1-4 Sức mạnh của câu lệnh HAVING
Bài đăng này đã không được cập nhật trong 4 năm
1-4 Sức mạng của câu lệnh HAVING
Nhân vật phụ nổi tiếng ngoại lệ
Câu lệnh HAVING là một trong những chức năng quan trọng của SQL nhưng vẫn chưa ai biết được giá trị thật sự của nó. Tuy nhiên, câu lệnh HAVING chính là chìa khóa quan trọng để hiểu về bản chất của SQL hướng tập hợp cũng như có thể ứng dụng rộng rãi. Chương này chúng ta sẽ học cách sử dụng câu lệnh HAVING, và thông qua đó để lý giải đặc tính thứ 2 của ngôn ngữ hướng tập hợp gọi là "Thao tác đơn vị tập hợp".
SQL là một ngôn ngữ khác lạ. Đối với từng người mà ấn tượng này có những khoảng cách khác nhau nhưng theo tôi, đối với những SE hay lập trình viên chính thống từ đầu đã học những ngôn ngư lập trình mang tính chất thủ tục thì sẽ nghĩ rằng ấn tượng này hẳn sẽ rất mạnh.
Lý do cảm thấy sự khác trong SQL thì tôi có thể nghĩ ra vài điều. Đầu tiên, SQL là ngôn ngữ được thiết kế dựa theo ý tưởng hướng tập hợp, và những ngôn ngữ có cùng phương châm này cũng rất ít. Một điều khác không nhỏ đó chính là giản đồ từ ngôn ngữ được học đầu tiên được cố định một cách tâm lý, ta thông qua đó để nhìn ta thế giới nên với một ngôn ngữ mang một giản đồ khác thì khả năng lý giải nó cũng giảm xuống.
Chương này sẽ giới thiệu rất nhiều phương pháp ứng dụng câu lệnh HAVING, trong những lúc đó sẽ có sự so sánh giữa suy nghĩ của SQL so với những ngôn ngữ khác. Từ đó sẽ thức tình hình mẫu tâm lý một cách vô ý thức mà chúng ta đã trang bị cho mình đối với những ngôn ngữ mang tính thủ tục và từ đó sẽ xóa dần những cảm giác về sự khác của ý tưởng về hướng tập hợp.
Tại chương này sẽ tiếp nối "Cách dùng tự tổ hợp" để điều tra về những đặc trưng của ngôn ngữ hướng tập hợp như SQL. Hướng nhìn chủ yếu trong lần trước là giải thích về mở đầu của hướng tập hợp như là sự tồn tại với độ trừu tượng cao như nghĩ bảng là một tập hợp. Lần này chúng ta dẫm lên trên đó và đánh vào điểm chính về đặc trưng là "Thao tác đơn vị tập hợp". Không hẳn những nội dung chương trước sẽ là tiền đề cho lần này nhưng hàm CASE và sự tự tổ hợp cũng sẽ xuất hiện nên nếu các bạn còn chưa đọc 1-1 và 1-2 thì nên đọc trước để có thể hiểu rõ hơn về chương này.
Tìm lỗ hổng của dữ liệu
Chúng ta nhanh chóng vừa nhìn vào ví dụ vừa tiến lên thôi. Chúng ta có một bảng có những số liên tiếp như tiếp theo đây.
SeqTbl
| seq | name |
|---|---|
| 1 | Dick |
| 2 | Ann |
| 3 | Rail |
| 5 | Car |
| 6 | Mary |
| 8 | Ben |
Tuy nhiên, nói là số liên tiếp nhưng dãy số này không hề liên tục. Khuyết 4 và 7. Bài tập đầu tiên chính là điều tra xem trong bảng có dữ liệu khuyết hay không. Đối với bảng ít dòng như thế này thì chúng ta có thể tìm ra mà chỉ cần đảo mắt, nhưng đối với bảng có hàng trăm vạn thì chắc chẳng có ai có đủ dũng khí để tự mình lần tìm cả.
Đối với bảng dưới đây, nếu chúng ta dùng ngôn ngữ lập trình mang tính thủ tục bình thường thì các giai đoạn tiến hành sẽ là
- Lựa chọn thứ tự tăng hay giảm của dãy
- Cho vào vòng lặp, so sánh từng dòng đối với dòng tiếp theo.
Trong những bước đơn giản như thế này, chúng ta cũng có thể hiểu rõ sự phân biệt giữa đặc trưng của hệ thống file và ngôn ngữ lập trình thủ tục. Đó chính là record của file mang một thứ là thứ tự, để có thể dùng được cái đó thì ngôn ngữ phải tiến hành sort. Mặt khác, những hàng trong bảng cũng không mang thứ tự, SQL cũng không mang những phép tính của sort. Thay vào đó, SQL sẽ thu lại những dòng phức tạp đó và xử lý nó như một tập hợp. Theo vậy toàn bộ bảng sẽ được nhìn như một tập hợp và câu trả lời sẽ ở tiếp theo đây.
