Xử lý 100 triệu dòng trong 1 giây: 8 thư viện Python khiến Excel trở nên thừa thãi
Khi xử lý dữ liệu, mình thấy Excel đôi khi rất ức chế. Không phải vì tính năng của nó tệ, mà là nó thua ngay từ vạch xuất phát ở khoản tự động chuyển đổi định dạng (hidden conversion) và thiếu tính tái lập (non-reproducible). Lỗi định dạng ngày tháng, file lớn thì treo máy, logic tính toán khó truy vết... những vấn đề này là chí mạng trong các dự án kỹ thuật (engineering).

Vì vậy, mình đã tổng hợp một bộ công cụ (stack) Python thực chiến. Không màu mè, chỉ tập trung giải quyết vấn đề cụ thể.
1. DuckDB: Xử lý dữ liệu quy mô tỷ bản ghi nhẹ tựa lông hồng
Nếu phải xử lý vài trăm MB đến vài GB dữ liệu trên máy đơn, mức tiêu thụ RAM của Pandas thực sự làm người ta phát điên. DuckDB xuất hiện để lấp đầy khoảng trống giữa SQLite và các cơ sở dữ liệu phân tán. Nó là một cơ sở dữ liệu OLAP dạng in-process (trong tiến trình), với đặc điểm nổi bật là không cần cấu hình (zero-config) và tính toán vector hóa.
DuckDB có thể thực thi SQL trực tiếp trên các file CSV, Parquet hoặc JSON mà không cần load toàn bộ dữ liệu vào RAM.
import duckdb
# Thực thi SQL trực tiếp trên file Parquet, không cần tạo DB hay bảng
# Query ở đây giống Pandas dataframe, nhưng tính toán diễn ra trong engine của DuckDB
result = duckdb.sql("""
SELECT
department,
AVG(salary) as avg_salary
FROM 'employees.parquet'
WHERE join_date > '2022-01-01'
GROUP BY department
ORDER BY avg_salary DESC
""").df()
print(result)
2. Ibis: Viết code một lần, chạy mọi nơi
Ibis và DuckDB hiện là "Cặp đôi vàng" trong làng Data Engineering.
Cốt lõi của Ibis là tách biệt logic nghiệp vụ khỏi engine thực thi. Bạn có thể dùng API Python tương tự Pandas để viết logic truy vấn, nhưng backend có thể chuyển đổi mượt mà giữa DuckDB, ClickHouse, BigQuery hay thậm chí là PySpark.
Khi dùng Ibis để "lái" DuckDB, bạn vừa tận hưởng sự thanh lịch và kiểm tra kiểu (type checking) của Python, vừa tận dụng được tốc độ thực thi cực nhanh của DuckDB. Một mũi tên trúng hai đích.
import ibis
# Kết nối backend DuckDB (cũng có thể là SQLite, Postgres...)
con = ibis.duckdb.connect()
# Đọc dữ liệu dạng lười (lazy), lúc này chưa load vào RAM
table = con.read_csv("sales_data.csv")
# Xây dựng biểu thức truy vấn
expr = (
table.filter(table["status"] == "completed")
.group_by("region")
.aggregate(total_revenue=table["amount"].sum())
.order_by(ibis.desc("total_revenue"))
)
# Chỉ khi gọi execute() thì SQL mới được sinh ra và thực thi
print(expr.execute())
3. Polars: DataFrame của kỷ nguyên đa luồng
Pandas là đơn luồng (single-threaded), trong khi Polars được viết bằng Rust, sinh ra đã hỗ trợ tính toán song song. Khi xử lý các tập dữ liệu lớn, tốc độ của Polars thường nhanh hơn Pandas vài lần.
Triết lý thiết kế của nó áp dụng "Đánh giá lười" (Lazy Evaluation), xây dựng kế hoạch truy vấn trước, tối ưu hóa qua optimizer rồi mới thực thi, giúp giảm đáng kể chi phí bộ nhớ.
import polars as pl
# Quét file (scan) thay vì đọc (read), bật chế độ Lazy
q = (
pl.scan_csv("large_dataset.csv")
.filter(pl.col("age") > 30)
.select(["name", "salary", "department"])
.group_by("department")
.agg(pl.col("salary").mean().alias("avg_salary"))
)
# collect() kích hoạt tính toán thực tế
df = q.collect()
print(df)
4. PyArrow Compute: Hòn đá tảng của tính toán
PyArrow không chỉ là tiêu chuẩn định dạng dữ liệu; module compute của nó cung cấp một bộ hàm tính toán vector hóa hiệu năng cao. Rất nhiều công cụ dữ liệu hiện đại (bao gồm Pandas 2.0+) đều đang dùng nó ở tầng dưới (under-the-hood).
