+6
Sử dụng mạng LSTM (Long Short Term Memory) để dự đoán cổ phiếu
Giới thiệu
Thường đối với các bài toán Time Series thì người ta thường sử dụng các mô hình RNN hoặc LSTM để dự đoán giá trị của một cái gì đó trong một khoảng thời gian nào đó, dựa trên những dữ liệu trong quá khứ mà nó đã học được. Trong bài viết ngày hôm nay, mình xin giới thiệu cho các bạn một ứng dụng của LSTM dùng để dự đoán cổ phiếu tương lai của Apple Company (AAPL), tại trang web: https://finance.yahoo.com/quote/AAPL/history?period1=1325376000&period2=1578614400&interval=1d&filter=history&frequency=1d dựa trên dữ liệu của 8 năm.
Tập dữ liệu :
Dữ liệu mình thu thập từ trang web https://finance.yahoo.com/quote/AAPL/history?period1=1325376000&period2=1578614400&interval=1d&filter=history&frequency=1d , mình lấy từ thời gian 03/01/2012 đến 09/01/2020. Hãy xem dữ liệu của chúng ta. Mở tập tin Apple stock price chứa dữ liệu trong 8 năm. Bạn sẽ thấy nó chứa 7 cột: date, open, high, low, low, close, adj và volume. Ta sẽ dự đoán giá cổ phiếu Open, vì vậy mình không quan tâm đến những cột còn lại.
Data Train:
Về bộ dữ liệu để cho training thì mình lấy 80% từ bộ dữ liệu mình tải về.
Data Test:
Về bộ test thì mình sẽ lấy 20% từ bộ dữ liệu mình tải về.
Môi trường lập trình :
Hiện tại mình dùng google colab để lập trình, cùng với sử dụng thư viện keras. Nếu bạn nào chưa biết cách sử dụng google colab thì bạn có thể đọc tại đây: https://trituenhantao.io/lap-trinh/lam-quen-voi-google-colab/
Thực hiện lập trình và giải thích chi tiết.
Đầu tiên chúng ta sẽ xem xu hướng giá trị cổ phiểu của công ty APPLE COMPANY như thế nào đã nhé :
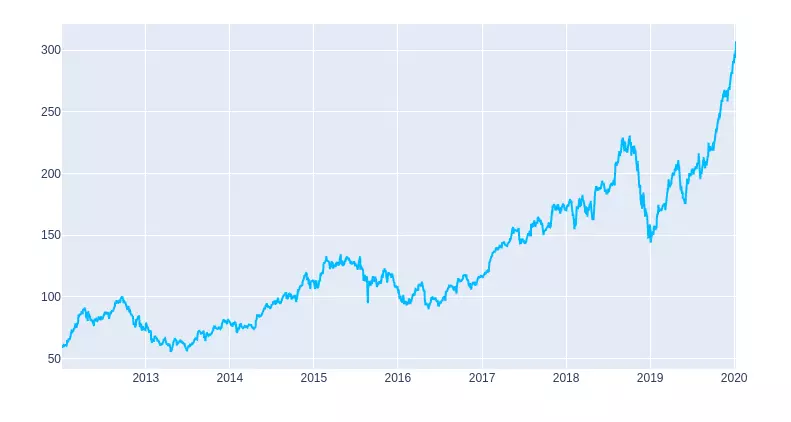 Có thể thấy rằng dữ liệu trên nó biến đổi một cách khó xác định, và bằng mắt thường chúng ta nhìn thì thấy nó chẳng có quy luật nào cả. Nhưng bằng một cách "vi diệu " nào đó mà LSTM có thể dự đoán được các dữ liệu trong tương lai một cách 80-90%. (Thực ra mình chém gió nghe cho sướng vậy thôi, chứ nó có bản chất cả đấy, chắc nhiều bạn hiểu về mô hình này thì hiểu tại sao rồi còn bạn nào chưa hiểu thì hôm sau mình sẽ viết thêm 4,5 bài về LSTM để các bạn hiểu rõ bản chất LSTM nó làm những gì, và họat động ra sao nhé). Thực ra do Lstm (Long short term memory)là một loại mạng thần kinh thường xuyên có khả năng ghi nhớ thông tin quá khứ và trong khi dự đoán các giá trị tương lai, nó cần thông tin trong quá khứ.
