1-9 Sử dụng dãy số trong SQL
Bài đăng này đã không được cập nhật trong 4 năm
>Cùng sử dụng thành thạo luận lý vị từ Trong SQL, về cơ bản thì dữ liệu được lấy như những thứ không có thứ tự. Chính vì vậy nên cách lấy dữ liệu mà có để ý đến thứ tự thì sẽ khá khác với những ngôn ngữ thủ tục và file system. Chương này sẽ giải thích dãy số trong ví dụ từ đó lấy ra những nguyên lý cơ bản của SQL từ đằng sau những giải pháp đề xuất.
Bắt đầu
Cấu tạo của dữ liệu trong mô hình quan hệ không có khái niệm thứ tự. Tất nhiên trong thực hiện của bảng hay view của cơ sở dữ liệu quan hệ thì cũng không có thứ tự của dòng. Cùng với đó SQL cũng không lấy mục đích trực tiếp lấy tập hợp theo thứ tự.
Chính vì vậy, cách lấy tập hợp theo thứ tự trong SQL về tính chất thì khác rất nhiều so với cách lấy thứ tự ngay từ đầu giống như đường đi của file system và những ngôn ngữ thủ tục khác. Tuy nhiên mặc dù khác về tính chất nhưng chắc chắn có những nguyên lý là cố định. Nếu nói bằng một câu thì cách sử dụng vị từ một cách đặc biệt gọi là "Lượng hoá" (Quantifier) được nêu ra trong chương trước chính là chìa khoá ở đây.
Tại chương này chúng ta sẽ sử dụng SQL và giải thích những phương pháp sử dụng dữ liệu có thứ tự như ngày tháng hay dãy số. Ở đây chúng tôi không chỉ nêu lên những Tips mà cố gắng đưa ra những nguyên lý cơ bản cùng với giải pháp và muốn thử tóm tắt kim chỉ nam thông thường nhất thích hợp ngay cả với những vấn đề chưa biết.
Cùng tạo dãy số liên tục
Chúng ta cùng suy nghĩ cách tạo một dãy số liên tục bằng SQL. Gần đây có khá nhiều những thực hiện có đối tượng tiếp nối nên trong trường hợp muốn lấy từ trong dãy số liên tục từng số theo một thứ tự thì chúng ta có thể dùng cái này. Tuy nhiên, trong 1 SQL mà chúng ta muốn có một dãy số liên tục có độ lớn theo ý muốn thì phải làm thế nào? Ví dụ chúng ta muốn làm 100 hàng từ 0 đến 99, nếu trong trường hợp có thể giao cho sự thực hiện chương trình thì chúng ta có thể dùng CONNECT BY (Oracle) hay WITH (DB2, SQLServer). Nhưng tại đây thì chúng ta hạn định phương pháp không thể làm như vậy.
Trước khi suy nghĩ vào vấn đề thì hơi đột ngột một chút nhưng chúng ta cùng suy nghĩ một câu đố sau.
Vấn đề: Trong 100 số của dãy số 0~99 thì những chữ số 0,1,2,...,9 thì mỗi chữ số có bao nhiêu số có trong đó?
Những chữ số có 1 hàng thì chúng ta sẽ thêm 0 vào đầu và viết như sau [01] [02] [03]. Chúng ta không viết ra giấy mà chỉ thử suy nghĩ trong đầu thôi nhé. Và, bắt đầu...
...Các bạn có làm được không? Câu trả lời đúng là mỗi chữ số xuất hiện 20 lần. Ví dụ đối với số 1 thì chúng ta đếm những chỗ số một chục và những số có 1 ở hàng đơn vị. Số có sỗ hàng chục là 1 có 10 số, số số có chữ số hàng đơn vị là 1 cũng có 10 số, số 11 thì có cả 2 điều kiện trên, vì chỉ có số này lại có 2 con số 1 nên không thể đếm trùng.
| 00 | 01 | 02 | 03 | 04 | 05 | 06 | 07 | 08 | 09 |
|---|---|---|---|---|---|---|---|---|---|
| 10 | 11 | ** 12** | 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 |
| 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 | 48 | 49 |
| 50 | 51 | 52 | 53 | 54 | 55 | 56 | 57 | 58 | 59 |
| 60 | 61 | 62 | 63 | 64 | 65 | 66 | 67 | 68 | 69 |
| 70 | 71 | 72 | 73 | 74 | 75 | 76 | 77 | 78 | 79 |
| 80 | 81 | 82 | 83 | 84 | 85 | 86 | 87 | 88 | 89 |
| 90 | 91 | 92 | 93 | 94 | 95 | 96 | 97 | 98 | 99 |
Điều muốn nói ở đây là trong trường hợp một số mà được nhìn như một chữ, thì ta nắm được những vị trí đó như những tập hợp được tạo nên từ sự kết hợp từ những số được cấu tạo bởi những vị trí đó. Vậy giờ câu hỏi kết thúc.
