1-2 Cách sử dụng chức năng tự tổ hợp
Bài đăng này đã không được cập nhật trong 4 năm
Cách sử dụng chức năng tự kết hợp
SQL là ngôn ngữ chỉ hướng tập hợp phép tính mà SQL cũng cấp được thực hiện với đối tượng là những bảng khác nhau, nhưng nó cũng có thể tiến hành với những bảng đồng nhất (những bảng đã tự liên hợp với nhau). Tự kết hợp là một kĩ năng rất khó hình dung động tác nên không được sử dụng nhiều nhưng khi sử dụng quen và thành thạo thì đây là một kĩ thuật rất tiện lợi. Tại chương này chúng ta sẽ học về sự tự liên hợp này.
Mở đầu
Tại những phép tính liên hợp mà SQL cung cấp thì thông qua chính đặc trưng của nó thì người ta đã đặt những cái tên như kết hợp trong, kết hợp ngoài và kết hợp Cross. Thông thường, hầu hết những kết hợp này chạy với đối tượng là những bảng khác nhau hay view dữ liệu khác nhau. Tuy nhiên SQl cũng không cấm những bảng đó đồng nhất thành một bảng để có thể sử dụng dễ dàng hơn. Kết hợp diễn ra khi đồng nhất các đối tượng bảng với nhau được gọi là Tự kết hợp(Self-join). Nếu có thể sử dụng tự tổ hợp một cách thành thạo thì đây là một kĩ thuật rất tiện lợi nhưng do sự khó hình dung trong các động tác nên mọi người thường tránh xa nó. Thông qua chương này, qua những ví dụ chúng ta sẽ học về sự tiện lợi của sự tự tổ hợp này, và sẽ được giải thích một cách dễ hiểu những động tác này.
Để hiểu về sự tự tổ hợp thì ngoài việc trang bị những kĩ năng thực vụ trên thực tế mà cần phải có thêm một điều rất quan trọng khác nữa. Đó chính là chúng ta phải hiểu một đặc trưng quan trọng của SQL là Chỉ hướng tập hợp(Set-oriented). Ngôn ngữ định hướng Object để biểu diễn được thế giới như là một object thì SQL biểu diễn thế giới như một tập hợp. Tự tổ hợp là kĩ thuật sử dụng đặc điểm này của SQL một cách hợp lý nhất. Nhất định sau khi đọc xong chương này những dữ liệu ta nhìn thấy trên biểu 2D thì chúng ta chắc chắn có thể dần nhìn thấy nó như một tập hợp.
Dãy hoán vị lặp lại - Dãy thứ tự - Kết hợp
Có 3 sản phẩm được lưu ở bảng lưu giữ sản phẩm và giá của nó là "Táo, cam, chuối". Trong những trường hợp như là tạo nên một phiếu ghi lượng bán, ta rất muốn có được những sự kết hợp của những loại quả này.
| name | price |
|---|---|
| Táo | 100 |
| Cam | 50 |
| Chuối | 80 |
Nói là dãy, tập hợp nhưng nó cũng có 2 loại. Một loại là dãy được sắp xếp theo một quy luật, thứ tự nào đó được gọi là Dãy có quy luật(ordered pair), còn một dãy khác là dãy được sắp xếp không chủ ý theo một thứ tự, quy luật nào được gọi là dãy bất quy luật.(unorrdered). Đối với những dãy được sắp xếp theo một quy luật nhất định thì được bao bởi dấu <1,2>, còn đối với dãy được sắp xếp không theo một quy luật nhất định thì được bao bằng dấu ngoặc {1,2}. Trong dãy được sắp xếp theo quy luật thì sự sắp xếp các nhân tố trong dãy khác nhau là những dãy khác nhau, <1,2> khác <2,1> nhưng đối với dãy không được xếp theo một quy luật nào đó thì vị trí các thành tố có trong dãy có thay đổi thì dãy cũng không thay đổi, {1,2} = {2,1}. Đối với dãy có quy luật thì việc tạo ra nó trên SQL là rất dễ dàng. Như dưới đây nếu chúng ta tạo một trực tích đơn giản bằng cách liên kết các cross thì đã có thể có được một dãy có quy tắc.
