2-5 GROUP BY và PARTITION BY
Bài đăng này đã không được cập nhật trong 4 năm
2-5 GROUP BY và PARTITION BY
Trong những chức năng mà SQL có thì có GROUP BY và PARTITION BY là hai chức năng có hoạt động khá giống nhau, mà cũng có thể nói là giống nhau cũng được. Và cả hai câu lệnh đều mang cơ sở mang tính toán học. Tại chương này sẽ lấy key là mội khái niệm quan trọng trong luận tập hợp là loại để giải thích rõ ràng ý nghĩa của GROUP BY và PARTITION BY mang.
Khi tiến hành những thao tác đối với dữ liệu thì một trong những thao tác cơ bản đó chusnh là phân loại dữ liệu thành từng nhóm theo một cơ sở nào đó. Không chỉ những khi sử dụng SQL mà trong cuộc sống thường ngày cũng có những khi muốn điều tra, chỉnh lý lại dữ liệu thì chúng ta cũng hay thực hiện tác nghiệp là phân loại nhóm dữ liệu.
Trong những câu lệnh của SQL thì thứ có chức năng để phân nhóm đó chính là GROUP BY và PARTITION BY. Cả hai câu lệnh này đều thực hiện động tác phân loại theo key được chỉ định. Cái khác là trong trường hợp GROUP BY thì sau khi phân loại sẽ tiến hành thao tác tập hợp lại thành một dòng.
Ví dụ chúng có lấy một bảng hiển thị cấu trúc một vài đội chơi như sau.
Teams
| member | team | age |
|---|---|---|
| Ooki | A | 28 |
| Tanaka | A | 19 |
| Shindo | A | 23 |
| Yamada | B | 40 |
| Kumoto | B | 29 |
| Hashida | C | 30 |
| Nonomiya | D | 28 |
| Onizuka | D | 28 |
| Kato | D | 24 |
| Shinjo | D | 22 |
Nếu chúng ta sử dụng GROUP BY và PARTITION BY đối với bảng này thì có thể viết được truy vấn để có được thông tin trên đơn vị đội. Kể cả sử dụng câu lệnh nào đi chăng nữa thì chúng ta sẽ thực hiện đối với những bộ phận tập hợp đã chia ra những thao tác như dùng hàm số SUM để tính tổng rồi dùng hàm RANK để xếp hạng.
SELECT member, team, age
RANK () OVER(PARTITION BY team ORDER BY age DESC) rn,
DENSE_RANK () OVER(PARTITION BY team ORDER BY age DESC) dense_rn,
ROW_NUMBER () OVER(PARTITION BY team ORDER BY age DESC) row_num
FROM Members
ORDER BY team, rn;
Kết quả
member team age rn dense_rn row_num
------- ----- --- -- -------- --------
Ooki A 28 1 1 1
Shindo A 23 2 2 2
Tanaka A 19 3 3 3
Yamada B 40 1 1 1
Kumoto B 29 2 2 2
Hashimoto C 30 1 1 1
Nonomiya D 28 1 1 1
Onizuka D 28 1 1 1
Kato D 24 3 2 3
Shinjo D 22 4 3 4
Nếu nhìn partition cut bằng hình ảnh thì ta sẽ có
Bình thường thể hiện tập hợp bằng các hình tròn là điều thông thường, chương này và cũng như những chương khác cũng như vậy, tại đây để hình dung được hình ảnh thao tác "cut" thì chúng ta biểu hiển bằng việc cắt thành những tập hợp bộ phận bằng những đường thẳng.
