2-9 Cuộc họp về sự diệt vong hoàn toàn của NULL
Bài đăng này đã không được cập nhật trong 4 năm
2-9 Cuộc họp về sự diệt vong hoàn toàn của NULL
Tất cả những kĩ sư DB trên thế giới, cùng đoàn kết lại thôi Trong chương "Logic 3 giá trị và NULL" chúng ta đã có giải thích về bối cảnh mang tính logic về logic 3 giá trị của SQL, trong chương "Logic không có thần thánh" thì chúng ta đã đi vào bối cảnh mang tính lịch sử của nó. Chương này sẽ thừa hưởng 2 chương trước và sẽ đưa ra một phương hướng làm thế nào để áp dụng NULL trong công việc thực tế.
Tất cả kĩ sư DB = Thông báo
Xin chào hơn 10 triệu kĩ sư DB trên toàn quốc. Tôi là chi bộ trưởng cực Đông của uỷ ban bàn về sự diệt vong hoàn toàn của NULL, tên là ミック. Tôi biệt rằng mọi người đang sống những ngày với những công việc như cấu tạo DB, hình thành SQL, perfomance tunning, sửa chữa hoàn toàn bảng có toàn bộ dữ liệu bị DROP,... Hôm nay điều mà tôi muốn cầm bút lên viết những dòng này là để chuẩn bị những nhận thức triệt để cho chị bộ cực Đông về Truyền ngôn cơ bản về sự diệt vong hoàn toàn của NULL và chi bộ trung tâm ở Mỹ đã thống nhất sử dụng.
Để cho chắc tôi xin nhắc lại một số kiến thức cơ bản. Điểm xấu trong chất của con quái vật NULL này chính là tạo cho chúng ta cảm giác gần gũi với nhận thức của con người, nên cứ tự nhiên cho vào trong việc thiết kế hệ thống, nhưng khi nhận ra thì hệ thống đã trở nên phức tạp, không mang tính hiệu quả, và có những động tác phản với trưc quan, nên sẽ gây ra sự rắc rối trong việc phát triển cũng như vận hành. Vậy để bảo vệ mình từ chuyện đó thì chúng ta phải biết chính xác về chính thể. Nó bằng cơ chế nào phá hoại hệ thống. Tôi ở một mức độ nào đó trong cuốn sách này đã đưa ra một cách rõ ràng về chính thể này bằng một câu rồi.
Tuy nhiên, trong nhiều vấn đề phương pháp cụ thể để bảo vệ mình từ kẻ địch đó (noi như vậy nhưng cũng không có gì to lớn, chỉ là mọi người nên để tâm ở một mức độ nào đó) thì tôi chưa ghi ra chi tiết. Chương này tôi muốn nhấn mạnh với mọi người cố gắng tham gia vào vận động diệt vong hoàn toàn NULL.
Tại sao NULL lại xấu đến vậy?
Lý do để thấy NULL là một kẻ xấu bình thường có 5 lý do dưới đây:
- Trong việc lập trình của SQL thì chúng ta không thể không nghĩ đến logic 3 giá trị phản với trực quan của con người.
- Trường hợp chỉ định IS NULL hay IS NOT NULL thì không thể tham chiếu index nên đối với perfomance sẽ không tốt.
- Trong đầu vào của 4 phép toán cơ bản hay của những hàm số trong SQL nếu có bao gồm NULL thì sẽ xảy ra sự sinh sôi của NULL.
- Đối với ngôn ngữ chủ lấy kết quả của SQL thì với cấu trúc của NULL sẽ không được thông thường hoá
- Khác với những giá trị bình thường của dãy thì NULL sẽ được thực hiện bằng việc lấy bit thừa ở chỗ nào đó trong dòng nên sẽ đàn áp vùng bộ nhớ và gây ảnh hưởng xấu đến perfomance trong tìm kiếm.
Lý do 1. tôi nghĩ đây là lý do lớn nhất để bào trừ NULL nhưng cũng như những điều đã nêu ra trong "Logic 3 giá trị và NULL" thì tooi sẽ không nêu ra ở đây nữa. Mặt khác, 2. hay được biết đến như một điểm cần chú ý trong perfomance tunning. Tôi xin giải thích một chút về 3. , giả sử chúng ta có NULL trong đối tượng của 4 phép toán cơ bản.