--SQL để có được một dãy hoán vị lặp lại
SELECT P1.name AS name_1, P2.name AS name_2
FROM Products P1, Products P2;
Kết quả
name_1 name_2
------ ------
Táo Táo
Táo Cam
Táo Chuối
Cam Táo
Cam Cam
Cam Chuối
Chuối Táo
Chuối Cam
Chuối Chuối
Mỗi một hàng sẽ biểu diễn một dãy có quy luật. Số lượng kết quả dãy hoán vị đó chính là 3^2=9. Trogn kết quả sẽ bao gồm những kết quả có những dãy như (táo, táo) rồi cũng sẽ xuất hiện là những sự kết hợp khác nhau chỉ qua sự thay đổi thứ tự như (táo, chuối), (chuối, táo). Lý do ở đây chính là vì nó được sắp xếp một cách có chủ ý theo một thứ tự nên sự thay đổi thứ tự nhỏ trong dãy cũng tạo ra một dãy khác.
Đầu tiên chúng ta loại bỏ những sự kết hợp mà 2 thành tố là giống nhau, như vậy chúng ta cần thêm như dưới đây.
--SQL để nhận được dãy
SELECT P1.name AS name_1, P2.name AS name_2
FROM Products P1, Products P2
WHERE P1.name <> P2.name
Kết quả
name_1 name_2
------ ------
Táo Cam
Táo Chuối
Cam Táo
Cam Chuối
Chuối Táo
Chuối Cam
Theo như câu điều kiện WHERE P1.name <> P2.name thì những sự kết hợp mà hai thành tố là giống nhau sẽ bị xóa đi. Số lượng kết quả tính toán được là chỉnh hợp chập 2 của 3. Điểm mấu chốt để hiểu được sự kết hợp này tưởng tượng xem hai bảng dưới đây có đúng thật hay không.
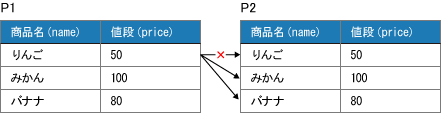
Tất nhiên, theo một cách vật lý P1 và P2 là bảng được đưa vào những thành tố cso trong Products. Tuy nhiên, đối với SQL thì nếu trả về những tên khác nhau thì kể cả trong cùng một bảng đồng nhất thì sẽ được nhìn là 2 bảng khác nhau. Chỉ là thông tin đưa vào 2 bảng chẳng may giống nhau nhưng vẫn được nghĩ là 2 bảng khác nhau. Như vậy động tác của tổ hợp là
- Đối tượng liên kết của dòng "Táo" của P1 chỉ có thể là 2 dòng "Cam, Chuối"
- Đối tượng liên kết của dòng "Cam" của P1 chỉ có thể là 2 dòng "Táo, Chuối"
- Đối tượng liên kết của dòng "Chuối" của P1 chỉ có thể là 2 dòng "Cam, Táo"
Và tất nhiên, kết quả này vẫn là một dãy có quy luật. Bây giờ chúng ta sẽ nghĩ để tiến hành xóa đi tập hợp là sự hoán vị của nhau như (táo, chuối), (chuối, táo). Hãy nhìn dòng SQL dưới đây.
SELECT P1.name AS name_1, P2.name AS name_2
FROM Products P1, Products P2
WHERE P1.name > P2.name
Kết quả
name_1 name_2
------ ------
Táo Cam
Chuối Táo
Chuối Cam
Tại đây các bạn hãy nghĩ chúng ta có 2 bảng P1 và P2. Qua điều kiện của dấu bất đẳng thì đối với mỗi mặt hàng sẽ chọn đối tượng cùng cặp là mặt hàng theo chọn ra theo thứ tự tên code và đặt tên đằng trước mình. Như vậy, số kết quả dãy sẽ là tổ hợp chập 2 của 3 = 3. Cho đến đây thì cuối cùng ta cũng có một dãy không theo quy luật. Có khi, bình thường cứ nói đến dãy tổ hợp thì trong đầu chúng ta đã định sẵn loại dãy số này rồi.
Kể cả trong trường hợp chúng ta muốn có một dãy là sự kết hợp của 3 yếu tố thì cũng có thể làm được một cách dễ dàng. Dữ liệu ví dụ của ta chỉ có 3 dòng nên kết quả cũng chỉ được biểu diễn trong một dòng.