Tại đây, chú ý vào những tập hợp bộ phận được chia thì chúng ta có thể thấy được ba tính chất như sau,
- Ít nhất không có tập hợp rỗng
- Tổng các tập hợp bộ phận bằng với tập hợp trước khi phân chia
- Không có tập hợp bộ phận nào có bộ phận giao
Chúng ta phân chia các tập hợp bộ phận từ chính dãy team tồn tại trong bảng ban đầu nên chắc chắn không thể có tập hợp rỗng trong tập hợp sau khi phân chia. (Cũng có thể có tập hợp có bao gồm NULL nhưng đó là một loại khác so với tập hợp rỗng. Trong toán học thì trong trường hợp tập hợp ban đầu là tập hợp rỗng thì tập hợp rỗng cũng là 1 loại nên sau khi chạy GROUP BY của SQL thì chương trình vẫn chạy thông thường và kết quả sẽ ra tập hợp rỗng.) Mặt khác thì nếu cộng tất cả những tập hợp bộ phận sau khi phân chia mà ra tập hợp mẹ ban đầu thì đó gần như là một điều đương nhiên, nếu nói một cách khác thì không có thành viên nào đi lạc cả.
Mặt khác, cũng không có thành viên nào cùng thuộc cả 2 tập hợp bộ phận (hoặc nhiều tập hợp bộ phận). Một thành viên nhất định sẽ được chia vào một tập hợp. Có nghĩa rằng chúng ta có thể hiểu GROUP BY và PARTITION BY là hàm số để chia các thành viên thích hợp vào các đội.
Trong toán học, những tập hợp bộ phận thoả mãn 3 điều kiện trên thì được gọi là partition (phần). Cái tên PARTITION BY trong SQL cũng bắt nguồn từ nguồn gốc này. mặt khác cũng có thể đặt cái tên này cho GROUP BY nhưng trong trường hợp của GROUP BY thì sau khi cut thì chắc chắn sẽ có thao tác tập hợp lại thêm vào nên chắc để tránh nhầm lẫn thì người ta dùng một cái tên khác. Thông thường có rất nhiều phương pháp để phân loại một tập hợp thành các phần. Trong SQL thì chỉ cần thay GROUP BY và PARTITION BY là nhóm được tạo ra cũng khác nhau.
Cũng như chúng ta có thể thấy rằng GROUP BY được sử dụng rất nhiều xung quanh, thì trong cuộc sống bình thường, xung quanh chúng ta tồn tại rất nhiều phần. Ví dụ, những lớp trong một trường hay quê quán mình xuất thân. Chả có ý nghĩa gì khi tạo ra một lớp mà không có học sinh hay cũng chả có ai được sinh ra ở 2 tỉnh. (Có thể có những người sinh ra mà không biết quê quán của mình ở đâu, trong trường hợp đó thì sẽ vào phần có key là NULL).
Hoặc, các lá bài trong bộ bài cũng vậy. Trong 52 lá bài thì dựa theo kí hiệu được kí hiệu trên từng lá bài thì chúng ta có thể chia thành 4 nhóm hay cũng có thể chia thành hai nhóm theo màu là đen và đỏ. Những thành phần cùng ở trong một phần với ý nghĩa ucngf thoả mãn một cơ sở chung nào đó. (Trong toán học thì người ta gọi đây là quan hệ đồng giá trị)
Ở đây, thông qua cách phân loại mả từng phần có những tên gọi khác nhau. Có rất nhiều phần có những đặc trưng thú vị nhưng trong đó có một thứ gọi là "phần dư". Cũng như tên của nó thì đây là phần được chia vào phần dư của số nguyên. (Thông thường thì không cần thiết giới hạn số lượng tập hợp trong phần nhưng ở đây mọi người hãy nghĩ chỉ là những số thông thường).
Ví dụ, khi phân loại những số tự nhiên (N) theo số dư sau khi chia cho 3 thì ta có
Chia cho 3 dư 0: M1 = {0,3,6,9,...} Chia cho 3 dư 1: M2 = {1,4,7,10,...} Chia cho 3 dư 2: M3 = {2,5,8,11,...}
Nếu theo tính chất thứ 2 của partition thì chúng ta có 3 tập hợp bộ phận này nối với nhau sẽ được tập hợp số tự nhiên. Nếu viết bằng công thức thì chúng ta sẽ có
M1 + M2 + m3 = N
Hàm số chia ở đây chính là MOD. Trong SQL thông thường sẽ không tồn tại hàm số này nhưng hầu hết có thể sử dụng trong các DBMS. Nếu viết bằng SQL thì chúng ta có thể viết như sau chăng.