1 + NULL = NULL
2 - NULL = NULL
3 * NULL = NULL
4 / NULL = NULL
NULL / 0 = NULL
Như trên ta thấy kết quả của phép toán sẽ là kết quả không thể sử dụng được và bị NULL hoá. Cũng như phép tính cuối cùng khi chia cho 0 thì kết quả cũng không thành error. Trong các hàm số của SQL thì hầu hết có kết cấu đối với NULL thì sẽ trả lại kết quả NULL. Hiện tượng này được gọi là NULLs propagate.
Tiếp theo là những lý do không được chú ý lắm đó chính là 4. và 5. Thật ra 2 điểm này cũng là vấn đề của ngôn ngữ chủ và vấn đề của việc chạy DBMS, sau này khả năng giải quyết được là rất lớn. Nhưng điểm ngôn ngữ chủ không hỗ trợ NULL trong mô hình quan hệ thì đó là một vấn đề rất lớn. Trong Oracle thì không phân biệt giữa NULL và ô chữ trống nhưng trong Visual Basic thì có phân biệt, chính tình trạng không đồng đều này diễn ra đủ là lý do để ta xoá đi NULL.
Nhưng chúng ta không thể hoàn toàn xoá đi NULL
Có thể chi cục trưởng sẽ bị nói rằng tự nhiên phát ngôn nhưng thực tế thì việc loại trừ NULL vĩnh viễn ra khỏi thế giới DBMS là rất khó. Mặt khác, đối với những dãy không quan trọng mà có NULL thì cũng nhắm mắt cho qua cũng là thói quen của một SE.
Lý do khó có thể vĩnh viễn loại trừ NULL đó chính là nó là cái rễ bám sâu vào DBMS rồi. Câu chuyện không đơn giản chỉ cần thêm NOT NULL vào toàn dãy trong bảng là xong. Ví dụ kể cả nếu có làm thế thì chỉ bằng liên kết ngoài hay câu lệnh GROUP BY kèm CUBE hay ROLLUP đã được thêm vào bởi SQL-99 thì NULL sẽ vào một cách đơn giản. Vì vậy, điều chúng ta có thể làm chỉ là cực lực loại trừ NULL thôi. Mà có khi nếu chúng ta sử dụng một cách khéo léo thì NULL sẽ trở thành một khái niệm cực kì tiện lợi. Vấn đề là việc sử dụng NULL một cách khéo léo chính là một điều cực kì khó khăn. Nỗi sợ của NULL đó chính là, cứ tưởng đã có thể sử dụng khéo léo nó mà không cần thận thì tự nhiên nó sẽ đâm từ đằng sau một nhát.
Chính vì vậy, cách sử dụng NULL chính là một chủ đề không bao giờ hết ngay cả giữa những trí óc thiên tài. Codd tin rằng NULL là một yếu tố không thể thiếu trong mô hình quan hệ. Người bạn thân của Codd, nhà luận học chi phối nhất hiện nay là Date cũng là cái cánh phải đắc lực nhất trong vận động bài trừ NULL. Độ sâu của sự đáng sự của NULL có thể đọc được rõ ràng từ đoạn văn ngắn dưới đây.
Nếu null có tồn tại thì chắc chắn đây không là câu chuyện của mô hình quan hệ (Là câu chuyện gì không biết nhưng chắc chắn không phải là mô hình quan hệ). Từ thời điểm null xuất hiện thì những gì được xây từ trước đến đó bị sập đổ hết và tấtcả sẽ trở thành giấy trắng.
Tôi cũng đứng về phía Date nhưng đối với những kĩ sư bên ngoài thì điều thích hợp nhất chính là cách nhìn hài hoà của Celko. Và dưới đây tôi xin đưa ra phương châm chính thức với tư cách của một chi bộ trưởng phía đông.
Hãy nghĩ NULL như một liều thuốc. Sử dụng một liều thuốc tốt như NULL chính là để cho chính bạn. Tuy nhiên lạm dụng sẽ mang đến những cái hại. Cách suy nghĩ tốt nhất đó chính là sử dụng thích hợp với những trường hợp cần sử dụng và cố gắng không sử dụng.
Và tiếp theo đây chusnh là một vài trường hợp cụ thể và từ đó chúng ta cùng nghĩ cách để loại trừ NULL.