--Kết quả trả về: có lỗ hổng
SELECT 'Có lỗ hổng' AS gap
FROM SeqTbl
HAVING COUNT(*) <> MAX (seq);
Kết quả
gap
----------
Có lỗ hổng
Kết quả của truy vấn này nếu trả lại 1 dòng thì sẽ là có lỗ hổng còn một dòng cũng không trả lại thì sẽ là không có lỗ hổng. Nếu số dòng mà COUNT() đếm được và giá trị cao nhất trong dãy là giống nhau thì đó chính là bằng chứng cho việc số số đếm được tự đầu cho đến cuối là liên tục và không có lỗ hổng. Nếu thiếu thì [COUNT()<MAX(seq)], điều kiện của câu lệnh HAVING sẽ trở thành đúng. Chỉ với 3 dòng mà chúng ta cũng có thể tìm được câu trả lời.
Nếu chúng ta biểu hiện bằng từ ngữ của lý luận tập hợp cho truy vấn này thì đó chính là chúng ta kiểm tra từng số một giữa tập hợp số tự nhiên và tập hợp SeqTbl. Như vậy có nghĩa là đối với MAX(seq) chính là giá trị lớn nhất của seq được so sánh với bộ đếm những thành tố có trong dãy số tự nhiên cho đến giá trị lớn nhất ấy. Như vậy trong trường hợp có lỗ hổng bị thiếu có nghĩa là hai giá trị đó là không đồng nhất với nhau.
Trong SQL này không có GROUP BY. Trong trường hợp này thì bảng sẽ được tập hợp trong một dòng. Và trong trường hợp đó thì câu lệnh HAVING cũng được sử dụng mà không vấn đề gì xảy ra. Đối với SQL ngày xưa thì chúng ta nhất định phải ghép câu lệnh HAVING và GROUP BY với nhau nên ngay cả bây giờ thỉnh thoảng chúng ta vẫn có những hiểu lầm như vậy. Đối với SQL thông thường hiện tại thì chỉ có Câu lệnh HAVING không được sử dụng đơn độc. Chúng ta có thể nghĩ rằng có nghĩa là câu lệnh để tập hợp dữ liệu lại là GROUP BY bị giản lược. Chúng ta cũng có thể coi nó giống như lý thuyết về động tác hàm OLAP không chỉ định câu lệnh PARTITION biến cả bảng chỉ thành 1 sự phân cách. Về chi tiết hãy tham khảo trong phần 2 [GROUP BY và PARTITION BY].
Tuy nhiên trong trường hợp này chúng ta không thể sử dụng câu lệnh SELECT để tham chiếu bảng ban đầu thì theo như ví dụ chúng ta chỉ định hằng số hoặc cần thiết phải dùng những hàm số tập hợp như SELECT COUNT(*).
Hiện nay chúng ta đã có thể biết rằng trong bảng có kẽ hở. Lần này chúng ta sẽ yêu cầu giá trị nhỏ nhất của kẽ hở này. Nếu là giá trị nhỏ nhất thì chắc chắn sẽ là hàm MIN. Và chúng ta sẽ viết như dưới đây.
--Tìm giá trị nhỏ nhất của lỗ hổng
SELECT MIN(seq+1) AS gap
FROM SeqTbl1
WHERE (seq+ 1) NOT IN (SELECT seq FROM SeqTbl);
Kết quả
gap
---
4
Chương trình này cũng chỉ có 3 dòng. Query sử dụng NOT IN là truy vấn xem đối với giá trị đó trong bảng có giá trị nào lớn hơn 1 đơn vị không. Như vậy đối với hàng (3, Rail), (6, Mary), (8,Ben) thì vì không tìm được số tiếp theo nên điều kiện sẽ trở nên đúng. Trong trường hợp không có lỗ hổng thì chúng ta sẽ có được kết quả là 9 là số tiếp theo của giá trị cao nhất là 8. Mặc dù được lặp đi lặp lại nhưng bảng không phải là file nên các dòng không được sắp xếp theo thứ tự (Bảng trên để dễ nhìn nên các dòng được xếp theo thứ tự tăng dần, nhưng cũng chỉ là vì cho dễ nhìn).
Tuy nhiên, khi trong bảng có giá trị NULL thì truy vấn trên sẽ không ra được kết quả đúng. Đối với những người không thể hiểu luôn lý do tại sao thì có thể xem lại "Luận lý 3 giá trị và NULL" (tr.46).