Bây giờ chúng ta quay lại với vấn đề chính. Đầu tiên, chúng ta tạo một bảng số có những chữ số là thành tố cấu thành. Đây là bảng chuyên dụng đọc có cố định 10 dòng. Kể cả là số lớn thế nào đi chăng nữa thì chuyện nó được cấu thành từ 10 số cơ bản này là chuyện rõ ràng.
Digits
| digit |
|---|
| 0 |
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
| 6 |
| 7 |
| 8 |
| 9 |
Như vậy những số 0~99 thì chúng ta có thể tạo nên bằng sự kết hợp giữa 2 tập hợp Digits.
--Tạo dãy số liên tục. Bản 1: 0~99
SELECT D1.digit + (D2.digit * 10) AS seq
FROM Digits D1, Digits D2
ORDER BY seq;
Kết quả
seq
-----
1
2
:
:
:
98
99
D1 hiện vị trí hàng đơn vị còn D2 thể hiện vị trí hàng chục. Trong phần tự tổ hợp thì chúng ta cũng đã nhìn thấy cách kết hợp Cross của những bảng giống nhau trong "Cách dùng tự tổ hợp" đúng không? Như vậy trong kết hợp Cross thì chúng ta có thể có được tất cả những kết hợp có thể từ những thành tố có trong 2 tổ hợp như dưới đây.
Cứ như vậy nếu ta thêm D3, D4,... vào thì chúng ta có thể tạo được số bao nhiêu hàng tuỳ thích cũng được. Rồi đối với những trường hợp như số đầu tiên không phải là 0 mà bắt đầu từ 1, hay trường hợp muốn dừng từ giữa chừng như đến [542] thì ta có thể dùng câu lệnh WHERE để thêm điều kiện.
--Tạo dãy số liên tục. Bản 1: 1~542
SELECT D1.digit + (D2.digit * 10) + (D3.digit * 100) AS seq
FROM Digits D1 CROSS JOIN Digits D2 CROSS JOIN Digits D3
WHERE D1.digit + (D2.digit * 10) + (D3.digit * 100) BETWEEN 1 AND 542
ORDER BY seq;
Các bạn có nhận ra không? Trong phương pháp tạo nên dãy số liên tục như thế này thì tính chất gọi là thứ tự của số thì bị phớt lờ đi. Trong quyển sách này cũng thử so sánh với định nghĩa thứ tự của dãy số kiểu Neumann thì tại đây có sự khác nhau. Trong định nghĩa sử dụng tập hợp hồi quy thì từ khi định nghĩa 0 thì có thể có 1, sau khi định nghĩa 1 thì ta có 2, và có một thứ tự như vậy. (Là thứ phù hợp với ghi quan hệ dãy số như luỹ kế hay bảng xếp hạng).
Mặt khác, vứt đi khái niệm thứ tự thì đây là con đường không nhìn quá là một sự kết hợp số từ những con số. Với ý nghĩa này thì chính là ý nghĩa mang tính SQL.
Nếu chúng ta lưu truy vấn này là một view thì có thể có được một dãy số liên tục đơn giản bằng một câu lệnh SELECT.
--Tạo view nối tiếp (0~999)
CREATE VIEW Sequence (seq)
AS SELECT D1.digit + (D2.digit * 10) + (D3.digit * 100)
FROM Digits D1 CROSS JOIN Digits D2 CROSS JOIN Digits D3;
--Tạo view nối tiếp: lấy số 0~100
SELECT seq
FROM Squence
WHERE seq BETWEEN 1 AND 100
ORDER BY seq;
Đây là một view rất tiện lợi có thể dùng mọi nơi nên chỉ cần tạo một cái thôi thì có thể có lợi khi dùng ở nhiều cục diện.