SELECT P1.name as name_1, P2.name AS name_2, P3.name AS name_3
FROM Products P1, Products P2, Products P3
WHERE P1.name > P2.name
AND P2.name > P3.name;
Kết quả
name_1 name_2 name_3
------ ------ ------
chuối táo cam
Như ví dụ trên, kết hợp sử dụng dấu <>, < hay > để so sánh ngoài dấu = thì đó gọi là kết hợp giá trị bất đẳng. Những giá trị này được sắp xếp trong một tự tổ hợp nên nó được gọi là tự kết hợp giá trị bất đẳng. Trường hợp muốn tạo ra một dãy như thế này là rất nhiều nên các bạn nên nhớ kĩ.
Mặt khác, không chỉ giới hạn bằng những dấu so sánh lớn nhỏ như vậy mà cũng có chức năng so sánh thứ tự chữ cái như trong thứ tự trong từ điển, đây cũng là một điểm (Và tất nhiên, dạng ngày tháng cũng có thể sử dụng).
Xóa dòng có nội dung trùng lặp
Dòng có nội dung trùng lặp là sự tồn tại bị ghét cùng độ với NULL trong thế giới cơ sở dữ liệu. Chính vì vậy phương pháp xóa đi dòng này đã được suy nghĩ ra rất nhiều cách. Ví dụ như trong bảng sản phẩm có ở ví dụ phần trên, chúng ta nghĩ đó là dòng xảy ra sự trùng lặp trong nội dung "Cam". Sự nguy hiểm đến với bảng này đó chính là key chính không được thiết lập (nói đúng hơn là không thể thiết lập. Một bảng như thế này thì cần thiết phải được "dọn dẹp" ngay lập tức.

Lần này tôi sẽ giới thiệu phương pháp để xóa đi sự trùng lặp sử dụng subquery tự tương quan. Tổ hợp và subquery tự tương quan là hai thứ khác nhau nhưng cách suy nghĩ là giống nhau, có rất nhiều trường hợp có thể dùng SQL để trao đổi cùng giá trị nên chỗ này có thể dùng cùng nhau.
Dòng bị trùng lặp không chỉ là dòng 2 mà là ở dòng nào cũng không quan trọng. Thông thường trong trường hợp dãy bị trùng không có chứa key chính thì chúng ta có thể dùng key chính, cũng giống như ví dụ này ......... Ở đây chúng ta sẽ dùng rowid của Oracle.
Cũng như trên, Record ID mà người dùng có thể sử dụng chỉ có thể là Oracle (rowid) và PostgreSQL (oid) thôi. Tại PostgreSQL thì chúng ta phải kèm Option WITH OIDS với mệnh đề CREATE TABLE. Trong trường hợp DBMS khác thì chúng ta nhất định phải thiết lập main key hoặc cần thiết phải sử dụng phương pháp khác (kết quả sau khi đã xóa đi dòng trùng lặp sẽ chuyển vào bảng khác).
--SQL xóa đi những dòng trùng lặp
DELETE FROM Products P1
WHERE rowid < ( SELECT MAX(P2,rowid)
FROM Products P2
WHERE P1.name = P2.name
AND P1.price = P2.price );
Nhìn như trên thì đây là một truy vấn tự tương quan với động tác khó hiểu. Từ sự liên quan giữa hai bảng thì ta mới có thể nói đến đó là sự tượng quan, nhưng chỉ có 1 bảng mà ta lại nói đến từ tương quan thì đó thật là một cách biểu hiện khác thường.
Nghi vấn này được sinh ra đó là khi trình độ đọc SQL bị nhầm lẫn. Subquery tương quan này cũng giống như ví dụ trước, các bạn hãy nghĩ nó như tạo ra 2 tập hợp như dưới đây.
P1
| rowid | name | price |
|---|---|---|
| 1 | りんご | 50 |
| 2 | みかん | 100 |
| 3 | みかん | 100 |
| 4 | みかん | 100 |
| 5 | バナナ | 80 |
P2
| rowid | name | price |
|---|---|---|
| 1 | りんご | 50 |
| 2 | みかん | 100 |
| 3 | みかん | 100 |
| 4 | みかん | 100 |
| 5 | バナナ | 80 |
Điểm chính cũng giống như ví dụ trước, tập hợp có những tên khác nhau trong SQL được suy nghĩ như những vật riêng biệt. Lệnh truy vấn này so sánh P1 với P2, trong những tập hợp giống nhau thì sẽ trả lại rowid lớn nhất của nó.
