
Một bài toán xử lý mảng tưởng chừng đơn giản!
Xuân sang, Quang đang lang thang trang facebook thì bắt gặp một bạn hỏi bài toán này:
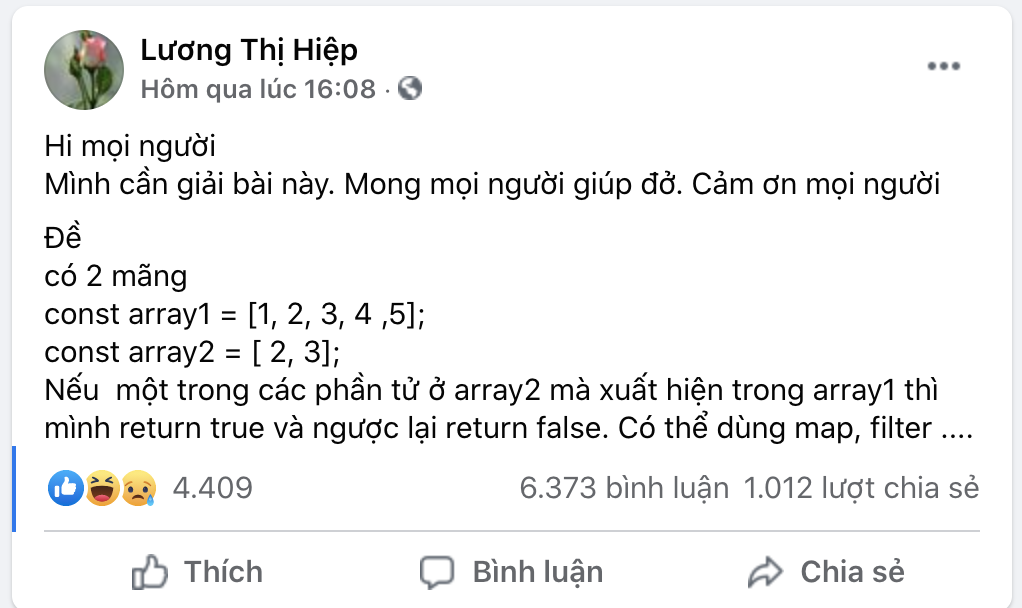
Mặc dù có rất nhiều comment nhưng có điểm sai mà tuyệt nhiên mình không thấy có ai phát hiện ra đó là chủ thớt viết sai "chính tã" : "giúp đỡ" chứ không phải "giúp đở", "mảng" chữ không phải "mãng". Mà thôi bỏ qua vấn đề này đi, cùng tập trung vào vấn đề chính nào!
Để giải bài này chắc cũng không có gì khó mình thấy cũng khá nhiều comment giải giống nhau, mình tóm gọn lại thành các phương pháp chung như sau : (Đây là diễn đàn về Javascript nên lời giải hoàn toàn dùng javascript)
- Gán giá trị check ban đầu là true. Lọc qua từng phần tử mảng array1, mỗi vòng lặp lọc qua mảng array2, nếu có phần tử nào ở màng 2 có giá trị bằng mảng 1 thì lập tức gán check = false và return . Viết thì khá là dễ hiểu nhưng cách này thuật toán quá phức tạp, lọc qua 2 mảng thì performance tăng theo cấp số nhân, nghĩa là 2 mảng càng dài thì thời gian thực thi càng lâu.
array2.some(item => array1.some(item1 => item1 === item))

Cách này thì không ai cãi được
- Cách 2 có vẻ đơn giản hơn, lọc qua array2 và sau đó dùng hàm includes() để xem array1 có chứa phần tử của mảng 2 không. Performance hiệu quả hơn hẳn vì chỉ chạy vòng lặp 1 lần.
arr1.some((x) => arr2.includes(x));
Ngoài ra thì còn 1 số cách sáng tạo khác nhưng nhìn chung là sai.
Nhưng cách giải khiến mình để ý nhất vẫn là cách giải của bạn này, nhận được vô số reaction và comment tán thưởng, thậm chí nhiều người còn thừa nhận rằng đây là cách giải tốt nhất vì không cần dùng bất kì vòng lặp nào :
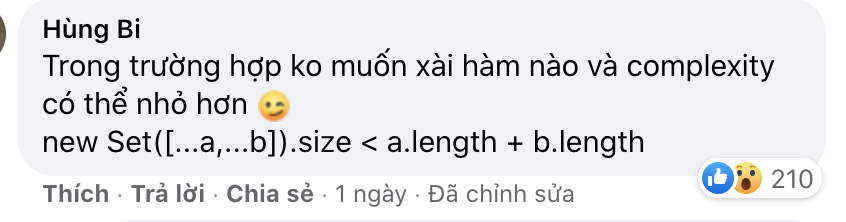
*set loại bỏ phần tử trùng nhau trong mảng (Javascript), tuy nhiên các phần tử của set nằm trong ngoặc nhọn , set không phải là mảng
Đúng là cách giải sáng tạo thật nhưng mình cứ ngờ ngợ làm sao á. Cái cảm giác này thường xuất hiện khi mình làm task xong mà không dám chắc mình có làm đúng hay không (rồi đúng là có bug thật)
Và cách giải trên cũng có bug. Trường hợp 2 mảng là [1,2,3,3] và [4,5] => Trả về true trong khi đáp án phải là false.
Chỉ cần Fix con bug trên là ngon lành cành đào. Không biết có bug nào nữa không nhỉ ? (Vẫn còn ngờ ngợ)
const uniq_a = new Set(a)
const uniq_b = new Set(b)
uniq_a.add(uniq_b).size < uniq_a.size + uniq_b.size
Website của tôi: https://www.websitegiare.co
All rights reserved