Tìm tất cả những bộ phận bị khuyết
Trong "Sức mạnh của câu lệnh HAVING" cũng đã giới thiệu phương pháp tìm những điểm bị khuyết trong dãy số liên tiếp. Trong lúc đó thì trong trường hợp có rất nhiều lỗ khuyết thì chúng ta chỉ có được giá trị nhỏ nhất cảu nó thôi. Nhưng trong lúc đọc thế này thì chắc chắn sẽ không có ít người sẽ nghĩ rằng đã như vậy thì tôi muốn tìm ra tất cả những điểm khuyết luôn.
Hãy giao cái đó cho tôi. Nếu sử dụng view nối tiếp trong câu trước thì chúng ta có thể dễ dàng đáp ứng như cầu của những người đầy mong muốn như bên trên. Nếu có thể tạo được tập hợp số tự nhiên không có lỗ khuyết 0~n thì sau đó chúng ta chỉ cần sử dụng phép tính giao tập hợp thì có thể có ngay tất cả kết quả mong muốn. Tiếp theo, những phương pháp để có được tập hợp giao trong SQL thì được chuẩn bị rất phong phú. Sử dụng EXCEPT là chuyện đương nhiên thì ngoài ra chúng ta có thể sử dụng NOT IN hay NOT EXISTS.
Trong ví dụ mẫu thì chúng ta có một bảng là dãy số liên tiếp có những lỗ khuyết như sau.
SeqTbl
| seq |
|---|
| 1 |
| 2 |
| 4 |
| 5 |
| 6 |
| 7 |
| 8 |
| 11 |
| 12 |
Vì giá trị nhỏ nhất là 1 và giá trị lớn nhất là 12 nên chúng ta cũng kết hợp phạm vi này với phạm vi của dãy số liên tục. Với truy vấn dưới đây sẽ trả lại kết quả số lỗ khuyết là 3, 9, 10.
--Phiên bản EXCEPT
SELECT seq
FROM Sequence
WHERE seq BETWEEN 1 AND 12
EXCEPT
SELECT seq FROM SeqTbl;
--Phiên bản NOT IN
SELECT seq
FROM Sequence
WHERE seq BETWEEN 1 AND 12
AND seq NOT IN (SELECT seq FROM SeqTbl);
Kết quả
seq
---
3
9
10
Với những người vẫn còn sự không thoả mãn với vấn đề trước thì tại đây có thể giải quyết một cách gọn gàng rồi đúng không?
Tiếp theo, mặc dù giá để thực hiện có hơi cao một chút nhưng chúng ta nhất quán hoá đầu vào của vị từ BETWEEN và lấy ra giá trị lớn nhất và nhỏ nhất của bảng muốn điều tra.
--Query quyết định phạm vi động của dãy số
SELECT seq
FROM Sequence
WHERE seq BETWEEN (SELECT MIN(seq) FROM SeqTbl)
AND (SELECT MAX(seq) FROM SeqTbl)
EXCEPT
SELECT seq FROM SeqTbl;
Với cách này thì trong trường hợp mà giá trị trần và giá trị sàn của bảng không cố định thì rất tiện lợi. 2 subquery này là phi tương quan nên chỉ được thực hiện 1 lần, nếu dãy seq còn có index thì có thể làm nhanh hơn sự hiện kết quả của hàm số cực trị.
Chúng tôi có 3 người, vậy có ngồi được không?
Khi đi du lịch với bạn bè thì khi chúng ta đặt ghế trên máy bay hay tàu điện thì không nếu không có dãy ghế ngồi liên tục mà tự nhiên chỉ một người phải ngồi ở một chỗ khác biệt thì chắc chắn không ít người đã phải trải qua kinh nghiệm cô đơn như thế này. Trong phần này chúng ta cùng suy nghĩ đến một vài trường hợp những mảnh ghép xung quan việc chọn chỗ ngồi như thế này.
Chúng ta có một bảng thể hiện tình trạng ghế trống của những chỗ ngồi như sau.
Seats
| seat | status |
|---|---|
| 1 | Đầy |
| 2 | Đầy |
| 3 | Trống |
| 4 | Trống |
| 5 | Trống |
| 6 | Đầy |
| 7 | Trống |
| 8 | Trống |
| 9 | Trống |
| 10 | Trống |
| 11 | Trống |
| 12 | Đầy |
| 13 | Đầy |
| 14 | Trống |
| 15 | Trống |
Hiện nay thì chúng ta muốn đi du lịch 3 người và đang định đặt vé trên tàu điện. Vấn đề là trong số ghế 1~15 này thì chúng ta muốn tìm 3 ghế trống liên tục. Chúng ta gọi tập hợp có những số liên tiếp này là Sequence. Mà thực ra nó chỉ là tập hợp số liên tiếp thôi. Vậy nên trong Sequence không thế có lỗ khuyết được.
