Xử lý bigdata bằng dịch vụ EMR của AWS part 1
Bài đăng này đã không được cập nhật trong 4 năm

Đối với 1 hệ thống chạy dịch vụ người dùng lớn và yêu cầu sự giám sát từ phía người dùng thì việc xử lý dữ liệu lớn đến hàng chục triệu bản ghi là điều không dễ dàng. Bởi lẽ để xử lý lượng dữ liệu lớn như vậy nếu theo cách thông thường thì respond time thường sẽ rất lớn, đôi khi còn vượt quá giới hạn thời gian kết nối (như của egnix) làm cho trình duyệt hiểu lầm là mất kết nối đến server và dữ liệu không trả được tới trình duyệt => khách hàng không dùng được dịch vụ => chất lượng dịch vụ đi xuống. Điều này quả thực rất tồi tệ nhưng bất cứ hệ thống lớn nào đều sẽ phải gặp phải.
Và các nhà cung cấp dịch vụ AWS đã rất "thấu hiểu" những nhu cầu cấp thiết này và đã cho nhiều ra dịch vụ để đáp ứng , ví như dịch vụ RedShift (các bạn có thể tham khảo RedShift ở bài viết này: https://viblo.asia/HjkaruBloom/posts/E7bGoxYKv5e2)
- Ưu điểm là các trường được sort và lưu theo cột nên việc đọc dữ liệu rất nhanh
- Nhược điểm:
- đó là chỉ có thể đánh index 1 lần lúc tạo bảng, nếu thêm dữ liệu hay đánh index thêm trường thì ta cần phải oánh index lại bảng từ đầu)
- Và aws hiện có ít lựa chọn (con rẻ nhất là 1 core thì tầm 0.34$/h còn con ngon hơn thì thường 8 core giá tầm 6$/h) nói chung là đắt
=> Có 1 giải pháp khác mà AWS cung cấp đó là sử dụng dịch vụ EMR. Nôm na đây là giải pháp sử dụng các tool xử lý bigdata(hadoop, yarn, hive, pig, spark ...) cài trên các con EC2 với mức phí như các con EC khác và cộng thêm phí sử dụng dịch vụ (tổng cộng thêm tầm 10 - 20%), giá cả bạn có thể xem ở đây.
Nói chung là dùng EMR sẽ rẻ hơn và đạt hiệu quả khá tốt với nhu cầu sử dụng đồng thời khả năng tùy chỉnh "kích cỡ" hệ thống rất đơn giản (theo như quảng cáo của AWS là giúp bạn tiết kiệm 50-80% chi phí trong việc sử dụng các con instance https://aws.amazon.com/emr/).
OK, nói lan ma lan minh nên mình sẽ vào vấn đề chính luôn đó là ví dụ về xử lý big data mà ở đây là log hệ thống
Bài toán minh đưa ra cần pahir xử lý ở đây đó là minh có 1 bảng log lưu ở dang json có 15 triệu record với dung lượng ~ 12Gb, và mình cần lọc thông tin theo nhiều trường dữ liệu, hiện tại chạy thử trên con cùi bắp nhất redshipt thì respondtime đang là ~ 34s. Và mình sẽ xử lý đống này với Emr
Trước hết để sử dụng EMR, bạn cần có tài khoản aws và đăng nhập vào hệ thống, sau đó bạn vào đường link sau để tạo các máy dùng dịch vụ EMR(giống như tạo máy ảo để chạy app vậy)
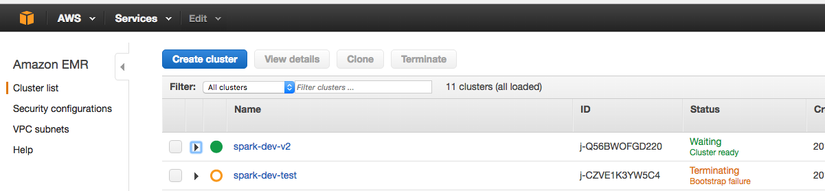
Ở đây AWS sẽ hiện ra 1 list danh sách các cluster (nếu bạn đã tạo), các cluster chính là 1 hệ thống bao gồm nhiều máy EC2 phục vụ việc xử lý dữ liệu của bạn.
Để tạo 1 cụm các máy xử lý bạn click vào nút Create cluster có màu xanh trên ảnh.