Trường hợp của Code: Tạo Code để biểu hiện dữ liệu không thể code hoá
Chắc chắn trong DBMS mọi người đang sử dụng sẽ có rất nhiều code được đưa vào. Ví dụ, code doanh nghiệp, code khách hàng, code tỉnh, code giới tính,... Như giới tính thì bình thường người ta gọi là flag và cũng không được bao gồm trong code. Flag là những code chỉ có 2 giá trị mà thôi. Những loại code như thế này đối với hệ thống nhiều trường hợp được xem như những dãy quan trọng và cũng nhiều trường hợp trở thành key để tìm kiếm hay kết hợp. Như vậy việc loại trừ NULL chính là việc hàng đầu.
Phương pháp giải quyết cũng đơn giản, chúng ta chỉ cần Tạo Code để biểu hiện dữ liệu không thể code hoá . Ví dụ code giới tính của ISO là 1: Nam, 2: Ngoài nữ ra, 0: Chưa rõ, 9: Không có khả năng tích hợp. Code 9 được sử dụng cho các pháp nhân. Đây là một cách xử lý rất tuyệt vời. Chúng ta không cần tính toán gì mà sử dụng 2 loại NULL là Chưa biết và Không có khả năng thích hợp.
Bình thường không cần thiết phải chuẩn bị 2 code này. Chỉ cần 1 cũng đủ cho nhiều trường hợp. Ví dụ đối với một khách hàng mang code khách hàng chưa rõ thì đối với trường hợp phải lưu lên DB thì chúng ta chỉ cần chuẩn bị một code dạng [XXXXX] như một code biểu diễn sự chưa rõ. Tại đây tôi nghĩ nên tránh sử dụng code dạng [99999]. Lý do vì code trong nhiều trường hợp là dùng số nên nghĩ rằng không thể có khả năng rồi dùng tạo Code để biểu hiện dữ liệu không thể code hoá thì có thể khách hàng đó sẽ xuất hiện trên thực tế luôn. Chính vì vậy dãy code nhất định nên là dãy chữ. Ngoài ra cũng có 2 lý do nên sử dụng dãy code là dãy chữ: Đầu tiên là code trong nhiều trường hợp cố định như dãy nhiều số bắt đầu từ số 0. Giả sử dãy có 3 hàng sẽ là [008] hay [012]. Trong mô hình giá trị số thì số 0 bị xoá đi và chỉ còn [8] hay [12] như vậy sort cũng không được sắp xếp một cách rõ ràng. Tiếp theo, đối với bảng đã một lần thêm dữ liệu vào thì việc đổi mô hình sau đó là rất khó nên để diễn ra sự chuyển đổi giữa số và chữ thì phải xoá hết tất cả những dữ liệu ban đầu. Điều gì cũng vậy, khởi đầu luôn là quan trọng.
Trường hợp tên: chia vào các vùng không có tên
Chắc chắn trong của bảng của DB mọi người đang sử dụng sẽ có những tên của nhiều loại nhiều kiểu tên không kém code. Trong trường hợp là tên thì phương châm cũng giống trong trường hợp của code. Có nghĩa rằng đưa giá trị để hiển thị những gì chưa rõ. "Chưa rõ" cũng được hay "Unknown" cũng được miễn là chúng ta thống nhất được với đội phát triển là được.
Tên so với code thì tần suất được sử dụng làm key sẽ ít hơn nên nhiều trường hợp sẽ không mang ý nghĩa cần thêm vào nên không cần thiết phải nhìn nó bằng con mắt sắc hơn nhưng cũng không thiếu nếu chúng ta có những kiến thức về nó.
Trường hợp giá trị số: Thay bằng 0
Trong trường hợp dãy giá trị số thì theo tôi cách nghĩ tốt nhất là ngay từ đầu những giá trị NULL ta sẽ thay bằng 0 khi đưa vào cơ sở dữ liệu. Tôi không khuyến khích phương pháp vẫn cho NULL nhưng khi thực hiện hàm thì sử dụng hàm số NULLIF hay vị từ IS NOT NULL để bài trừ NULL. Trong kinh nghiệm của tôi thì không có vấn đề gì khi thay NULL bằng 0 và hơn nữa chúng ta có thể có được những điểm lợi khi bài trừ được NULL.
