1-6 So sánh giữa dòng với dòng bằng subquery tương quan
Bài đăng này đã không được cập nhật trong 4 năm
1-6 So sánh giữa dòng với dòng bằng subquery tương quan
>So sánh giữa các dòng trong SQL
Chúng ta có thể dễ dàng so sánh giữa các dãy trong cùng một dòng bằng SQL. Tuy nhiên chúng ta lấy đối tượng so sánh là các dòng khác nhau thì điều đó không còn đơn giản nữa. Tuy nhiên thế có nghĩa rằng không thể làm so sánh giữa các dòng bằng SQL được. Chương này sẽ giới thiệu ví dụ ứng dụng so sánh giữa các dòng sử dụng subquery tương quan.
Mở đầu
Trong SQL thì chúng ta có thể dễ dàng so sánh các dãy trong cùng một dòng. Vì chúng ta chỉ cần viết sử dụng câu lệnh WHERE như "col_1 = col_2" là được. Tuy nhiên việc so sánh giữa các dãy trong các dòng khác nhau thì không đơn giản như vậy. Nhưng không có nghĩa chúng ta không thể làm phép so sánh như vậy. Có thể cách tiếp cận sẽ hơi khác đối với những ngôn ngữ lập trình thủ tục khác nhưng chúng ta vẫn có thể ghi được xử lý như vậy bằng SQL.
Trong trường hợp so sánh giữa các dòng trong SQL thì thứ phát huy năng lực mạnh mẽ đó chính là subquery tương quan, đặc biệt là subquery kết hợp với tự tổ hợp đó chính là subquery tự tương quan. Trong chương này sẽ giới thiệu phương pháp ứng dụng của so sánh giữa các dòng sử dụng kĩ thuật này thông qua giải thích những ví dụ cụ thể.
Tăng trưởng, thoái lui, trạng thái duy trì
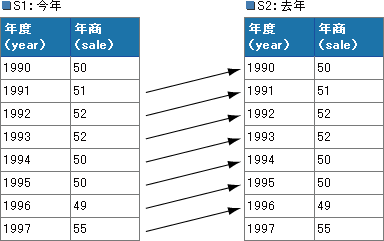
Nếu nói về trường hợp nghiệp vụ đại biểu cần thiết sự so sánh giữa các dòng này thì chúng ta có trường hợp tiến hành phân tích dãy thời gian sử dụng bảng ghi dữ liệu mang tính kinh tế. Ví dụ chúng ta có bảng như dưới đây ghi doanh thu theo năm của một công ty.
Sales
| year | sale |
|---|---|
| 1990 | 50 |
| 1991 | 51 |
| 1992 | 52 |
| 1993 | 52 |
| 1994 | 50 |
| 1995 | 50 |
| 1996 | 49 |
| 1997 | 55 |
Đồ thị biểu diễn
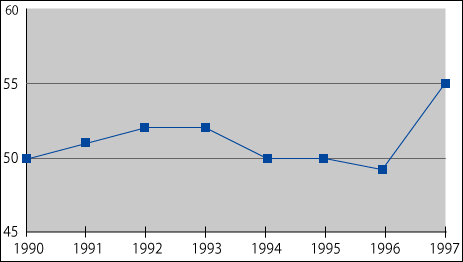
Chúng ta sẽ sử dụng dữ liệu này bằng SQL só sánh doanh thu so với năm trước tăng hay giảm hay không thay đổi. Lấy ví dụ chúng ta muốn thử với trường hợp không thay đổi. Nếu nhìn vào bảng thì chắc hẳn đây sẽ là năm 94 và 95. Nếu suy nghĩ theo những ngôn ngữ thủ tục thì ta sẽ có,
- Sắp xếp từng năm theo thứ tự tăng dần
- Cho vào vòng lặp và so sánh dòng sale của từng dòng so với dòng trước nó.
Với SQL truyền thống thì chúng ta không thể có suy nghĩ như thế này được. Ít nhất chúng ta cần thiết phải nghĩ nó theo hướng tập hợp. Chúng ta cùng tạo thêm một bảng khác ngoài Sales là tập hợp có thông tin "dòng năm trước".