1 bảng mới sẽ xuất hiện
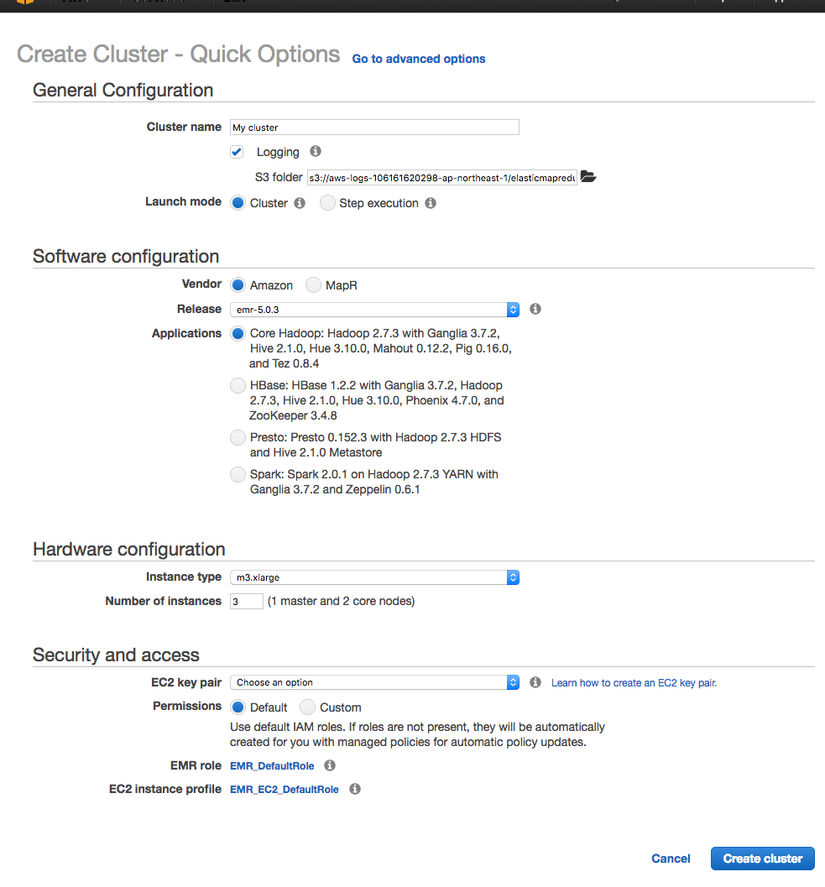
có khá nhiều thông số ở phần cài đặt nhanh này, ok đừng lo lắng, chúng ta sẽ đi từng phần 1
đầu tiên là:
General Configuration - Cấu Hình chung
- Cluster name: tên cụm máy sẽ hiện lên danh sách ở bước trước, bạn đặt như nào cho dễ nhớ là đc
- Log: tích vào là bạn chọn đường dẫn lưu log lên trên s3, nếu ko thì log sẽ đc lưu trên máy instance và sẽ mất sạch sành sanh nếu bạn hay 1 dịch vụ nào đó tắt máy.
- Launch mode: vì mình đang tạo sample nên sẽ chọn cluster, nếu bạn pro và muốn cài thêm các chương trình khác chạy kèm trên máy thì bạn có thể chọn Step execution sau đó ... làm tiếp theo hướng dẫn
 ). Beginner như mình thì cứ để Amazone cài mặc định thôi.
). Beginner như mình thì cứ để Amazone cài mặc định thôi.
Software configuration - cấu hình phần mềm
- vender: chọn nhà cung cấp dịch vụ lưu file, mặc định cứ chọn Amazone
- Release: chọn phiên bản mới nhất bây giờ là emr-5.0.3
- Application: chọn các ứng dụng cài đặt lên máy, ở đây mính cần dùng hadoop, spark, yarn nên sẽ chọn option thứ 4 dưới cùng
Hardware configuration - cấu hình phần cứng
ở đây bạn sẽ chọn loại máy instance để sử dụng, tùy vào nhu cầu mà ta cần chọn máy phù hợp, ví dụ ở đây mình chỉ cần load file mỗi ngày 1 lần với dung lượng lớn cần tốc độ cao do đó mình sẽ chọn dòng máy C có ram chấp nhận được cùng tốc độ chip xử lý cao.
- number of instance: số lượng máy bạn sẽ dùng để chạy hệ thống theo công thức n máy thì có 1 master (quản lý + tổng hợp dữ liệu) + (n-1) con máy con để phục vụ tính toán. càng nhiều con thig tính toán kết quả càng nhanh (theo cấu trúc hệ thống phân chia file tới các máy con cái này minh sẽ nói ở phần sau khi giảo thích về hadoop) tuy nhiên giá tiên phải trả sẽ càng tăng.