Nếu suy nghĩ một cách nghiêm khắc hơn thì cách làm này không thể phủ định rằng là một cách làm khá bạo lực. Nó như là sự khác nhau giữa một cái ô tô không có bình xăng và một cái ô tô có bình xăng rỗng. Vậy đề án đối với những công việc trên thực tế sẽ là:
- Đổi thành 0
- Trong trường hợp rất muốn phân biệt giữa 0 và NULL thì cho phép NULL.
Rất mong bằng việc thay thế bằng 0 sẽ làm cho công việc của mọi người sẽ thuận lợi hơn.
Trường hợp ngày tháng: Thay thế bằng giá trị lớn nhất và giá trị nhỏ nhất
Trong trường hợp ngày tháng thì bằng việc biểu hiện bằng NULL thì ý nghĩa sẽ khác nhau nên trong trường hợp này một là dùng một giá trị mặc định hoặc cho phép NULL.
Trong trường hợp hiển thị ngày đầ và ngày cuối với ý nghĩa kì hạn thì chúng ta có thể sử dụng giá trị lớn nhất và nhỏ nhất như [0001-01-01] và [9999-12-31] để đối ứng. Ví dụ ngày nhân viên mới vào công ty hay ngày để hiển thị giới hạn để sử dụng thẻ thì có thể sử dụng phương pháp này. Đây là phương pháp được sử dụng từ xưa.
Mặt khác, trong trường hợp không biết giá trị mặc định thì ngày xảy ra một sự kiện nào đó trong lịch sử hay ngày sinh của một nhân vật nào đó, trong trường hợp muốn thể hiện NULL với ý nghĩa "Chưa biết" thì chúng ta không thể để giá trị mặc định như bên trên được. Trường hợp này thì có thể cho phép NULL cũng được.
Lời kết
Như bên trên tôi đã nêu ra những bước cụ thể phân loại theo 4 dạng dữ liệu để loại trừ NULL. Tóm tắt lại ta có những phương pháp như sau,
- Kiểm tra xem có thể sử dụng những giá trị mặc định không
- Chỉ cho phép NULL trong trường hợp không thể làm gì được
Chỉ như thế này thì tôi nghĩ rằng chúng ta có thể giải phóng NULL khá nhiều ra khỏi hệ thống. Có thể có những ý kiến cho rằng "Cách này không thực hiện được" hay "Có phương pháp tốt hơn". Trong những trường hợp đó nhất định hãy báo cho chi bộ trưởng một tiếng nhé.
2-10 Những tầng lớp tồn tại trong SQL
Xã hội phân cấp nghiêm khắc Trong SQL thì trong trường hợp sử dụng GROUP BY để tập hợp thì ngoài key tập hợp thì không thể tham chiếu những dãy trong bảng cũ được. Đối với những lập trình viên chưa quen với SQL hẳn sẽ có những cảm giác thiếu nhưng đây chính là một lý luận của SQL để phân chia một cách nghiêm khắc tồn tại của các tầng. Để giải thích hiện tượng kì diệu này thì chúng ta cùng đi vào bản chất của SQL.
Tầng lớp của logic vị từ, tầng lớp của luận tập hợp
Trong chương "Cách sử dụng vị từ EXISTS" trong phần 1 chúng ta đã đề cập đến những tầng (order) trong khái niệm logic vị từ trong SQL. Khái niệm này chia ra các tầng của tồn tại, rồi sự phân biệt giữa thành tố và tập hợp trong luận tập hợp, hay phân biệt giữa giá trị nhập vào và vị từ trong logic vị từ đều là những khái niệm rất quan trọng.
Trong SQL, khi sử dụng vị từ EXISTS thì việc nhận thức về tầng sẽ làm dễ hiểu hơn, điều này cũng đã được nêu ở trên. Nhưng còn một điểm nữa, đối với SQL còn một bộ phận mang ý nghĩa quan trong là "tầng của tồn tại". Nếu hỏi cái đó ở đâu thì rất dễ, đó chính là một câu lệnh rất quen thuộc với chúng ta - GROUP BY.
Trong trường hợp EXISTS, thì khoảng cách giữa các tầng liên quan đến vị từ EXISTS và giá trị được nhập vào trong đó. Đây chính là order của logic vị từ. Mặt khác, order được hình thành từ GROUP BY liên quan đến việc phân biệt tập hợp và thành tố nên đây chính là order của logic tập hợp. GROUP BY mang lại rất nhiều điều cần phải suy nghĩ nên tại đây sẽ làm sáng tỏ những bí mật đó.
