1-7 Phép toán tập hợp trong SQL
Bài đăng này đã không được cập nhật trong 4 năm
1-7 Phép toán tập hợp trong SQL
SQL và luận tập hợp SQL là ngôn ngữ lấy luận tập hợp là một trong những cơ bản. Cho đến nay thì những tính năng của SQL vẫn chưa được sử dụng một cách đầy đủ trong những phép toán tập hợp. Tuy nhiên trong những năm gần đây thì cuối cùng SQL đã tập hợp đủ những tính năng của phép toán tập hợp cơ bản và có khả năng ứng dụng một cách đúng cách. Chương này sẽ giới thiệu những technique sử dụng phép toán tập hợp của SQL và giải thích cách nghĩ trong bối cảnh đó.
Mở đầu
SQL là ngôn ngữ được định nghĩa từ luận tập hợp, đây cũng là một chủ đề được nêu lên trong cuốn sách này. Chính vì vậy mà SQL được gọi là ngôn ngữ hướng tập hợp rồi lần đầu tiên tôi thấy sức mạnh nhìn từ quan điểm tập hợp. Tuy nhiên, trên thực tế thì SQL vẫn bị làm ngơ về mặt này.
Về bối cảnh này thì đó cũng là một phần trách nhiệm của SQL. Vì trong một thời gian ngắn trước đây thì SQL không được trang bị những phép toán tập hợp cơ bản được học cho đến tầm trung học phổ thông. Tổng (UNION) được trang bị từ SQL-86 cổ nhưng phép giao (INTERSECT) hay hiệu (EXCEPT) thì mới được cho vào SQL-92 mới đây rồi phép chia (DIVIDE BY) vẫn chưa được cho vào thông thường hóa thì vấn đề này cũng đã được nêu ở những chương trước. Vậy nên có thể nói lý do cũng là do SQL chưa được hoàn thiện đầy đủ.
Tuy nhiên, đối với hiện tại thì những phép tính cơ bản đã được trang bị đầy đủ trong SQL, rồi ta cũng có thể kết hợp những thứ đó, tiến hàng thực thi và cuối cùng cũng có khả năng ứng dụng một cách đúng nghĩa. Chương này sẽ giới thiệu những SQL tiện lợi sử dụng phép toán tập hợp, giải thích về cách suy nghĩ của nó và sẽ tiếp cận bản chất của SQL bằng giác độ khác cho đến nay.
Nhập môn - Những điểm chú ý liên quan đến phép toán tập hợp
Phép toán tập hợp trong SQL cũng ý hệt như tên của nó, sẽ là phép toán để lấy được tập hợp, và trong vài trường hợp sẽ là lấy phép toán mà argument là view hay bảng để thực thi. Về cơ bản thì giống như đại số tổ hợp được học trong trung học cơ sở và phổ thông nên chắc mọi người chắc sẽ dễ hiểu trực quan hơn nhưng trong SQL thì cần chú ý một vài đặc trưng đặc biệt.
Chú ý 1: Tập hợp được dùng trong SQL có thể sử dụng tập hợp có dòng trùng nên để đối ứng với cái đó thì có option ALL
Thông thường nếu nói về tập hợp bằng luận tập hợp thì sẽ không chấp nhận những thành tố trùng. Vậy nên, tập hợp {1,1,2,3,3,3} sẽ được nhìn giống ý hệt như tập hợp {1,2,3}. Tuy nhiên bảng trong cơ sở dữ liệu quan hệ thì có thể chấp nhận được dòng trùng (multiset, bag).
Vì vậy nên trong phép toán tập hợp của SQL thì được chuẩn bị 2 phiên bản là phiên bản chấp nhận dòng trùng và phiên bản không chấp nhận dòng trùng. Bình thường nếu sử dụng UNION và INTERSECT mà không thêm điều kiện gì thì những dòng trùng sẽ bị xóa đi. Nếu trong trường hợp muốn để lại dòng trùng thì chúng ta thêm ALL như UNION ALL. Vừa đúng ngược lại hoàn toàn với cách dùng DISTINCT vào câu lệnh SELECT. Tuy nhiên không hiểu sao nhưng cách viết như UNION DISTINCT thì không được chấp nhận.
Trong 2 cách dùng trên thì tồn tại thêm 1 điểm khác ngoài kết quả của phép tính. Đó chính là để xóa đi những dòng trùng lặp trong phép toán tổ hợp thì sẽ phát sinh sắp xếp dữ liệu ẩn nhưng nếu thêm ALL vào thì sắp xếp dữ liệu không diễn ra và hướng perfomance. Đây là một perfomance tunning hiệu quả nên đối với những trường hợp không cần để ý đến dòng trùng hoặc những trường hợp chắc chắn không xuất hiện những dòng trùng thì thêm ALL vào sẽ tốt hơn.