Đây chính là query hiển thị cách suy nghĩ cơ bản nhất khi tìm kiếm chỗ bị thiếu trong SQL. Thực ra query này có hơi quá đơn giản, không thể đối ứng được tất cả các trường hợp. Ví dụ trong bảng ngay từ số 1 đã thiếu rồi thì kết quả trả lại là giá trị nhỏ nhất là số 1, nhưng không một query nào trả lại kết quả đúng. (Các bạn hãy thử tưởng tượng xem kết quả trả lại là gì?). Về tất cả những gì liên quan đến tìm chỗ trống thì chúng ta sẽ đề cập đến vấn đề này tại chương sau "Câu lệnh HAVING trả lại" (tr.176).
Subquery trong câu lệnh HAVING: yêu cầu giá trị xuất hiện nhiều nhất
Đại học nổi tiếng Virginia được Thomas Jefferson thành lập, năm 1984 được phát biểu lương khởi điểm bình quân của sinh viên ra trường khoa giao tiếp quốc tế là 55000 USD. Tại thời điểm đó, 1$ = 240 yên nên chúng ta có thể nghĩ thì ở nhật thì đó là 1320 vạn yên, tức 13 triệu 200 ngàn yên. Nếu nghe qua như thế này thì chúng ta đều có ấn tượng là lương khởi điểm của sinh viên tốt nghiệp có vẻ cao. Tuy nhiên trong con số này có một thủ thuật. Trong những sinh viên tốt nghiệp có bao gồm ngôi sao NBA Sampson Raph là cầu thủ cao nhất trong lịch sử trường đại học. Có nghĩa là trong bảng những sinh viên tốt nghiệp mà trường đại học sử dụng sẽ có hình ảnh của sự phân chia một cách rõ ràng như sau.
Graduates
| name | income |
|---|---|
| Sampson | 400,000 |
| Mike | 30,000 |
| White | 20,000 |
| Arnold | 20,000 |
| Smith | 20,000 |
| Lorrent | 15,000 |
| Hudson | 15,000 |
| Kent | 10,000 |
| Baker | 10,000 |
| Scott | 10,000 |
Chúng ta cũng có thể dễ hiểu từ bảng trên, trong cách tính trung bình thông thường có khuyết điểm là rất dễ kết quả sẽ bị ảnh hưởng bởi giá trị đặc biệt "outlier". Trong trường hợp này thì chúng ta phải dùng một chỉ số khác phản ánh đúng hơn xu hướng của tập thể. Một trong số đó chính là mode. Đây chính là giá trị xuất hiện nhiều nhất trong tập hợp. Chính vì vậy nên nó cũng có tên gọi là giá trị trào lưu. Nếu trong bảng sinh viên tốt nghiệp ở trên thì hcung ta cũng có thể nhìn thấy giá trị đó là 10,000 và 20,000. Chúng ta cùng suy nghĩ các tìm ra những giá trị này.
Tùy theo DBMS mà có thể có những hàm số đặc biệt khác nhau để tìm ra giá trị mode này. Tuy nhiên trong SQL căn bản thì chúng ta cũng có thể đơn giản yêu cầu được. Cách suy nghĩ chính là tạo một tập hợp có những người có thu nhập giống nhau, rồi trong những tập hợp đó tìm ra tập hợp có nhiều thành tố nhất. Đối với SQL thì thao tác đối với tập hợp như thế này là trong tầm tay.
--SQL yêu cầu giá trị mode Bản 1: dùng ALL
SELECT income, COUNT(*) AS cnt
FROM Graduates
GROUP BY income
HAVING COUNT(*) >= ALL ( SELECT COUNT(*)
FROM Graduates
GROUP BY income);
Kết quả
income cnt
------ ---
10,000 3
20,000 3
GROUP BY thực hiện chức năng tạo tập hợp bộ phận từ tập hợp cũ. Như vậy nếu chúng ta sử dụng GROUP BY đối với income thì chúng ta sẽ có được 5 tập hợp. Trong đó có tập hợp có số thành tố nhiều nhất chính là số thành tố 3 của S3 và S5. Và như vậy 2 tập hợp này được chọn.
Mặt khác, cũng như đã đề cập ở "Luận lý 3 giá trị và NULL" thì thuật ngữ ALL có thể thay thế bằng hàm số cực trị khi sử dụng trong những trường hợp có NULL hoặc tập hợp rỗng cần chú ý. Lần này chúng ta cần "nhiều nhất" nên chúng ta sẽ sử dụng hàm MAX.