--Yêu cầu năm có doanh thu giống năm trước: Sử dụng subquery tương quan.
SELECT year, sale
FROM Sales S1
WHERE sale = (SELECT sale
FROM Sales S2
WHERE S2.year = S1.year - 1)
ORDER BY year;
Kết quả
year sale
----- -----
1993 52
1995 50
Theo điều kiện trong subquery "S1.year = S2.year - 1" có nghĩa là lệch 1 dòng so với dòng làm đối tượng so sánh. Có nhiều trường hợp chúng ta có thể viết thay thế tự tổ hợp với subquery tương quan nên nếu viết theo tự tổ hợp thì truy vấn sẽ viết như sau,
--Yêu cầu năm có doanh thu giống năm trước: Sử dụng: Sử dụng tự tổ hợp.
SELECT S1.year, S1.sale
FROM Sales S1
Sales S2
WHERE S2.year = S1.year - 1
ORDER BY year;
Chúng ta cũng không thể nói perfomance của cái nào tốt hơn, tùy theo từng môi trường sẽ bị tri phối nên chúng ta có thể so sánh thử tại từng môi trường.
Tiếp theo đây, hãy ứng dụng cái này để so sánh giữa các năm là tăng trưởng, hay thoái lui, hay trong tình trạng duy trì.
Hiển thị bảng kết quả so sánh so với năm trước
--Yêu cầu kết quả tăng trưởng, thoái lui hay không tăng trưởng trong 1 lần: sử dụng subquery tương quan.
SELECT S1.year, S1.sale,
CASE WHEN sale =
(SELECT sale
FROM Sales S2
WHERE S2.year = S1.year - 1) THEN '→' --Đi ngang
WHEN sale >
(SELECT sale
FROM Sales S2
WHERE S2.year = S1.year - 1) THEN '↑' --Tăng trưởng
WHEN sale <
(SELECT sale
FROM Sales S2
WHERE S2.year = S1.year - 1) THEN '↓' --Thoái lui
ELSE '-' END AS var
FROM Sales S1
ORDER BY year;
Kết quả
year sale var
------ ------ -----
1990 50 ―
1991 51 ↑
1992 52 ↑
1993 52 →
1994 50 ↓
1995 50 →
1996 49 ↓
1997 55 ↑
Chúng ta có thể hay nhìn thấy những bảng di chuyển như thế này nhu các bảng xếp hạng tuần của phim, hay CD âm nhạc. Như những gì ta nhìn thấy, trogng subquery tương quan, câu lệnh SELECT so sánh năm trước và năm sau. Vì năm 90 không có dữ liệu trong S2 nên hiển thị kết quả "―".
Cái này tất nhiên cũng có thể viết thay thế lại bằng tự tổ hợp.
--Yêu cầu kết quả tăng trưởng, thoái lui hay không tăng trưởng trong 1 lần: sử dụng tự tổ hợp (kết quả của năm đầu không hiển thị)
SELECT S1.year, S1.sale,
CASE WHEN S1.sale = S2.sale THEN '→'
WHEN S1.sale > S2.sale THEN '↑'
WHEN S1.sale < S2.sale THEN '↓'
ELSE '-' END AS var
FROM Sales S1, Sales S2
WHERE S2.year = S1.year - 1
ORDER BY year;
Tuy nhiên bằng phương pháp này thì năm 90 không có năm trước bị xóa đi và kết quả bị giảm đi 1 dòng. Đối với kết quả thực tế thì đó không có vấn đề gì cả nhưng có thể có những trường hợp layout yêu cầu có cả kết quả đối với năm đầu tiên. Về cái này thì chúng ta sẽ suy nghĩ bằng vấn đề dưới đây.