---Phân loại theo số dư sau khi chia cho 3 của các số 1~10
SELECT MOD(num, 3) AS modulo,
num
FROM Natural
ORDER BY modulo, num;
Kết quả
modulo num
------ ----
0 0
0 3
0 6
0 9
1 1
1 4
1 7
1 10
2 2
2 5
2 8
Phần dư này cũng mang những tính chất khá thú vị nên cũng có nhiều ứng dụng. Để nêu lên một ví dụ, phần dư sẽ phân loại tập hợp số tự nhiên ban đầu thành những phần có kích thước giống nhau nên lấy mẫu bằng một tỷ lệ đặc định sẵn từ một khối lượng dữ liệu lớn thì rất tiên lợi. Ví dụ nếu sử dụng truy vấn sau thì có thể giảm xuống được 1/5 lượng dữ liệu (Trong trường hợp trong bảng không có dãy thứ tự thì chúng ta có thể sử dụng ROW_NUMBER để gán số cho dãy cũng có thể được)
--Lấy 1/5 số dòng từ bảng ban đầu
SELECT *
FROM SomeTbl
WHERE MOD(seq, 5) = 0;
--Ngay cả trong trường hợp trong bảng không có dãy số thứ tự thì có thể dùng hàm số ROW_NUMBER
SELECT *
FROM (SELECT col,
ROW_NUMBER() OVER(ORDER BY col) AS seq
FROM SomeTbl)
WHERE MOD(seq, 5) = 0;
Tất nhiên trong thực tế không hẳn chắc chắn số dòng sẽ chia hết cho 5 nên không hẳn số thành phần trong một phần sẽ giống nhau nuhwng đối với yêu cầu lấy mẫu ngẫu nhiên với điều kiện phân chia tập hợp thành những phần bằng nhau mà không đụng gì đến dữ liệu thì cũng coi như thoả mãn.
Mọi người thấy như thế nào? Không biết mọi người đã nâng cao thêm những kiến thức của mình về cơ sở mang tính toán học của hình ảnh động tác của GROUP BY và PARTITTION BY chưa? Như thế này, đây là thành quả rất hay được đưa vào trong bản phát triển của luận tập hợp hay luận về nhóm của SQL và cơ sở dữ liệu quan hệ.
Đây là một câu chuyện có thể mọi người sẽ cảm thấy nó hơi trừu tượng, mà chính xác là nó có tính trừu tượng nhưng nó đảm bảo tính ứng dụng cao. Những lý luận của toán học không chỉ là trò đùa vui xa rời thực tế mà nó chứa trong đó khả năng ứng dụng lớn đối với các nghiệp vụ trong thực tế. Nhưng đó không phải là thứ có thể nhìn thấy nếu chỉ chờ đợi. Tác giả nghĩ rằng bằng sự cố gắng làm cầu nối giữa nguyên lý và thực tiễn như một kĩ sư năng động thì có thể nâng cao thêm được năng lực ứng dụng của chính mình.
2-6 7 điều kiện để có thể đổi cái đầu từ mô hình thủ tục sang mô hình hướng đối tượng, mô hình Declarative
Vẽ vòng tròn Hầu hết những kĩ sư hầu hết đã quen sử dụng (hoặc ít nhất thì lấy đó làm cơ sở) những ngôn ngữ lập trình thủ tục như C, COBOL, Java, Perl nên cứ ngẫu nhiên trong lúc ta không biết thì cứ khi sử dụng ngôn ngữ nào để lập trình thì cũng bị ám ảnh với những ý tưởng của ngôn ngữ lập trình thủ tục. Tuy nhiên, để sử dụng thành thạo những ngôn ngữ phi thủ tục như SQL thì cần phải biết những nguyên lý, cấu tạo riêng của chúng.