-- SQL yêu cầu giá trị mode Bản 2: dùng hàm số cực trị
SELECT income, COUNT(*) AS cnt
FROM Graduates
GROUP BY income
HAVING COUNT(*) >= ( SELECT MAX(cnt)
FROM (SELECT COUNT(*) AS cnt
FROM Graduates
GROUP BY income) TMP);
Nếu bảng Graduates là file, tức là yêu cầu giá trị mode bằng ngôn ngữ lập trình thủ tục thì chúng ta làm thế nào? Có thể cách làm sẽ là sau khi phân loại bằng thu nhập rồi cho vào vòng lặp thực hiện Control break. Nếu số dòng đếm được của tập hợp thu nhập giống nhau lại lớn hơn số dòng đếm được trước đó của tập hợp thu nhập giống nhau khác thì giá trị đó sẽ được thay thế và lưu. Tuy nhiên, cũng như chúng ta có thể nhìn thấy thì trong SQL thì chúng ta cũng không có vòng lặp hay sự thay thế nào.
Tự tổ hợp bằng câu lệnh HAVING: yêu cầu giá trị chính giữa, giá trị trung tâm
Trong trường hợp không thể tín nhiệm số bình quân thì cũng với giá trị hay được sử dụng thì còn một giá trị khác cũng hay được sử dụng đó chính là giá trị trung vị, giá trị median. Đây là giá trị vào chính giữa khi sắp xếp tập hợp mẹ theo chiều tăng dần. Nếu số lượng thành tố trong dãy là số chẵn thì đó chính là trung bình cộng của 2 giá trị nằm giữa. Trong bảng Graduates trên vì có 10 dòng nên median chính là giá trị trung bình cộng của (Smith, 20,000) và (Lorrent, 15,000) là 17,500.
Như vậy khi yêu cầu giá trị này thì trong SQL chúng ta phải làm thế nào? Tất nhiên chúng ta sẽ không lấy phương pháp mang tính thủ tục là lựa chọn và đếm từ trên trở xuống. Trong trường hợp chúng ta nghĩ theo hướng tập hợp thì làm thế nào để biết được giá trị vào chính giữa tập hợp mẹ?
Như vậy chúng ta sẽ chia tập hợp thành nửa trên và nửa dưới. Chúng ta sẽ làm để tập hợp nửa trên và tập hợp nửa dưới sẽ cùng nhau giá trị ở giữa. Và trung bình của bộ phận ở giữa chính là giá trị median chúng ta đang tìm.
Tạo tập hợp bộ phận dựa theo quan hệ lớn nhỏ này chính là sự xuất hiện của tự tổ hợp giá trị bất đẳng.
-- SQL yêu cầu giá trị median: sử dụng câu lệnh HAVING để tự tổ hợp giá trị bất đẳng.
SELECT AVG(DISTINCT income)
FROM (SELECT T1.income
FROM Graduates T1, Graduates T2
GROUP BY T1.income
-- Điều kiện S1
HAVING SUM(CASE WHEN T2.income >= T1.income THEN 1 ELSE 0 END)
>= COUNT(*) / 2
-- Điều kiện S2
AND SUM(CASE WHEN T2.income <= T1.income THEN 1 ELSE 0 END)
>= COUNT(*) / 2) TMP;
Điểm nhấn đây chính là trong điều kiện so sánh [>= COUNT(*)/2] có thêm dấu [=] có nghĩa là không phân chia hẳn S1 và S2 ra mà đây chính là hành động cố tình để cho 2 tập hợp này có thành tố chung. Trong điều kiện này nếu chúng ta bỏ đi dấu đẳng thức [=] thì trong trường hợp số lượng thành tố là số chẵn thì S1 và S2 sẽ không có thành phần chung, từ đó chúng ta sẽ không có được median.
Nếu chúng ta biết ngay từ đầu số lượng là số lẻ thì subquery của FROM chỉ có một giá trị, chúng ta sẽ không cần viết thêm AVG ở bên ngoài. Tuy nhiên, nếu số lượng thành tố là số chẵn thì query này là một suy nghĩ rất bình thường nên hàm số AVG trở nên cần thiết. Tự tổ hợp của hàm CASE cùng với vũ khí câu lệnh HAVING của SQL, đây là câu trả lời không còn gì để nói.
Trong những lúc phát biểu giá trị trung bình mang cả những vấn đề như thế này thì bình thường đại học Virginia cũng không công bố những chỉ tiêu khác như median. Như vậy các bạn (hay con của các bạn) khi chọn trường, về điều kiện làm việc hay tỉ lệ học lên thì nếu người ta không chỉ công bố giá trị trung bình mà còn công bố cả mode hay median thì có lẽ chúng ta mới có thể tin tưởng hoàn toàn vào cơ quan giáo dục đó.