Security and access - bảo mật và quyền truy cập
- EC2 key pair: ở đây bạn cần add key để máy tính của bạn sử dụng key này có thể ssh vào các con ec-2 này (giống khi tạo mấy con ec-2 bình thường), nếu ko có bạn cần tạo key theo link bên cạnh mục
Learn how to create an EC2 key pair.rồi key sẽ hiện ra trong list - Permissions: default mà xài thôi, nếu bạn không phải admin tài khoản thì bạn cần chọn custome và xin permision từ admin
Sau khi create thành công bạn đợi 1 lát để máy bật lên và cài đặt các gói tin cần thiết. Rồi bạn vào cluster list bạn sẽ thấy cluster mà bạn vừa tạo ra. Click vào cluster đó để xem thêm thông tin chi tiết
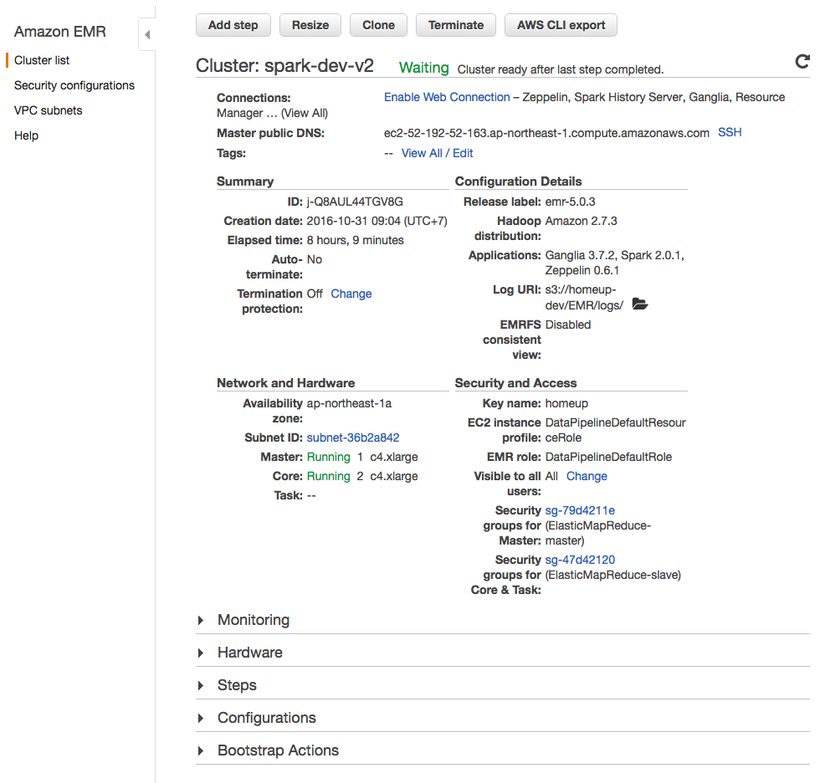
Bạn sẽ thấy các thông tin khá là chi tiết và đầy đủ
Ngoài ra ở dưới bạn còn thấy 5 tab hỗ trợ khác:
-
Monitoring: giám sát các thông số của hệ thống realtime trong khoảng thời gian 5'
-
Hardware: thông tin phần cứng các instances trong cluster. Cái này khá quan trọng, ở tab này bạn có thể tinh chỉnh số client dùng trong 1 hệ thống một cách đơn giản
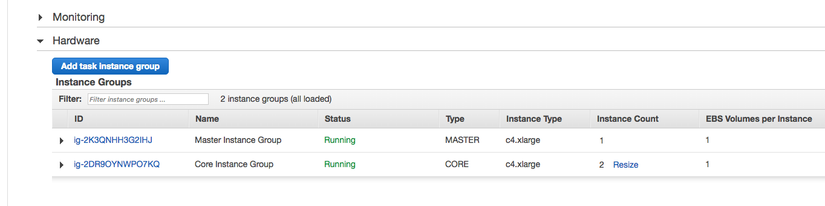
để sửa số instance bạn click vào phần
resizecủa phần máy có type là CORE. Nó sẽ hiện lên 1 box để bạn điền số lượng instances mà bạn muốn chạy ở client. Hệ thống sẽ tự động down/up thêm instance cho bạn.Để xem thêm thông tin và thao tác với các máy trong hệ thống như xem ip, tên domain, hành động tắt/bật máy ...
-
Steps: như mình đã nói nên đây là phần bạn add các script chạy trong hệ thống, hiện tại mặc định sẽ là các gói khi cài đặt máy.
-
Configurations: các cấu hình của tool cài trên máy, bạn có thể thêm trực tiếp ở đây
-
Bootstrap Actions: bạn có thể thêm
Bootstrap Actionsđể chạy các script để cài đặt các phần mềm ngoài hay các config hệ thống bạn muốn khi chạy máy ( phần nayd còn chạy trước cả các quá trình hadoop chạy và các node kết nối với nhau và xử lý dữ liệu).
Để truy cập vào máy master bạn cần vào hardware check xem địa chỉ ip máy master. Có 1 lưu ý ở đây là bạn cần ssh với key mà bạn đã đăng ký ở lúc tạo máy và dùng tên ssh là hadoop
ssh -i [đường dẫn file key pem] hadoop@địa_chỉ_ip_or_ten_domain
#sample
ssh -i /path/my-key-pair.pem hadoop@compute-1.amazonaws.com
Sau khi ssh thành công bạn sẽ thấy thông báo khá là đẹp từ hệ thống (theo mình thấy là đẹp hơn EC ) )
Bài 1 tạm kết thúc ở đây, ở bài sau mình sẽ nói rõ hơn về cấu trúc hệ thống hadoop, spark mà emr sử dụng
Refrences:
All rights reserved