Chú ý 2: Trong thứ tự của phép tính thì có những thứ tự ưu tiên
Trong SQL thông thường thì trong UNION và EXCEPT thì INTERSECT được thực hiện trước hơn hết. Vậy nên ví dụ trong trường hợp có UNION và INTERSECT mà muốn thực hiện UNION trước thì chúng ta phải chỉ định cho vào ngoặc một cách rõ ràng. (Ví dụ về điểm chú ý này sẽ được nêu trong phần luyện tập)
Chú ý 3: Tùy từng DBMS mà tình trạng thực thi phép toán tổ hợp sẽ khác nhau
Cũng như đã nêu lên từ trước thì trong SQL đời đầu thì những chuẩn bị để thực hiện phép toán tập hợp vẫn bị làm lười. Chính vù vậy nên tình trạng thực thi ở từng DBMC không được thống nhất.SQL Server từ bản 2005 đã hộ trợ INTERSECT và EXCEPT, nhưng MySQL vẫn chưa có cả 2 chức năng đó. Mặt khác, giống như trong Oracle có những DBMS có những biệt danh như MINUS thay cho EXCEPT. Mặc dù đây là một điểm khá bất tiện nhưng những người dùng Oracle thì hãy hãy thay tất cả EXCEPT bằng MINUS.
Chú ý 4: Phép chia vẫn chưa được định nghĩa một cách thông thường, chính thống
Trong 4 phép tính cơ bản thì có tổng (UNION), tích (CROSS JOIN), hiệu (EXCEPT) được định nghĩa. Tuy nhiên, còn một thứ nữa là thương (DIVIDE BY) vẫn chưa được thông thường hóa. Vậy nên khi sử dụng phép chia thì cần thiết phải tạo một truy vấn.
1. So sánh giữa bảng với nhau - kiểm tra tính tương đẳng của tập hợp: phần cơ bản
Trong những trường hợp di chuyển môi trường DB sẽ có những trường hợp muốn so sách dữ liệu sau khi back-up có giống như dữ liệu ban đầu không. Ở đây, nói là "bằng" có nghĩa là số dòng hay số cột rồi nội dung dữ liệu là giống nhau, có nghĩa là "giống nhau như cách nói của một tập hợp". Ví dụ chúng ta có 2 bảng là tbl_A và tbl_B chỉ khác nhau về tên gọi nhưng về mặt tập hợp thì giống y hệt nhau như sau.
tbl_A
| key | col_1 | col_2 | col_3 |
|---|---|---|---|
| A | 2 | 3 | 4 |
| B | 0 | 7 | 9 |
| C | 5 | 1 | 6 |
tbl_B
| key | col_1 | col_2 | col_3 |
|---|---|---|---|
| A | 2 | 3 | 4 |
| B | 0 | 7 | 9 |
| C | 5 | 1 | 6 |
Vậy có phương pháp nào để biết được bảng này nếu giống nhau thì cho kết quả là giống nhau, nếu không giống nhau thì cho kết quả là không giống nhau không? Để giải thích một cách dễ hiểu thì sự so sánh các file có hình như như làm nó diễn ra với các bảng. Theo như ví dụ, ở một mức độ nào đó về số dòng thì kiểm tra bằng mắt cũng có thể không sai, nhưng với qui mô hàng trăm dòng, hàng ngàn dòng thì chuyện kiểm tra bằng mắt chắc chắn sẽ không thực hiện được.
Về trường hợp này chúng ta có 2 con đường để thực hiện. Đầu tiên chúng ta sẽ xem từ cách đơn giản dùng UNION. Đầu tiên chúng ta sẽ giả định đã kiểm tra xong rằng 2 bảng này đã giống nhau về số dòng.(Nếu số dòng không giống nhau thì từ đó chương trình sẽ kết thúc).
Trong trường hợp này thì cả 2 bảng đều có 3 dòng. Nếu kết quả của truy vấn dưới đây là 3 thì chúng ta có thể hiểu 2 bảng này là giống nhau nhưng người lại nếu kết quả lớn hơn 3 thì hai bảng này là khác nhau.
Kết quả của truy vấn này nếu số dòng của tbl_A và tbl_B đồng nhất với nhau thì hai bảng là giống nhau.
SELECT COUNT(*) AS row_cnt
FROM ( SELECT *
FROM tbl_A
UNION
SELECT *
FROM tbl_B ) TMP;
Kết quả
row_cnt
---------
3
Tại sao lại có thể nói như vậy? Các bạn hãy nhớ lại chú ý 1 ở phần nhập môn. Phép toán tập hợp trong SQL nếu không gắn thêm ALL thì sẽ xóa đi những dòng trùng. Chính vì vậy nên nếu tbl_A và tbl_B giống nhau thì dòng trùng bị xóa đi, 2 bảng hoàn toàn nhập lại với nhau thành 1.