Tìm tập hợp không có NULL
Trong những phương pháp sử dụng hàm COUNT thì chúng ta có 2 loại là COUNT() và COUNT(tên dãy). Có 2 sự khác nhau giữa 2 hàm. Đầu tiên đó chính là sự khác nhau của perfomance, điều thứ 2 đó chính là ngược với COUNT() đếm cả NULL thì COUNT(tên dãy) cũng giống như những hàm số khác thì nó sẽ ra kết quả tập hợp khi đã loại bỏ kết quả NULL. Nói một cách khác thì ngược với COUNT(*) đếm tất cả các hàng có trong bảng thì COUNT(tên dãy) khôngg như vậy.
Đối với sự khác nhau của 2 hàm thì chúng ta thử dùng 1 bảng chỉ toàn NULL và chạy thử thì sẽ nhìn thấy rõ ràng kết quả.
NullTbl
| col_1 |
|---|
--Trường hợp dãy toàn NULL, kết quả của COUNT(*) và COUNT(tên dãy) là khác nhau.
SELECT COUNT(*), COUNT(col_1)
FROM NullTbl;
Kết quả
count(*) count(col_1)
-------- ------------
3 0
Sự khác nhau này tất nhiên trong khi lập trình chúng ta cần chú ý nhưng nếu sử dụng một cách uyển chuyển thì chúng ta chúng ta có thể có những ứng dụng với ý nghĩa sâu hơn được. Ví dụ chúng ta suy nghĩ về bảng tiếp theo đây ghi ngày nộp báo cáo của sinh viên.
Students
|student_id|dpt|sbmt_date| |--------|--------| |100|Khoa Lý|2005-10-10| |101|Khoa Lý|2005-09-22| |102|Khoa Văn| | |103|Khoa Văn|2005-09-10| |200|Khoa Văn|2005-09-22| |201|Khoa Máy| | |202|Khoa Kinh tế|2005-09-25|
Khi sinh viên nộp báo cáo thì chúng ta ghi ngày nộp vào bảng. Khi chưa nộp có nghĩa là NULL. Từ bảng này chúng ta có thể yêu cầu khoa mà học sinh thuộc đã nộp hết báo cáo. Đơn giản chúng ta chỉ cần chọn điều kiện [WHERE sbmt_date IS NOT NULL] là được, nhưng như vậy thfi nó sẽ bao gồm cả khoa Văn không cần thiết nên chương trình sẽ không chạy như ý muốn (Khoa Văn có số 102 chưa nộp). Cách nghĩ sẽ là đầu tiên chúng ta sử dụng GROUP BY để phân chia ra các tập hợp như dưới đây.
S1: Khoa Lý. COUNT(*) = 2; COUNT(sbmt_date) = 2
S2: Khoa Văn. COUNT(*) = 3; COUNT(sbmt_date) = 2
S3: Khoa Máy. COUNT(*) = 1; COUNT(sbmt_date) = 0
S4: Khoa Kinh tế. COUNT(*) = 1; COUNT(sbmt_date) = 1
Như vậy trong 4 tập hợp bộ phận thì kết quả chúng ta mong muốn đó chính là S1 và S4. Như vậy đâu là tính năng mà cả 2 tập hợp này đều có mà những tập hợp khác không có đây? Đó chính là kết quả COUNT(*) và COUNT(sbmt_date) giống nhau. Đây là hiện tượng không xảy ra ở S2 và S3 vì trong 2 tập hợp này có kết quả NULL. Như vậy thì kết quả sẽ thành như sau.
--Chọn khoa không có NULL trong ngày nộp. Bản 1: sử dụng câu lệnh COUNT
SELECT dpt
FROM Students
GROUP BY dpt
HAVING COUNT(*)=COUNT(sbmt_date);
Kết quả
dpt
------------
Khoa Lý
Khoa Kinh tế
Tất nhiên chúng ta cũng có thể viết cũng điều kiện như vậy bằng công thức viết bằng hàm CASE.
--Chọn khoa không có NULL trong ngày nộp. Bản 1: sử dụng hàm CASE
SELECT dpt
FROM Students
GROUP By dpt
HAVING cOUNT(*) = SUM(CASE WHEN sbmt_date IS NOT NULL
THEN 1
ELSE 0 END);
Hàm CASE đối với những dòng không phải NULL thì sẽ trả lại giá trị 1, còn đối với dòng NULL thì sẽ trả lại giá trị 0, chúng ta chỉ cần đơn giản nghĩ như vậy thôi. Nói cách khác ở đây thì hàm CASE biểu diễn hàm số quyết định có phải tập hợp có chứa những thành tố (dòng) thỏa mãn một điều kiện nhất định nào đó không. Những hàm số như thế này được gọi là hàm số đặc tính (characteristic function) là hàm số định nghĩa mang ý nghĩa định nghĩa tập hợp.