Mặt khác, trong bảng trên thì chúng ta đã lấy thời gian là cột nhưng chúng ta có thể chuyển format để thời gian trở thành dòng được không? Như hình dưới đây,
| Năm | 1990 | 1991 | 1992 | 1993 | 1994 | 1995 | 1996 | 1997 |
|---|---|---|---|---|---|---|---|---|
| Xu hướng | - | ↑ | ↑ | → | ↓ | → | ↓ | ↑ |
Nếu hỏi là có thể hay không thì câu trả lời là có thể. Với cách làm thì chúng ta có thể làm như cách đã giới thiệu trong phần "Cách sử dụng OUTER JOIN". Tuy nhiên, cũng như đã viết trong phần trước, SQL không chuyên để chỉnh sửa format. Kết quả chỉnh sửa thì chúng ta sẽ để cho những ứng dụng hiển thị bảng và ngôn ngữ chuyên dụng có khả năng giới hạn làm.
Trường hợp khuyết kết quả trong dãy thời gian: so sánh với kết quả ngay trước đó
Trong ví dụ trước thì chúng ta đã có một bảng với kết quả đầy đủ, không khuyết cái nào nhưng chắc chắn có những công ty mà thông tin không đầy đủ, chỉ số của một số năm sẽ khuyết.
Sales2: Có khuyết
| year | sale |
|---|---|
| 1990 | 50 |
| 1992 | 50 |
| 1993 | 52 |
| 1994 | 55 |
| 1997 | 55 |
Như thế này thì chúng ta không thể để cài đặt là năm -1 được. Như vậy ta cần thiết phải để đối tượng so sánh là dòng ngay trước đó. Những trường hợp như thế này thì chúng ta cũng thử cùng suy nghĩ SQL đúng để so sánh năm 92 với 90 rồi 97 với 94.
Nhìn từ một năm nào đó thì năm trong quá khứ ngay đó phải thỏa mãn 2 điều kiện dưới đây:
- Là năm nhỏ hơn năm đang lấy.
- Trong những năm thỏa mãn điều kiện 1 thì đó phải là giá trị lớn nhất.
SQL để ghi lại những điều kiện này sẽ như dưới đây.
--Chọn năm có doanh số giống năm trước đó
SELECT year, sale
FROM Sales2 S1
WHERE sale =
(SELECT sale
FROM Sales2 S2
WHERE S2.year =
(SELECT MAX(year) --Điều kiện 2:Trong những năm thỏa mãn điều kiện 1 thì đó là giá trị lớn nhất
FROM Sales2 S3
WHERE S1.year > S3.year)) --Điều kiện 1: Là năm quá khứ
ORDER BY year;
Kết quả
year sale
----- ------
1992 50
1997 55
Nếu sử dụng tự tổ hợp thfi sẽ giảm 1 dòng so với subquery tương quan.
Lựa chọn năm có doanh thu giống với năm trước đó: Sử dụng tự tổ hợp
SELECT S2.year AS pre_year,
S1.year AS now_year
FROM Sales2 S1, Sales2 S2
WHERE S1.sale = S2.sale
AND S2.year = (SELECT MAX(year)
FROM Sales2 S3
WHERE S1.year > S3.year)
ORDER BY now_year;
Theo con đường này thì chúng ta có thể lấy được chênh lệch giá trị hiện tại đối với giá trị của năm trước.
--Tính giá trị chênh lệch so với năm trước: (1) không bao gồm kết quả thời điểm bắt đầu
SELECT S2.year AS pre_year,
S1.year AS now_year,
S2.sale AS pre_sale,
S1.sale AS now_sale,
S1.sale - S2.sale AS diff
FROM Sales2 S1, Sales2 S2
WHERE S2.year = (SELECT MAX(year)
FROM Sales2 S3
WHERE S1.year > S3.year)
ORDER BY now_year;
Kết quả
pre_year now_year pre_sale now_sale diff
---------- ---------- ---------- ---------- ------
1990 1992 50 50 0 --50 - 50 = 0
1992 1993 50 52 2 --52 - 50 = 2
1993 1994 52 55 3 --55 - 52 = 3
1994 1997 55 55 0 --55 - 55 = 0
Nhưng theo những gì nhìn thấy ở kết quả thì năm 90 không hiện kết quả. Đây là vì dữ liệu năm trước năm 90 không có nên theo tự tổ hợp thì dòng này sẽ bị xóa đi. Nếu muốn có cả kết quả của năm 90 thì chúng ta cần cùng OUTER JOIN.