Tất nhiên chỉ cần một dòng khác nhau thôi thì kết quả sẽ là 4. Dòng khác nhau sau khi qua giai đoạn xóa những dòng trùng thì không được nhất thể hóa mà vẫn còn dư ra ngoài.
Ví dụ bảng B khác và kết quả trở thành 4
tbl_A
| key | col_1 | col_2 | col_3 |
|---|---|---|---|
| A | 2 | 3 | 4 |
| B | 0 | 7 | 9 |
| C | 5 | 1 | 6 |
tbl_B
| key | col_1 | col_2 | col_3 |
|---|---|---|---|
| A | 2 | 3 | 4 |
| B | 0 | 7 | 8 |
| C | 5 | 1 | 6 |
Truy vấn này kể cả là bảng có chứa NULL thì cũng được chạy đúng, và điều tiện lợi là nó không chỉ định dạng dữ liệu là số hay chữ. Chỉ dùng UNION thôi nên ngay trong MySQL cũng có thể sử dụng được. Tất nhiên, chúng ta cũng có thể so sánh dãy là một bộ phận của bảng hoặc một bộ phận của dãy thôi cũng được. Trong trường hợp đó thì chúng ta phải chỉ định tên dãy muốn do sánh, thiết lập điều kiện ở câu lệnh WHERE là được.
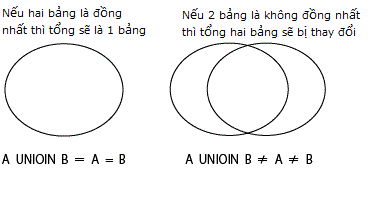
Như ví dụ trên ta có thể nhìn thấy rõ, UNION của SQL đối với bảng S là
S UNION S = S
Đây có nghĩa là UNION mang một tính chất rất quan trọng. Tính chất này trong toán học được gọi là khái niệm kết quả không thay đổi khi thực hiện 1 lần hay nhiều lần cũng vẫn vậy(idempotency). Vốn đây là khái niệm được sử dụng trong đại số trừu tượng, nó có một vài ý nghĩa khác nhau nhưng nói về nghĩa được sử dụng trong trường hợp này thì nó có ý nghĩa là đối với S nhập vào trong phép toán nhị phân thì S x S = S. UNION được dùng với ý nghĩa như thế này.
Trong lĩnh vực lập trình thì chúng ta mở rộng trường nghĩa này ra thì cũng có thể dùng với ý nghĩa "kết quả sau khi chạy nhiều lần với kết quả trong trường hợp chạy một lần là giống nhau". Ví dụ như một ví dụ gần với ta sẽ là head file của ngôn ngữ C được thiết kế mang tính impodency. Ta include một file bao nhiêu lần thì kết quả cũng không thay đổi so với trường hợp iclude một lần. Cùng với ý nghĩa đó, thì GET trong HTTP cũng impodency. Một yêu cầu được phát hành lặp đi lặp lại cũng được thực hành một cách an toàn. Mặt khác, tính chất này đặc biệt với user interface thì sẽ có một trọng trách rất quan trọng. Cơ bản của việc thiết kế giao diện an toàn đó chính là có nhấn một nút bao lần đi chăng nữa thì cũng giống như nhấn nút đó 1 lần.
Trong trường hợp phép toán tập hợp là UNION thì nếu nhìn [S UNION S] như một đơn vị xử lý thì bao nhiêu lần thực hiện xử lý đó thì cũng ra được kết quả không thay đổi. Cái này chúng ta cũng gọi là impodency. Như vậy chúng ta cũng có thể so sánh xem 3 hay nhiều bảng có giống nhau hay không.
S UNION S UNION S UNION S .... UNION S = S
Một điểm cần chú ý ở đây chính là nếu ta lặp đi lặp lại phép toán UNION ALL thì mỗi lần như vậy kết quả sẽ thay đổi nên sẽ không thành tính impodency. Lý do giống vậy, đối với những bảng có dòng trùng nhau thì UNION sẽ mất đi tính impodency. Có nghĩa là tính năng mạnh và đẹp này tồn tại chỉ là câu chuyện của thế giới tập hợp, đối với thế giới tập hợp có nhiều dòng trùng nhau thì không sử dụng được.
Vậy thì trước khi tiến lên trước thì chúng ta có một câu hỏi. Thực ra, trong phép toán tổ hợp thì ngoài UNION ra còn có một thứ nữa cũng có tính impodency. Vậy nó là gì?