Tại sao sau khi tập hợp lại thì không thể tham chiếu được tập hợp ban đầu nữa?
Chúng ta cùng nhanh chóng chủ đề thông qua những ví dụ cụ thể. Chuẩn bị một bảng ví dụ sử dụng GROUP BY hoặc PARTITION BY như dưới đây.
Teams
| member | team | age |
|---|---|---|
| Ooki | A | 28 |
| Tanaka | A | 19 |
| Shindo | A | 23 |
| Yamada | B | 40 |
| Kumoto | B | 29 |
| Hashida | C | 30 |
| Nonomiya | D | 28 |
| Onizuka | D | 28 |
| Kato | D | 24 |
| Shinjo | D | 22 |
Đây là bảng quan lý thông tin của thành viên được chia ra trong 4 đội A~D. Như ví dụ, chúng ta cùng bắt đầu với truy vấn tập hợp theo từng team.
SELECT team, AVG(age)
FROM Teams
GROUP BY team;
team AVG(age)
----- --------
A 23.3
B 34.5
C 30.0
D 25.5
Query này không có vấn đề gì xảy ra cả. Chúng ta tìm trung bình tuổi của các đội, vậy tiếp theo đây đổi một chút để thành truy vấn sau.
SELECT team, AVG(age), age
FROM Teams
GROUP BY team;
Query này sẽ trả về kết quả error. Nguyên nhân là không thể chọn dãy age được thêm vào câu lệnh SELECT. MySQL có thể thực hiện truy vấn này như một mở rộng đặc biệt nhưng vì đây là vi phạm so với thông thường nên không có tính di chuyển tương đương sang các DBMS khác.
Trong SQL thông thường khi tập hợp bảng thì những thành tố có thể viết trong câu lệnh SELECT được giới hạn trong 3 loại dưới đây.
- Key được chỉ định trong câu lệnh GROUP BY
- Hàm số tập hợp (SUM, AVG, ...)
- Số cố định
Đối với những người mới làm quen với SQL vì không để ý đến những điều kiện này nên hay thêm những dãy khác vào SELECT làm chương trình thành error. Khi dùng đi dùng lại DBMS thì có thể mọi người không cần để ý vẫn có thể viết được những truy vấn đúng, nhưng tại sao lại có những qui định như thế này? Số người có thể lý giải được điều này ngoài dự đoán có khi là rất ít. Mọi người hãy thử hướng mặt hỏi một lập trình viên mới như một cấp dưới của mình câu "Tại sao không được viết câu lệnh SELECT cho dãy của bảng ban đầu?" thì có thể họ sẽ ngập ngừng trong câu trả lời cũng nên.
Chương này sẽ giải quyết những vấn đề liên quan đến chủ đề này. Bây giờ, dãy age trong bảng Teams có mang thông tin tuổi của từng người. Và điều quan trọng là tuổi là thuộc tính của riêng của từng người, chứ không phải thuộc tính của cả một nhóm. Nhóm là tập hợp được tạo nên bới nhiều người. Như vậy, thuộc tính của nhóm chính là những thuộc tính mang tính thống kê như tổng, bình quân.