Như vậy thì câu lệnh HAVING có thể sử dụng như một công cụ điều tra tính chất của tập hợp. Đặp biệt khi được dùng kết hợp với hàm CASE hay những hàm số tập hợp khác thì tính năng càng được cường hóa rất mạnh.
Phân tích giỏ hàng bằng phép chia quan hệ
Tiếp theo, chúng ta sẽ suy nghĩ đến bảng hiển thị tình hình tồn kho của chuỗi cửa hàng giảm giá trên toàn quốc. Đây chính là cấu trúc bảng chúng ta hay nhìn thấy.
Items
| item |
|---|
| Bia |
| Tã giấy |
| Ô tô |
| shop | item |
|---|---|
| Sendai | Bia |
| Sendai | Tã giấy |
| Sendai | Ô tô |
| Sendai | Rèm cửa |
| Tokyo | Bia |
| Tokyo | Tã giấy |
| Tokyo | Ô tô |
| Osaka | Tivi |
| Osaka | Tã giấy |
| Osaka | Ô tô |
Vấn đề lần này là chọn những cửa hàng có tất cả những sản phẩm có trong bảng items. Có nghĩa kết quả mong muốn nhận được là của hàng ở Sendai và Tokyo. Vì Osaka không có bia nên nằm ngoài đối tượng. Ví dụ đại diện của những công việc giải quyết những vấn đề như thế này thì đó chính là một kĩ thuật của khai phá dữ liệu, là phân tích giỏ hàng, nhưng khi ta chỉ cần thay hình dạng một chút thì sẽ được những nghiệp vụ khác nhau. Ví dụ trong lĩnh vực y học, khi ta muốn tìm kiếm những bệnh nhân dùng những loại thuốc khác nhau hay những trường hợp tìm kiếm những lập trình viên thông qua cả Oracle và UNIX từ cơ sở dữ liệu kĩ thuật của công ty, v...v...
Basket Analysis (phân tích giỏ hàng) là một trong những phương pháp được sử dụng trong lĩnh vực marketing, để phân tích xu hướng những giỏ hàng mà người mua có thể mua cùng nhau. Đối với ví dụ thực tế ở đây thì ví dụ chúng ta có thể biết rằng trong siêu thị, người mua bia thường mua cùng với tã giấy (có thể người bố đến mua tã giấy cho con thì tiện tay mua bia luôn) thì sẽ thành công trong tăng lượng bán ra nếu chúng ta để bia ở khu vực gần tã giấy là được.
Cũng như bảng ShopItems, chúng ta muốn phân tích một số dòng thông tin của một thực thể (mà ở đây là cửa hàng) thì chúng ta chỉ đơn giản dùng câu lệnh WHERE rồi sử dụng câu điều kiện OR hay IN thì sẽ không thể có được kết quả đúng.
--Tìm kiếm cửa hàng để cả ô tô, tã giấy và bia: SQL sai
SELECT DISTINCT shop
FROM ShopItems
WHERE intem IN (SELECT item FROM Items);
Kết quả
shop
------
Sendai
Tokyo
Osaka
Điều kiện trong câu điều kiện IN này không quá với ý nghĩa chỉ định những cửa hàng để ô tô hoặc tã giấy hoặc bia. Chỉ cần có một trong những thứ đó thì sẽ có trong kết quả. Những lúc như thế này, có nghĩa là điều kiện là nhiều dòng hay chúng ta muốn xác lập điều kiện đối với một tập hợp thì phải làm thế nào? Đến đây chắc các bạn cũng có thể hiểu rồi đúng không? Chúng ta sẽ sử dụng câu lệnh HAVING để viết như sau.
--Tìm kiếm cửa hàng có đặt cả ô tô, tã giấy và bia: SQL đúng
SELECT SI.shop
FROM ShopItems SI, Items I
WHERE SI.item = I.item
GROUP By SI.shop
HAVING COUNT(SI.item) = (SELECT COUNT(item) FROM Items);
Kết quả
shop
------
Sendai
Tokyo
Subquery của câu lệnh HAVING, [(SELECT COUNT(item) FROM Items)] sẽ trả lại kết quả là 3. Như vậy những cửa hàng có kết quả tổ hợp bảng tồn kho là 3 sẽ được chọn. Đối với Osaka không để bia, chỉ có 2 dòng nên bị loại. Dòng "Rèm cửa của Sendai" sẽ bị xóa bởi tổ hợp nên của hàng ở Sendai và Tokyo sẽ được chọn.