Như vậy, trong trường hợp mà thành phần không có bộ phận bị trùng lặp như, [1:りんご] hay [5:バナナ] thì kết quả được trả lại như cũ vì điều kiện không thỏa mãn giống nhau nên một dòng cũng không được xóa. Trong trường hợp của みかん thì kết quả trả về sẽ là [4:みかん], và những dòng rowid nhỏ hơn cũng mang thông tin みかん như [2:みかん] và [3:みかん] thì sẽ bị xóa đi. Nhìn SQL nhìn dưới trình độ như một bảng cơ sở thì đó là một cách nhìn với độ trừu tượng thấp. Table hay View là những cái tên được đặt thông qua phương pháp ghi nhớ của chúng, còn nếu suy nghĩ theo góc độ động tác của SQL thì cách ghi nhớ, ghi lại dữ liệu (trừ Perfomance) thì không cần thiết phải xem xét. Cái nào cũng giống nhau đều là những tập hợp (quan hệ). Cấu tạo dữ liệu trong SQL chỉ có một loại như vậy thôi.
Cũng như điều đã nêu ở phần trước thì chúng ta có thể dùng dấu bất đẳng thức thì có thể thực hiện được động tác SQL y như trước. Để xem nó sẽ thực hiện động tác gì thì các bạn hãy thử viết và chạy xem sao nhé.
--SQL xóa đi những dòng trùng lặp
DELETE FROM Products P1
WHERE rowid < ( SELECT MAX(P2,rowid)
FROM Products P2
WHERE P1.name = P2.name
AND P1.price = P2.price
AND P1.rowid < P2.rowid);
Tìm kiếm key bất nhất trong từng bộ phận
Ta có bảng ghi chép về địa chỉ. Những Key chính ở đây có tên, những người cùng một gia đình thì ID gia đình sẽ giống nhau.
Address
| name | family_id | address |
|---|---|---|
| Maeda Yoshiaki | 100 | Tokyo, Minato-ku, Toranomon 3-2-29 |
| Maeda Yumi | 100 | Tokyo, Minato-ku, Toranomon 3-2-92 |
| Kato Cha | 200 | Tokyo, Shinjuku-ku, Nishi Shinjuku 2-8-1 |
| Kato Masaru | 200 | Tokyo, Shinjuku-ku, Nishi Shinjuku 2-8-1 |
| Holmes | 300 | 221B Phố Baker |
| Watson | 400 | 221B Phố Baker |
Như cơ bản thì những người trong cùng một gia đình thì sẽ có cùng một địa chỉ nhưng cũng có trường hợp không là gia đình nhưng lại sinh sống cùng nhau như trường hợp của Holmes. Bây giờ mọi người hãy chú ý vào thông tin vợ chồng Maeda xem. Thực thế thì nếu cùng một ID gia đình thì chắc chắn địa chỉ cũng phải giống nhau, trường hợp này cần sự chỉnh sửa lại. Vậy để tìm kiếm ra nhưng trường hộ như vợ chồng Maeda, cùng family_id mà địa chỉ sinh sống lại không giống với nhau thì chúng ta phải làm thế nào?
Có một vài phương pháp được suy nghĩ ra nhưng nếu chúng ta sử dụng tự tập hợp không đồng nhất thì có thể viết code một cách gọn nhẹ và dễ nhìn.
--SQL tìm ra những ghi chép cùng gia đình nhưng địa chỉ khác nhau
SELECT DISTINCT A1.name, A1.address
FROM Adresses A1, Adresses A2
WHERE A1.family_id = A2.family_id
AND A1.adress <> A2.adress;
Với những câu trong code là "Gia đình giống nhau và địa chỉ khác nhau", về ý nghĩa thì không có điều gì phải suy nghĩ cả. Sự kết hợp tự tổ hợp và tổ hợp giá trị bất đẳng và một sự kết hợp rất mạnh. Ngoài trường hợp phát hiện chỉnh hợp dữ liệu như thế này thì việc diễn ra điều tra sản phẩm như dưới đây cũng có tính ứng dụng ca.
Câu hỏi 1: Từ bảng sản phẩm dưới đây, hãy lấy ra những kết hợp hàng hóa giống nhau về giá.