2. So sánh giữa bảng với nhau - kiểm tra tính tương đẳng của tập hợp: phần ứng dụng
Với giải pháp trước thì khi so sánh giữa 2 bảng thì chúng ta đã cần phải điều tra trước được số dòng của 2 bảng chuẩn bị trước. Mặc dù cái này cũng không tốn quá nhiều thời gian và công sức nhưng chúng ta hãy cùng suy nghĩ phương pháp cải thiện để có thể check tính đồng nhất của bảng mà không cần sự chuẩn bị trước đó. Về ví dụ thì chúng ta dùng luôn tbl_A và tbl_B có từ phần 1.
Trong luận tập hợp, về cơ bản về công thức điều tra tính giống nhau của tập hợp thì về công thức thì có 2 công thức sau được biết đến nhiều nhất.
- (A ⊆ B ) かつ (A ⊇ B) ⇒ (A = B)
- (A ∪ B ) = (A ∩ B) ⇒ (A = B)
Phương pháp số 1 là phương pháp dùng quan hệ bao hàm để điều tra tính đồng nhất của tập hợp. Có nghĩa là nếu B thuộc A cùng với A thuộc B thì A = B. Chúng ta cũng có thể dùng phương pháp này để điều tra nhưng sẽ hơi tốn công.(Về phương pháp này sẽ có ví dụ chạm đến trong phần sau)
Mặt khác, về một phía thì phương pháp số 2 là công thức tra tính đồng nhất dựa trên phép giao và phép cộng của tập hợp. Nếu chúng ta dịch ra bằng ngôn ngữ SQL thì đó chính là [A UNION B = A INTERSECT B thì A=B]. Chúng ta có thể viết dễ hơn theo cách này.
Nếu A và B là hai tập hợp giống nhau thì [A UNION B = A = B]. Và thực ra ở INTERSECT cũng vậy, A INTERSECT B = A = B được thành lập. Đúng vậy, ngoài UNION thì còn một phép tính nữa cũng có tính impodency đó chính là INTERSECT.
Ngược lại, nếu A khác B thì kết quả của UNION và INTERSECT sẽ khác nhau. Chắc chắn kết quả của UNION sẽ lớn hơn. Đầu tiên chúng ta tưởng tượng hình ảnh nếu tập hợp A và B khác nhau với hình ảnh như sau thì sẽ dễ hiểu hơn.
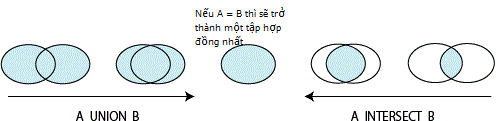
Vấn đề còn lại là chúng ta làm thế nào để so sánh kết quả của UNION và INTERSECT. Bây giờ chúng ta hiểu là đã có,
( A INTERSECT B ) ⊆ ( A UNION B )
Vậy thì chúng ta tiếp theo chỉ cần phán định xem (A UNION B) EXCEPT (A INTERSECT B) có ra kết quả rỗng không là được. Nếu A = B thì đó sẽ ra kết quả rỗng còn nếu A khác B thì chắc chắn sẽ còn sót trên 1 dòng.
--Truy vấn điều tra nếu hai tập hợp bằng nhau thì sẽ trả lại kết quả bằng, còn không bằng nhau thì sẽ trả lại kết quả khác.
SELECT DISTINCT CASE WHEN COUNT(*) = 0
THEN 'Bằng'
ELSE 'Khác' END AS result
FROM ((SELECT * FROM tbl_A
UNION
SELECT * FROM tbl_B)
EXCEPT
(SELECT * FROM tbl_A
INTERSECT
SELECT * FROM tbl_B)) TMP;
Với truy vấn này thì tất nhiên, chúng ta không cần biết đó là dãy chữ hay dãy số, kể cả bảng NULL cũng có thể sử dụng được thì điểm mạnh này vẫn được kèm thêm, cùng với điểm lợi hơn là mất chuẩn bị là điều tra số dòng trước nên là một cách rất ưu việt. Tuy nhiên phần chức năng cao thì sẽ phát sinh khuyết điểm. Phép toán tập hợp phát sinh 3 lần sort nên sẽ làm giảm perfomance. Vậy nên trước khi sử dụng thì mọi người hãy suy xét ưu điểm và khuyết điểm trước nhé.
Bây giờ chúng ta đã biết được rằng sự khác hay giống nhau của 2 bảng nhưng lần này chúng ta cùng hiển thị cụ thể hơn dòng nào khác của hai bảng. Chúng ta chỉ cần tưởng tượng chúng ta thực hiện command diff với file như làm đối với bảng này là được. Cái này thì chỉ cần chọn tập hợp tổng loại trừ là được.