Tại đây chúng ta chú ý đến [HAVING COUNT(SI.item) = COUNT(I.item)] vì đó là sai. nếu với điều kiện này thì cả 3 cửa hàng Sendai, Tokyo, Osaka sẽ đều được chọn. Đó là vì chịu ảnh hưởng của tổ hợp, giá trị của COUNT(I.item)sẽ không là số dòng của bảng [Items] ban đầu nữa. Nhìn kết quả dưới đây chúng ta có thể thấy rõ bằng mắt thường.
SELECT SI.shop, COUNT(SI.item), COUNT(I.item)
FROM ShopItems SI, Items I
WHERE SI.item = I.item
GROUP By SI.shop;
Kết quả
shop COUNT(SI.item) COUNT(I.item)
------ -------------- --------------
Sendai 3 3
Tokyo 3 3
Osaka 2 2
Như vậy chúng ta đã có SQL thỏa mãn điều kiện của ví dụ. Tiếp theo chúng ta cùng suy nghĩ biến đổi làm thế nào để loại bỏ cả cửa hàng ở Sendai có bán thêm rèm cửa mà chỉ chọn Tokyo thôi thì làm thế nào? Có nghĩa là phép chia quan hệ chính xác (exact relational division), có nghĩa là chọn cửa hàng với điều kiện không thiếu không thừa.(Đối ngược với cái này chính là phép chia nhìn thấy bây giờ chính là phép chia có phép nhân (divison with a remainder). Như vậy chúng ta dùng tổ hợp ngoại bộ như sau.
--Phép chia quan hệ chính xác: sử dụng hàm COUNT và tổ hợp ngoại bộ.
SELECT SI.shop
FROM ShopItems AS SI LEFT OUTER JOIN Items AS I
ON SI.item=I.item
GROUP BY SI.shop
HAVING COUNT(SI.item) = (SELECT COUNT(item) FROM Items) --Điều kiện 1
AND COUNT(I.item) = (SELECT COUNT(item) FROM Items); --Điều kiện 2
Kết quả
shop
-----
Tokyo
Khi chúng ta tổ hợp ngoại bộ bảng ShopItems thì những thành tố như rèm cửa hay tivi không tồn tại trong bảng Items sẽ hiện lên trong dãy I.item như một NULL. Đi đến được đây thì chúng ta có thể sử dụng một thủ thuật của hàm COUNT giống như vì dụ nộp báo cáo lúc trước. Theo điều kiện 1 thì COUNT(SI.item)=4 sẽ được xóa, theo điều kiện 2 cửa hàng Osaka với COUNT(I.item) = 2 sẽ bị xóa (NULL sẽ không được đếm).
Kết quả tổ hợp ngoài của bảng ShopItems và Items
|shop|SI.item|I.item| |--------|--------| |Sendai|Bia|Bia| |Sendai|Tã giấy|Tã giấy| |Sendai|Ô tô|Ô tô| |Sendai|Rèm cửa| | |Tokyo|Bia|Bia| |Tokyo|Tã giấy|Tã giấy| |Tokyo|Ô tô|Ô tô| |Osaka|Tivi| | |Osaka|Tã giấy|Tã giấy| |Osaka|Ô tô|Ô tô|
Bình thường nếu chúng ta nói về tổ hợp ngoài thì trường hợp tổ hợp bảng Items là chủ yếu nhưng ở đây chúng ta lại đảo ngược lại, đây cũng chính là một ý tưởng rất thú vị.
Phép chia quan hệ
Phép tính được giới thiệu ở đây thông thường được gọi là "Phép chia quan hệ". Nếu chúng ta viết theo phép chia được học thông thường sẽ là [ShopItems / Items]. Tại sao đây được gọi là phép chia thì chúng ta suy nghĩ theo hướng phép tính ngược lại chính là phép nhân thì sẽ hiểu. Giữa phép nhân và phép chia, chúng ta có một quan hệ giữa số bị chia, thương và số chia.
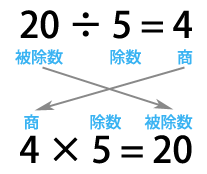
Phép tính phù hợp với phép chia trong SQL đó chính là tổ hợp Cross. Nếu chúng ta yêu cầu tích sau khi tổ hợp Cross thương và bảng Items là số chia thì sẽ có được tập hợp bộ phận của bảng ShopItems. (Không chắc chắn là sẽ trở lại bảng ShopItems như ban đầu). Đây chính là nguồn gốc của cái tên "Phép chia".