--Tính giá trị chênh lệch so với năm trước: (2) Sử dụng OUTER JOIN, bao gồm cả kết quả ban đầu.
SELECT S2.year AS pre_year,
S1.year AS now_year,
S2.sale AS pre_sale,
S1.sale AS now_sale,
S1.sale - S2.sale AS diff
FROM Sales2 S1 LEFT OUTER JOIN Sales2 S2
ON S2.year = (SELECT MAX(year)
FROM Sales2 S3
WHERE S1.year > S3.year)
ORDER BY now_year;
Kết quả
pre_year now_year pre_sale now_sale diff
---------- ---------- ---------- ---------- -------
1990 50 --Hiển thị cả năm 90
1990 1992 50 50 0
1992 1993 50 52 2
1993 1994 52 55 3
1994 1997 55 55 0
Lấy master là bảng Sales2 và lấy OUTER JOIN thì chúng ta có thể làm hiện lên phía cột tất cả các năm. Chúng ta sử dụng OUTER JOIN ở phần tự tổ hợp, rồi dùng cả dấu bất phương trình, đây quả thật là một kĩ thuật không thấp.
Query so sánh với giá trị ngay trước đó ngoài việc có thể lo cả những trường hợp có khuyết, thì không giới hạn tại đó thì tính ứng dụng cao ngay cả những trường hợp đối với dãy thứ tự ngày tháng hay chữ cái chính là sự thu hút của phương pháp này. Tuy nhiên các bạn cũng nên so sánh tính ứng dụng và giá phải trả mà sử dụng từng phương pháp.
Lũy kế di chuyển và bình quân di chuyển
Lũy kế, hay còn gọi là tổng lũy tích chính là tổng được cộng tất cả những ghi chép được ghi đến thời điểm đó. Ví dụ ta có bảng ghi chép xuất nhập của một tài khoản ngân hàng và suy nghĩ cách tính lũy kế như sau.
Accounts
| prc_date | prc_amt |
|---|---|
| 2006-10-26 | 12,000 |
| 2006-10-28 | 2,500 |
| 2006-10-31 | -15,000 |
| 2006-11-03 | 34,000 |
| 2006-11-04 | -5,000 |
| 2006-11-06 | 7,200 |
| 2006-11-11 | 11,000 |
Bảng này có ý nghĩa nhập tiền là ngày số dương, xuất tiền là ngày số âm. Vậy có nghĩa là tính lũy kế của số tiền cho đến ngày xử lý có nghĩa là tính số tiền trong tài khoản tại thời điểm đó. Để tính giá trị đó đầu tiên chúng ta có phương pháp dùng hàm số OLAP.
--Tính lũy kế: Sử dụng hàm OLAP
SELECT prc_date, prc_amt,
SUM(prc_amt) OVER (ORDER BY prc_date) AS onhand_amt
FROM Accounts;
Từ đầu thì đây là chức năng được trang bị chỉ cho trường hợp này nên không những chúng ta có thể viết lệnh một cách gọn gàng thì perfomance hay sort cũng được hoàn tất trong 1 lần. Tuy nhiên, rất tiếc là chúng vẫn chưa chạy được。Nếu trên SQL-92 thì chúng ta sẽ viết như sau.
--Tính lũy kế: Sử dụng tập hợp hồi quy kiểu Neumann
SELECT prc_date, A1.prc_amt,
(SELECT SUM(prc_amt)
FROM Accounts A2
WHERE A1.prc_date >= A2.prc_date ) AS onhand_amt
FROM Accounts A1
ORDER BY prc_date;
Kết quả
prc_date prc_amt onhand_amt
---------- --------- ------------
2006/10/26 12,000 12,000 -- 12,000
2006/10/28 2,500 14,500 -- 12,000 + 2,500
2006/10/31 -15,000 -500 -- 12,000 + 2,500 + (-15,000)
2006/11/03 34,000 33,500 -- 12,000 + 2,500 + (-15,000) + 34,000
2006/11/04 -5,000 28,500 -- như trên
2006/11/06 7,200 35,700 -- :
2006/11/11 11,000 46,700 -- :
Đã trót viết câu trả lời mà không có lời giải thích gì nhưng các bạn có nhớ rằng câu trả lời này đã nhìn thấy ở đâu đó rồi không? Thực ra đây là truy vấn giống y hệt với truy vấn trong phương pháp tính ra bảng xếp hạng được nêu trong "Cách dùng tự tổ hợp". Chúng ta chỉ thay COUNT bằng SUM thôi. Lũy kế cũng có thể tính được khi sử dụng tập hợp hồi quy kiểu Neumann. Mọi người đã phát hiện ra chưa?