Việc học cách nhìn từ quan điểm của SQL là một bước nhảy đối với rất nhiều lập trình viên. Có thể rất nhiều trong các bạn đã trải qua hơn nửa sự nghiệp viết code của mình bằng ngôn ngữ lập trình thủ tục. Và có một ngày đột nhiên phải đối mặt với ngôn ngữ lập trình phi thủ tục. Và điều quan trọng ở đây chính là chuyển cách suy nghĩ từ thứ tự sang tập hợp. --Joe Celko--
Đúng như những gì Celko đã nói thì trở ngại lớn nhất khi học cách nghĩ của SQL đó chính là cách nghĩ của ngôn ngữ thủ tục mà chúng ta đã quen. Nếu nói một cách cụ thể thì chính là ý tưởng chia toàn bộ hệ thống bằng những xử lý cơ bản như loop, chu kì. Cùng với đó thì sử dụng cách phân loại theo đơn vị nhỏ tên là record (bản ghi) từ hệ thống file hay khối dữ liệu lớn. Nếu hỏi vậy giao điểm giữa 2 loại này là gì thì đó chính là cả hai đều có cách suy nghĩ biến những cái phức tạp thành những thứ đơn giản.
Cách nghĩ của SQL ở một ý nghĩa nào đó thì đi về hướng đối cực. Ở SQL chúng ta không hề có những thủ tục như loop hay chu kì, dữ liệu cũng không phải là record mà lại sử dụng một tập hợp phức tạp hơn thế nữa. Nếu nói ý tưởng của SQL hay cơ sở dữ liệu quan hệ là gì thì đó chính là tính luận toàn thể.
Nếu cứ cố tình ép SQL theo hướng thủ tục thì có thể biến nó thành một SQL dài đến mức không thể đọc hết và lại trở lại với thế giới lập trình thủ tục mà ta đã quen. Để tích cực học SQL thì cần phải lý giải những nguyên lý của đặc trưng chi phối thế giới cơ sở dữ liệu quan hệ và SQL và sử dụng thành thạo nó. Nguyên lý hay lý luận không được chỉ lý giải mà còn phải ứng dụng, phát huy nó trong thực tiến. Đây chính là chủ đề chính được nêu ra trong cuốn sách này. SQL là ngôn ngữ nếu có phát huy toàn bộ những tính năng của nó thì cũng là ngôn ngữ có sức mạnh không thua kém gì những ngôn ngữ lập trình thủ tục khác.
Vì vậy nên mục đích của chương này là tóm tắt những điểm làm phương hướng để chuyển đổi những ý tưởng, cách nghĩ từ ngôn ngữ lập trình thủ tục sang SQL. Nếu có thể trở thành cẩm nang thực tiễn hoá cách nghĩ snag hướng tập hợp trong nghiệp vụ hàng ngày thì quả thật là điều may mắn của tác giả.
1. Chuyển câu lệnh IF hay CASE thành hàm CASE. SQL có cách nghĩ gần hơn với ngôn ngữ kiểu hàm số
Trong ngôn ngữ lập trình thủ tục thì những xử lý thường được tiến hành với đơn vị câu lệnh. Mặt khác, trong SQL thì được tiến hành với đơn vị hàm trong câu lệnh. Trong SQL cũng có thể viết được những xử lý phức tạp trong câu lệnh SELECT hay UPDATE như ngôn ngữ lập trình thủ tục nhưng thứ có thể phát huy toàn lực để làm được điều đó chính là hàm CASE (CASE expression).
Cũng như cách gọi là hàm chứ không phải là câu lệnh CASE (statement) thì nó cũng giống như biểu thức 1 + (2 - 4) hay (x * y)/z thì khi chạy nó được đánh giá như một giá trị. Vì giống như biểu thức nên nếu là chỗ có thể viết được biểu thức (1 + 1) thì cũng có thể viết được. Vì cuối cùng thì nó sẽ được tóm lại thành một giá trị nên cũng có thể đưa vào làm đầu vào của hàm số toán học.
Nếu cứ bị ám ảnh trong ý tưởng của ngôn ngữ lập trình thủ tục, nếu cứ phân ra xử lý theo đơn vị câu lệnh thì chương trình sẽ bao gồm một lượng rất lớn SQL nhưng nếu sử dụng đơn vị hàm thì có thể viết được những truy vấn dễ đọc mà gọn gàng.