--diff của bảng
(SELECT * FROM tbl_A
EXCEPT
SELECT * FROM tbl_B)
UNION ALL
(SELECT * FROM tbl_B
EXCEPT
SELECT * FROM tbl_A);
Kết quả
key col_1 col_2 col_3
----- ------- ------- -------
B 0 7 9
B 0 7 8
Giữa A-B và B-A chắc chắn sẽ không tồn tại phần giao nên khi merge hai bộ phận này thì chúng ta dùng UNION ALL cũng không vấn đề gì cả. Truy vấn này trong trường hợp một bảng này là một bộ phận trong bảng kia cũng có thể thực thi đúng. (Trong trường hợp đó thì 1 trong A-B hay B-A sẽ là tập hợp trống). Dùng dấu ngoặc để chỉ định thứ tự thực hiện phép tính nên nếu bỏ ra thì chưa chắc chúng ta đã có được kết quả đúng.
3. Hiển thị phép chia quan hệ bằng tập hợp giao
Cũng như đã nêu trong phần mở đầu thì trong SQL chưa có một dấu phép tính cụ thể nào cho phép chia. Chính vì vậy thì chúng ta cần phải viết truy vấn trước mới có thể thực hiện được phép chia. Có rất nhiều phương pháp nhưng có những cách tiêu biểu như.
- Đưa NOT EXISTS thành khung lồng
- Sử dụng 1 đối 1 trong câu lệnh HAVING
- Biểu hiện phép chia bằng phép trừ
Lần này phần tiếp theo đây sẽ giới thiệu về phương pháp thứ 3.
Phép trừ trong đại số tổ hợp đó là phép tính của tập hợp giao. Trong lúc giới thiệu phương pháp viết tập hợp giao bằng OUTER JOIN trong phần "Cách sử dụng OUTER JOIN" thì chúng tôi đã ra bài tập để mọi người suy nghĩ về phương pháp, thì đây chính là giải thích của phương pháp đó.
Dữ liệu ví dụ sử dụng 2 bảng quản lý thông tin kĩ thuật của nhân viên trong công ty.
Skills
| skill |
|---|
| Oracle |
| UNIX |
| Java |
EmpSkills
| emp | skill |
|---|---|
| Aida | Oracle |
| Aida | UNIX |
| Aida | Java |
| Aida | C# |
| Kanzaki | Oracle |
| Kanzaki | UNIX |
| Kanzaki | Java |
| Hirai | UNIX |
| Hirai | Oracle |
| Hirai | PHP |
| Hirai | Perl |
| Hirai | C++ |
| Wakatabe | Perl |
| Torai | Oracle |
Vấn đề là từ bảng EmpSkills tìm những nhân viên có tất cả những kĩ năng có trong bảng Skills. Tức là câu trả lời là Aida và Kanzaki. Hirai thì hơi tiếc vì không sử dụng được Java nên bị loại.
Phương pháp giới thiệu lần này có thể sẽ dễ hiểu hơn cách dùng câu lệnh HAVING. Nó xuất phát từ ý tưởng rất gần với kiểu thủ tục. Đầu tiên chúng ta sẽ nhìn từ câu trả lời.
--Phép chia quan hệ bằng tập hợp giao (Phép chia có số dư)
SELECT DISTINCT emp
FROM EmpSkills ES1
WHERE NOT EXISTS
(SELECT skill
FROM Skills
EXCEPT
SELECT skill
FROM EmpSkills ES2
WHERE ES1.emp = ES2.emp);
Kết quả
Aida
Kanzaki
Điểm nhấn ở đây là subquery tương quan và phép tính EXCEPT. Subquery tương quan gắn quan hệ với bảng EmpSkills nhưng đây là để tiến hành phép trừ đối với từng nhân viên. Kĩ năng của từng nhân viên được trừ từ tập hợp những kĩ năng yêu cầu, nếu kết quả là rỗng thì có nghĩa tằng có tất cả những gì yêu cầu, còn nếu còn một dòng thì đó là thiếu kĩ năng đó.
Ví dụ đối với anh Aida
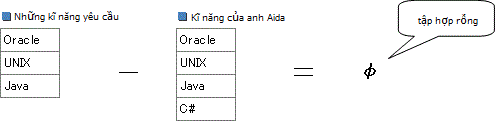
Vì kết quả là tập hợp rỗng nên anh được chọn. Mặt khác ví dụ trường hợp của anh Hirai.
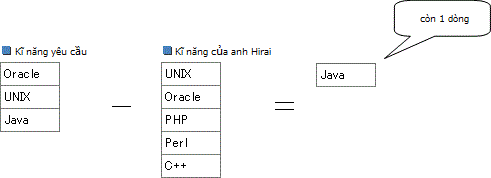
Bên cạnh còn sót lại một dòng "Java" nên không có trong kết quả. Nói một cách khác là so với phép chia thì ta chuyển thành phép trừ đơn giản. Đây là một phương pháp rất sắc khi được sử dụng.