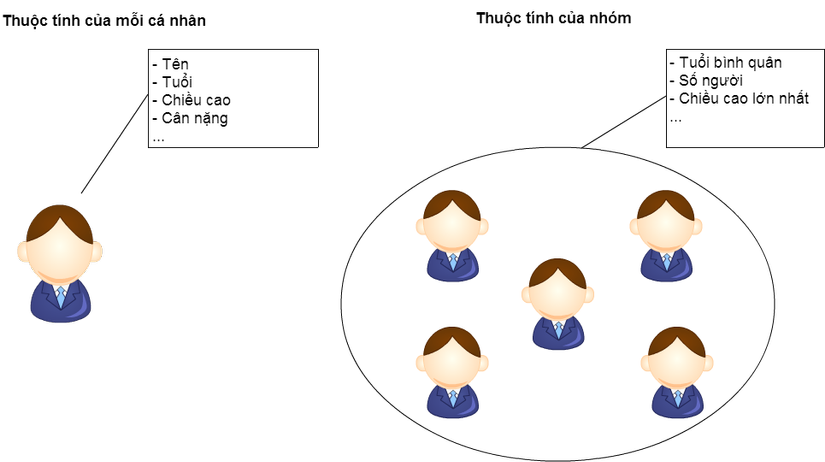
Đối với mỗi cá nhân thì chúng ta có thể hỏi "Bạn bao nhiêu tuổi" nhưng đối với một tập hợp thì ta không thể hướng đến họ và hỏi "Bạn bao nhiêu tuổi" được. Đối với một tập hợp thì chỉ những câu hỏi như "Tuổi trung bình là bao nhiêu" hay "Chiều cao lớn nhất là bao nhiêu" mới có ý nghĩa. Những thuộc tính chỉ dành cho cá nhân mà lại để hỏi tập hợp thì đó không gì ngoài Category mistake. Cũng như những gì ta nhìn thấy trong chương GROUP BY và PARTITION BY thì GROUP BY mang tính năng chia từng thành tố vào từng nhóm. Nếu làm thử như vậy, đối với mô hình quan hệ thì chúng ta có thể lấy đó làm lý do để gọi tên chính thức cho dãy chính là "Thuộc tính" được.
Có thể những DBMS như MySQL không để ý đến sự phân biệt tầng lớp thì mọi người sẽ cảm thấy tâm trạng tốt khi sử dụng nhưng nó đồng nghĩa với việc bỏ qua logic hình thành trong SQL. Bằng việc tập hợp sử dụng GROUP BY thì đối tượng của SQL sử dụng biến đổi từ dòng là tầng 0 đến tập hợp dòng là tầng 1. Vào đúng thời điểm đó thì chúng ta không thể lấy đối tượng tham chiếu là dòng được nữa. Thế giới SQL là xã hội rất nghiêm khắc trong việc phân chia tầng lớp. Việc tích hợp những thuộc tính của những tồn tại ở tầng thấp vào tầng cao sẽ làm rối loạn trật tự nên bị nghiêm cấm. Như vậy, cùng với lý do đó thì dưới đây cũng trở thành error.
--Error
SELECT team, AVG(age), member
FROM Teams
GROUP BY team;
Đối với team thì ta không thể đặt câu hỏi "Tên là gì" được. Nếu dù thế nào cũng muốn có được kết quả của dãy member thì ta chỉ có thể viết như sau,
--Đúng
SELECT team, AVG(age), MAX(member)
FROM Teams
GROUP BY team;
MAX(member) sẽ đưa kết quả là tên thành viên của đội được sắp xếp theo thứ tự của từ điển, đây cũng chính là thuộc tính của tập hợp.
Ứng dụng truy vấn này một chút chúng ta có thể viết được SQL bao gồm kết quả cho đến "người có tuổi cao nhất trong nhóm"
SELECT team, MAX(age),
(SELECT MAX(member)
FROM Teams T2
WHERE T2.team = T1.team
AND T2.age = MAX(T1.age)) AS oldest
FROM Teams T1
GROUP BY team;
team max(age) oldest
---- -------- -------
A 28 Ooki
B 40 Yamada
C 30 Hashida
D 28 Nonomiya
Đây là một truy vấn thú vị mang tính ngoài dự đoán. [member] là thuộc tính của bảng trước khi tập hợp nhưng nếu suy nghĩ một cách thông thường thì không thể có trong kết quả sau khi tập hợp (vì tầng lớp khác nhau). Tuy nhiên ở đây tại đây có sử dụng scalar subquery nên điều này trở nên có thể.
Truy vấn này có 2 điểm cần chú ý. Đầu tiên chính là việc sử dụng hàm số tập hợp [MAX(T1.age)] với câu lệnh WHERE trong subquery. Chúng ta khi lần đầu tiên học SQL được dạy rằng trong câu lệnh WHERE không thể sử dụng hàm số tập hợp, nhưng trong trường hợp này có thể sử dụng mà không vấn đề gì xảy ra. Lý do là vì bên ngoài đã có bảng T1 được tập hợp lại nên hàm số tập hợp có thể tham chiếu bằng câu lệnh SELECT. (Chính vì vậy, ngược lại không thể sử dụng trần dãy [age] trong subquery). Vậy mọi người đã hiểu SQL nghiêm khắc trong việc phân biệt tầng lớp như thế nào chưa?