Bình luận
Mình thấy code logic sao dễ đọc, dễ hiểu nhất có thể là được còn performance thì tính sau. Nếu mình code thì loop array 2 rồi dùng indexOf
Mình không giỏi thuật toán nhưng mình đoán Set vẫn được implement từ vòng lặp phía dưới mới có thể loại bỏ các phần tử trùng lặp, nên khẳng định này không đúng lắm 🙂
@hoangtq160798 Haiz, cái mình muốn nói là đánh giá khi chạy nhiều lần và đang bàn lượng dữ liệu như ví dụ. Khi chạy 1 lần cách tạo Set tốt hơn, mảng lớn thì Set cũng tốt hơn. Tại sao? Vì giai đoạn check key có hay chưa nó rất nhanh và nó bù lại cho khoảng thời gian tạo Set, thời gian cấp phát bộ nhớ. Vậy khi đánh giá lựa chọn một cách nào đó thì ta cần cân nhắc cái gì? Ý mình là tránh nhận xét cách tạo Set là hay nhất như trong bài viết, mà cần coi ngữ cảnh chạy nhiều hay ít, data nhiều không, cần tối ưu bộ nhớ hay cpu vì RAM và CPU thường phải đánh đổi... ứng với mỗi ngữ cảnh mà chọn cách phù hợp, tránh nhớ đúng một cách và làm một cách máy móc. Phần mình up là muốn nói tác dụng ngoài của Set khi chạy nhiều lần, chi phí tạo Set nó bị tăng nhanh theo số lần lặp và ăn luôn lợi thế check key, không câu nào mình bác bỏ nó. Như vậy mình có thể tóm tắt thế này:
@dhvan85 oke, nghe hợp lý
Bài viết ngắn quá bạn ơi, hụt hẫng
Nếu add một array vào Set thì Set đó sẽ thêm 1 element mới chính là array mà ta? Vậy thì đâu có loại bỏ phần tử trùng nhau

bác lag rồi đó bên dưới có bác giải thích kìa
bên dưới có bác giải thích kìa
Set cũng là 1 dạng hash table. Chỉ khác là các phần tử trong Set được lưu trữ dưới dạng các cặp key-value(K,V) với các value là hằng số. Ví dụ: 1 Set có các phần tử {1, 2, 3} thì bản chất đằng sau là 1 hash table có thể biểu thị dưới dạng object như sau: {1: true, 2: true, 3: true} Do đó, để khởi tạo 1 Set ta cần phải lặp qua array (O(N)) và sử dụng phương thức Object.hasProperty() để kiểm tra phần tử có tồn tại chưa trước khi thêm vào.
Thế nên time complexity vẫn là O(N).
Mình không tán thành với cách suy nghĩ của host, bạn có chắc là sử dụng include , set v.v rằng ở tầng bên dưới của javascript không sử dụng for loop không , mà chắc nịt rằng việc sử dụng tụi kia cho performace tốt hơn trong khi lại không có 1 bài test nào xảy ra cả? đúng là sử dụng những hàm có sẳn là nhanh nhất , nhưng best performance thì mình lại không nghĩ vậy ?
chắc bác chưa biết barebone - xương sống của mọi loại ngôn ngữ, chỉ gồm vòng lặp và phép tăng 1 (++). Cho dù Set có nhanh hơn thì bởi vì không chạy bằng vòng lặp của JS mà là vòng lặp của C++ (Java tuỳ engine) nên trông có vẻ nhanh hơn thôi.
Cho mình hỏi ngu xíu, hàm some và hàm includes trong js đều là duyệt mảng để tìm phần tử, vậy cách giải 2 bản chất vẫn là 2 vòng lặp lồng nhau, độ phức tạp O(N^2) chứ. Đúng là với trường hợp số phần tử nhỏ thế này thì code cho rõ ràng là ok, còn nếu mẫu rất lớn thì mình nghĩ cách giải là: chuyển mảng 1 thành Set trước -> lặp qua từng phần tử trong mảng 2 và xem phần tử đó có trong mảng 1 không, nếu có thì return true, lặp hết mảng 2 mà k có thì return false. Do Set thuộc dạng hash table nên việc tìm 1 phần tử trong Set là O(1), tổng kết thuật toán là O(N)
Nghĩ đơn giản thôi các bác, lấy giao của 2 mảng là được
Mình thuộc trường phái clean code, nên viết cái nào cho rõ ràng, dễ hiểu nhất, ai đọc vào cũng hiểu code làm gì, performance thì từ từ tính sau Chứ code cho cao siêu vào, hoặc viết hằm bà lằng tỏ ra cao thủ, hoặc viết code cụt ngủn kèm 7x7 49 cái comment để người đọc khỏi wtf thì mình thấy cũng không được :v
cái array có dăm 3 cái phần tử mà cứ nghĩ phức tạp lên làm gì.