Xem về phần logic thì mọi người có phát hiện ra điều gì không? Thực ra truy vấn này đã ghi giống như xử lý control break của ngôn ngữ thủ tục. Để thử thì mọi người hãy nghĩ bảng này là một file rồi cho từng dòng vào vòng lặp để xử lý. Với mỗi một nhân viên thì chúng ta thực hiện phép trừ giữa những kĩ năng hiện có nếu hết kĩ năng rồi thì chúng ta chuyển sang nhân viên khác và thực hiện vòng lặp tương tự.
Subquery tương quan cũng như hay được biết đến, nó được đưa vào sử dụng thay cho vòng lặp trong SQL. Ý nghĩa mà đã nói trước phần trên là phương pháp này có thể dễ hiểu đó chính là vì lý do này.
4. Tìm những tập hợp bộ phận giống nhau
Bài tập này từ khi được Date đưa ra bào năm 1993 thì nó đã trở thành một mảnh ghép rất nổi tiếng. Tại ví dụ ta sẽ sử dụng bảng hiển thị mối quan hệ giữa sản phẩm và người cung cấp sản phẩm.
SupParts
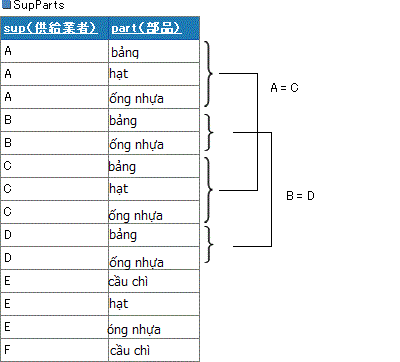
Vấn đề cần tính toán ở đây là những cặp nhà cung cấp mà cung cấp những mặt hàng kể cả về số lượng hay tên hàng cũng giống hệt nhau. Với ví dụ này thì đó chính là cặp A-C và B-D. A và E mặc dù số lượng cung cấp đều là 3 nhưng vì loại mặt hàng khác nhau nên không là đối tượng của nhau, F thì cả về số lượng lẫn mặt hàng không giống như bất cứ nhà cung cấp nào nên nằm ngoài đề bài luôn.
Nhìn qua thì đây có vẻ là một vấn đề dễ, nhưng tại sao ta gọi đây là puzzle thì đó chính là trong SQL thì không tồn tại những từ lệnh để test tính bằng nhau hay quan hệ bao hàm. IN chỉ là để kiểm tra có bao gồm thành tố đó trong tập hợp không thôi, tức là ∈ chứ không phải điều tra tập hợp bộ phận ⊆. Mặt khác, trong cơ sở dữ liệu quan hệ mà IBM tạo dựng thử số 1 "System R" có một lệnh để điều tra về quan hệ bao của tập hợp. Tuy nhiên, cuối cùng vì lý do về perfomance nên nó bị xoá đi và bây giờ vẫn chưa thấy được khôi phục lại.
Vấn đề này với điểm tiến hành so sánh giữa những tập hợp với nhau nên khá giống với phép chia quan hệ được nêu ra ở câu trước. Tuy nhiên, đối với phép chia thì một bên đối tượng được cố định, còn lần này thìhợp tập hợp không cố định và để test tất cả bộ phận là sự kết hợp của những tập hợp với nhau nên đã trở thành một vấn đề cao hơn một bậc.
Đầu tiên, chúng ta thử kết hợp những nhà cung cấp với nhau. Cái này chúng ta có thể tạo ra bằng liên kết bất đẳng thức. Với phép tính tập hợp ở đây thì những dòng trùng sẽ được xoá đi một cách đơn giản.
--Tạo sự kết hợp giữa những nhà cung cấp
SELECT SP1.sup AS s1, SP2.sup AS s2
FROM SupParts SP1, SupParts SP2
WHERE SP1.sup < SP2.sup
GROUP BY SP1.sup, SP2.sup;
Kết quả
s1 s2
---- -----
A B
A C
A D
:
:
:
D E
E F
Tiếp theo, chúng ta sử dụng công thức sau đối với những cặp này, (A ⊆ B ) và (A ⊇ B) ⇒ (A = B) kết quả này cũng giống như chúng ta làm thoả mãn 2 điều kiện sau.
- Điều kiện 1. Cả hai nhà cung cấp đều cung cấp những sản phẩm giống nhau.
- Điều kiện 2. Số lượng sản phẩm là giống nhau.
Điều kiện 1 thì chúng ta chỉ cần có giao những bộ phận có trong tập hợp, còn điều kiện 2 thì chúng ta chỉ cần dùng COUNT là được.