Nếu cần thực hiện các phép toán hoặc xử lý chuỗi cực nhanh trên mảng mà không muốn gánh thêm overhead của DataFrame, hãy cân nhắc PyArrow Compute.
import pyarrow as pa
import pyarrow.compute as pc
# Tạo mảng Arrow
arr_a = pa.array([10, 20, 30, 40, None])
arr_b = pa.array([2, 4, 5, 8, 1])
# Dùng kernel tính toán để nhân vector, tự động xử lý giá trị None
result = pc.multiply(arr_a, arr_b)
# Lọc dữ liệu
mask = pc.greater(result, 50)
filtered = pc.filter(result, mask)
print(filtered)
5. TinyDB: Lưu trữ hướng tài liệu siêu nhẹ
Không phải dự án nào cũng cần PostgreSQL. Với việc quản lý cấu hình, lưu dữ liệu crawler nhỏ hay tool local, TinyDB là lựa chọn tuyệt vời. Nó là database dạng document viết bằng Python thuần, dữ liệu lưu trong file JSON, API tự nhiên như thao tác với list trong Python.
from tinydb import TinyDB, Query
db = TinyDB('local_storage.json')
User = Query()
# Insert dữ liệu
db.insert({'name': 'Alice', 'role': 'admin', 'points': 85})
db.insert({'name': 'Bob', 'role': 'user', 'points': 60})
# Query dữ liệu
results = db.search(User.role == 'admin')
print(results)
6. Rill: Công cụ BI cho Developer
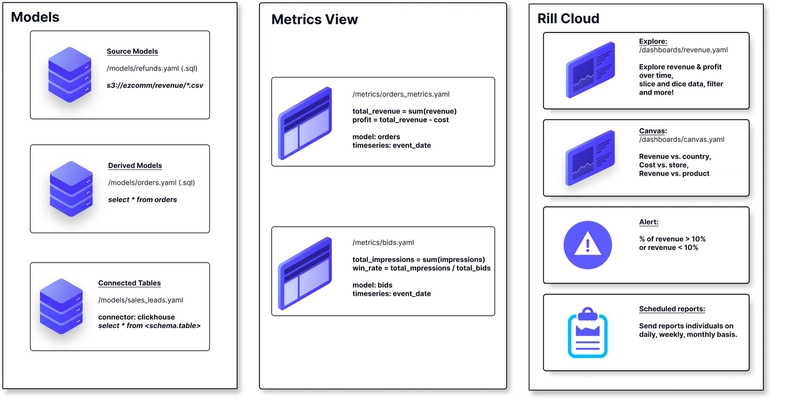
Dù Rill giống một công cụ hơn là thư viện Python thuần túy, nhưng nó có vị thế độc tôn trong stack dữ liệu Python hiện đại. Dựa trên DuckDB, Rill đọc nhanh dữ liệu local (CSV, Parquet) và tạo dashboard BI tương tác trong tích tắc. Nó giải quyết nỗi đau "muốn xem cái biểu đồ mà phải dựng cả con Superset", cực kỳ hợp để khám phá phân phối dữ liệu nhanh (EDA).