Kết quả ta muốn có từ dữ liệu trên
- 3~5
- 7~9
- 8~10
- 9~11
Sequence (7,8,9,10,11) có chứa 3 tập hợp liên tiếp khác là (7,8,9), (8,9,10), (9,10,11) nhưng chúng ta cũng đếm những tập hợp này một cách phân biệt. Tất nhiên trên thực tế thì những dãy ghế này có thể giữa chừng chuyển hàng nhưng ở đây chúng ta bỏ qua vấn đề đó và coi như 15 ghế này sắp xếp liên tiếp nhau.

Theo như nhận xét thì nếu gọi số mở đầu là n thì số n + (3-1) thì tất cả đều ở trạng thái ghế trống. (Nếu không trừ 1 thì mọi người nên chú ý để không bị quá q chỗ ngồi quá. Câu trả lời sẽ được trả lời như sau.
--Tìm ghế trống cho số người cho trước. Phiên bản 1: không nghĩ đến viêc ghế bị cắt hàng
SELECT S1.seat AS start_seat, '~', S2.seat AS end_seat
FROM Seats 1, Seats 2
WHERE S2.seat = S1.seat + (:head_cnt -1) -- Quyết định điểm đầu và điểm cưới.
AND NOT EXISTS
(SELECT *
FROM Seats S3
WHERE S3.seat BETWEEN S1.seat ANG S2.saet
AND S3.seat <> 'Trống'
:head_cnt là thông số biểu hiện những người muốn ngồi. Chỉ cần đưa vào thông số này thì cũng có thể đối ứng được với tập hợp bao nhiêu người cũng được khi số người thay đổi.
Trong truy vấn này thì có môt nguyên lý rất hay xuất hiện khi sử dụng tập hợp liên tiếp trong SQL. Từ đây thì chúng ta sẽ đi giải thích kĩ từng thứ đó. Chúng ta chia những điểm chủ yếu của truy vấn này làm hai, và suy nghĩ nó như 2 tầng thì sẽ dễ hiểu hơn. Đầu tiên, tầng 1,
Step 1: Tạo kết hợp điểm đầu, điểm cuối bằng tự kết hợp
Nếu nói trong truy vấn này thì chính là bộ phận S2.seat = S1.seat + (:head_cnt - 1). Dựa vào đó thì chúng ta loại trừ được những kết hợp có độ lớn ngoài 3 như [2~3] hay [1~8], như vậy chúng ta có thể giới hạn chỉ những dãy số liên tiếp bao gồm vừa đúng 3 ghế trống từ điểm đầu đến điểm cuối.
Step 2: Điền điều kiện của tất cả những điểm từ điểm đầu đến điểm cuối cần thoả mãn
Nếu đã quyết định được điểm đầu và điểm cuối thì lần này chúng ta sẽ điền điều kiện mà những điểm có trong đó cần thoả mãn. Để làm việc đó thì chúng ta thêm tập hợp điểm di chuyển giữa điểm đầu và điểm cuối. (Với truy vấn trên thì là S3), trong trường hợp viết ra một phạm vi di chuyển thì vị từ BETWEEN sẽ tiện lợi. Lần này thì điều kiện mà những thành tố trong sequence cần thoả mãn là,
Tình trạng tất cả các hàng ghế là "Trống"
Ở chương trước thì chúng ta cũng nhìn thấy hình thức của điều kiện này rồi đúng không? Đây là một loại mệnh đề tên là mệnh đề toàn xưng trong nguyên lý vị từ. Tuy nhiên, trong SQL thì chúng ta không thể điền điều kiện này một cách một phát trực tiếp được. Như vậy trong trường hợp suy nghĩ về lượng hoá toàn xưng thì trong SQL chún ta cần biến "Tất cả các hàng thoả mãn điều kiện P" thành
Không có hàng nào không thoả mãn điều kiện P
Như vậy thì điều kiện trong subquery không phải là [S3.status = 'Trống'] mà là thể phủ định [S3.status <> 'Trống']
Tiếp theo, như một bản ứng dụng, chúng ta cùng nghĩ đến trường hợp các hàng ghế có thể bị chia đứt giữa chừng. Ví dụ giả định như đây là tàu mà sẽ chỉ có 5 dãy thôi. Trong bảng chúng ta sẽ thêm dòng row_id vào.