Về điểm trả lại một giá trị đối với đầu vào thì hàm CASE chình là một loại hàm số. Chính vì vậy suy nghĩ khi sử dụng hàm CASE cũng gân fvowis khi sử dụng ngôn ngữ dạng hàm số. Trong Lisp cũng có những chức năng để ghi lại case hay cond nhưng khác với câu lệnh IF của ngôn ngữ lập trình thủ tục thì đây là hàm số. Chính vì vậy, cũng giống như hàm CASE thì nó không phải là statement mà là expression nên cái nào giá trị trả về cũng là một giá trị. (Trong Lisp có một điểm khác SQL chính là nhìn một danh sách cũng như một giá trị thì cái đó trong SQL được sử dụng như một dạng dữ liệu phức hợp)
Để thử nghiệm thì chúng ta cùng đặt hai cái đó với nhau để so sánh.
'Chia theo hàm số cond của Lisp'
cond(
((=x 1) 'x là 1')
((= x 2) 'x là 2')
(t 'x là một số khác'))
--Chia theo hàm CASE của SQL
CASE WHEN x = 1 THEN 'x là 1'
WHEN x = 2 THEN 'x là 2'
ELSE 'x là số khác'
END
Ngoài điểm những kí hiệu trong Lisp khác ra thì động tác là giống nhau. Chúng ta có thể lồng điều kiện vào điều kiện nên điểm cả hai hàm này giống nhau đó chính là có thể ghi phân chia nhiều tầng. Vì vậy những người đã quen với ngôn ngữ dạng hàm số rồi thì có thể ngay lập tức hiểu hàm CASE của SQL, mà đó cũng là điều đương nhiên. Việc tìm ra điểm chung là cầu nối giữa những ngôn ngữ với nhau như thế này để có thể hiểu được nhiều ngôn ngữ cũng là một điều quan trọng.
Tham khảo --> Chương đầu
2. Vòng lặp thay bằng câu lệnh GROUP BY và subquery tương quan
Trong SQL không tồn tại vòng lặp ở đơn vị câu lệnh. Nếu sử dụng console thì không nói làm gì, đó là câu chuyện trong thế giới lập trình thủ tục, nhưng trong SQL nguyên chất thì điều đó không liên quan. SQL ngay từ những ý tưởng thiết kế ban đầu đã hướng đến việc loại bỏ vòng lặp. Cái này được chứng minh trong câu nói của chính Codd.
Thao tác quan hệ lấy đối tượng là thao tác trên toàn bộ quan hệ. Mục đích chính là làm mất đi sự lặp đi lặp lại (loop). Nếu suy nghĩ về tính sản xuất cho người sử dụng thì đây là là yêu cầu không thể thiếu và nếu suy nghĩ về tính sản xuất cho lập trình viên ứng dụng thì đây rõ ràng là điều mang lại lợi ích.
Trong những xử lý chắc chắn có khi sử dụng vòng lặp trong ngôn ngữ lập trình thủ tục chắc chắn có là control break, nhưng chúng ta cũng có thể biểu hiện nó bằng GROUP BY và subquery tượng quan trong SQL. Subquery tương quan là một trong những điểm dễ vấp đối với những người mới học SQL nhưng đây là một kĩ thuật rất hiệu quả khi suy nghĩ việc phân chia đơn vị xử lý.
Thỉnh thoảng những lập trình viên đã cố định những ý tưởng của ngôn ngữ lập trình thủ tục thì những phần chỉ cần thực hiện tóm lại bằng GROUP BY thì lại tự nhiên lại tiến hành lấy kết quả của SELECT, tóm lại từng dòng trong loop bằng console, chắc chắn đây là câu chuyện thực buồn cười mà không cười nổi mà mọi người không ít lần nghe được.
Mọi người đừng quên rằng SQl không có vòng lặp, mà không có cũng không gây bất cứ trở ngại nào cả. SQL hơn nữa còn lấy một trong những mục đích của mình chính là làm mất vòng lặp ra khỏi quá trình lập trình.
Tham khảo -> "So sánh dòng với dòng bằng subquery tương quan" "Phép toán tập hợp trong SQL"
3. Không có thứ tự trong dòng của bảng
Những kĩ sư đã quen với hệ thống file hay ngôn ngữ lập trình thủ tục (mà nói quá lên thì hầu hết chúng ta) thì lúc nào cũng có tật lý giải bảng của DBMS tương tự theo file.