Products
| name | price |
|---|---|
| Táo | 50 |
| Cam | 100 |
| Nho | 50 |
| Dưa hấu | 80 |
| Chanh | 30 |
| Dâu tây | 100 |
| Chuối | 100 |
Câu trả lời Về cấu tạo thì giống y hệt ví dụ về địa chỉ nhà ở ví dụ phía bên trên family_id -> price adress -> name
Sẽ trở thành như sau
--SQL tìm giá giống nhau nhưng tên sản phẩm là khác nhau
SELECT DISTINCT P1.name, P1.price
FROM Products P1, Products P2
WHERE P1.price = P2.price
AND P1.name <> P2.name;
Kết quả
name price
---- ----
Táo 50
Nho 50
Dâu tây 100
Cam 100
Chuối 100
Trong trường hợp này, khác với ví dụ về địa chỉ ở trên thì nếu ta không viết thêm DISTINCT thì sẽ xuất hiện ra những hàng dài vô dụng nữa. Điểm chính ở đây chính là số lượng ghi chép có cũng key. Trong trường hợp là địa chỉ cũng vậy, nếu gia định Maeda có con thì quả nhiên nếu không có DISTINCT thì kết quả sẽ là một hàng dài. Nếu chúng ta thay thế không viết tổ hợp mà viết bằng Subquery tương quan thì DISTINCT sẽ không cần nữa.
Ranking-Bảng xếp hạng
Trong những công việc tạo ra bảng thống kê hay phiếu đánh giá sử dụng cơ sở dữ liệu thì việc lập những bảng thứ tự theo giá trị điểm số, số người hay lượng bán ra. Theo DBMS thì chúng có những chức năng để đối ứng với những trường hợp như thế này (Oracle, hàm số RANK của DB2 v...v...). Bây giờ, từ bảng dưới đây, chúng ta sẽ điền bảng thứ tự theo giá từ cao trở xuống. Trong trường hợp này thì những sản phẩm có giá giống nhau thì sẽ cùng một số thứ tự, bảng dưới đây sẽ mang thứ tự số cách ra hay thứ tự số liên tiếp thì chúng ta có 2 cách để sắp xếp.
Products
| name | price |
|---|---|
| Táo | 50 |
| Cam | 100 |
| Nho | 50 |
| Dưa hấu | 80 |
| Chanh | 30 |
| Chuối | 50 |
Nếu sử dụng hàm OLAP thì chúng ta sẽ viết như dưới đây.
--Xây dựng bảng xếp hạng: xử dụng hàm OLAP
SELECT name, price
RANK() OVER (ORDER BY price DESC) AS rank_1
DENSE_RANK() OVER(ORDER BY price DESC) AS rank_2
FROM Products;
Kết quả
name price rank_1 rank_2
------ ------ ------ ------
Cam 100 1 1
Dưa hấu 80 2 2
Táo 50 3 3
Chuối 50 3 3
Nho 50 3 3
Chanh 30 6 4
rank_1 là bảng xếp hạng sau khi có những xếp hạng đồng thời gần nhau thì đến thứ hạng tiếp theo không phải là thứ hạng theo số tiếp theo liên tục mà sẽ nhảy qua số mục xếp hạng cùng nhau, còn rank_2 là bảng xếp hạng không xếp theo thứ tự đó mà sẽ tiếp tục xếp hạng ở thứ tự tiếp theo. Đây là những dòng code thể hiện rõ nhất ý nghĩa nó mang. Tuy nhiên chức năng nay so với SQL căn bản vẫn là chức năng mới nên trong MySQL vẫn chưa thể sử dụng được.
Tại đó chúng ta cùng nghĩ phương pháp khác để có thể thực hiện được chương trình trên. Tại đây chúng ta dùng tự tổ hợp những giá trị phi đẳng (thực ra được sử dụng rất nhiều).
--Ranking bắt đầu từ vị trí 1. Không tiếp tục giá trị xếp hạng tiếp theo
SELECT P1.name,
P1.price,
(SELECT COUNT(P2.price)
FROM Products P2
WHERE P2.price>P1.price) + 1 AS rank_1
FROM Products P1;
Kết quả
name price rank_1
------ ------ ------
Cam 100 1
Dưa hấu 80 2
Táo 50 3
Chuối 50 3
Nho 50 3
Chanh 30 6
Có thể đây là phương thức để gán thứ tự một cách thông thường nhất, nhưng chúng ta có thể tùy chỉnh được phương thức này. Nếu chúng ta bỏ đi dòng subquery là +1 thì thứ tự từ top sẽ bắt đầu từ 0, nếu ta chuyển thành [COUNT(DISTINCT P2.price)] thì kể cả trong trường hợp có một thứ tự giống như thế đi chăng nữa thì số thứ tự xếp hạng cũng không bị nhảy và có thể sắp xếp theo đúng thứ tự số(giống như DENSE_RANK). Như thế này thì ta có thể thấy một SQL linh động thông qua việc có thể tùy chỉnh phương thức sắp xếp thứ tự khác nhau tùy theo yêu cầu. Từ đây tôi xin giải thích về động tác của SQL này. Thực ra đây là ví dụ mang hình thái của một khái niệm mang tính định hướng tổ hợp. Những việc được làm trong subquery này là đếm số lượng object có giá trị lớn hơn mình rồi gán thứ tự cho nó.Để câu chuyện có thể dễ hiểu hơn thì chúng ta sẽ loại bỏ những yếu tố có giá trị trùng đi.