Seats2
| seat | row_id | status |
|---|---|---|
| 1 | A | Đầy |
| 2 | A | Đầy |
| 3 | A | Trống |
| 4 | A | Trống |
| 5 | A | Trống |
| 6 | B | Đầy |
| 7 | B | Trống |
| 8 | B | Trống |
| 9 | B | Trống |
| 10 | B | Trống |
| 11 | C | Trống |
| 12 | C | Đầy |
| 13 | C | Đầy |
| 14 | C | Trống |
| 15 | C | Trống |
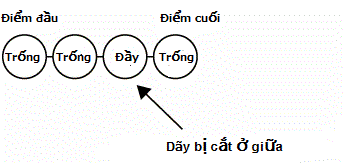
Trong trường hợp này thì kể cả đó là dãy số liên tục thôi như (9,10,11) thôi thì chưa được. Như vậy người số 11 sẽ phải ngồi một mình.
Đối với trường hợp phải đối ứng với việc không phải hàng ghế liên tục mà bị cắt giữa chừng như thế này thì không chỉ với điều kiện trong requence thì tất cả ghế đều là trống mà cần thiết phải có thêm điều kiện "Tất cả những ghế đó phải cùng một hàng". Như vật thì chúng ta có thể dễ dàng sửa như sau.
--Tìm ghế trống cho số người cho trước. Phiên bản 2: có nghĩ đến viêc ghế bị cắt hàng
SELECT S1.seat AS start_seat, '~', S2.seat AS end_seat
FROM Seats 1, Seats 2
WHERE S2.seat = S1.seat + (:head_cnt -1) -- Quyết định điểm đầu và điểm cưới.
AND NOT EXISTS
(SELECT *
FROM Seats S3
WHERE S3.seat BETWEEN S1.seat ANG S2.saet
AND ( S3.seat <> 'Trống'
OR S3.row_id <> S1.row_id));
Kết quả
start_seat '~' end_seat
---------- --- ---------
3 ~ 5
8 ~ 10
11 ~ 13
Tất cả những điều kiện mà những thành tố trong Sequence phải thoả mãn đó chính là "Tất cả các hàng thì tình trạng ghế phải là trống và ID của hàng thì phải giống nhau". Về phía sau thì chúng ta đã thêm điều kiện để ID hàng giống nhau nhưng với điều kiện thế này thì chỉ là cùng hàng với điểm bắt đầu (tất nhiên chúng ta thay đó là điểm cuối thì cũng không sao). Nếu chúng ta dịch trực tiếp điều kiện này bằng SQL thì đó sẽ là,
S3.status = "Trống" và S3.row_id = S1.row_id
Tuy nhiên, với trường hợp này cũng như đã viết ở trên thì chúng ta phải dùng thể phủ định nên điều kiện trong SQL sẽ là
NOT (S3.status = "Trống" và S3.row_id = S1.row_id)
= S3.status <> "Trống" và S3.row_id <> S1.row_id
Hình thức biến đổi khẳng định <=> 2 lần khẳng định như thế này là một kĩ thuật rất cần thiết trong SQL nên mọi người hãy luyện tập để có thể sử dụng một cách thuần thục.
Tối đa có bao nhiêu người có thể ngồi được?
Được nêu ra tiếp theo đây chính là mặt khác của vấn đề trước. Có nghĩa là "Với tình trạng ghế trống như thế này thì tối đa có bao nhiêu người có thể ngồi được liên tiếp với nhau?". Nói một cách khác thì chúng ta cần tính giá trị lớn nhất của requence, chúng ta sẽ sử dụng bảng "Seats3" dưới đây.
Seats3
| seat | status |
|---|---|
| 1 | Đầy |
| 2 | Trống |
| 3 | Trống |
| 4 | Trống |
| 5 | Trống |
| 6 | Đầy |
| 7 | Trống |
| 8 | Trống |
| 9 | Trống |
| 10 | Trống |
Với dữ liệu mẫu này thì chúng ta sẽ có được câu trả lời là 4 [2~5]. Để giải vấn đề này thì đầu tiên chúng ta có thể dễ dàng tạo được view liệt kê tất cả những requence. Nếu làm như vậy thì sau đó chúng ta chỉ cần lựa chọn requence có giá trị lớn nhất từ view thôi.
Trong bảng Seats3 thì để bảo đảm requence từ ghế số A nào đó đến ghế số B nào đó khác thì chúng phải thoả mãn cả 3 điều kiện.