Việc này ở một ý nghĩa nào đó thì là điều không có cách nào khác. Khi định hiểu một khái niệm nào đó một trong những phương pháp hữu hiệu đầu tiên là kết nối nó với một khác niệm mà ta đã hiểu, mà cũng có thể nói đó gần như là phương pháp duy nhất. Tuy nhiên, khi đến một trình độ nào đó thì chúng ta phải vứt đi, thoát khỏi cách lý giải cũ này. Điều nguy hiểm nhất khi nhìn bảng như một file đó chính là nhầm lẫn rằng các dòng sẽ có thứ tự.
Trong file thì thứ tự của dòng là một điều rất quan trọng. Khi mở một text file thì nếu các dòng không được sắp xếp theo một thứ tự định sẵn thì sẽ không trở thành thứ có thể sử dụng được. Tuy nhiên, đối với cơ sở dữ liệu quan hệ thì khi gọi bảng ta cũng sẽ xảy ra điều tượng tự. Không có gì bảo đảm rằng sẽ gọi ra được thứ tự đã INSERT nhưng đối với những thao tác dữ liệu trong SQL thì điều đó cũng không cần thiết. SQL kể cả không có thứ tự cũng đủ để thực hiện.
Bảng (Quan hệ) trong cơ sở dữ liệu quan hệ chính là một lại trong tập hợp (set) của toán học. Vứt đi khái niệm nhìn thấy bằng mắt là thứ tự thì bảng là khái niệm có thể suy nghĩ là để nâng cao đến giới hạn có thể độ trừu tượng. Từ ban đầu đây là hai khái niệm với khởi nguồn khác nhau nên cũng không có gì vô lý khi bảng và file lại khác nhau. Nếu hình dung bảng thì so với việc hình dung nó như một chất kết nối dữ liệu được sắp xếp theo một thứ tự thì nhìn nó như một hộp đồ chơi hay một cái cập có rất nhiều loại dữ liệu sẽ gần hơn.
Nếu chúng ta cứ không để ý đến điều này mà cứ cố tình theo ý tưởng thứ tự thì sẽ sinh ra một code phức tạp một cách lãng phí và không có tính di chuyển. Ví dụ khi định nghĩa view chúng ta lại chỉ định câu lệnh ORDER BY hay theo dãy thứ tự dòng như rownum của ORACLE thì đây đều là những trở ngại mang tính cổ điển của chỉ hướng thứ tự.
Đây được ví như kim chỉ mà nhà vật lý học Feynman đã nói cho những học trò lần đầu tiên học lượng tử học của mình rằng "Không được lý giải những kiến thức mới này tương tự theo lý thuyết lực học của Newton đã được học từ trước". "Vì lượng tử không giống những gì mà mọi người đã học từ trước đến nay."
Khi học những khái niệm mới thì chúng ta cần cần một lần vứt đi những khái niệm cũ, hoặc ít nhất thì chỉ lấy một chút để tương đối hoá. Đây không phải là một phương pháp học mới mà có khi nó là phương pháp học chính thức được sử dụng từ trước đến nay cũng nên. Nhưng phương pháp chính này là khó nhất. Khi rời xa những chuẩn đã quen thuộc thì thứ cần thiết ở đây không phải là trí lực mà chính là dũng cảm.
Tham khảo --> 1-4, 1-10, 1-9
4. Cùng nhìn bảng như một tập hợp
Cũng như đã nêu ở trên thì bảng so với file có tính trừu tượng cao hơn nhiều. File có liên hệ mật thiết với phương pháp lưu của nó nhưng khi sử dụng bảng hay view trong SQL thì hoàn toàn không cần phải để ý đến việc sử dụng như thế nào trên bộ nhớ. (Nếu loại trừ đi mặt perfomance). Chúng ta rất hay có thói quen nhìn bảng thành file nhưng trên thực tế thì một bảng không đối ứng như một file và cũng không đọc ra từng dòng như file.