{100,80,50,30}
Sẽ còn lại 4 giá trị trên, chúng ta suy nghĩ đến trường hợp bắt đầu từ vị trí 0. Đầu tiên, đối với giá trị 100, vì không có giá trị nào lớn hơn giá trị 100 này nên hàm COUNT sẽ gán cho nó thứ tự 0. Tiếp theo, trường hợp 80, vì trên đó có 1 giá trị lớn hơn đó chính là 100 nên hàm sẽ trả lại giá trị 1. Tiếp theo cũng giống như vậy với trường hợp 50 là số 2, 30 sẽ được gán giá trị 3. Làm như vậy theo như kết quả theo thang giá cả thì chúng ta đã làm được một tập hợp như sau.
Tập hợp đệ quy mang tính vòng tròn đồng tâm
| Tập hợp | Giá | Giá trị cao hơn mình | Số giá trị cao hơn mình |
|---|---|---|---|
| S0 | 100 | - | 0 |
| S1 | 80 | 100 | 1 |
| S2 | 50 | 100, 80 | 2 |
| S3 | 30 | 100, 80, 50 | 3 |
Có nghĩa SQL này,
S0 = ∅
S1 = {100}
S2 = {100, 80}
S3 = {100, 80, 50}
sẽ tạo nên một tập hợp mang tính hồi quy Vòng tròn đồng tâm, và nó sẽ đếm những số thành phần trong tập hợp đó. Để biểu thị từ [Mang tính vinfg tròn đồng tâm] thì chúng ta sẽ nhìn vào mối quan hệ bao hàm của 4 tập hợp sau:
S3 ⊃ S2 ⊃ S1 ⊃ S0
Thực ra, khái niệm sự chia số vào những tập hợp hồi quy không còn và khái niệm mới. Thuyết này được yêu thích và thuyết tập hợp được sử dụng trên 100 năm nay, nó cũng giống như định nghĩa hồi quy của số tự nhiên (bao gồm cả số 0). Ngay cả phương pháp này thì tùy vào người nghiên cứu lại có một số những phong cách khác nhau, nhưng hình thái giống như thứ ta đã dùng lần này trong ví dụ lần này thì đó là phương pháp do một nhà toán học cũng như là một trong những cha đẻ của máy tính Von Neumann nghĩ ra. Neumann bắt đầu từ việc định nghĩa tập hợp rỗng là 0 rồi tiếp theo đó, theo quy tắc như vậy làm với toàn bộ số tự nhiên
0 = φ
1 = {0}
2 = {0, 1}
3 = {0, 1, 2}
・
・
・
Sau khi định nghĩa 0 thì dùng nó để định nghĩa 1. Rồi dùng 0, 1 để định nghĩa 2, rồi dùng 0,1,2 để định nghĩa 3. Cách làm như vậy cũng giống như cấu tạo và cách làm của tập hợp S0~S3 như trên. Có thể nói đây là một ví dụ tốt biểu thị sự liên kết một cách trực tiếp SQL với thuyết tập hợp. Và cong đường nối chúng lại với nhau thì gọi là tự tổ hợp.
Ngoài ra, Sub query này có thể chuyển đổi hình thức tự tổ hợp như tiếp theo đây.