Và tại đây chúng ta luyện tập lại một chút. Từ đây sẽ là vấn đề chính. Bây giờ lũy kế là tổng của được cộng không kể thời điểm được chỉ định mà được cộng từ dữ liệu cũ nhất. Lần này chúng ta sẽ thử suy nghĩ phương pháp tính lũy kế di động , có nghĩa là lũy kế của 3 lần đơn vị. Cũng như cách dùng của từ "di động" thì ta sẽ lấy đối tượng lũy kế là 3 dòng liên tiếp, và thừa mất 1 dòng.

Cách suy nghĩ đó chính là trong điều kiện của truy vấn tính lũy kế trên thì chúng ta thêm vào điều liện "Giữa ngày xử lý trong A2 và ngày xử lý trong A1 thì sẽ có 3 dòng được record. Nếu là hàm số OLAP thì chúng ta có thể chỉ định được dòng nhờ key ROW.(Tuy nhiên trong PostgreSQL thì chúng ta không thể sử dụng ROW).
--Tính lũy kế di động: sử dụng hàm số OLAP
SELECT prc_date, prc_amt,
SUM(prc_amt) OVER (ORDER BY prc_date
ROW 2 PRECEDING) AS onhand_amt
FROM Accounts;
Trong subquery tương quan thì chúng ta có thể thực hiện đếm dòng bằng Scalar Subquery.
--Tính lũy kế di động: (2) đưa ra thời gian không 3 dòng không thảo mãn.
SELECT prc_date, A1.prc_amt,
(SELECT SUM(prc_amt)
FROM Accounts A2
WHERE A1.prc_date >= A2.prc_date
AND (SELECT COUNT(*)
FROM Accounts A3
WHERE A3.prc_date
BETWEEN A2.prc_date AND A1.prc_date ) <= 3 )
AS mvg_sum
FROM Accounts A1
ORDER BY prc_date;
Kết quả
prc_date prc_amt mvg_sum
---------- --------- ----------
2006/10/26 12,000 12,000 --12,000
2006/10/28 2,500 14,500 --12,000 + 2,500
2006/10/31 -15,000 -500 --12,000 + 2,500 + (-15,000)
2006/11/03 34,000 21,500 --2,500 + (-15,000) + 34,000
2006/11/04 -5,000 14,000 --như trên
2006/11/06 7,200 36,200 -- :
2006/11/11 11,000 13,200 -- :
Các bạn hãy nghĩ hành động xảy ra giữa thời điểm A3.prc_date bắt đầu (A2.prc_date) và điểm kết thúc (A1.prc_date). Chỉ cần thay đổi điều kiện "<=3" thì chúng ta có thể di chuyển được thời gian làm đối tượng tập hợp di chuyển thành tính trong 4 hay 5 dòng. Trong 2 dòng đầu của truy vấn này có hiển thị giá trị cộng vào của những dữ liệu đã có giới hạn, nhưng chúng ta cũng có thể xác lập sao cho không đủ 3 dòng thi không thể thực hiện. Như tiếp theo đây chúng ta sử dụng câu lệnh HAVING để tìm đúng nhóm có 3 dòng (<=3 mà chúng ta chuyển thành =3 thì chương trình không chạy như mong muốn được, các bạn có biết tại sao không?)
--Tính lũy kế di chuyển: (2)Không có tác dụng đối với những thời kì không đủ 3 dòng.