Chém gió vậy là đủ rồi, tiếp theo mình sẽ tiến hành lập trình :
Có thể thấy rằng dữ liệu trên nó biến đổi một cách khó xác định, và bằng mắt thường chúng ta nhìn thì thấy nó chẳng có quy luật nào cả. Nhưng bằng một cách "vi diệu " nào đó mà LSTM có thể dự đoán được các dữ liệu trong tương lai một cách 80-90%. (Thực ra mình chém gió nghe cho sướng vậy thôi, chứ nó có bản chất cả đấy, chắc nhiều bạn hiểu về mô hình này thì hiểu tại sao rồi còn bạn nào chưa hiểu thì hôm sau mình sẽ viết thêm 4,5 bài về LSTM để các bạn hiểu rõ bản chất LSTM nó làm những gì, và họat động ra sao nhé). Thực ra do Lstm (Long short term memory)là một loại mạng thần kinh thường xuyên có khả năng ghi nhớ thông tin quá khứ và trong khi dự đoán các giá trị tương lai, nó cần thông tin trong quá khứ.
Chém gió vậy là đủ rồi, tiếp theo mình sẽ tiến hành lập trình :
Kết nối với tài khoản google driver:
Do mình tải file dữ liệu lên google driver nên mình cần liên kết google colab với google driver của mình để tí nữa mình có thể lấy dữ liệu ra từ google driver và tiến hành xử lý dữ liệu trước khi cho vào mô hình mạng.
from google.colab import drive
drive.mount('/content/driver')
Import Libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.preprocessing import MinMaxScaler
from keras.preprocessing.sequence import TimeseriesGenerator
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from keras.layers import Dropout
from tensorflow import keras
import warnings
warnings.filterwarnings("ignore")
Chúng ta import 1 số thư viện quan trọng, để tí nữa chúng ta sử dụng. Ở đây mình sử dụng các thư viện:
- numpy: Giúp xử lý số liệu
- panda: dùng để đọc dữ liệu
- pyplot: Dùng để vẽ biểu đồ
- MinMaxScaler: Dùng để chuẩn hóa dữ liệu
- Và một số thư viện để lập trình cho mô hình mạng dựa trên thư viện keras
Import Dataset
Thực hiện lấy data bằng thư viện panda, sau đó tiến hành chia dữ liệu thành 2 bộ, một bộ train chiếm 80% dữ liệu chính, và một bộ test chiếm 20% còn lại của dữ liệu.
data = pd.read_csv('/content/driver/My Drive/Deep-Learning/stock5/AAPL.csv')
data_end = int(np.floor(0.8*(data.shape[0])))
train = data[0:data_end]['Open']
train =train.values.reshape(-1)
test = data[data_end:]['Open'].values.reshape(-1)
date_test = data[data_end:]['Date'].values.reshape(-1)
Xử lý dữ liệu:
def get_data(train,test,time_step,num_predict,date):
x_train= list()
y_train = list()
x_test = list()
y_test = list()
date_test= list()
for i in range(0,len(train) - time_step - num_predict):
x_train.append(train[i:i+time_step])
y_train.append(train[i+time_step:i+time_step+num_predict])
for i in range(0, len(test) - time_step - num_predict):
x_test.append(test[i:i+time_step])
y_test.append(test[i+time_step:i+time_step+num_predict])
date_test.append(date[i+time_step:i+time_step+num_predict])
return np.asarray(x_train), np.asarray(y_train), np.asarray(x_test), np.asarray(y_test), np.asarray(date_test)
Trước hết để giải thích hàm trên thì mình xin giải thích một số điều như sau:
- time_step: Trong bài toán này thì bạn hiểu là nếu bạn muốn cứ 30 giá trị của Open thì đoán 1 giá trị open tiếp theo thì time_step ở đây bằng 30. Còn num_predict là 1.