Phép chia quan hệ trong thế giới những phép tình thì là phép tính mà tên có độ được biết đến là thấp nhất. Nhưng như vậy không có nghĩa nó không được sử dụng thường xuyên. Trong một số trường hợp nó hay được sử dụng một cách vô thức khi ngay cả người sử dụng cũng không biết tên nó. Hơn nữa nó là phép tính được sinh ra là một trong 8 phép tính cơ bản được định nghĩa đầu tiên trong lập trình
Nhưng tại sao sau này nó lại bị xa lánh như thế này thì nó có một lý do rất lớn đó chính là định nghĩa phép chia quan hệ có rất nhiều cách định nghĩa khác nhau. Không chỉ 2 loại phép chia như đã được giới thiệu ở phần trên mà còn có những cái khác nữa như "Phép chia có chứa phép nhân" mà Date đã viết ra sử dungj EXISTS và nó sẽ làm những động tác khác hẳn những động tác chúng ta đã làm từ trước đến nay. Phép chia của Date thì ngay cả bảng Items có trống hết thì nó bẫn trả lại kết quả là cả 3 cửa hàng, nhưng nếu dù ng hàm COUNT trong trường hợp phép chia này sẽ ra kết quả này sẽ ra rỗng. Phép chia quan hệ chậm với tiến trình thông thường hóa, đối với những bối cảnh không có những dấu phép tính chuyên dụng thì sẽ xảy ra những trường hợp khó xử.
Tóm tắt
Có thể mọi người sẽ nghĩ câu lệnh HAVING sẽ như một diễn viên phụ mãi không có cơ hội để xuất hiện. Cũng không có ít người coi nhẹ nó và nghĩ rằng "Đúng là một câu lệnh ngu dốt và thảm hại hư thế này. Nhưng cũng có thể nhìn thấy ở trong chương trình này thì câu lệnh HAVING là một trong những vũ khí có sức mạnh lớn về ngôn ngữ lập trình hướng tập hợp. Và giá trị thực của nó được phát huy khi lắp ráp với những vũ khí khác như tự tổ hợp hay hàm CASE.
Dưới đây chúng ta sẽ tóm tắt lại những điểm của chương lần này.
- Bảng không phải là file. Dòng sẽ không có thứ tự.
- Vì SQL không phải là ngôn ngữ thủ tục nên sẽ không xảy ra thay thế, vòng lặp hay phân kì
- **Thay vào đó SQL sẽ liên tiếp tạo những tập hợp cho đến khi đến được tập hợp như yêu cầu. Suy nghĩ trong SQL không phải chúng ta sẽ suy nghĩ như là đang vẽ, viết tứ giác, dấu mũi tên mà trung tâm sẽ là suy nghĩ rằng chúng ta đang vẽ hình tròn. **
- Tạo tập hợp bằng GROUP BY.
- Đối ngược với công cụ điều tra tính chất của thành tố trong tập hợp bằng câu lệnh WHERE thì có công cụ điều tra tính chất của chính tập hợp đó bằng câu lệnh HAVING.
Cho đến đây các bạn thấy thế nào? Cho đến đây mọi người đã có thực cảm rằng mình đang học một ngôn ngữ hướng tập hợp không? Đối với những người muốn học kĩ hơn thì chúng ta có thể tham khảo những tài liệu dưới đây.
- **C.J.Date - "C. J. Dateのデータベース実践講義" **
Chương 5.2.8 sẽ có thuyết minh về phép chia quan hệ sử dụng EXISTS. Ấn tượng về bình luận "Không muốn chạm vào kĩ hơn" khi nói về phép chia.
- Joe Celko プログラマのためのSQL 第2版 、ピアソンエデュケーション、2001年4月
Chương 23. Thống kê bằng SQL sẽ là sự hoạt động mạnh mẽ của câu lệnh HAVING
- Joe Celko, SQLパズル 第2版 (翔泳社、2007)
Cách sử dụng câu lệnh HAVING là một trong những chìa khóa của quyển sách này. Về những thủ thuật cao độ của câu lệnh HAVING sẽ là "Puzzle 20 Kết quả bài test", về phép chia quan hệ là "Puzzle 21. Máy bay và phi công", về tìm kiếm điểm khuyết sử dụng câu lệnh HAVING là puzzle 57, 58 "Tìm kiếm điểm khuyết". Hơn nữa đối với những bạn có sở thích sâu hơn đối với phép chia quan hệ phức tạp hơn, đa chiều thì sẽ được giới thiệu trong Puzzle 64 Box, chúng ta có thể gọi nó là hòm kho báu của ý tưởng chỉ định tập hợp.
- J.Celko Joe Celko's Analytics And Olap in SQL』、Morgan Kaufmann Pub、2006年7月
Đây là cuốn sách với điểm nhìn thú vị vào SQL như một tools của OLAP. Tại đây phép chia quan hệ sẽ được giới thiệu kĩ hơn như một phương pháp phân tích giỏ hàng. Nhất định các bạn hãy xem cách tính median thú vị bằng hàm số ROW_NUMBER.
All rights reserved