SELECT prc_date, A1.prc_amt,
(SELECT SUM(prc_amt)
FROM Accounts A2
WHERE A1.prc_date >= A2.prc_date
AND (SELECT COUNT(*)
FROM Accounts A3
WHERE A3.prc_date
BETWEEN A2.prc_date AND A1.prc_date ) <= 3
HAVING COUNT(*) =3) AS mvg_sum --Không đủ 3 dòng thì không hiển thị
FROM Accounts A1
ORDER BY prc_date;
Kết quả
prc_date prc_amt mvg_sum
---------- --------- ----------
2006/10/26 12,000 --Vì chưa đủ 3 dòng nên không hiểu thị
2006/10/28 2,500 --Vì chưa đủ 3 dòng nên không hiểu thị
2006/10/31 -15,000 -500 --Đã đủ 3 dòng nên giá trị được hiển thị
2006/11/03 34,000 21,500
2006/11/04 -5,000 14,000
2006/11/06 7,200 36,200
2006/11/11 11,000 13,200
Nếu động tác của truy vấn này khó hiểu thì hiển thị kết quả không nhóm hóa rồi nhìn bên trong chắc sẽ dễ hiểu hơn.
--Phi nhóm hóa rồi hiển thị
SELECT A1.prc_date AS A1_date,
A2.prc_date A2_date,
A2.prc_amt AS amt
FROM Accounts A1, Accounts A2
WHERE A1.prc_date >= A2.prc_date
AND (SELECT COUNT(*)
FROM Accounts A3
WHERE A3.prc_date BETWEEN A2.prc_date AND A1.prc_date ) <= 3
ORDER BY A1_date, A2_date;
Kết quả
A1_date A2_date amt
------------ ------------ ---------
2006/10/26 2006/10/26 12,000
2006/10/28 2006/10/26 12,000
2006/10/28 2006/10/28 2,500
2006/10/31 2006/10/26 12,000
2006/10/31 2006/10/28 2,500 …S1:-500
2006/10/31 2006/10/31 -15,000
2006/11/03 2006/10/28 2,500
2006/11/03 2006/10/31 -15,000 …S2:21,500
2006/11/03 2006/11/03 34,000
2006/11/04 2006/10/31 -15,000
2006/11/04 2006/11/03 34,000 …S3:14,000
2006/11/04 2006/11/04 -5,000
2006/11/06 2006/11/03 34,000
2006/11/06 2006/11/04 -5,000 …S4:36,200
2006/11/06 2006/11/06 7,200
2006/11/11 2006/11/04 -5,000
2006/11/11 2006/11/06 7,200 …S5:13,200
2006/11/11 2006/11/11 11,000
Nếu triển khai như vậy thì cách suy nghĩ cơ bản cũng giống như tập hợp hồi qui kiểu Neumann sẽ không có dòng lồng mà từng đơn vị sẽ dần dần lệch đi và tạo ra những tập hợp khác nhau.
Dãy tập hợp này so sánh với tập hợp lồng nhau mang tính vòng tròn đồng tâm thì chúng ta có thể hiểu có rất nhiều phiên bản trong cách tạo tập hợp. Tại đây khi suy nghĩ về lũy kế thì ta dùng hàm SUM, nhưng nếu muốn tính bình quan di chuyển (moving average) thì chỉ cần thay SUM bằng AVG là được.
Điều tra thời kì overlap
Chúng ta có bảng sau hiển thị trình trạng đặt phòng của khách sạn, nhà nghỉ.
Reservations
| reserver | start_date | end_date |
|---|---|---|
| Kimura | 2006-10-26 | 2006-10-27 |
| Aragi | 2006-10-28 | -10-31 |
| Hori | 2006-10-31 | 2006-11-01 |
| Yamamoto | 2006-11-03 | 2006-11-04 |
| Uchida | 2006-11-03 | 2006-11-05 |
| Mizutani | 2006-11-06 | 2006-11-06 |
Tuy không viết sô phòng nhưng chúng ta sẽ suy nghĩ như đây là một phòng và loại đi những bộ phận phòng khác. Tất nhiên, không thể để cho 2 lượt khách cùng ở một phòng trong cùng một ngày được. Tuy nhiên nếu nhìn vào tình trạng đặt phòng thì có tồn tại tình trạng đặt phòng trùng. Hãy nhìn biểu dưới đây.