Phương pháp tốt nhất để hiểu được tính trừu tượng của bảng chính là sử dụng tự kết hợp. Vì đây là kĩ thuật có khả năng biểu diễn tính trừu tượng (hay có thể nói là tính tự do) của khái niệm tập hợp cao nhất. Trong SQL, chúng ta có thể sử dụng những bảng giống nhau được gắn những cái tên khác nhau như những bảng khác nhau. Có nghĩa là khi sử dụng tự kết hợp thì có thể tạo ra bảng với số lượng tuỳ thích. Độ tự do cao không những chính là mị lực của SQL mà cũng chính là sức mạnh của nó.
Tham khảo --> 1-2
5. Cùng hiểu khái niệm "Lượng hoá" và vị từ EXISTS
Lý luận bổ trợ cho SQL không chỉ là luận tập hợp mà còn có một luận nữa. Đó chính là lý luận vị từ (predicate logic). Đặc biệt trong trường hợp SQL thì nó được giới hạn trong logic vị từ bậc 1. Logic vị từ có lịch sử gần 100 năm và nó cũng trở thành một logic thông dụng trong logic hiện nay.(Trong lĩnh vực logic học thì cái gì chúng ta cũng gọi là logic, nhưng đó chính là logic vị từ bậc 1)
Trường hợp logic vị từ đặc biệt phát huy sức mạnh chính là khi sử dụng một số dòng như một đơn vị. Logic vị từ có một vị từ là "Lượng hoá" chỉ một công cụ để tóm tắt thành một số đối tượng thành một để sử dụng. Trong SQL thì đây chính là vị từ EXISTS.
Cách dùng EXISTS cũng giống như cách dùng của vị từ IN nên mọi người có thể dễ hiểu nhưng thứ hay được sử dụng hơn đó chính là NOT EXISTS. Trong SQL chỉ biểu hiện được trực tiếp được lượng hoá thoả mãn một trong những điều kiện, vậy nên để biểu hiện được lượng hoá với mọi thì những lập trình viên chỉ có thể sử dụng gián tiếp thông qua NOT EXISTS để viết.
Những truy vấn sử dụng NOT EXISTS nói một cách thẳng thắn thì không phải là những tuỷ vấn dễ đọc. Hơn nữa lại có thể sử dụng câu lệnh HAVING hay vị từ ALL nên nhiều lập trình viên có bỏ qua nó. Tuy nhiên NOT EXISTS có một lợi điểm rất lớn. Đó chính là so với câu lệnh HAVING hay vị từ ALL thì nó có một bậc tốt hơn hẳn về perfomance.
Đối với trường hợp ưu tiên hơn khả năng đọc hiểu thì chúng ta không cần thiết phải sử dụng NOT EXISTS. Tuy nhiên chắc chắn có những trường hợp không thể đánh đổi được perfomance. Nên chúng ta cũng cần thiết lý giải được kĩ thuật biểu diễn lượng hoá với mọi gián tiếp sử dụng NOT EXISTS.
Tham khảo --> 1-8, 1-9
6. Học giá trị thực của câu lệnh HAVING
Có thể nói câu lệnh HAVING trong những chức năng của SQL thì bị coi nhẹ nhất. Tuy nhiên thì việc không biết giá trị thật của câu lệnh HAVING cũng là câu chuyện không thể có hiện nay. Câu lệnh HAVING nếu nói là tính năng được tập hợp những bản chất của SQL như một ngôn ngữ hướng tập hợp cũng không phải là nói quá. Con đường gần nhất để trang bị được cách nghĩ của SQL đó chính là học cách sử dụng câu lệnh HAVING, đây chính là suy nghĩ của tác giả trong những năm gần đây.
Tại sao lại có thể nói như vậy, là vì khác với câu lệnh WHERE thì HAVING là nơi thiết kế điều kiện với chính những đối tượng là tập hợp nên để có thể sử dụng thành thạo được ở đây thì cần phải nắm rõ quan điểm nhìn bảng như tập hợp. Vậy nên, trong lúc luyện tập câu lệnh HAVING thì chúng ta có thể từ lúc nào không biết có thể hiểu được bản chất của hướng tập hợp, và đây chính là sự sắp xếp mong muốn. Và về những hoạt động khi thao tác dữ liệu sử dụng câu lệnh HAVING chính là luận phương pháp "Vẽ vòng tròn" dưới đây.
