. Marvin: Biến năng lực AI thành một function Python
Nếu tôi chỉ cần một tính năng phân loại hoặc trích xuất đơn giản, tôi không rảnh để ngồi viết Prompt dài dòng. Marvin cho phép tôi viết logic AI hệt như viết một function Python bình thường, cực kỳ lý tưởng cho các tác vụ phân loại, bóc tách hoặc generate data.
import marvin
@marvin.fn def generate_tags(description: str) -> list[str]: """ Tự động sinh 3 thẻ tag dựa trên mô tả sản phẩm """
tags = generate_tags("Laptop vỏ nhôm nguyên khối, hiệu năng cao, hỗ trợ sạc siêu tốc") print(tags) # Trả về mảng kiểu ['Công nghệ', 'Văn phòng', 'Tiện lợi']
Cách tiếp cận này giúp nhúng sức mạnh AI vào các hệ thống sẵn có với độ xâm lấn (intrusion) thấp nhất.
6. Haystack: Pipeline truy xuất dữ liệu từ A-Z
 Haystack sinh ra để build các hệ thống search quy mô lớn. Nó support nhiều loại vector database (như Qdrant, Elasticsearch) và cho phép bạn lắp ráp các module truy xuất (retrieval), xếp hạng (ranking), và lọc (filtering) y như chơi xếp hình Lego.
Haystack sinh ra để build các hệ thống search quy mô lớn. Nó support nhiều loại vector database (như Qdrant, Elasticsearch) và cho phép bạn lắp ráp các module truy xuất (retrieval), xếp hạng (ranking), và lọc (filtering) y như chơi xếp hình Lego.
from haystack import Pipeline from haystack.components.builders import PromptBuilder from haystack.components.generators import OpenAIGenerator
Lắp ráp các node trong pipeline
query_pipeline = Pipeline() query_pipeline.add_component("prompt_builder", PromptBuilder(template="Trả lời: {{query}}")) query_pipeline.add_component("llm", OpenAIGenerator(model="gpt-4o")) query_pipeline.connect("prompt_builder", "llm")
res = query_pipeline.run({"prompt_builder": {"query": "Làm sao để học Python nhanh nhất?"}})
Với các app cần xử lý hàng núi tài liệu và chạy search ngữ nghĩa (semantic search), Haystack mang lại khả năng mở rộng (scalability) tuyệt vời.
7. tiktoken: Tính toán chính xác lượng Token cắn mất
Có lần tôi bị "cắn" mất 1.5 đô la chỉ cho 1 API call vì dính lỗi logic đệ quy sinh ra cái prompt siêu to khổng lồ. Giờ tôi khôn rồi, trước khi call API là phải móc máy tính ra tính tiền trước. tiktoken là một bộ tokenizer chạy tốc độ bàn thờ, chuyên dùng để ước tính chi phí cho các model của OpenAI.
import tiktoken
tokenizer = tiktoken.encoding_for_model("gpt-4") content = "Chuỗi text này tốn bao nhiêu token đây" token_list = tokenizer.encode(content)
print(f"Số lượng Token: {len(token_list)}")
Cái này giúp tôi kiểm soát chi phí realtime, không còn bị đau tim khi nhận hóa đơn vào cuối tháng nữa.
8. FAISS: Search độ tương đồng Vector siêu tốc
Khi phải móc dữ liệu từ hàng trăm nghìn record, xài search tuyến tính bình thường là app treo cứng ngắc. FAISS - thư viện vector open-source do Meta chống lưng, có thể tìm ra các phân đoạn liên quan nhất từ hàng trăm triệu vector chỉ trong vài mili giây.
import faiss import numpy as np
Khởi tạo index
vector_dim = 64 search_index = faiss.IndexFlatL2(vector_dim)
Tạo data vector giả lập
mock_data = np.random.random((1000, vector_dim)).astype('float32') search_index.add(mock_data)
Chạy search
distances, results = search_index.search(mock_data[:1], 3)
Đây là công cụ tiêu chuẩn mang tính biểu tượng trong làng vector retrieval, hiệu năng cực đỉnh, nhất là khi triển khai ở môi trường local.
9. Pydantic Evals: Test hồi quy (Regression test) cho Prompt
Ngày xưa sửa prompt tôi toàn làm theo "hệ tâm linh", chạy thử 2-3 case thấy ưng mắt là đẩy lên Production. Kết quả là fix xong 1 bug thì nó đẻ ra 3 bug mới. Pydantic Evals cho phép tôi chạy test hồi quy tự động để kiểm chứng hiệu năng của model thông qua các case đã định sẵn.

from pydantic_evals import Case, Dataset
Định nghĩa tập test
eval_dataset = Dataset( cases=[ Case(inputs="Trích xuất tên công ty: Microsoft vừa tung ra hệ điều hành mới", expected_output="Microsoft"), ] )
Chạy test và check report
results = eval_dataset.evaluate(your_extract_function) results.print()
Đạt được sự chắc chắn (determinism) này chính là tiền đề bắt buộc nếu muốn phát triển các app chuẩn Production.
Lời kết
LiteLLM lo phần đồng bộ giao tiếp, MarkItDown tối giản hóa vụ xử lý file doc, và PydanticAI bảo kê chất lượng đầu ra. Tích hợp mấy thư viện này vào giúp tiến độ code của tôi tăng như gắn tên lửa, chữa dứt điểm luôn căn bệnh chán nản sau kỳ nghỉ lễ.
All rights reserved