Từ đó ta thấy hàm get_data ở trên mục đích là định dạng lại dữ liệu để tí có thể đưa vào mạng. Ví dụ, sau khi qua hàm get_data thì:
x_train = [[1,2,3,4,5,6,7,8,9,10],[2,3,4,5,6,7,8,9,10,11]] và y_train = [11,12]
Bản chất là mình muốn dùng [1,2,3,4,5,6,7,8,9,10] để đoán ra 11, [2,3,4,5,6,7,8,9,10,11] để đoán ra 12. Chắc các bạn hiểu rồi chứ

x_train, y_train, x_test, y_test, date_test = get_data(train,test,30,1, date_test)
# dua ve 0->1 cho tap train
scaler = MinMaxScaler()
x_train = x_train.reshape(-1,30)
x_train = scaler.fit_transform(x_train)
y_train = scaler.fit_transform(y_train)
# dua ve 0->1 cho tap test
x_test = x_test.reshape(-1,30)
x_test = scaler.fit_transform(x_test)
y_test = scaler.fit_transform(y_test)
Ở đây, mình đã code theo kiểu lấy 30 dữ liệu để đoán 1 dữ liệu tiếp theo. Sau đó mình chuẩn hóa dữ liệu về dạng từ 0 đến 1, theo hàm MinMaxScaler() cho bộ train và test. Mục đích của chuẩn hóa là để tí nữa vào mô hình mạng nó tối ưu tốt hơn. Tiếp theo, chúng ta sẽ reshape lại cho x_train và y_train :
# Reshape lai cho dung model
x_train = x_train.reshape(-1,30,1)
y_train = y_train.reshape(-1,1)
#reshape lai cho test
x_test = x_test.reshape(-1,30,1)
y_test = y_test.reshape(-1,1)
date_test = date_test.reshape(-1,1)
Tại sao phải reshape vậy, bởi vị theo quy chuẩn của keras thì đầu vào của LSTM có dạng (batch_size, time_steps, feature) như sau:
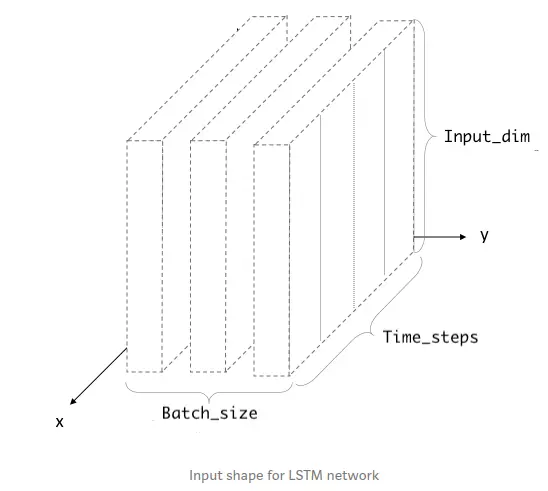 Batch size: Cứ hiểu là có bao nhiêu cặp (time_steps, feature) ấy
time_steps: Như trình bày ở trên rồi
feature: là có bao nhiêu thuộc tính của mỗi phần tử trong time_step. Ví dụ : time_step có 10 giá trị (mỗi giá trị là một vector), mỗi vector là một giá trị 2 chiều chẳng hạn, thì feature ở đây là 2 (tức 2 chiều đó ). Tóm cái váy lại, thì feature cứ hiểu là số thuộc tính của mỗi phần tử time_step.
Còn reshape đầu ra mục đích là tí cho hợp với shape đầu ra của mô hình mạng. Ở trên ta thấy dùng 30 để đoán 1, nên đầu ra ở đây phải reshape theo (-1,1).
Batch size: Cứ hiểu là có bao nhiêu cặp (time_steps, feature) ấy
time_steps: Như trình bày ở trên rồi
feature: là có bao nhiêu thuộc tính của mỗi phần tử trong time_step. Ví dụ : time_step có 10 giá trị (mỗi giá trị là một vector), mỗi vector là một giá trị 2 chiều chẳng hạn, thì feature ở đây là 2 (tức 2 chiều đó ). Tóm cái váy lại, thì feature cứ hiểu là số thuộc tính của mỗi phần tử time_step.
Còn reshape đầu ra mục đích là tí cho hợp với shape đầu ra của mô hình mạng. Ở trên ta thấy dùng 30 để đoán 1, nên đầu ra ở đây phải reshape theo (-1,1).