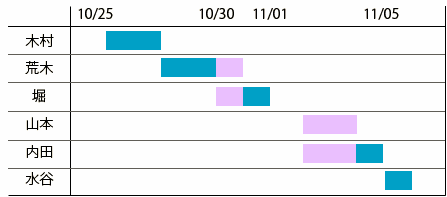
Đây là vấn đề. Chúng ta phải sắp xếp lại phòng ngay. Vấn đề lần này là list-up những khách hàng có thời gian nghỉ trùng nhau.
Đầu tiên chúng ta cùng phân loại các loại trùng nhau. Dưới đây sẽ đưa ra 3 trường hợp của trùng nhau.
- Ngày bắt đầu muộn hơn, nằm trong một thời kì khác.
- Ngày kết thúc sớm hơn, nằm trong một thời gian khác.
- Cả ngày bắt đầu và kết thúc cùng nằm trong một thời gian khác.

Ví dụ nếu nhìn từ anh Hori đến anh Aragi thì sẽ vào trường hợp 1 còn nhìn từ anh Aragi vào anh Hori thì sẽ vào trường hợp 2. Trường hợp anh Yamamoto thì kế hoạch của anh ta hoàn toàn nằm trong thời gian của anh Uchida nên đây là trường hợp 3. Có nghĩa là chắc chắn những trường hợp đăng kí nghỉ này sẽ chọn được 1 trong 3 điều kiện phía trên. Nhưng nếu suy nghĩ kĩ thì chúng ta cũng không cần trường hợp 3, vì nó là kết quả khi hợp trường hợp 1 và 2.
Nên điều kiện cần và đủ đó chính là ít nhất trúng 1 trong 2 điều kiện (1) và (2) bên trên. Như vậy chương trình sẽ là,
--Yêu cầu thời gian bị trùng.
SELECT reserver, start_date, end_date
FROM Reservations R1
WHERE EXISTS
(SELECT *
FROM Reservations R2
WHERE R1.reserver <> R2.reserver --So sánh với khách khác bản thân
AND ( R1.start_date BETWEEN R2.start_date AND R2.end_date
--Điều kiện (1):ngày bắt đầu nằm trong 1 thời gian khác
OR R1.end_date BETWEEN R2.start_date AND R2.end_date));
--Điều kiện (2):ngày kết thúc nằm trong 1 thời gian khác
Kết quả
reserver start_date end_date
---------- ------------ ----------
Aragi 2006/10/28 2006/10/31
Hori 2006/10/31 2006/11/01
Yamamoto 2006/11/03 2006/11/04
Uchida 2006/11/03 2006/11/05
Vì ta tìm người khác mình trùng lịch với mình nên nếu không có điều kiện [R1.reserver <> R2.reserver] thì kết quả sẽ hiện ra tất cả mọi người nên đây là điểm cần chú ý. Cuối cùng, ngược lại nếu chúng ta muốn tìm thời gian không overlap với một thời gian khác thì chúng ta chỉ cần thay EXISTS thành NOT EXISTS là được. Mặt khác nếu ngày bắt đầu của anh Yamamoto chệch đi 1 ngày, không phải là 3 tháng 11 mà là 4 tháng 11 thì anh Uchida sẽ bị xóa đi khỏi kết quả của truy vấn này. Đây là vì sẽ không trùng với ngày vào và ngày ra nhà nghỉ của anh Uchida. Có nghĩa là truy vấn này trong vấn đề thời gian của mình bị vào trong cả khoảng thời gian đối phương thì sẽ không được chọn.
Để trong trường hợp đó thì kết quả vẫn được hiện ra thì chúng ta phải thêm điều kiện dưới đây.