--Yêu cầu ranking: sử dụng tự tổ hợp
SELECT P1.name
MAX(P1.price) AS price,
COUNT(P2.name) +1 AS rank_1
FROM Products P1 LEFT OUTER JOIN Products P2
ON P1.price < P2.price
GROUP BY P1.name;
Nếu không tập hợp lại mà triển khai như tiếp theo đây thì chúng ta có thể nhìn thấy dễ hơn hình ảnh bao trùm mang tính vòng tròn đồng tâm. (Để dễ nhìn, chúng ta bỏ qua sự trùng về giá coi như bảng chỉ có 4 dòng là cam, dưa hấu, nho, chanh)
--Không tập hợp lại, điều tra quan hệ bao hàm
SELECT P1.name, P2.name
FROM Products P1 LEFT OUTER JOIN Products P2
ON P1.price < P2.price
Kết quả
name name
---- ----
Cam
Dưa hấu Cam
Nho Cam
Nho Dưa hấu
Chanh Cam
Chanh Nho
Chanh Dưa hấu
Khi tập hợp tăng thêm một đơn vị thì thành tố cũng tăng thêm một đơn vị. Dựa vào sự đếm số lượng thành tố thì chúng ta có thể tính toán được bảng xếp hạng.
Ngoài ra, query này còn có thêm 1 mẹo đặc trưng nữa. Có thể các bạn đã nhận ra rồi. Tập hợp từ câu trước cho đến nay thì đều là tổ hợp nội bộ một cách chính thống, tại đây chúng ta sẽ xử dụng tổ hợp ngoại bộ. Lý do thì các bạn cứ thử đổi thành tổ hợp nội bộ và chạy thử xem sao.
--Yêu cầu ranking : Thử chuyển về tổ hợp nội bộ ...
SELECT P1.name
MAX(P1.price) AS price,
COUNT(P2.name) +1 AS rank_1
FROM Products P1 INNER JOIN Products P2
ON P1.price < P2.price
GROUP BY P1.name;
Kết quả
--Ranking không hiện số 1!
name price rank_1
------ ------ ------
Dưa hấu 80 2
Táo 50 3
Chuối 50 3
Nho 50 3
Chanh 30 6
Đúng như vậy, kết quả thứ nhất là "Cam" đã biến mất. Về vấn đề này nếu chúng ta chịu khó suy nghĩ một chút thì đó là một kết quả đương nhiên, không có kết quả nào có giá cao hơn cam nên bị điều kiện [P1.price<P2.price] loại trừ. Còn tổ hợp ngoại bộ là một mẹo rất nhỏ để có thể lưu được kết quả thứ nhất. (Về thật này sẽ lại có một nhiệm vụ rất lớn trong chương "So sánh hàng với hàng trong Sub query tương quan" (p.104).
Tóm tắt
Ở trên, thông qua 4 ví dụ ứng dụng thì chúng ta đã giải quyết bấn đề liên quan tới tự tổ hợp. Tự tổ hợp cũng là một thuật rất mạnh của hàm CASE nên nhất định trong khoản này mọi người hãy sử dụng thật thành thạo nó. Tuy nhiên, khi đưa ra điểm chú ý này thì chúng ta sẽ nghĩ tự tổ hợp so với những tổ hợp chạy với đối tượng là những bảng khác nhau thông thường sẽ có giá cao hơn. (Nhất là trường hợp kết hợp và tổ hợp giá trị bất đẳng). Key sử dụng trong trường hợp tự tổ hợp thì khuyến khích sử dụng Key chính hoặc tạo sẵn các chỉ số. Lần này ngay cả trong các câu ví dụ, sẽ sử dụng key chính là hầu hết trong các tập hợp.
Bây giờ chúng ta cùng tóm tắt lại một số nội dung.
- Kiến thức cơ bản về sử dụng kết hợp tự tổ hợp và tổ hợp những giá trị bất đẳng.
- Tạo tập hợp hồi quy và GROUP BY, kết hợp
- Lý giải và suy nghĩ khi tổ hợp các bảng khác nhau thật sự
- Vì giá thành xử lý tốn nhiều nên ta nghĩ đến việc cố gắng hết sức gán chỉ số với key tổ hợp và sử dụng.
Tự tổ hợp là một kĩ thuật được ứng dụng rất rộng rãi, ngay trong quyển sách này thì nó là thứ 2 về tần suất được sử dụng so với hàm CASE. Đối với những người muốn tìm hiểu thêm về kĩ thuật này thì hãy tham khảo những tài liệu dưới đây.
- Joe Celko "SQL cho lập trình viên Bản 2" Về tự tổ hợp thì là chương 17.4.1, về ranking thì là chương 21.4.2
- Joe Celko "Puzzle SQL - xuất bản lần 2"
All rights reserved