Điểm chú ý thứ 2 đó chính là trong trường hợp có nhiều người có số tuổi cao trong cùng một bộ phận thì chúng ta phải chọn một người làm đại diện, cái này có thể được thực hiện bằng cách dùng MAX(member). Ví dụ trong đội D có Onizuka và Nonomiya cùng số tuổi cao nhưng kết quả chỉ ra Nonomiya. Nếu không sử dụng hàm số MAX thì vì subquery sẽ trả lại nhiều dòng nên chương trình sẽ error.
Mẫu duy nhất Singleton cũng là một tập hợp lớn
Cho đến đây tôi mong rằng chúng ta đã hiểu được độ quan trọng của việc phân biệt tập hợp và thành tố của tập hợp. Tuy nhiên ở đây tôi muốn mọi người chú ý một điểm.
Hãy chú ý vào đội C. Đội này có thể gọi là đội nhưng chỉ có mỗi một mình anh Hashida thôi. Như vậy độ tuổi trung bình của cả đội cũng chính là độ tuổi của anh Hashida. Ở đây không chỉ giới hạn ở thuộc tính tuổi mà thuộc tính nào cũng vậy. Tập hợp chỉ có một thành tố gọi là mẫu duy nhất singleton nhưng mẫu duy nhất này đều có những thuộc tính như thuộc tính ban đầu. Đối với những tập hợp chỉ có một thành tố như thế này thì chúng ta hay có câu hỏi rằng chỉ với một thành tố như thế này thì có nhất thiết phải tạo thành một tập hợp không. Thực tế ngay cả trong lịch sử toán học thì đầu tiên việc công nhận mẫu duy nhất singleton này không cũng đã trở thành một chủ đề thảo luận. Và cũng đã có ý kiến cho rằng yếu tố và thực chất thì là giống nhau nên cũng không cần phải tạo thêm một tập hợp mới.
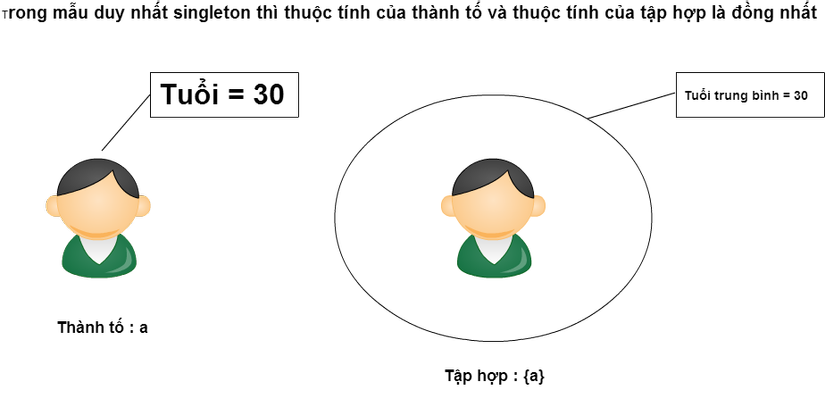
Tuy nhiên nếu nói từ kết luận thì đối với luận tập hợp hiện tại thì mẫu đơn nhất cũng được thừa nhận như một tập hợp chính đáng. Mẫu duy nhất cũng giống như tập hợp rỗng có tất cả những lý luận của luận tập hợp. Chính vì vậy nên đối với SQL ứng dụng những lý luận của luận tập hợp thì đương nhiên thành tố và mẫu đơn nhất singleton cũng được phân biệt một cách rõ ràng.Giữa thành tố a và tập hợp {a} cũng được thiết kế thành những tầng lớp riêng.
a ≠ {a}
Sự phân biệt tầng lớp như thế này cũng như sự phân biệt giữa câu lệnh WHERE và câu lệnh HAVING. Đối tượng của câu lệnh WHERE chính là dòng, tức là tầng 0 thì đối tượng của HAVING là tập hợp của dòng, là tồn tại ở tầng 1.
Vậy tại đây mọi người đã hiểu tại sao không thể viết trần dãy của bảng ban đầu vào câu lệnh SELECT chưa? Nếu ngày mai có một lập trình viên mới vào nghề nào đó hỏi thì bạn hãy trả lời như một tiền bối đáng tin cậy nhé.
All rights reserved