- Điều kiện 1. Trong khoảng từ điểm bắt đầu đến điểm kết thức thì tất cả tình trạng ghế phải là "Trống"
- Điều kiện 2. Ghế trước điểm khởi đầu không phải là "Trống"
- Điều kiện 3. Ghế sau điểm kết thức không phải là "Trống"
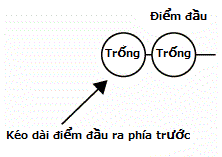
Ví dụ nếu ta nhìn từ điều kiện 1 thì nếu ở giữa có ghế "Đầy" thì việc ngay tại đó requence của ta bị thất bại thì đó là việc rõ ràng.
Trường hợp không thoả mãn điều kiện 1
 Đồng thời với đó thì cũng có thời điểm có thể kéo dài thêm điểm đầu và điểm cuối, trường hợp như vậy cũng bị xoá khỏi đối tượng lựa chọn.
Đồng thời với đó thì cũng có thời điểm có thể kéo dài thêm điểm đầu và điểm cuối, trường hợp như vậy cũng bị xoá khỏi đối tượng lựa chọn.
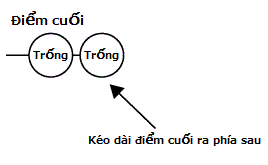
Trường hợp không thoả mãn điều kiện 2
Trường hợp không thoả mãn điều kiện 3
Vấn đề lần này cũng giống như lần trước, cần phải thoả mãn những bước step 1, step 2 nên chúng ta cũng tạo một view như sau.
--Giai đoạn 1: Tạo view có tất cả các requence
CREATE VIEW Sequence (start_seat, end_seat, seat_cnt) AS
SELECT S1.seat AS start_seat
S2.seat AS end_seat
S2.seat - S1.seat + 1 AS seat_cnt
FROM Seats3 S1, Seats3 S2
WHERE S1.seat <= S2.seat --Step 1: Tạo kết hợp điểm đầu, điểm cuối
AND NOT EXISTS --Step2: Điền những điều kiện cần thoả mãn của những thành tố trong sequence
(SELECT *
FROM Seats3 S3
WHERE ( S3.seat BETWEEN S1.seat and S2.seat
AND S3.status <> 'Trống') --Phủ định điều kiện 1
OR (S3.seat = S2.seat +1 AND S3.status = 'Trống') --Phủ định điều kiện 3
OR (S3.seat = S1.seat -1 AND S3.status = 'Trống')); --Phủ định điều kiện 2
View này sẽ bao gồm những nội dung sau.
start_seat end_seat seat_cnt
---------- -------- --------
2 5 4
7 7 1
9 10 2
Chúng ta có thể sẽ để ý đến độ lớn 1 của requence 7~7 nhưng lần này cứ coi như tập hợp này cũng có thể được bao gồm. (Nếu muốn loại bỏ tập hợp có độ lớn 1 thì chúng ta chỉ cần loại bỏ dấu "=" trong điều kiện của câu lệnh WHERE [S1.seat <= S2.seat]).
Nếu có thể hoàn thành đến đây thì đằng sau rất đơn giản. Từ view này chúng ta chọn hàng có số ghế (seat_cnt) lớn nhất.
--Giai đoạn 2: Tìm requence có số ghế lớn nhất
SELECT start_seat, '~', end_seat, seat_cnt
FROM Requences
WHERE seat_cnt = (SELECT MAX(seat_cnt) FROM Sequences);
Trong vấn đề lần này thì chúng ta cũng dùng tự kết hợp với kết hợp điểm đầu và điểm cuối (S1.seat <= S2.seat). Cách này thì cũng đã có trong "Cách sử dụng tự kết hợp".
Tiếp theo nếu đã quyết định điểm đầu và điểm cuối thì để ghi điều kiện để tất cả những dòng trong nội bộ tập hợp phải thoả mãn thì chúng ta tạo tập hợp S3 di động giữa điểm đầu và điểm cuối, rồi chuyển đồng giá trị từ lượng hoá toàn xưng sang phủ định của phủ định. Về đoạn này thì hoàn toàn giống với câu trên.
2 steps này là những thứ nhất định có khi sử dụng tập hợp có thứ tự trong SQL. Vấn đề cuối cùng tiếp theo thì mọi người cũng nên ý thức 2 điểm này. Sau này còn có "Tập hợp của chương 4" cũng dụng kĩ thuật này như một bản phát triển.
Tăng đơn điệu và giảm đơn điệu
Giả sử có một bảng chỉ hướng chuyển động của giá cổ phiếu tại một công ty.