SELECT SP1.sup AS s1, SP2.sup AS s2
FROM SupParts SP1, SupParts SP2
WHERE SP1.sup < SP2.sup --Tạo sự kết hợp giữa các nhà cung cấp
AND SP1.part = SP2.part --Điều kiện 1. Các bộ phận có chủng loại giống nhau
GROUP BY SP1.sup, SP2.sup
HAVING COUNT(*) = (SELECT COUNT(*) --Điều kiện 2. Số lượng bộ phận giống nhau.
FROM SupParts SP3
WHERE SP3.sup = SP1.sup)
AND COUNT(*) = (SELECT COUNT(*)
FROM SupParts SP4
WHERE SP4.sup = SP2.sup);
Kết quả
s1 s2
---- ----
A C
B D
Hai điều kiện của câu lệnh HAVING thì chúng ta cứ suy nghĩ như đó là phép chia quan hệ thì sẽ dễ hiểu hơn. Theo như thế này thì thành tố của tập hợp A và B được bảo đảm không thừa không thiếu mà thống nhất với nhau. Và hơn nữa, điều kiện 1 đã bảo đảm những thành tố đó đều có chủng loại giống nhau.
Về puzzle này thì người ta đã có những cách giải quyết khác nhau, nhưng cách sử dụng phép chia như ở trên là một cách rất đặc trưng sử dụng đặc tính hướng tập hợp của SQL nhất. Tại SQL thì khi so sánh 2 tập hợp thì không phải chúng ta so sánh theo đơn vị dòng có trong tập hợp đó mà ít nhất thì chúng ta nên hiểu điểm mình sẽ so sánh cả tập hợp đó.
Và cuối cùng thì chúng ta cùng nói một câu chuyện ngoài lề. Lúc trước tôi cũng đã nói CONTAINS là một từ lệnh yểu mệnh nhưng nếu chúng ta có thể sử dụng được thì sẽ được viết với cấu trúc như câu lệnh dưới đây.
SELECT 'A CONTAINS B'
FROM SupParts
WHERE (SELECT part
FROM SupParts
WHERE sup = 'A')
CONTAINS
(SELECT part
FROM SupParts
WHERE sup = 'B')
Về ý nghĩa thì đó chính là tất cả những bộ phận mà nhà cung cấp B sử dụng thì cũng được nhà cung cấp A sử dụng. Đối với dữ liệu trên thì nó sẽ trả lại kết quả 'A CONTAINS C'. Đây đúng là một thuật rất tiện lợi đúng không? Nếu là bây giờ thì chắc vấn đề về perfomance sẽ được giải quyết và một tương lai gần nào đó nó sẽ được khôi phục và đưa vào sử dụng cũng nên.
5. Truy vấn nhanh chóng xoá đi những dòng trùng
Về phương pháp ứng dụng phép toán quan hệ thì chúng ta cũng biết rằng cuối cùng những dòng trùng sẽ bị xoá đi. Đây là vấn đề đã được nêu ra trong chương "Cách sử dụng tự liên kết". Lần này một lần nữa chúng ta có sự xuất hiện đáng swoj của một bảng không có key chính.
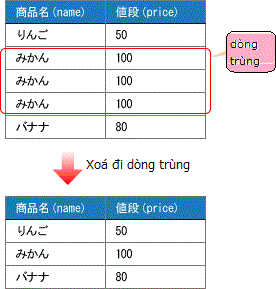
Phương pháp được giới thiệu từ trước thì chúng ta chỉ đơn giản dùng subquery tương quan.
--Xoá đi dòng trùng: Sử dụng subquery tương quan
DELETE FROM Products
WHERE rowid < ( SELECT MAX(P2.rowid)
FROM Products P2
WHERE Products.name = P2. name
AND Products.price = P2.price ) ;
Phương pháp này không tồi nhưng nó gặp một điểm không tốt đó chính là về perfomance.(DELETE là một xử lý tốn thời gian). Tại đây thì chúng ta cùng suy nghĩ phương pháp thực hiện cùng một sử lý mà không dùng subquery tương quan.
Về cách suy nghĩ của truy vấn trên đó là lúc thu thập sau khi thu thập những kết hợp của tên và giá thì chúng ta tính rowid lớn nhất và xoá đi những dòng còn lại. Dòng là đối tượng xoá để yêu cầu trực tiếp thì khó nên thì chúng ta có cách suy nghĩ đầu tiên tìm ra những dòng còn lại trước sau đó lấy tất cả để trừ đi, hay còn gọi là tập hợp phụ. Trogn phiên bản dùng subquery tương quan thì chúng ta tiến hành xử lý đối với từng cặp kết hợp tên và giá. Lần này, chúng ta sẽ yêu cầu tất cả trong subquery những rowid là đối tượng xoá.
Chúng ta coi như có những dòng rowid như dưới đây.