Xây dựng mô hình mạng:
#dau vao 30 doan 1
n_input = 30
n_features = 1
model = Sequential()
model.add(LSTM(units=50,activation='relu', input_shape=(n_input, n_features), return_sequences=True))
model.add(Dropout(0.3))
model.add(LSTM(units=50, return_sequences=True))
model.add(Dropout(0.3))
model.add(LSTM(units=50))
model.add(Dropout(0.3))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mse')
Bước đầu tiên, chúng ta cần khởi tạo lớp Sequential. Đây sẽ là lớp mô hình của chúng tôi và chúng tôi sẽ thêm các lớp LSTM, Dropout và Dense cho mô hình này. Ở trên ta thêm vào 3 lớp LSTM liên tiếp, và cứ qua 1 lớp là có 1 dropout 0.3 . Cuối cùng ta cho qua một tầng Dense với đầu ra là 1 chiều.
model.compile(optimizer='adam', loss='mse')
Mình sử dụng hàm loss bình phương trung bình là hàm mất mát và để tối ưu hóa thuật toán, chúng tôi sử dụng trình tối ưu hóa adam.
Huấn luyện mạng
model.fit(x_train, y_train, epochs=500, validation_split=0.2, verbose=1, batch_size=30)
model.save('/content/driver/My Drive/Deep-Learning/stock5/30_to_1.h5')
Thực hiện huấn luyện mạng với validation là 0.2, batch_size =30 và tiến hành lưu lại mô hình
Chạy kết quả test
model = keras.models.load_model('/content/driver/My Drive/Deep-Learning/stock5/30_to_1.h5')
test_output = model.predict(x_test)
# print(test_output)
test_1 = scaler.inverse_transform(test_output)
test_2=scaler.inverse_transform(y_test)
plt.plot(test_1[:100], color='r')
plt.plot(test_2[:100] ,color='b')
plt.title("STOCK APPLE COMPANY")
plt.xlabel("STT")
plt.ylabel("Price")
plt.legend(('prediction', 'reality'),loc='upper right')
plt.show()
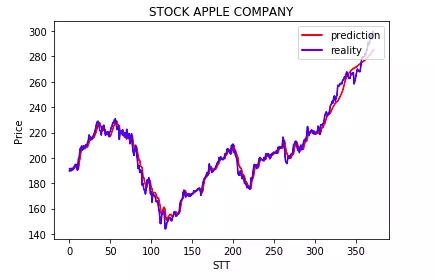
Ta thực hiện lấy model đã lưu ra và tiến hành dự đoán bằng test_output = model.predict(x_test)
Sau khi dự đoán xong thì chúng ta thực hiện inverse transform lại, do lúc nãy ta đã chuẩn hóa chúng nằm trong 0->1, bây giờ ta chuyển nó về đúng giá trị thật của chúng bằng đoạn mã sau:
test_1 = scaler.inverse_transform(test_output)
test_2=scaler.inverse_transform(y_test)
Và chúng ta có thể thấy mô hình mạng của mình dự đoán giá trị cổ phiếu khá chính xác phải không nào.
Kết luận
Mạng bộ nhớ ngắn hạn (LSTM) là một trong những mạng thần kinh được sử dụng phổ biến nhất để phân tích chuỗi thời gian. Khả năng ghi nhớ thông tin trước đó của LSTM khiến nó trở nên lý tưởng cho các nhiệm vụ như vậy. Trong bài viết này, mình đã thực hiện viết mô hình cho dự đoán cổ phiếu Apple và cho kết quả tốt. Cảm ơn các bạn đã xem bài viết của mình. Source code: code lstm
NỘI DUNG
Series này không có bất kỳ bài đăng nào

Hôm sau quân sư cho mình mua ít cổ phiếu làm giàu bạn ei
với time_step = 1 thì scale như thế nào vậy bạn? predict cho giá ngày mai sẽ như thế nào trong trường hợp này.
làm dự báo thời tiết được ko
Cái này cũng khá hay. Nhưng nó có thể hiển thị hôm nay cổ phiếu đăng tang hay giảm k
Cho hỏi xíu ạ mình phân chia train test thế nó được lưu ở đâu hỏi ngu tý
dữ liệu trong khoảng cần dự đoán lại dựa trên chính dữ liệu thật trong khoảng đó ?? 😃 ??
"Mô hình mạng của mình dự đoán giá trị cổ phiếu khá chính xác phải không nào" thôi nào bro )
)