MyStock
| deal_date | price |
|---|---|
| 2007-01-06 | 1000 |
| 2007-01-08 | 1050 |
| 2007-01-09 | 1050 |
| 2007-01-12 | 900 |
| 2007-01-13 | 880 |
| 2007-01-14 | 870 |
| 2007-01-16 | 920 |
| 2007-01-17 | 1000 |
Trong ví dụ trước thì đã nói đến thứ tự của số, và ngày tháng cũng vậy, cũng có thứ tự. Lần này chúng ta tìm thời gian mà cổ phiếu tăng đơn điệu. Có nghĩa là kết quả mong muốn là,
- 2007-01-06 ~ 2007-01-08
- 2007-01-14 ~ 2007-01-17
Chúng ta sẽ loại đi thời kì giá đi ngang trong khoảng này 8~9. Cũng như những bước đã định bên trên thì đầu tiên bắt đầu từ "Step 1: Tạo điểm đầu và điểm cuối bằng tự kết hợp".
--Query có được kết hợp điểm đầu và điểm cuối
SELECT S1.deal_date AS start_date
S2.deal_date AS end_date
FROM MyStock S1, MyStock S2
WHERE S1.deal_date > S2.deal_date;
Vì số dòng nhiều nên ở đây chúng tôi lược phần kết quả nhưng tổng công tất cả có 28 kết hợp được lựa chọn. Từ đây chúng ta sẽ bỏ đi những kết hợp không phù hợp với điều kiện đặt ra. "Step 2: Ghi điều kiện mà tất cả các điểm nằm trong khoảng từ điểm đầu đến điểm cuối phải thoả mãn".
Điều kiện đủ đảm bào trong một thời kì thì giá cổ phiếu sẽ tăng đơn điệu là trong một thời điểm nằm trong khoảng đó thì cổ phiếu trong tương lai có giá trị lớn hơn giá cổ phiếu đó trong quá khứ. Như vậy, lật lại điều kiện này chúng ta sẽ có,
- Trong 2 điểm lựa chọn trong khoảng thời gian, sẽ không tồn tại những cặp mà giá trị đằng sau nhỏ hơn giá trị đằng trước
Ví dụ, chỉ cần có một cặp [2007-01-12] = 900, [2007-01-13] = 880 như thế này thì thời kì này không gọi là tăng đơn điệu. Như vậy thì kết quả sẽ là,
--Query tìm thời kì có tăng đơn điệu: hiện cả những thành phần bên trong
SELECT S1.deal_date AS start_date
S2.deal_date AS end_date
FROM MyStock S1, MyStock S2
WHERE S1.deal_date > S2.deal_date
AND NOT EXISTS
( SELECT *
FROM MyStock S3, MyStock S4
WHERE S3.deal_date BETWEEN S1.deal_date AND S2.deal_date
AND S4.deal_date BETWEEN S1.deal_date AND S2.deal_date
AND S3.deal_date < S4.deal_date
AND S3.price >= S4.price);
Kết quả
start_date end_date
---------- -----------
2007-01-06 2007-01-08
2007-01-14 2007-01-16
2007-01-14 2007-01-17
2007-01-16 2007-01-17
Vì ta lấy 2 điểm trong khoảng thời gian nên đối ứng với nó thì ta thêm S3 và S4. Trong subquery có 2 BETWEEN để đảm bào S3, S4 chạy trong phạm vi khoảng thời gian. (Khi sử dụng tập hợp thứ tự thì sử dụng vị từ BETWEEN rất tiện lợi). Tiếp theo để S4 so với S3 là ngày trong tương lai thì ta có "S3.deal_date < S4.deal_date". Tiếp theo để ghi điều kiện giá cổ phiếu trong quá khứ phải cao hơn hoặc bằng giá cổ phiếu trong tương lai thì chúng ta có điều kiện "S3.price >= S4.price". Nhìn như thế này thì đây có vẻ là một truy vấn khá dài nhưng từng vị từ đều mang ý nghĩa rất rõ ràng.
Tuy nhiên trong kết quả này thì có bao gồm cả giai đoạn thời gian ngày 14~17 và 16~17, nên cuối cùng chúng ta sẽ làm những bước để xoá đi những tập hợp thừa này. Trường hợp này thì chúng ta có thể giải quyết rất đơn giản bằng hàm số cực trị.