7. Numba: Python chạy với tốc độ C
Khi code chứa nhiều vòng lặp for thuần (như tính toán khoa học, thuật toán phức tạp), trình thông dịch của Python thường trở thành nút thắt cổ chai. Numba là trình biên dịch JIT (Just-In-Time), chỉ cần thêm một dòng decorator, nó sẽ biên dịch hàm Python thành mã máy để chạy.
from numba import jit
import time
# Không dùng @jit, vòng lặp Python khá chậm
# Dùng nopython=True để ép sinh mã máy
@jit(nopython=True)
def heavy_computation(n):
total = 0
for i in range(n):
total += i * 2
return total
start = time.time()
print(heavy_computation(100_000_000))
print(f"Thời gian: {time.time() - start:.4f} giây")
8. Bonobo: Framework ETL hạng nhẹ
Với các tác vụ di chuyển dữ liệu không cần đến hệ thống lập lịch hạng nặng như Airflow, Bonobo cung cấp giải pháp ETL dựa trên đồ thị (Graph) rất nhẹ nhàng. Nó dùng code Python thuần để định nghĩa luồng dữ liệu, logic rõ ràng, rất hợp để xử lý làm sạch và chuyển đổi dữ liệu quy mô vừa và nhỏ.
import bonobo
def extract():
yield {'id': 1, 'name': ' Item A '}
yield {'id': 2, 'name': ' Item B '}
def transform(row):
return {
'id': row['id'],
'name_clean': row['name'].strip().upper()
}
def load(row):
print(f"Loading: {row}")
def get_graph(**options):
graph = bonobo.Graph()
graph.add_chain(extract, transform, load)
return graph
if __name__ == '__main__':
# Chạy thực tế dùng lệnh 'bonobo run'
parser = bonobo.get_argument_parser()
with bonobo.parse_args(parser) as options:
bonobo.run(get_graph(**options))
Nền tảng: Quản lý môi trường của bạn
Các thư viện trên bao phủ từ lưu trữ, tính toán đến quy trình ETL. Và tất nhiên, đã là thư viện Python thì cần môi trường Python.
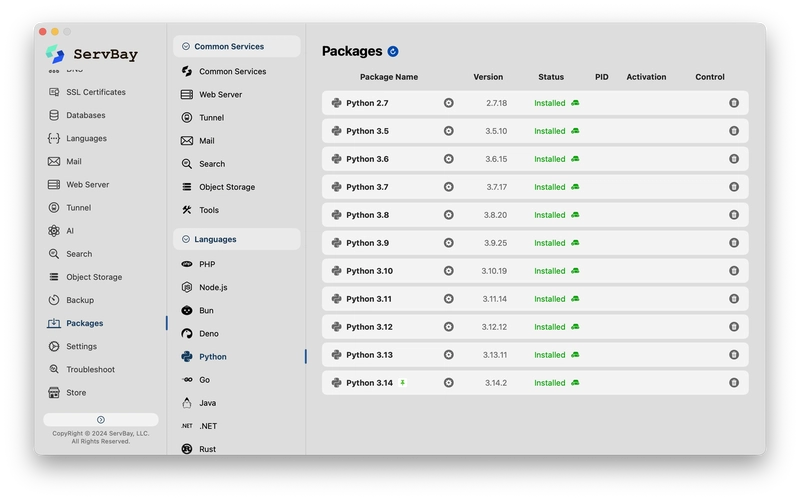
Nhưng thực tế thì có coder nào chỉ maintain đúng một dự án đâu? Chắc chắn sẽ có dự án cần Python 3.14 mới nhất, dự án khác lại kẹt ở Python 3.8, thậm chí phải bảo trì hệ thống cũ rích chạy Python 2.7. Nếu làm rối tung môi trường Python mặc định của hệ thống thì việc sửa chữa đúng là ác mộng.
Lúc này, chúng ta cần đến ServBay.
ServBay cung cấp cho developer một môi trường phát triển cách ly và thuần khiết. Ưu điểm lớn nhất là triển khai một chạm (one-click) và cùng tồn tại đa phiên bản.
- Cài đặt siêu tốc: Đừng dùng dòng lệnh hì hục nữa. ServBay cài đặt môi trường phát triển chứa đủ các component thông dụng chỉ với vài cú click.
- Hỗ trợ toàn diện phiên bản: Từ Python 3.x mới nhất đến các bản Python 2.x đời đầu.
- Cách ly môi trường: Môi trường của ServBay độc lập hoàn toàn với hệ thống, không làm "ô nhiễm" Python mặc định của macOS/Linux, đảm bảo tính ổn định cho máy của bạn.
Đối với các developer theo đuổi hiệu suất, việc giao phó quản lý môi trường cho ServBay để dồn sức vào code và logic dữ liệu mới là sự lựa chọn khôn ngoan.
All rights reserved