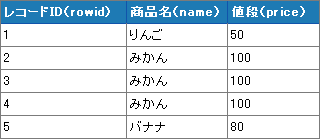
Cũng giống như chúng ta lấy một dòng rowid muốn để lại bằng hàm số cực trị. Điểm chính ở đây chính là chúng ta thực hiện phép trừ toàn bộ tập hợp đối với bảng Products. Truy vấn đó sẽ được trả lời như dưới đây.
DELETE FROM Products
WHERE rowid IN ( SELECT rowid --rowid của tất cả
FROM Products
EXCEPT --Trừ
SELECT MAX(rowid) --rowid muốn để lại
FROM Products
GROUP BY name, price) ;
Subquery không tương quan sẽ trả lại kết quả là định số 2,3. Nếu tưởng tượng bằng hình ảnh thì ta có hình ảnh sau,

Nếu sử dụng EXCEPT thì chúng ta có thể thực hiện đơn giản được giải pháp sử dụng tập phụ đã nêu ra bên trên. Mặt khác chúng ta cũng có thể suy nghĩ đến phương pháp sử dụng NOT IN thay thế cho EXCEPT, thì code đó sẽ được viết như dưới đây.
DELETE FROM Products
WHERE rowid NOT IN ( SELECT MAX(rowid)
FROM Products
GROUP BY name, price);
Phương pháp nào có perfomance tốt hơn thì tuỳ vào qui mô của bảng cũng như so sánh giữa dòng xoá và dòng để thì kết quả sẽ thay đổi. Tuy nhiên, với dòng code trên đây thì chúng ta có lợi thế rằng lệnh sẽ được chạy mà không có EXCEPT.
Tuy nhiên đối với những chương trình có thể chạy được code ID như thế này thì chỉ có Oracle và PostgreSQL. Trong trường hợp PostgreSQL thì nó có tên là oid. Trường hợp đó thì mọi người đừng quên gắn option WITH OIDS khi CREATE TABLE nhé.
Kết luận
Chương này đã giới thiệu về cách dùng phép toán tập hợp. Cũng như đã nói ở phần đầu thì vì sự chuẩn bị về thuật này bị chậm nên không tính đến sự ứng dụng rất phong phú thì không được biết đến nhiều lắm. Mọi người nhất định hãy suy nghĩ những SQL thú vị hơn nữa nhé.
Dưới đây sẽ là những điểm chính trong chương này.
- Trong SQL thì sự chuẩn bị về tính năng phép toán tập hợp bị trễ. Trong tình trạng thực thi trong DB thì cũng có những điều ngoài ý muốn xảy ra nên khi sử dụng hãy chú ý kĩ.
- Phép tính tập hợp nếu không thêm option ALL thì sẽ tiến hành xoá những dòng trùng. Trong trường hợp đó thì trong nguồn cũng sẽ được diễn ra nên về mặt perfomance sẽ không tốt.
- UNION và INTERSECT mang một tính chất quan trọng đó là impodency, còn EXCEPT thì không vậy.
- Phép chia không phải là một phép tính tập hợp thông dụng, được bình thường hoá nên khi muốn sử dụng thì chúng ta phải tự tạo
- Trong phương pháp điều tra sự giống nhau của tập hợp thì chúng ta có 2 con đường để dùng đó là sử dụng tính impodency và song ánh.
- Nếu sử dụng EXCEPT thì có thể biểu hiện tập hợp phụ một cách dễ dàng.
Tài liệu tham khảo.
- 『プログラマのためのSQL 第2版』 Joe Celko 著、ピアソンエデュケーション、2001年4月
Về xoá những dòng trùng là 9.1.4, về phép chia quan hệ sử dụng phép tính tập hợp giao 19.2.6. Celko đang sử dụng IS NULL nhưng trong nhiều thực hiện thì trong nhiều trường hợp sub query sử dụng số phức thì nhiều khi sẽ trở thành error. Trong SQL thông thường thì có thể lấy argument là list giá trị NULL nên không có gì sai cả nhưng nó là chức năng không được sử dụng một cách rộng rãi.
- 『SQLパズル 第2版』 Joe Celko 著、ミック 訳、翔泳社、2007年11月
Về truy vấn phát hiện những tập hợp giống nhau thì tham khảo Chương 27 Phát hiện bảng giống nhau. Chương này cũng viết nguồn của episode của System R.
- 『Relational Database Writings 1991-1994』 C. J. Date 著、Addison-Wesley Pub、1995年
Về tính impodency của UNION và INTERSECT thì sẽ có trong 「Expression Transformation (Part 1 of 2)」, về sự xuất hiện của puzzle về phát hiện tập hợp giống nhau thì chúng ta có thể tham khảo ở 「A Matter of Integrity (Part 2 of 3)」
All rights reserved