--Bỏ những tập hợp bộ phận, chỉ lấy thời kì có phạm vi lớn nhất
SELECT MIN(start_date) AS start_date, end_date
FROM (SELECT S1.deal_date AS start_date,
MAX(S2.deal_date) AS end_date
FROM S1.deal_date > S2.deal_date
AND NOT EXISTS
( SELECT *
FROM MyStock S3, MyStock S4
WHERE S3.deal_date BETWEEN S1.deal_date AND S2.deal_date
AND S4.deal_date BETWEEN S1.deal_date AND S2.deal_date
AND S3.deal_date < S4.deal_date
AND S3.price >= S4.price)
GROUP BY S1.deal_date) TMP
GROUP BY end_date;
Kết quả
start_date end_date
---------- -----------
2007-01-06 2007-01-08
2007-01-14 2007-01-17
Chúng ta ở đây chỉ kéo dài nhất giới hạn của điểm đầu và điểm cuối thôi. Bây giờ nếu trong trường hợp muốn tìm tăng đơn điệu theo nghĩa rộng, có nghĩa là có thêm cả thời điểm mà giá đi ngang thì chúng ta chỉ việc bỏ đi dấu bằng theo subquery [S3.price >= S4.price] là được. Điều kiện trong subquery là điều kiện ngược với điều kiện đủ nên nếu muốn kết quả có bao gồm thời kì đó thì chúng ta chỉ việc bỏ dấu đi trong truy vấn phụ.
Kết luận
Lần này thì chúng ta đã nhìn qua cách dùng tập hợp thứ tự là đại điện cho dãy số. Những tips đơn giản đã được nêu trong phần này không phải chỉ kết thúc tại đó mà chúng tôi muốn các bạn tìm ra những nguyên lý về SQL chìm đằng sau những những giải pháp đó.
Có thể khi là lần đầu tiên chạm đến SQL qua vị từ hay tập hợp thì chắc hẳn mọi người sẽ có ấn tượng kì diệu. Chúng ta vẫn chưa thể hiểu rõ những khái niệm mới này (từ khi chúng ta sinh ra thì cũng mới chỉ có 100 năm)và cũng chưa thể sử dụng một cách thuần thục những thứ này. Chính vì vậy việc không học một cách cơ bản và sâu về vị từ hay tập hợp thì đó chính là nguyên nhân dẫn đến sự thiếu hiểu biết của chúng ta. Nhưng mà, việc sử dụng thành thạo 2 khái niệm này chính là điểm chính trong sự trưởng thành trong SQL.
Tiếp theo đây chính là những điểm chính trong lần này.
- Cách sử dụng dữ liệu trong SQL có 2 con đường.
- Đầu tiên là phương pháp nhìn tập hợp không để ý đến thứ tự.
- Thứ hai là phương pháp nhìn theo thứ tự tập hợp. Phương châm cơ bản của những lúc này là,
- Đầu tiên tạo một kết hợp điểm đầu và điểm cuối bằng tự kết hợp
- Tiếp theo là tạo mối quan hệ cần thành lập giữa những thành tố của trong nội bộ bằng subquery.
- Khi muốn ghi câu toàn xưng bằng SQL thì chúng ta cần chuyển thành câu phủ định của điều kiện tồn tại và sử dụng vị từ NOT EXISTS. ĐÂy chính là vì SQL chỉ thực hiện lượng hoá tồn tại trong luận lý vị từ.
Đối với những người muốn biết sâu hơn về phương pháp sử dụng thứ tự tập hợp hay dãy số trong SQL thì có thể tham khảo những tài liệu dưới đây
-
Joe Celko "プログラマのためのSQL 第2版" Về cách sử dụng dãy số trong SQL thì nhất định hãy đọc Chương 24. Những vấn đề trong chương này ở đây thì có mượn ở đây rất nhiều.
-
Joe Celko "SQLパズル 第2版" Về cách sử dụng sequence view để tìm lỗ khuyết có thể tham khảo trong Câu 57 Tìm lỗ khuyết - Phiên bản 1. Celko giả định một trong 2 bảng có giá trị trùng nhau nào hay không và sử dụng EXCEPT ALL để hướng tốt cho perfomance. Đây là một cách làm khá ưu tú nhưng hiện nay vẫn chưa có kĩ sư DB nào support nên tại đây chúng ta chỉ đơn giản sử dụng EXCEPT. Để sử dụng EXCEPT ALL thì với tình trạng hiện tại chúng ta chỉ có thể thực hiện tại DB2 và PostgreSQL
All rights reserved