--Để 1 thời gian hoàn toàn nằm trong một khoảng thời gian khác mà kết quả vẫn được hiện
SELECT reserver, start_date, end_date
FROM Reservations R1
WHERE EXISTS
(SELECT *
FROM Reservations R2
WHERE R1.reserver <> R2.reserver
AND ( ( R1.start_date BETWEEN R2.start_date
AND R2.end_date
OR R1.end_date BETWEEN R2.start_date
AND R2.end_date)
OR ( R2.start_date BETWEEN R1.start_date
AND R1.end_date
AND R2.end_date BETWEEN R1.start_date
AND R1.end_date)));
Kết luận
Như trên ta có thể thấy subquery tương quan là một phép tính rất mạnh. Tuy nhiên cuối cùng vẫn phải nếu ra những khuyết điểm của nó. Đầu tiên, nó sẽ trở thành một code khá khó đọc để hiểu. Đây là vấn đề quen hay chưa nhưng đối với những truy vấn dùng subquery tương quan thì cũng không phải là những truy vấn có thể nhìn qua mà có thể hiểu được luôn. Đặc biệt là lũy kế hay trung bình di chuyển rồi lại còn kết hợp cả những phép tính tập hợp trong đó thì truy vấn sẽ trở nên rất khó đọc những động tác bên trong. Rồi khuyết điểm thứ 2 sẽ là perfomance không tốt. Đặc biệt nếu ta dùng scalar subquery trong câu lệnh SELECT thì sẽ làm giảm tốc độ rất nhiều và đây là điểm cần chú ý. Nếu là mượn ngôn ngữ của Celko thì người ta sẽ nói là subquery tương quan sẽ làm chương trình hay bộ tối ưu hóa optimizer trở nên khó đọc.
Kể cả ta có dùng ngôn ngữ nào, kĩ thuật nào đi chăng nữa thì không cái nào là viên đạn bạc toàn năng cả. Những gì ta có trong tay đều là con dao 2 lưỡi. Một kĩ thuật mạnh như subquery tương quan nhưng vẫn mang những khuyết điểm như trên. Chúng ta hãy để ý điều đó mà sử dụng sức mạnh của nó một cách khéo léo.
Và dưới đây là những điểm chính của chương này.
- Đối với ngôn ngữ hướng tập hợp như SQL, khi tiến hành so sánh giữa dòng với dòng thì chúng ta không thể sort rồi cho vào vòng lặp được.
- Thay vào đó, ta pahir thêm tập hợp làm đối tượng so sánh rồi sử dụng subquery tương quan (hay tự tổ hợp). Trong môi trường có thể dùng hàm số OLAP thì cũng nên nghĩ đến để sử dụng.
- Trong trường hợp tính lũy kế hay bình quân di chuyển thì cơ bản là dùng tự hồi quy kiểu Neumann.
- Khuyết điểm của subquery tương quan là perfomance và khả năng đọc hiểu thấp.
- Không thể nói đời người lúc nào mọi thứ cũng có thể diễn ra tốt đẹp được.
Tài liệu tham khảo
- 『プログラマのためのSQL 第2版』 Joe Celko 著
Về cách tính lũy kế, tham khảo "23.5.1 Tổng lũy tích"
- 『Joe Celko's SQL Programming Style』 Joe Celko 著、Morgan Kaufmann Pub、2005年5月
Đây là cuốn sách lập trình hướng được gọi là bản SQL của phương pháp lập trình của Brian Kernighan và Rob Pike. Chúng ta có thể nhìn subquery tương quan từ quan điểm, cách nhìn từ khả năng đọc hiểu và perfomance.
- 『SQLパズル 第2版』 Joe Celko 著、ミック 訳、翔泳社、2007年11月
Tính lũy kế có trong Puzzle 35. Điều chỉnh tồn kho, bình quân di chuyển có trong Puzzle 37. Bình quân di chuyển, điều tra thời gian overlap sẽ có trong Puzzle6. Đặt phòng khách sạn, Puzzle 47 Block ghế,...
- 「移動平均を求める」 明智重蔵
oraclesqlpuzzle.hp.infoseek.co.jp/8-5.html
Ở đây có giới thiệu cách tính bình quân di chuyển sử dụng hàm số OLAP và subquery tương quan. Sau đó sẽ là phương pháp gọn sử dụng BETWEEN.
All rights reserved