Tham khảo --> 1-4, 1-10
7. Đừng vẽ tứ giác, hãy vẽ hình tròn
Những tool mang tính thị giác giúp cho việc lập trình bằng ngôn ngữ lập trình thủ tục, có rất nhiều những tích tụ mang tính lịch sử từ trước đến nay. Đặc biệt quan sát những năm 1970 thì những thứ đã phát triển qua thời gian dài như biểu đồ cấu trúc (Structure Diagram) hay DFD (Data Flow Diagram) được chú ý như những công cụ phát huy được hiệu quả cao. Những biểu đồ này thông thường được biểu diễn bằng những mũi tên chỉ dòng chảy của dữ liệu trong những hộp thủ tục (xử lý).
Tuy nhiên, những dụng cụ truyền thống thế này thì nếu coi như một phương tiền giúp đỡ trong việc lập trình SQL thì không hướng đến. SQL chẳng qua chỉ để ghi những điều kiện của dữ liệu mong muốn chứ hoàn toàn không biểu diễn những thao tác động. Bảng cũng chỉ là biểu hiện những dữ liệu tĩnh. Nói một cách khác thì nó không khác gì hành động chúng ta đưa ra quảng cáo về tuyển người gắn những điều kiện như "Không yêu cầu kinh nghiệm" hay "Dưới 35 tuổi" mà thôi. Tìm những nhân lực trên thực tế phù hợp với điều kiện chọn lọc đề ra chính là công việc của cơ sở dũ liệu.
Biểu đồ thị giác đích xác nhất để biểu diễn những mô hình dữ liệu tĩnh như thế này chính là biểu đồ Benz, hay chính là những hình tròn. Hơn nữa, bằng việc vẽ những hình tròn của đầu vào chính là một cách để nâng cao bước nhảy để hiểu được SQL. Trong SQL thì cách sử dụng tập hợp đầu vào chính là một trong những chìa khoá để sử dụng. Chúng ta có thể chia tập hợp thành những tập hợp bộ phận bằng GROUP BY hoặc PARTITION BY rồi ngay cả mô hình tập hợp để sử dụng cấu trúc cây hay cấu trúc hồi quy của máy tính kiểu Neumann cũng có thể phát huy được chức năng của mình. Có thể nói rằng việc hình dung tốt tập hợp hồi quy để sử dụng chính là trung tâm để master được lập trình SQL trung cấp.
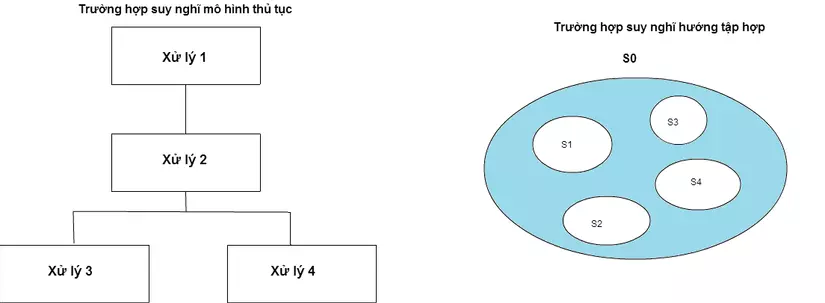
Bruce Lee, một thần thánh trong giới điện ảnh đã có một câu nói rất nổi tiếng "Don't think. Feel" (Đừng nghĩ ngợi, hãy cảm nhận) thì thần thánh trong thế giới cơ sở dữ liệu, Joe Celko cũng có câu nói rất nổi tiếng "Đừng vẽ những mũi tên và cái hộp, hãy vẽ hình tròn". (Tham khảo quyển "Joe Celko's Programming Style" chương 9.7. Do not think with Boxes and Arrows và 9.8. Draw Circle and Set Diagrams)
Tham khảo --> 1-4 1-7
All rights reserved
